- 分区表
- partition by
- case when then end
- if else
- 日期:Date,Timestamp,text,String互转
- 时间获取周,月等
- 自增序列
- 创建表,删除表
- 修改表,默认值,重命名列,修改列类型
- 时间序列
- 聚合等,
- 日月周统计
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;
select json_build_object(0,1,2,3);
createdb mydb;
dropdb mydb;
SELECT version(),current_date;
CREATE TABLE weather (
city varchar(80),
temp_lo int,
temp_hi int,
prcp real,
date date
);
CREATE TABLE cities (
name varchar(80),
location point
);
DROP TABLE weather;
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
SELECT * FROM ops.t_application_properties
SELECT DISTINCT city FROM weather order by city;
SELECT * FROM weather;
SELECT * FROM weather, cities WHERE city = name;
SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
SELECT city, max(temp_lo) FROM weather GROUP BY city;
SELECT city, max(temp_lo) FROM weather GROUP BY city HAVING max(temp_lo) < 40;
SELECT city, max(temp_lo) FROM weather city LIKE 'S%' GROUP BY city HAVING max(temp_lo) < 40;
UPDATE weather SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2 WHERE date > '1994-11-28';
DELETE FROM weather WHERE city = 'Hayward';
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY salary DESC) FROM empsalary;
select 'Dianne''s horse',E'Dianne\'s horse',$$Dianne's horse$$
-- 一个转义字符串常量可以通过在开单引号前面写一个字母E(大写或小写形式)来指定
select E'\b' as 退格,E'\f' as 换页,E'\n' 换行,E'\r' 回车,E'\t' 制表符,E'\o, \oo, \ooo (o = 0–7)' 八进制字节值
select 2^3,sqrt(2);
-- 聚合函数 根据某个字段排序后在聚合
SELECT array_agg(city ORDER BY prcp DESC) FROM weather;
SELECT string_agg(city, ',' ORDER BY city) FROM weather;
-- 直接聚合,并且以''字符串连接
select string_agg('''' || "city" || '''',',') from weather;
SELECT
count(*) AS unfiltered,
count(*) FILTER (WHERE i < 5) AS filtered
FROM generate_series(1,10) AS s(i);
-- generate_series生成序列
SELECT * FROM generate_series(1,10);
-- CROSS JOIN,INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL OUTER JOIN的区别
CREATE TABLE foo (fooid int, foosubid int, fooname text);
CREATE FUNCTION getfoo(int) RETURNS SETOF foo AS $$
SELECT * FROM foo WHERE fooid = $1;
$$ LANGUAGE SQL;
SELECT * FROM getfoo(1) AS t1;
SELECT * FROM foo
WHERE foosubid IN (
SELECT foosubid
FROM getfoo(foo.fooid) z
WHERE z.fooid = foo.fooid
);
CREATE VIEW vw_getfoo AS SELECT * FROM getfoo(1);
SELECT * FROM vw_getfoo;
-- json_to_recordset & generate_series
SELECT *
FROM ROWS FROM
(
json_to_recordset('[{"a":40,"b":"foo"},{"a":"100","b":"bar"}]')
AS (a INTEGER, b TEXT),
generate_series(1, 3)
) AS x (p, q, s)
ORDER BY p;
-- 计算每种商品的销售额
SELECT product_id, p.name, (sum(s.units) * p.price) AS sales
FROM products p LEFT JOIN sales s USING (product_id)
GROUP BY product_id, p.name, p.price;
-- 计算近4周的产品id,名称及利润
SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit
FROM products p LEFT JOIN sales s USING (product_id)
WHERE s.date > CURRENT_DATE - INTERVAL '4 weeks'
GROUP BY product_id, p.name, p.price, p.cost
HAVING sum(p.price * s.units) > 5000;
-- 聚合分组
SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%'
-- 数组
CREATE TABLE arr(f1 int[], f2 int[]);
INSERT INTO arr VALUES (ARRAY[[1,2],[3,4]], ARRAY[[5,6],[7,8]]);
SELECT ARRAY[f1, f2, '{{9,10},{11,12}}'::int[]] FROM arr;
SELECT ARRAY[]::integer[],ARRAY[1,2,3+4],ARRAY[1,2,22.7]::integer[],ARRAY[ARRAY[1,2],ARRAY[3,4]],ARRAY(SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%');
SELECT ARRAY(SELECT ARRAY[i, i*2] FROM generate_series(1,5) AS a(i));
--复杂的case when计算
SELECT CASE WHEN min(employees) > 0
THEN avg(expenses / employees)
END
CASE COALESCE(sum(employees),0)
WHEN 0 THEN 0.0
ELSE SUM(salary)/sum(employees)
END
-- 计算比率
(CASE COALESCE(sum(employees),0)
WHEN 0 THEN '0.00%'
ELSE concat(round(SUM(salary)*100.0/sum(employees)),2),'%')
END) excelRate
(CASE WHEN time > 1440 THEN time/1440||'天'||time%1440/60||'小时'||time%60||'分钟'
WHEN time > 60 THEN time/60||'小时'||time%60||'分钟'
ELSE time%60||'分钟'
END) weekAvg
FROM departments;
-- 创建表
drop table if exists my_first_table;
CREATE TABLE if not exists my_first_table (
first_column text,
second_column integer
);
-- 自增序列 主键 唯一 非空约束 外键
CREATE TABLE products (
product_no integer DEFAULT nextval('products_product_no_seq') PRIMARY KEY,
name text NOT NULL,
price numeric DEFAULT 9.99,
number CHECK (number > 0),
discounted_price numeric CONSTRAINT positive_price CHECK (discounted_price > 0),
CONSTRAINT valid_discount CHECK (price > discounted_price), --打折价格低于正常价格
UNIQUE (product_no)
);
-- 组合约束
CREATE TABLE example (
a integer,
b integer,
c integer,
UNIQUE (a, c)
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT, --不允许删除被引用的行
order_id integer REFERENCES orders ON DELETE CASCADE,--删除时级联删除 还有其他两种选项:SET NULL和SET DEFAULT。这些将导致在被引用行被删除后,引用行中的引用列被置为空值或它们的默认值。
quantity integer,
PRIMARY KEY (product_no, order_id)
);
-- 序列发生器取值
CREATE TABLE tablename (
colname SERIAL
);
-- 等价于以下语句:
CREATE SEQUENCE tablename_colname_seq AS integer;
CREATE TABLE tablename (
colname integer NOT NULL DEFAULT nextval('tablename_colname_seq')
);
ALTER SEQUENCE tablename_colname_seq OWNED BY tablename.colname;
--创建序列
CREATE SEQUENCE serial START 101;
-- 从这个序列中选取下一个数字:
SELECT nextval('serial');
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.5, 3.5, 1) as x;
-- 生成时间序列
select * from generate_series(to_timestamp(1658937600)::DATE,to_timestamp(1659537600)::DATE,'1 day')
-- 生成char时间序列
select to_char(generate_series(to_timestamp(1658937600)::DATE,to_timestamp(1659537600)::DATE,'1 day'),'yyyy-mm-dd')
create table if not exists t_gt_json(
oid bigint not null,
sd_type varchar(10),
frame bigint not null,
mark text,
jval text,
gltf text,
ms text not null,
constraint testA_unique_key unique(oid,sd_type,frame,ms)
) partition by List(ms);
comment on table t_gt_jsonis "测试表";
comment on column t_gt_json.sd_type is "要素类型";
create index if not exists t_gt_json_type_idx on public.t_gt_json_type using btree("type");
create table if not exists t_gt_json_type_202307 partition of t_gt_json for values in ('202307');
