Pytorch面试题整理(2023.09.10)
1、pytorch如何微调fine tuning?
在加载了预训练模型参数之后,需要finetuning 模型,可以使用不同方式finetune。
- 局部微调:加载了模型参数后,只想调节最后几层,其他层不训练,也就是不进行梯度计算,pytorch提供的requires_grad使得对训练的控制变得非常简单。
model = torchvision.models.resnet18(pretrained=True) for param in model.parameters(): param.requires_grad = False # 替换最后的全连接层, 改为训练100类 # 新构造的模块的参数默认requires_grad为True model.fc = nn.Linear(512, 100) # 只优化最后的分类层 optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9) - 全局微调:对全局微调时,只不过我们希望改换过的层和其他层的学习速率不一样,这时候把其他层和新层在optimizer中单独赋予不同的学习速率。
ignored_params = list(map(id, model.fc.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params,
model.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': model.fc.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
2、Pytorch如何使用多gpu?
- model.gpu()把模型放在gpu上。
- model = nn . DataParallel ( model ) ,DataParallel并行的方式,是将输入一个batch的数据均分成多份,分别送到对应的GPU进行计算,各个GPU得到的梯度累加。与Module相关的所有数据也都会以对模型和相应的数据进行.cuda()处理,可以将内存中的数据复制到gpu显存中去。
3、Pytorch如何实现大部分layer?
pytorch可以实现大部分layer,这些层都继承于nn.Module。如nn.Conv2卷积层;AvgPool, Maxpool, AdaptiveAvgPool平均池化,最大池化; TransposeConv逆卷积; nn.Linear全连接层; nn.BatchNorm1d(1d,2d,3d)归一化层; nn.dropout; nn.ReLU; nn.Sequential。
net1 = nn.Sequential()
net1.add_module("conv1", nn.Conv2d(3,3,3))## add_module
net1.add_module("BatchNormalization", nn.BatchNorm2d(3))
net1.add_module('activation_layer', nn.ReLU())
net2 = nn.Sequential(nn.Conv2d(3,3,3),
nn.BatchNorm2d(3),
nn.Relu())
from collections import OrderedDict
net3 = nn.Sequential(OrderedDict([("conv1", nn.Conv2d(3,3,3)),
("BatchNormalization", nn.BatchNorm2d(3)),
("activation_layer", nn.Relu())]))
4、nn.Module与autograd的区别。
- autograd.Function利用了Tensor对autograd技术的扩展,为autograd实现了新的运算操作,不仅要实现前向传播还要手动实现反向传播
- nn.Module利用了autograd技术,对nn的功能进行扩展,实现了深度学习中更多的层,只需实现前向传播功能,autograd会自动实现反向传播。
- nn.functional是一些autograd操作的集合,是经过封装的函数。
5、inplace的理解
- Pytorch不推荐使用inplace。
- inplace操作:inplace指的是在不更改变量的内存地址的情况下,直接修改变量的值。即指进行原地操作,选择进行原地覆盖运算。当使用 inplace=True后,对于上层网络传递下来的tensor会直接进行修改,改变输入数据,具体意思如下面例子所示:修改输入的数据
a = torch.tensor([1.0, 3.0], requires_grad=True)
b = a + 2
print(b._version) # 0
loss = (b * b).mean()
b[0] = 1000.0
print(b._version) # 1
loss.backward()
# RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation ...
6、nn.Functional和nn.Module
- 高层API方法:使用torch.nn.****实现
- 低层API方法:使用低层函数方法,torch.nn.functional.****实现
- nn.Module实现的layers是一个特殊的类,都是由class layer(nn.Module)定义,会自动提取可学习的参数。
- nn.functional中的函数更像是纯函数,由def function(input)定义,也就是说如果模型有可学习的参数,最好用nn.Module,否则使用哪个都可以,二者在性能上没有多大的差异。
- 对于卷积,全连接等具有可学习参数的网络建议使用nn.Module
激活函数(ReLU,sigmoid,tanh),池化等可以使用functional替代。
对于不具有可学习参数的层,将他们用函数代替,这样可以不用放在构造函数__init__中。
7、Pytorch数据
- 数据:数据集对象被抽象为Dataset类,自定义需要继承Dataset类,并实现两个方法:①getitem:返回一条数据,或一个样本,obj[idx]等价于obj.getitem(idex)。②len:返回样本数量,len(obj)等价于obj.len()。③Dataset只负责数据的抽象,一次调用__getitem__只返回一个样本,若对batch操作或者对数据shuffle和并行加速,需要使用DataLoader。
- dataloader是一个可迭代的对象,我们可以像使用迭代器一样使用它。
8、自定义层的步骤。
要实现一个自定义层大致分为以下几个主要步骤:
- 自定义一个类,继承自Module类,并且一定要实现两个基本函数,第一个构造函数__init__,第二个是层的逻辑运算函数,即所谓的前向计算函数forward函数。 __init__函数和 forward函数。
- 在构造函数__init__中实现层的参数定义。比如Linear层的权重和偏置,Conv2d层的in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode='zeros’这一系列参数。
- 在前向传播forward函数里面实现前向运算。这一般都是通过torch.nn.functional.***函数来实现,当然很多时候我们也需要自定义自己的运算方式。如果该层含有权重,那么权重必须是nn.Parameter类型,关于Tensor和Variable(0.3版本之前)与Parameter的区别请参阅相关的文档。简单说就是Parameter默认需要求导,其他两个类型则不会。另外一般情况下,可能的话,为自己定义的新层提供默认的参数初始化,以防使用过程中忘记初始化操作。
- 一般情况下,我们定义的参数是可以求导的,但是自定义操作如不可导,需要实现backward函数。
9、nn.ModuleList和nn.Sequential的不同
- nn.ModuleList并没有定义一个网络,它只是将不同模块存储在一起,这些模块之间并没有什么先后顺序可言。
- nn.Sequential实现了内部的forward函数,并且里面的模块必须是按照顺序进行排列的,所以我们必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。
-
nn.Sequential 里面的顺序是你想要的,而且不需要再添加一些其他处理的函数 (比如nn.functional 里面的函数,nn 与 nn.functional 有什么区别? ),那么完全可以直接用 nn.Sequential。这么做的代价就是失去了部分灵活性,毕竟不能自己去定制 forward 函数里面的内容了。一般情况下 nn.Sequential 的用法是来组成卷积块 (block),然后像拼积木一样把不同的 block 拼成整个网络,让代码更简洁,更加结构化。
10、apply-参数初始化
Pytorch中对卷积层和批归一化层权重进行初始化,也就是weight和bias,主要会用到torch的apply()函数。
- apply(fn):将fn函数递归地应用到网络模型的每个子模型中,主要用在参数初始化,使用apply()时,需要先定义一个参数初始化的函数。
def weight_init(m):
classname = m.__class__.__name__ # 得到网络层的名字,如ConvTranspose2d
if classname.find('Conv') != -1: # 使用了find函数,如果不存在返回值为-1,所以让其不等于-1
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
model = net()
model.apply(weight_init)
11、Sequential三种实现方法
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
print(model)
print(model[2]) # 通过索引获取第几个层
'''运行结果为:
Sequential(
(0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(3): ReLU()
)
Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
'''
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
