模拟生成新能源车辆数据,并写入HDFS中
目录
基本要求如下
一、虚拟机的准备
二、生成新能源车辆数据
1、导入需要用到的库
2、生成车辆数据
三、将数据写入json文件
四、将文件写入HDFS
1、下载pyhdfs
2、将文件写入HDFS中
五、总结
编写一个程序,每天凌晨3点模拟生成当天的新能源车辆数据(字段信息必须包含:车架号、行驶总里程、车速、车辆状态、充电状态、剩余电量SOC、SOC低报警、数据生成时间等)。
基本要求如下
1、最终部署时,要将这些数据写到HDFS中
2、车辆数据要按天存储,数据格式是JSON格式,另外如果数据文件大于100M,则另起一个文件存。每天的数据总量不少于300M
3、每天模拟生成的车辆数据中,必须至少包含20辆车的数据,即要含有20个车架号
4、每天生成的数据中要有少量(20条左右)重复数据(所有字段都相同的两条数据则认为是重复数据),且同一辆车的两条数据的数据生成时间间隔两秒;
5、每天生成的数据中要混有少量前几天的数据
本人也是一位正在学习中的新手,了解有限,有什么错误的地方大家多多指点。
一、虚拟机的准备
1、首先部署好三个节点(此节点是从伪分布式复制过来的,伪分布式已经部署过部分内容)
192.168.216.101 master
192.168.216.102 slave1
192.168.216.103 slave2
2、使用vi /etc/sysconfig/network-scripts/ifcfg-ens33对IP进行修改
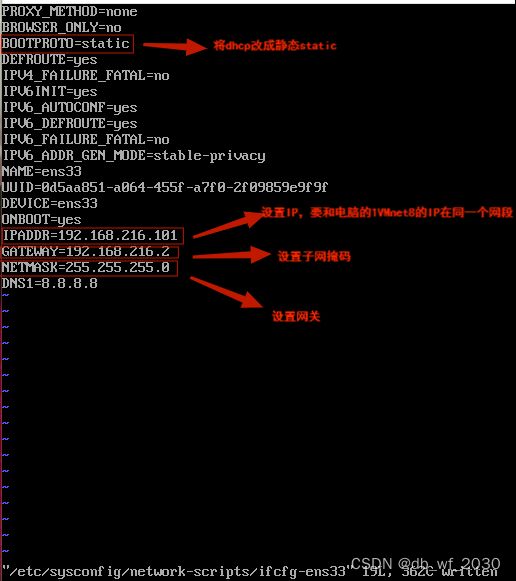
修改IP之后重启网卡:systemctl restart network
3、设置主机名和映射

master的hosts映射配置好后,可以通过scp命令,将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。
scp /etc/hosts root@slavel:/etc将hosts同步到另外两个虚拟机的/etc路径下,默认覆盖原有文件
验证映射是否成功:ping 主机名,能ping成功说明映射成功
4、设置免密登录、关闭防火墙,并禁止防火墙开机自启
关闭防火墙
systemctl stop firewalld5、修改master主机上的hadoop配置文件,配置好后同步到其他两个主机上
分别是:core-site.ml、hdfs-site.xml、yarn-site.xml、slaves
6、进行时间同步和NameNode格式化,启动hadoop集群
在三个虚拟机上分别执行该命令,即可完成时间同步,此时三个节点的时间应该是一致的。
ntpdate ntp.api.bz格式化(格式化只需格式化一次)
hdfs namenode -format启动集群
start-all.sh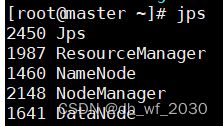
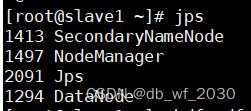
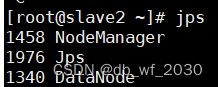
二、生成新能源车辆数据
1、导入需要用到的库
import json
import random
import time
import osrandom()方法可以返回随机生成的一个实数
import time 模块time包含用于获取当前时间、操作时间和日期、从字符串中读取日期、将日期格式化为字符串的函数
os模块提供的就是各种 Python 程序与操作系统进行交互的接口
2、生成车辆数据
过程:首先,按照题目要求,我们构建了很多不同的字段,如车架号、车速、车辆状态等,然后用不同的函数为每个字段实现了要求,如用random.uniform()函数随机生成行驶里程和速度,最后读取当前时间,生成数据。
# 生成车架号
def generate_vin():
vin = ''
for i in range(17):
vin += random.choice('0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ')
return vin
# 生成车辆状态
def generate_vehicle_status():