-- 创建一个范围分区表:
CREATE TABLE if not exists measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建在分区键中具有多个列的范围分区表:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
-- 创建列表分区表:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
-- 建立哈希分区表:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
-- 创建范围分区表的分区:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
--使用分区键中的多个列,创建范围分区表的几个分区:
CREATE TABLE if not exists measurement_ym_older
PARTITION OF measurement_year_month
FOR VALUES FROM (MINVALUE, MINVALUE) TO (2016, 11);
CREATE TABLE measurement_ym_y2016m11
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 11) TO (2016, 12);
CREATE TABLE measurement_ym_y2016m12
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 12) TO (2017, 01);
CREATE TABLE measurement_ym_y2017m01
PARTITION OF measurement_year_month
FOR VALUES FROM (2017, 01) TO (2017, 02);
-- 创建列表分区表的分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b');
-- 创建本身是分区的列表分区表的分区,然后向其添加分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b') PARTITION BY RANGE (population);
CREATE TABLE cities_ab_10000_to_100000
PARTITION OF cities_ab FOR VALUES FROM (10000) TO (100000);
-- 建立哈希分区表的分区:
CREATE TABLE if not exists orders_p1 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
-- 建立默认分区:
CREATE TABLE cities_partdef
PARTITION OF cities DEFAULT;
-- 移除旧数据最简单的选择是删除掉不再需要的分区:可以非常快地删除数百万行记录,因为它不需要逐个删除每个记录。不过注意需要在父表上拿到ACCESS EXCLUSIVE锁。
DROP TABLE measurement_y2006m02;
-- 另一种通常更好的选项是把分区从分区表中移除,但是保留它作为一个独立的表:
ALTER TABLE measurement DETACH PARTITION measurement_y2006m02;
-- 父表创建索引子表自动也有索引,或者父表创建索引子表不拥有;
CREATE INDEX if not exists measurement_usls_idx ON measurement (unitsales); --子表将自动拥有索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales); --子表将不拥有索引
--父表也将能使用子表的索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales);
CREATE INDEX measurement_usls_200602_idx
ON measurement_y2006m02 (unitsales);
ALTER INDEX measurement_usls_idx
ATTACH PARTITION measurement_usls_200602_idx;
-- 创建一个范围分区表:
CREATE TABLE measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建在分区键中具有多个列的范围分区表:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
-- 创建列表分区表:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
-- 建立哈希分区表:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
-- 创建范围分区表的分区:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
-- 使用分区键中的多个列-- 创建范围分区表的几个分区:
CREATE TABLE measurement_ym_older
PARTITION OF measurement_year_month
FOR VALUES FROM (MINVALUE, MINVALUE) TO (2016, 11);
CREATE TABLE measurement_ym_y2016m11
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 11) TO (2016, 12);
CREATE TABLE measurement_ym_y2016m12
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 12) TO (2017, 01);
CREATE TABLE measurement_ym_y2017m01
PARTITION OF measurement_year_month
FOR VALUES FROM (2017, 01) TO (2017, 02);
-- 创建列表分区表的分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b');