print(model)
print(model[2]) # 通过索引获取第几个层
'''运行结果为:
Sequential(
(0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(3): ReLU()
)
Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
'''
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential()
model.add_module("conv1",nn.Conv2d(1,20,5))
model.add_module('relu1', nn.ReLU())
model.add_module('conv2', nn.Conv2d(20,64,5))
model.add_module('relu2', nn.ReLU())
print(model)
print(model[2]) # 通过索引获取第几个层
12、计算图
计算图通常包含两种元素,一个是tensor,另一个是Function。Function指的是计算图中某个节点(node)所进行的运算,比如加减乘除卷积等等。Function内部有forward()和backward()两个方法,分别应用于正向、反向传播。
a = torch.tensor(2.0, requires_grad=True)
b = a.exp()
print(b)
# tensor(7.3891, grad_fn=)
- 举例:模型设计:
l1 = input x w1
l2 = l1 + w2
l3 = l1 x w3
l4 = l2 x l3
loss = mean(l4) - input 其实很像神经网络输入的图像,w1, w2, w3 则类似卷积核的参数,而 l1, l2, l3, l4 可以表示4个卷积层输出,如果我们把节点上的加法乘法换成卷积操作的话。
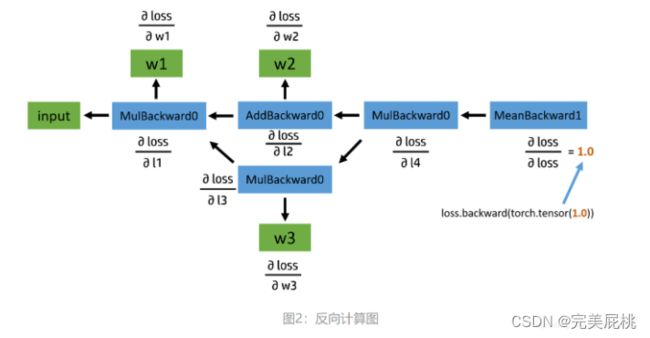
input = torch.ones([2, 2], requires_grad=False) w1 = torch.tensor(2.0, requires_grad=True) w2 = torch.tensor(3.0, requires_grad=True) w3 = torch.tensor(4.0, requires_grad=True) l1 = input * w1 l2 = l1 + w2 l3 = l1 * w3 l4 = l2 * l3 loss = l4.mean() print(w1.data, w1.grad, w1.grad_fn) # tensor(2.) None None print(l1.data, l1.grad, l1.grad_fn) # tensor([[2., 2.], # [2., 2.]]) Noneprint(loss.data, loss.grad, loss.grad_fn) # tensor(40.) None 需要注意的是,我们给定的 w 们都是一个常数,利用了广播的机制实现和常数和矩阵的加法乘法,比如 w2 + l1,实际上我们的程序会自动把 w2 扩展成 [[3.0, 3.0], [3.0, 3.0]],和 l1 的形状一样之后,再进行加法计算,计算的导数结果实际上为 [[2.0, 2.0], [2.0, 2.0]],为了对应常数输入,所以最后 w2 的梯度返回为矩阵之和 8 。另外还有一个问题,虽然 w 开头的那些和我们的计算结果相符,但是为什么 l1,l2,l3,甚至其他的部分的求导结果都为空呢?
- 因为对于任意一个张量来说,我们可以用 tensor.is_leaf 来判断它是否是叶子张量(leaf tensor)。在反向传播过程中,只有 is_leaf=True 的时候,需要求导的张量的导数结果才会被最后保留下来。
- 叶子张量:对于 requires_grad=False 的 tensor 来说,我们约定俗成地把它们归为叶子张量。但其实无论如何划分都没有影响,因为张量的 is_leaf 属性只有在需要求导的时候才有意义。我们真正需要注意的是当 requires_grad=True 的时候,如何判断是否是叶子张量:当这个 tensor 是用户创建的时候,它是一个叶子节点,当这个 tensor 是由其他运算操作产生的时候,它就不是一个叶子节点。
a = torch.ones([2, 2], requires_grad=True)
print(a.is_leaf)
# True
b = a + 2
print(b.is_leaf)
# False
# 因为 b 不是用户创建的,是通过计算生成的
- 为什么要搞出这么个叶子张量的概念出来?原因是为了节省内存(或显存)。我们来想一下,那些非叶子结点,是通过用户所定义的叶子节点的一系列运算生成的,也就是这些非叶子节点都是中间变量,一般情况下,用户不会去使用这些中间变量的导数,所以为了节省内存,它们在用完之后就被释放了。有办法保留中间变量的导数吗?当然有,通过使用 tensor.retain_grad() 就可以:
# 和前边一样
# ...
loss = l4.mean()
l1.retain_grad()
l4.retain_grad()
loss.retain_grad()
loss.backward()
print(loss.grad)
# tensor(1.)
print(l4.grad)
# tensor([[0.2500, 0.2500],
# [0.2500, 0.2500]])
print(l1.grad)
