Web 抓取:如何在 Playwright 中阻止资源
目录
Playwright 简介
记录网络事件
阻塞资源
按 Glob 模式阻止
按正者表达式阻止
按资源类型阻止
函数处理程序
衡量绩效提升
HAR Files
有一些HAR 可视化工具,但最简单的方法是使用 Chrome DevTools。打开网络选项卡并单击导入按钮或拖放 HAR 文件。
浏览器的性能 API
CDP
结论
要使代码正常工作,您需要安装 python3。有些系统已经预装了它。之后,安装 Playwright 和适用于 Chromium、Firefox 和 WebKit 的浏览器二进制文件。
pip install playwright
playwright installPlaywright 简介
Playwright “是一个 Python 库,可通过单个 API 自动化 Chromium、Firefox 和 WebKit 浏览器。” 它允许我们以编程方式使用无头浏览器浏览 Internet。
Playwright 也可用于 Node.js,下面显示的所有内容都可以使用类似的语法完成。查看文档以获取更多详细信息。
下面是如何在几行中启动浏览器(即 Chromium)、导航到页面并获取其标题。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://www.zenrows.com/")
print(page.title())
# Web Scraping API & Data Extraction - ZenRows
page.context.close()
browser.close()记录网络事件
订阅请求或响应等事件并记录它们的内容以查看发生了什么。由于我们没有另外告诉 Playwright,它将加载整个页面:HTML、CSS、执行 Javascript、获取图像等。在请求页面之前添加这两行,看看是怎么回事。
page.on("request", lambda request: print(
">>", request.method, request.url,
request.resource_type))
page.on("response", lambda response: print(
"<<", response.status, response.url))
page.goto("https://www.zenrows.com/")
# >> GET https://www.zenrows.com/ document
# << 200 https://www.zenrows.com/
# >> GET https://cdn.zenrows.com/images_dash/logo-instagram.svg image
# << 200 https://cdn.zenrows.com/images_dash/logo-instagram.svg
# ... and many more 整个输出将近 50 行,包含 24 个资源请求。我们可能不需要其中的大部分用于网站抓取,因此我们将了解如何阻止它们并节省时间和带宽。
阻塞资源
为什么要加载我们不会使用的资源和内容?了解如何使用这些技术避免不必要的数据和网络请求。
-
按 Glob 模式阻止
page还公开了一个方法,该方法route将为每个匹配的路由或模式执行处理程序。假设我们不想加载 SVG。使用类似的模式"**/*.svg"将匹配以该扩展名结尾的请求。至于处理程序,我们暂时不需要逻辑,只需中止请求即可。为此,我们将使用 lambda 和route参数的 abort 方法。page.route("**/*.svg", lambda route: route.abort()) page.goto("https://www.zenrows.com/")注意:根据官方文档,像这样的模式
"**/*.{png,jpg,jpeg}"应该有效,但我们发现并非如此。不管怎样,用下一个阻塞策略是可行的。 -
按正者表达式阻止
如果(出于某种原因)你喜欢正则表达式,请随意使用它们。但是首先编译它们是强制性的。在这种情况下,我们将阻止三个图像扩展。正则表达式很棘手,但它们提供了大量的灵活性。
import re # ... page.route(re.compile(r"\.(jpg|png|svg)$"), lambda route: route.abort()) page.goto("https://www.zenrows.com/")现在有 23 个请求,只有 15 个响应。我们保存了 8 张图片免于下载!
-
按资源类型阻止
但是如果他们使用“jpeg”扩展名而不是“jpg”会发生什么?还是avif、gif、webp?我们应该维护更新列表吗?
对我们来说幸运的是,
route上面 lambda 函数中公开的参数包括原始请求和资源类型。其中一种类型是image,完美!您可以访问整个资源类型列表。我们现在将匹配每个请求 (
"**/*") 并将条件逻辑添加到 lambda 函数。如果是图像,请像以前一样中止请求。否则,照常继续。page.route("**/*", lambda route: route.abort() if route.request.resource_type == "image" else route.continue_() ) page.goto("https://www.zenrows.com/")考虑到一些跟踪器使用图像。抓取或测试时可能没什么大不了的,但以防万一。
-
函数处理程序
我们还可以为处理程序定义函数而不是使用 lambda。这在我们需要重用它或它超过单个条件时会派上用场。
假设我们现在想积极地阻止。查看之前运行的输出将显示已用资源的列表。我们会将它们添加到列表中,然后检查该类型是否在该列表中。
excluded_resource_types = ["stylesheet", "script", "image", "font"] def block_aggressively(route): if (route.request.resource_type in excluded_resource_types): route.abort() else: route.continue_() # ... page.route("**/*", block_aggressively) page.goto("https://www.zenrows.com/")我们现在完全处于控制之中,多功能性是绝对的。从
routes.request,可以使用原始 URL、标题和其他一些信息。更加严格:阻止所有非
document类型的内容。这将有效地防止除初始 HTML 之外的任何内容被加载。def block_aggressively(route): if (route.request.resource_type != "document"): route.abort() else: route.continue_()现在只有一个响应!我们在没有下载任何其他资源的情况下获得了 HTML。我们确实节省了很多时间和带宽,对吧?但是……具体是多少?