-- 创建本身是分区的列表分区表的分区,然后向其添加分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b') PARTITION BY RANGE (population);
CREATE TABLE cities_ab_10000_to_100000
PARTITION OF cities_ab FOR VALUES FROM (10000) TO (100000);
-- 建立哈希分区表的分区:
CREATE TABLE orders_p1 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
-- 建立默认分区:
CREATE TABLE cities_partdef
PARTITION OF cities DEFAULT;
-- 增加列
ALTER TABLE products ADD COLUMN description text;
ALTER TABLE products ADD COLUMN description text CHECK (description <> '');
-- 移除列
ALTER TABLE products DROP COLUMN description;
ALTER TABLE products DROP COLUMN description CASCADE;
-- 增加约束
ALTER TABLE products ADD CHECK (name <> '');
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
-- 移除约束
ALTER TABLE products DROP CONSTRAINT some_name;
ALTER TABLE products ALTER COLUMN product_no DROP NOT NULL;
-- 更改列默认值,移除默认值
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
-- 修改列类型
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
-- 重命名列
ALTER TABLE products RENAME COLUMN product_no TO product_number;
-- 重命名表
ALTER TABLE products RENAME TO items;
-- 创建模式
CREATE SCHEMA hollywood;
CREATE TABLE hollywood.films (title text, release date, awards text[]);
CREATE VIEW hollywood.winners AS
SELECT title, release FROM hollywood.films WHERE awards IS NOT NULL;
-- 删除模式
DROP SCHEMA hollywood CASCADE;
-- 定义外部统计
CREATE TABLE t1 (
a int,
b int
);
INSERT INTO t1 SELECT i/100, i/500
FROM generate_series(1,1000000) s(i);
ANALYZE t1;
-- 匹配行的数量将被大大低估:
EXPLAIN ANALYZE SELECT * FROM t1 WHERE (a = 1) AND (b = 0);
CREATE STATISTICS s1 (dependencies) ON a, b FROM t1;
ANALYZE t1;
-- 现在行计数估计会更准确:
EXPLAIN ANALYZE SELECT * FROM t1 WHERE (a = 1) AND (b = 0);
CREATE TABLE t2 (
a int,
b int
);
INSERT INTO t2 SELECT mod(i,100), mod(i,100)
FROM generate_series(1,1000000) s(i);
CREATE STATISTICS s2 (mcv) ON a, b FROM t2;
ANALYZE t2;
-- valid combination (found in MCV)
EXPLAIN ANALYZE SELECT * FROM t2 WHERE (a = 1) AND (b = 1);
-- invalid combination (not found in MCV)
EXPLAIN ANALYZE SELECT * FROM t2 WHERE (a = 1) AND (b = 2);
-- CREATE TABLE AS创建一个表,并且用由一个SELECT命令计算出来的数据填充 该表。该表的列具有和SELECT的输出列 相关的名称和数据类型(不过可以通过给出一个显式的新列名列表来覆盖这些列名)。
-- CREATE TABLE AS和创建一个视图有些相似,但是实际上非常不同:它会创建一个新表并且只计算该查询一次用来初始填充新表。这个新表将不会跟踪该查询源表的后续变化。相反, 一个视图只要被查询,它的定义SELECT 语句就会被重新计算。
CREATE TABLE films_recent AS SELECT * FROM films WHERE date_prod >= '2002-01-01';
- 要完全地复制一个表,也可以使用TABLE命令的 简短形式:
CREATE TABLE films2 AS TABLE films;
-- 触发器
-- 历史数据更新
update test_geo set lon=st_x(st_geomfromtext(lastp,4326)),lat = st_y(st_geomfromtext(lastp,4326));
-- 触发器更新
create or replace FUNCTION func_updatelastp() RETURNS trigger
AS
$func_updatelastp$
BEGIN
update test_geo set lon=st_x(st_geomfromtext(lastp,4326)),lat = st_y(st_geomfromtext(lastp,4326)) where id = NEW.id;
RETURN NEW;
END;
$func_updatelastp$ LANGUAGE plpgsql;
CREATE TRIGGER updatelastp_trigger AFTER INSERT OR UPDATE OF lastp ON test_geo