# tensor([[7., 7.],
# [7., 7.]])
13、requires_grad
当我们创建一个张量 (tensor) 的时候,如果没有特殊指定的话,那么这个张量是默认是不需要求导的。我们可以通过 tensor.requires_grad 来检查一个张量是否需要求导。在张量间的计算过程中,如果在所有输入中,有一个输入需要求导,那么输出一定会需要求导;相反,只有当所有输入都不需要求导的时候,输出才会不需要 。
- 举一个比较简单的例子,比如我们在训练一个网络的时候,我们从 DataLoader 中读取出来的一个 mini-batch 的数据,这些输入默认是不需要求导的,其次,网络的输出我们没有特意指明需要求导吧,Ground Truth 我们也没有特意设置需要求导吧。这么一想,哇,那我之前的那些 loss 咋还能自动求导呢?其实原因就是上边那条规则,虽然输入的训练数据是默认不求导的,但是,我们的 model 中的所有参数,它默认是求导的,这么一来,其中只要有一个需要求导,那么输出的网络结果必定也会需要求的。
- 在写代码的过程中,不要把网络的输入和 Ground Truth 的 requires_grad 设置为 True。虽然这样设置不会影响反向传播,但是需要额外计算网络的输入和 Ground Truth 的导数,增大了计算量和内存占用不说,这些计算出来的导数结果也没啥用。因为我们只需要神经网络中的参数的导数,用来更新网络,其余的导数都不需要。
input = torch.randn(8, 3, 50, 100)
print(input.requires_grad)
# False
net = nn.Sequential(nn.Conv2d(3, 16, 3, 1),
nn.Conv2d(16, 32, 3, 1))
for param in net.named_parameters():
print(param[0], param[1].requires_grad)
# 0.weight True
# 0.bias True
# 1.weight True
# 1.bias True
output = net(input)
print(output.requires_grad)
# True
14、把网络参数的 requires_grad 设置为 False 会怎么样?
同样的网络在训练的过程中冻结部分网络,让这些层的参数不再更新,这在迁移学习中很有用处。
input = torch.randn(8, 3, 50, 100)
print(input.requires_grad)
# False
net = nn.Sequential(nn.Conv2d(3, 16, 3, 1),
nn.Conv2d(16, 32, 3, 1))
for param in net.named_parameters():
param[1].requires_grad = False
print(param[0], param[1].requires_grad)
# 0.weight False
# 0.bias False
# 1.weight False
# 1.bias False
output = net(input)
print(output.requires_grad)
# False
只更新FC层:
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# 用一个新的 fc 层来取代之前的全连接层
# 因为新构建的 fc 层的参数默认 requires_grad=True
model.fc = nn.Linear(512, 100)
# 只更新 fc 层的参数
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
# 通过这样,我们就冻结了 resnet 前边的所有层,
# 在训练过程中只更新最后的 fc 层中的参数。
15、反向传播的流程
loss.backward();optimizer.step() 权重更新;optimizer.zero_grad() 导数清零–必须的
class Simple(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, padding=1, bias=False)
self.conv2 = nn.Conv2d(16, 32, 3, 1, padding=1, bias=False)
self.linear = nn.Linear(32*10*10, 20, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.linear(x.view(x.size(0), -1))
return x
# 创建一个很简单的网络:两个卷积层,一个全连接层
model = Simple()
# 为了方便观察数据变化,把所有网络参数都初始化为 0.1
for m in model.parameters():
m.data.fill_(0.1)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1.0)
model.train()
# 模拟输入8个 sample,每个的大小是 10x10,
# 值都初始化为1,让每次输出结果都固定,方便观察
images = torch.ones(8, 3, 10, 10)
targets = torch.ones(8, dtype=torch.long)
output = model(images)
print(output.shape)
# torch.Size([8, 20])
loss = criterion(output, targets)
print(model.conv1.weight.grad)
# None
loss.backward()###############################################################
print(model.conv1.weight.grad[0][0][0])
# tensor([-0.0782, -0.0842, -0.0782])
# 通过一次反向传播,计算出网络参数的导数,
# 因为篇幅原因,我们只观察一小部分结果
print(model.conv1.weight[0][0][0])
# tensor([0.1000, 0.1000, 0.1000], grad_fn=)
# 我们知道网络参数的值一开始都初始化为 0.1 的
optimizer.step()###########################################################
print(model.conv1.weight[0][0][0])