vehicle_status = ['run', 'stop', 'charging']
return random.choice(vehicle_status)
# 生成充电状态
def generate_charge_status():
charge_status = ['not charged', 'charging', 'charge complete']
return random.choice(charge_status)
# 生成SOC低报警
def generate_soc_warning():
soc_warning = ['normal', 'Less than 20%', 'Less than 10%']
return random.choice(soc_warning)
# 生成数据
def generate_data():
data = {}
data['vin'] = generate_vin()
data['mileage'] = round(random.uniform(0, 100000), 2)
data['speed'] = round(random.uniform(0, 120), 2)
data['vehicle_status'] = generate_vehicle_status()
data['charge_status'] = generate_charge_status()
data['soc'] = round(random.uniform(0, 100), 2)
data['soc_warning'] = generate_soc_warning()
data['time'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
return datafor i in range():是python中的for循环语句,用于遍历一个可迭代对象,其中range()函数将其转化为一系列整数序列,,然后在每个循环迭代中,将序列中的一个元素赋值给变量i,然后执行循环体中的代码。
random.choice(seq):从非空序列中随机选取一个数据并返回,该序列可以是list、tuple、str、set
车架号从"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"中随机抽取一个数据
车辆状态分为:run、stop、charging
充电状态分为:not charged、charging、charge complete
SOC低报警分为:normal、Less than 20%、Less than 20%
所有数据均为随机抽取的
random.uniform:在 [x,y] 范围内,随机生成一个实数
time.strftime:读取当前时间
time.localtime:格式化时间戳为本地的时间
三、将数据写入json文件
过程:首先我们打开一个文件用于追加,如果该文件不存在,就创建新文件进行写入,然后用当前时间给文件命名,当文件大小大于100M时,我们将数据写入下一个文件,文件以json的形式保存。
# 写入数据到文件
def write_data_to_file(data, file_path):
with open(file_path, 'a') as f:
f.write(json.dumps(data) + '\n')
# 获取文件大小
def get_file_size(file_path):
if os.path.exists(file_path):
return os.path.getsize(file_path)
else:
return 0
# 获取文件名
def get_file_name():
return 'can-' + time.strftime('%Y-%m-%d', time.localtime(time.time())) + '.json'
# 获取文件路径
def get_file_path():
file_name = get_file_name()
file_path = file_name
i = 1
while get_file_size(file_path) > 10240:
file_path = file_name + '.' + str(i)
i += 1
return file_path
# 生成数据并写入文件
def generate_and_write_data():
for i in range(20):
data = generate_data()
write_data_to_file(data, get_file_path())
time.sleep(0.5)
for i in range(20):
data = generate_data()
write_data_to_file(data, get_file_path())
time.sleep(2)
write_data_to_file(data, get_file_path())
for i in range(10):
data = generate_data()
data['time'] = '2023-6-23 23:59:59'
write_data_to_file(data, get_file_path())
if __name__ == '__main__':
generate_and_write_data()with open() as f相关参数:
r:以只读方式打开文件
rb:以二进制格式打开一个文件用于只读
r+:打开一个文件用于读写
rb+:以二进制格式打开一个文件用于读写
w:打开一个文件只用于写入
wb:以二进制格式打开一个文件只用于写入
w+:打开一个文件用于读写
wb+:以二进制格式打开一个文件用于读写
a:打开一个文件用于追加,如果该文件不存在,创建新文件进行写入
ab:以二进制格式打开一个文件用于追加,如果该文件不存在,创建新文件进行写入
a+:打开一个文件用于读写,如果该文件不存在,创建新文件用于读写
ab+:以二进制格式打开一个文件用于追加,如果该文件不存在,创建新文件用于读写
json.dumps:将python对象转换为json字符串
os.path.exists():判断括号里的文件是否存在
os.path.getsize():获取文件大小
while return:return 的作用是退出循环体所在的函数
for i in range () :给 i 赋值,range (20) 即:从0到20,不包含20
time sleep(): 推迟调用线程的运行,可通过参数secs指秒数,表示进程挂起的时间,sleep(2)表示推迟执行2秒
JSON文件:JSON是一种轻量级的数据交换格式。它基于 ECMAScript的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。C、Python、C++、Java、PHP、Go等编程语言都支持 JSON,它一共有三种形式:简单值的形式、对象形式、数组形式
四、将文件写入HDFS
1、下载pyhdfs
pip install pyhdfs2、将文件写入HDFS中
from pyhdfs import HdfsClient
client = HdfsClient(hosts='master:50070',user_name='root')
client.copy_from_local('/visualization/Hadoop/can-2023-06-24.json','/1')#本地文件绝对路径,HDFS目录必须不存在hosts的参数为hdfs的url,user_name是本机的用户可以使用hadoop的用户。
copy_from_local的第一个参数为本地路径,第二个参数为HDFS的路径,且这个路径不能已经存在。
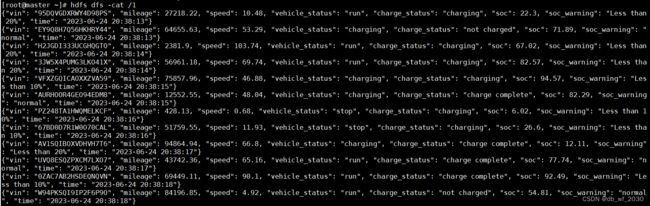
我们可以通过终端命令查看文件内容
hdfs dfs -cat /1
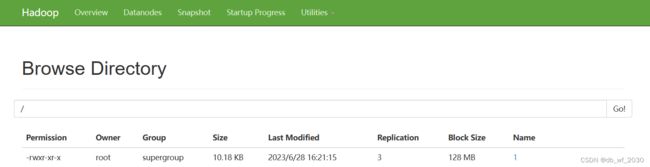
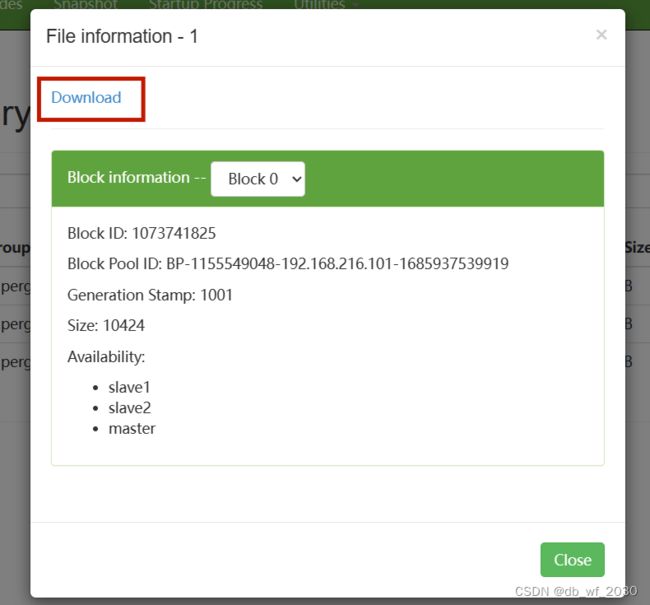
还可以通过网页查看HDFS上的文件(这里不能查看文件内容,想要从这里查看文件内容可以下载文件)
虚拟机IP:50070 图形化界面
五、总结
在这里简单的介绍了数据的生成和如何将文件写入HDFS,希望能给大家带来帮助,本人是个还在学习的小白,有不对的地方还请大家多多指点。