FOR EACH ROW EXECUTE PROCEDURE func_updatelastp();
-- eg: 创建触发器
CREATE FUNCTION trigf() RETURNS trigger
AS 'filename'
LANGUAGE C;
CREATE TRIGGER tbefore BEFORE INSERT OR UPDATE OR DELETE ON ttest
FOR EACH ROW EXECUTE FUNCTION trigf();
CREATE TRIGGER tafter AFTER INSERT OR UPDATE OR DELETE ON ttest
FOR EACH ROW EXECUTE FUNCTION trigf();
drop table if exists test_geo;
CREATE TABLE if not exists test_geo
(
id bigint NOT NULL,
line_geom geometry,
lastp text,
lat numeric,
lon numeric
);
INSERT INTO test_geo(id, line_geom, lastp)
VALUES(1,ST_GeomFromText('LINESTRING(118.810687877626 31.9125455099001,118.809488683078 31.9106356486321)',4326),'POINT(115.6 30.9)');
INSERT INTO test_geo(id, line_geom,lastp)
VALUES(2,ST_GeomFromText('LINESTRING(118.8094259903 31.9126940986126,118.809430971813 31.9125951121883)',4326),'POINT(113.6 34.9)');
INSERT INTO test_geo(id, line_geom,lastp)
VALUES(3,ST_GeomFromText('POLYGON((113.412350 29.971457,115.156783 29.971457,115.156783 31.428195,113.412350 31.428195,113.412350 29.971457))',4326),'POINT(116.6 40.9)');
INSERT INTO test_geo(id, line_geom)
VALUES(4,ST_GeomFromText('POINT(115.6 30.9)',4326));
INSERT INTO test_geo(id, line_geom,lastp)
VALUES(6,ST_GeomFromText('POLYGON((113.412350 29.971457,115.156783 29.971457,115.156783 31.428195,113.412350 31.428195,113.412350 29.971457))',4326),'POINT(120.1 35.2)');
INSERT INTO test_geo(id, line_geom,lastp)
VALUES(7,ST_GeomFromText('POLYGON((113.412350 29.971457,115.156783 29.971457,115.156783 31.428195,113.412350 31.428195,113.412350 29.971457))',4326),'POINT(118.1 38.2)');
select *,ST_AsText(line_geom),ST_LengthSpheroid(line_geom,'SPHEROID["WGS 84",6378137,298.257223563]') from test_geo;
select st_geomfromtext(lastp,4326),st_x(st_geomfromtext(lastp,4326)),st_y(st_geomfromtext(lastp,4326)),* from test_geo;
--构建表并进行geomtry与wkt互转,计算长度等;
CREATE TABLE if not exists test_geo
(
id bigint NOT NULL,
line_geom geometry
);
INSERT INTO test_geo(id, line_geom)
VALUES(1,ST_GeomFromText('LINESTRING(118.810687877626 31.9125455099001,118.809488683078 31.9106356486321)',4326));
INSERT INTO test_geo(id, line_geom)
VALUES(1,ST_GeomFromText('POLYGON((113.412350 29.971457,115.156783 29.971457,115.156783 31.428195,113.412350 31.428195,113.412350 29.971457))',4326));
INSERT INTO test_geo(id, line_geom)
VALUES(1,ST_GeomFromText('POINT(115.6 30.9)',4326));
select *,ST_AsText(line_geom),ST_LengthSpheroid(line_geom,'SPHEROID["WGS 84",6378137,298.257223563]') from test_geo;
-- 直接构建点、线计算距离
select
ST_Distance(
ST_SetSRID(ST_MakePoint(118.810687877626,31.9125455099001),4326)::geography,
ST_SetSRID(ST_MakePoint(118.809488683078,31.9106356486321),4326)::geography
),
ST_LengthSpheroid(ST_GeomFromText('LINESTRING(118.810687877626 31.9125455099001,118.809488683078 31.9106356486321)',4326),
'SPHEROID["WGS 84",6378137,298.257223563]'),
ST_Length(
ST_MakeLine(
ST_MakePoint(118.810687877626,31.9125455099001),