# tensor([0.1782, 0.1842, 0.1782], grad_fn=)
# 回想刚才我们设置 learning rate 为 1,这样,
# 更新后的结果,正好是 (原始权重 - 求导结果) !
optimizer.zero_grad()############每次更新完权重之后,我们记得要把导数清零啊,
# 不然下次会得到一个和上次计算一起累加的结果。
print(model.conv1.weight.grad[0][0][0])
# tensor([0., 0., 0.])
# 每次更新完权重之后,我们记得要把导数清零啊,
# 不然下次会得到一个和上次计算一起累加的结果。
# 当然,zero_grad() 的位置,可以放到前边去,
# 只要保证在计算导数前,参数的导数是清零的就好。
16、detach
- 如果一个 tensor 的 requires_grad=True 的话,我们不能直接使用 numpy() ,否则会报错:RuntimeError: Can’t call numpy() on Variable that requires grad. Use var.detach().numpy() instead.因此我们需要先用 detach() 返回 tensor requires_grad=False 的版本,再进行转换。
- 在 0.4.0 版本以前,.data 是用来取 Variable 中的 tensor 的,但是之后 Variable 被取消,.data 却留了下来。现在我们调用 tensor.data,可以得到 tensor的数据 + requires_grad=False 的版本,而且二者共享储存空间,也就是如果修改其中一个,另一个也会变。因为 PyTorch 的自动求导系统不会追踪 tensor.data 的变化,所以使用它的话可能会导致求导结果出错。官方建议使用 tensor.detach() 来替代它,二者作用相似,但是 detach 会被自动求导系统追踪,使用起来很安全 .
多说无益,我们来看个例子吧:
这个导数计算的结果明显是错的,但没有任何提醒,之后再 Debug 会非常痛苦。所以,建议大家都用 tensor.detach()。
a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=)
loss = torch.mean(b * b)
b_ = b.detach()
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=)
# 储存空间共享,修改 b_ , b 的值也变了
loss.backward()
# RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
这个例子中,b 是用来计算 loss 的一个变量,我们在计算完 loss 之后,进行反向传播之前,修改 b 的值。这么做会导致相关的导数的计算结果错误,因为我们在计算导数的过程中还会用到 b 的值,但是它已经变了(和正向传播过程中的值不一样了)。在这种情况下,PyTorch 选择报错来提醒我们。但是,如果我们使用 tensor.data 的时候,结果是这样的:
a = torch.tensor([7., 0, 0], requires_grad=True)
b = a + 2
print(b)
# tensor([9., 2., 2.], grad_fn=)
loss = torch.mean(b * b)
b_ = b.data
b_.zero_()
print(b)
# tensor([0., 0., 0.], grad_fn=)
loss.backward()
print(a.grad)