衡量绩效提升
我们只能说,如果我们能够衡量差异,它就会变得更好。我们将看看三种方法。但是只需运行一个包含多个 URL 的脚本就可以了。剧透:我们为 10 个 URL 做了这个,1.3 秒 VS 8.4。
HAR Files
对于那些习惯查看 DevTools 网络选项卡的人,我们有好消息!Playwright 通过在方法中提供一个额外的参数来允许 HAR 记录new_page。就这么简单。
page = browser.new_page(record_har_path="playwright_test.har")
page.goto("https://www.zenrows.com/")有一些HAR 可视化工具,但最简单的方法是使用 Chrome DevTools。打开网络选项卡并单击导入按钮或拖放 HAR 文件。
检查时间!下面是两个不同的 HAR 文件之间的比较。第一个是无阻塞(常规导航)。第二个是阻止除初始文档之外的所有内容。
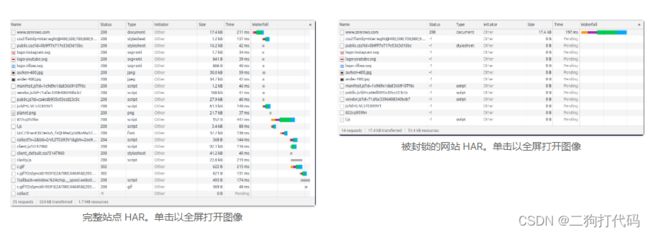
几乎每个资源在阻塞端都有一个“-1”状态和“待定”时间。这是 DevTools 告诉我们那些被阻止且未下载的方式。在左下方我们可以清楚地看到我们执行的请求变少了,传输的数据量是原来的零头!从 524kB 到 17.4kB,减少了 96%。
浏览器的性能 API
浏览器提供了一个界面来检查性能,显示它在计时等方面的表现。Playwright 可以评估 Javascript,因此我们将使用它来打印这些结果。
输出将是一个带有大量时间戳的 JSON 对象。navigationStart最直接的检查是获取和之间的差异loadEventEnd。阻塞时,应在半秒以下(即346ms);对于常规导航,超过一秒甚至两秒(即 1363 毫秒)。
page.goto("https://www.zenrows.com/")
print(page.evaluate("JSON.stringify(window.performance)"))
# {"timing":{"connectStart":1632902378272,"navigationStart":1632902378244, ...如您所见,阻塞可以快一秒,对于速度较慢的站点甚至更快。下载的越少,抓取的速度就越快!
CDP
更进一步,我们直接连接Chrome DevTools Protocol。Playwright 创建了一个CDP 会话供我们提取,例如,性能指标。
我们必须从页面上下文创建一个客户端并开始与 CDP 通信。在我们的例子中,我们将在访问页面之前启用“性能”并在之后获取指标。
输出将是一个类似 JSON 的字符串,其中包含有趣的值,例如节点、处理时间、使用的 JS 堆等等。
client = page.context.new_cdp_session(page)
client.send("Performance.enable")
page.goto("https://www.zenrows.com/")
print(client.send("Performance.getMetrics"))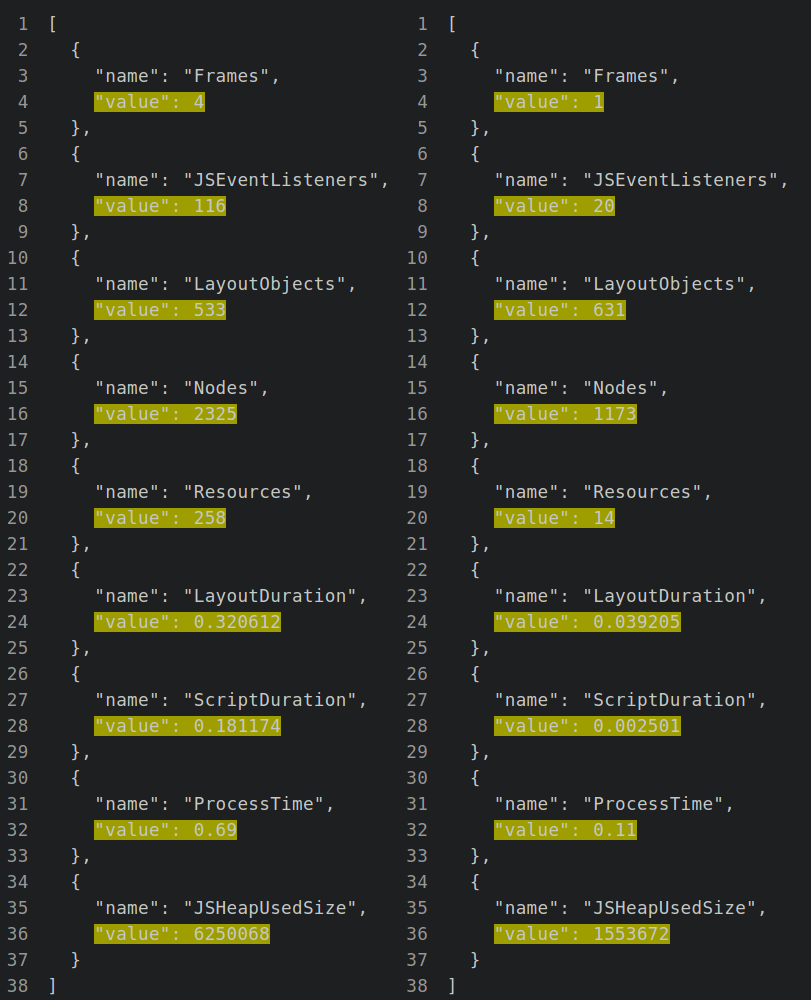
结论
- 只加载需要的资源。
- 尽可能节省时间和带宽。
- 在扩大规模之前衡量您的努力和绩效。
我们不要忘记,网站抓取是一个包含多个步骤的过程,其中之一是轮换代理。这些会增加处理时间,有时还会按带宽收费。
您可以获得完全相同的结果,同时节省时间/带宽/金钱。很多时候,图像或 CSS 只是开销。其他一些,如果您只想要初始静态内容,则不需要 JS。