ST_MakePoint(118.809488683078,31.9106356486321)
)::geography
)
select ST_GeomFromText('LINESTRING (115.805946 39.2572185, 115.8059521 39.2572183, 115.8059566 39.2572192, 115.805962 39.2572191, 115.8059678 39.2572183, 115.8059764 39.2572184, 115.8059806 39.2572192, 115.8059855 39.2572193, 115.8059884 39.2572182, 115.8059937 39.2572182, 115.8060005 39.2572196, 115.8060042 39.2572216, 115.8060075 39.2572206, 115.8060137 39.2572209)',4326),ST_GeomFromText('LINESTRING ( 115.80597777855581 39.257218662582055, 115.805976 39.257228 )',4326)
INSERT INTO test_geo(id, line_geom) VALUES(10,ST_GeomFromText('LINESTRING (115.805946 39.2572185, 115.8059521 39.2572183, 115.8059566 39.2572192, 115.805962 39.2572191, 115.8059678 39.2572183, 115.8059764 39.2572184, 115.8059806 39.2572192, 115.8059855 39.2572193, 115.8059884 39.2572182, 115.8059937 39.2572182, 115.8060005 39.2572196, 115.8060042 39.2572216, 115.8060075 39.2572206, 115.8060137 39.2572209)',4326));
INSERT INTO test_geo(id, line_geom) VALUES(11,ST_GeomFromText('LINESTRING ( 115.80597777855581 39.257218662582055, 115.805976 39.257228 )',4326));
-- Geometry点 线 面 多线互转
select point_geom,st_astext(point_geom) as point,
polygon_geom,st_astext(polygon_geom) as polygon,
line_geom,st_astext(line_geom) as line from
(select st_geomfromtext('Point(121.344239 31.292094 40.54)',4326) as point_geom,
ST_GeomFromText('MULTIPOLYGON(((116.25853747 39.97870959,116.2585059 39.97869392,116.25845554 39.97875528,116.25848712 39.97877096,116.25853747 39.97870959)))') as multipoly_Geom,
st_geomfromtext('LINESTRING(121.344239 31.292094, 121.345239 31.293094)',4326) as line_geom,
st_geomfromtext('POLYGON ((121.3450796849 31.29321148221, 121.34539831471 31.29297651758, 121.34439831415 31.29197651879, 121.34407968546 31.292211481, 121.3450796849 31.29321148221))')
as polygon_geom) t
select * from test_geo where id >9;
-- 日期转换
select 1659351600000,1659355199999,
cast('1659351600000' as bigint) as char2bigint,
cast('1659351600000' as bigint)/1000 as s,
to_timestamp(1659355199)::DATE as date,
to_date('2022-08-01 19:59:59.000000', 'yyyy-mm-dd hh24:mi:ss.us' ) as date2,
to_char(to_timestamp(cast('1659351600000' as bigint)/1000),'YYYY-MM-DD HH24:MI:SS') as char2ts24,
to_char(to_timestamp(1659351600000),'yyyy-mm-dd hh:mm:ss') as msts,
to_char(to_timestamp(1659355199999),'yyyy-mm-dd hh:mm:ss') as mste,
to_char(to_timestamp(1659351600),'yyyy-mm-dd hh:mm:ss') as sts,
to_char(to_timestamp(1659355199),'yyyy-mm-dd hh:mm:ss') as stE,
to_char(to_timestamp(1659351600),'YYYY-MM-DD HH24:MI:SS') as ts24,
to_char(to_timestamp(1659355199),'YYYY-MM-DD HH24:MI:SS') as te24,
to_char(to_timestamp(1659355199),'yyyy-mm-dd hh24:mi:ss.us') as te24_2
-- 生成00:00~23:00
select '0' || generate_series(0,9)||':00' as hour union all select generate_series(10,23)||':00'
-- 生成时间戳s序列
select t.hour,to_timestamp(t.hour),to_char(to_timestamp(t.hour),'yyyy-mm-dd hh24:mi:ss.us'),to_char(to_timestamp(t.hour),'yyyy-mm-dd hh24:00')