# tensor([0., 0., 0.])
# 其实正确的结果应该是:
# tensor([6.0000, 1.3333, 1.3333])
17、tensor-numpy
使用GPU还有一个点,在我们想要GPUtensor转换成Numpy变量的时候,需要先将tensor转换到CPU中去,因为Numpy是CPU-only。其次,如果tensor需要求导的话,还需要加一步detach,再转成Numpy。
18、tensor.item()
- 提取loss的纯数值时,常常用到loss.item(),其返回值是一个Python数值(Python number)。不像从tensor转到numpy(需要考虑 tensor 是在 cpu,还是 gpu,需不需要求导),无论什么情况,都直接使用item()就完事了,如果需要从 gpu 转到 cpu 的话,PyTorch 会自动帮你处理。
- 但注意 item() 只适用于 tensor 只包含一个元素的时候。因为大多数情况下我们的 loss 就只有一个元素,所以就经常会用到 loss.item()。如果想把含多个元素的 tensor 转换成 Python list 的话,要使用 tensor.tolist()。
x = torch.randn(1, requires_grad=True, device='cuda')
print(x)
# tensor([-0.4717], device='cuda:0', requires_grad=True)
y = x.item()
print(y, type(y))
# -0.4717346727848053
x = torch.randn([2, 2])
y = x.tolist()
print(y)
# [[-1.3069953918457031, -0.2710231840610504], [-1.26217520236969, 0.5559719800949097]]
19、torch.backends.cudnn.benchmark=True
设置 torch.backends.cudnn.benchmark=True 将会让程序在开始时花费一点额外时间,为整个网络的**每个卷积层搜索最适合它的卷积实现算法,进而实现网络的加速。**适用场景是网络结构固定(不是动态变化的),网络的输入形状(包括 batch size,图片大小,输入的通道)是不变的,其实也就是一般情况下都比较适用。反之,如果卷积层的设置一直变化,将会导致程序不停地做优化,反而会耗费更多的时间。
20、静态图和动态图
- PyTorch 使用的是动态图(Dynamic Computational Graphs)的方式,而 TensorFlow 使用的是静态图(Static Computational Graphs)
- 动态图,就是每次当我们搭建完一个计算图,然后在反向传播结束之后,整个计算图就在内存中被释放了。如果想再次使用的话,必须从头再搭一遍。
# 这是一个关于 PyTorch 是动态图的例子:
a = torch.tensor([3.0, 1.0], requires_grad=True)
b = a * a
loss = b.mean()
loss.backward() # 正常
loss.backward() # RuntimeError
# 第二次:从头再来一遍
a = torch.tensor([3.0, 1.0], requires_grad=True)
b = a * a
loss = b.mean()
loss.backward() # 正常
- 以 TensorFlow 为代表的静态图**,每次都先设计好计算图,需要的时候实例化这个图,然后送入各种输入,重复使用,只有当会话结束的时候创建的图才会被释放。
- 理论上来说,静态图在效率上比动态图要高。因为首先,静态图只用构建一次,然后之后重复使用就可以了;其次静态图因为是固定不需要改变的,所以在设计完了计算图之后,可以进一步的优化,比如可以将用户原本定义的 Conv 层和 ReLU 层合并成 ConvReLU 层,提高效率。
- 但是,深度学习框架的速度不仅仅取决于图的类型,还很其他很多因素,比如底层代码质量,所使用的底层 BLAS 库等等等都有关。从实际测试结果来说,至少在主流的模型的训练时间上,PyTorch 有着至少不逊于静态图框架 Caffe,TensorFlow 的表现。
- 除了动态图之外,PyTorch 还有一个特性,叫 eager execution。意思就是当遇到 tensor 计算的时候,马上就回去执行计算,也就是,实际上 PyTorch 根本不会去构建正向计算图,而是遇到操作就执行。真正意义上的正向计算图是把所有的操作都添加完,构建好了之后,再运行神经网络的正向传播。
- 动态图和 eager execution,所以它用起来才这么顺手,简直就和写 Python 程序一样舒服,debug 也非常方便。除此之外,我们从之前的描述也可以看出,PyTorch 十分注重占用内存(或显存)大小,没有用的空间释放很及时,可以很有效地利用有限的内存。