from (select generate_series(1659196800,1660015435,86400) as hour) t
-- 日期序列
select generate_series('2022-07-09'::date,'2022-08-08'::date,'1 day')::date
-- date转text
select d.date,d.date::TEXT from (select generate_series('2022-07-09'::date,'2022-08-08'::date,'1 day')::date as date) d
-- 生成当天小时整点的时间戳,字符串转日期date年月日时分秒,字符串转day年月日,字符串转timestamp,字符串转ms,m
select '2022-08-10 '||hour|| ':00' as dayYMDHMS,('2022-08-10 '||hour|| ':00')::date as date1,
to_date('2022-08-10 '||hour|| ':00', 'yyyy-mm-dd hh24:mi:ss.us' ) as date2,
to_timestamp('2022-08-10 '||hour|| ':00', 'yyyy-mm-dd hh24:mi:ss.us') timestamp1,
floor(extract(epoch from to_timestamp('2022-08-10 '||hour|| ':00', 'yyyy-mm-dd hh24:mi:ss.us'))*1000) ms,
floor(extract(epoch from to_timestamp('2022-08-10 '||hour|| ':00', 'yyyy-mm-dd hh24:mi:ss.us'))) s,
floor(extract(epoch from to_timestamp('2022-08-10 '||hour|| ':00', 'yyyy-mm-dd hh24:mi:ss.us'))*1000)+3600*1000 msE
from (select '0' || generate_series(0,9)||':00' as hour union all select generate_series(10,23)||':00' as hour) t
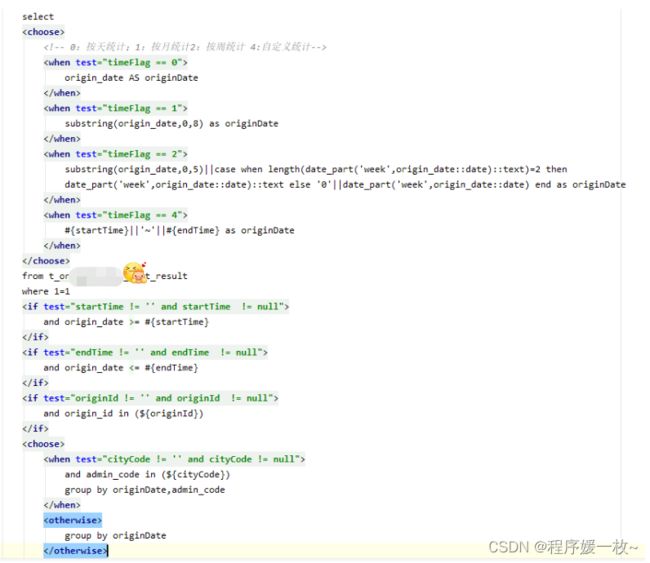
select
-- 0: 按天统计
origin_date As originDate,
-- 1: 按月统计
substring(origin_date,0,8) as originDate,
-- 2: 按周统计
substring(origin_date,0,5)||case when length(date_part('week',origin_date::date)::text)=2 then date_part('week',origin_date::date)::text else
'0'||date_part('week',origin_date::date) end as originDate,
-- 4: 自定义统计
'2022-05-05'~'2022-05-13' as originDate
from (select to_char(generate_series(to_timestamp(1658937600)::DATE,to_timestamp(1659537600)::DATE,'1 day'),'yyyy-mm-dd') as origin_date) T
where 1=1;
-- 字符串截取和替换: position截取lat,lon
select p.position,SUBSTR(SPLIT_PART(position,' ',1),7) as lon,REPLACE(SPLIT_PART(position,' ',2),')','') as lat from (select 'Point(114.23451279684568 34.892324932024)' as position) as p
-- coalesce:返回其参数中第一个非空表达式
select COALESCE(3,1),COALESCE('其他','1')
-- case when可以一行统计多个状态的值,totalLength,finishLength,total,failCnt,successCnt
select ds,sum(track_length) as total_track_length,sum(case when status=5 then track_length else 0 end) as finish_track_length,
count(1) as total,sum(case when status=5 then 1 else 0 end) as finish_cnt,sum(case when status=4 then 1 when status=7 then 1 else 0 end) as fail_cnt,
sum(case when status=6 then 1 else 0 end) as executing_cnt from t_task group by ds order by ds
- 时间戳转日期
select 1660197595000,to_timestamp(1660198903355/1000)
drop table if exists weather2;
CREATE TABLE weather2 (
city varchar(80),
temp_lo int, -- 最低温度
temp_hi int, -- 最高温度
prcp real, -- 湿度
date date
);
ALTER TABLE weather2 ADD CONSTRAINT date_uniq UNIQUE (date, city);
SELECT *
FROM ROWS FROM
(
json_to_recordset('[{"a":40,"b":"foo"},{"a":"100","b":"bar"}]')
AS (a INTEGER, b TEXT),
generate_series(1, 3)
) AS x (p, q, s)
ORDER BY p;
-- on conflict 不更新,更新
insert into weather2 as tos (city,temp_lo,date) SELECT p,q,s::date
FROM ROWS FROM
(
json_to_recordset('[{"a":40,"b":"sh"},{"a":"100","b":"qd"},{"a":"10","b":"qdd"},{"a":"3","b":"bj"}]')
AS (b TEXT,a INTEGER),
generate_series(1, 4),
generate_series('2022-08-06'::date,'2022-08-09'::date,'1 day')
) AS x (p,q,r,s)
-- ORDER BY p
-- on conflict(date, city) do update set temp_lo = excluded.temp_lo; --保留当前值
-- on conflict(date, city) do update set temp_lo = tos.temp_lo; --保留原始值
-- on conflict(date, city) do nothing; --保留原始值
on conflict on constraint date_uniq do nothing; --保留原始值
on conflict(date, city) do update set temp_lo = tos.temp_lo+excluded.temp_lo -- 原始值与当前值相加
select * from weather2
-- 找出占用磁盘最大的表和索引
-- SELECT relname, relpages FROM pg_class ORDER BY relpages DESC;
-- 某张表的磁盘占用量
SELECT pg_relation_filepath(oid), relpages FROM pg_class WHERE relname = 't_application';
--
SELECT relname, relpages
FROM pg_class,
(SELECT reltoastrelid
FROM pg_class
WHERE relname = 't_application') AS ss
WHERE oid = ss.reltoastrelid OR
oid = (SELECT indexrelid
FROM pg_index
WHERE indrelid = ss.reltoastrelid)
ORDER BY relname;
select provider_id,count(1) from t_sync_task group by provider_id;
select * from t_sync_task order by create_time desc limit 10
select * from t_sync_task where provider_id is null order by create_time desc limit 10
select * from t_sync_task where provider_id ='navinfo' order by create_time desc limit 10
-- 查看索引
-- select * from pg_indexes where tablename = 'pg_index';
-- 查看索引定义
select pg_get_indexdef(indexrelid),* from pg_index where indrelid in (select oid from pg_class where relname = 'flyway_schema_history') order by indexrelid desc
-- 查看索引
select * from pg_index;
-- 可视化查看索引,schema,表名,索引名,tablespace,索引定义
SELECT
n.nspname AS schemaname,
c.relname AS tablename,
i.relname AS indexname,
t.spcname AS tablespace,
pg_get_indexdef(i.oid) AS indexdef
FROM pg_index x
JOIN pg_class c ON c.oid = x.indrelid
JOIN pg_class i ON i.oid = x.indexrelid
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = i.reltablespace
where c.relname = 'flyway_schema_history'
-- 修改类型
alter table evaluate_detail alter column class1 type smallint using class1::int;
-- string字符串截取及拼接 "20220916" 转为 "2022-09-16"
select day,SUBSTRING (day, 1, 4)||'-'||SUBSTRING (day,5,2)||'-'||SUBSTRING (day, 7) from (select '20220916' as day)t
--获取时间:自然周
SELECT now(),date_part('week',TIMESTAMP '2021-03-11'),date_part('week','2021-03-11'::timestamp),date_part('week',now());
-- 更新字段类型
alter table evaluate_detail alter rate type varchar(10);
alter table evaluate_detail alter true_rate type varchar(10);
alter table evaluate_detail alter miss_rate type varchar(10);
alter table evaluate_detail alter false_phk_rate type varchar(10);
alter table evaluate_detail alter recall type varchar(10);
-- 更新字段名
alter table evaluate_detail rename false_phk_rate to false_phk;
COMMENT ON COLUMN evaluate_detail.false_phk IS '百公里误报量';
-- 根据某个字段聚合统计
select distinct(e.id) as id,e.name, string_agg(provider_id,',') OVER (PARTITION BY eid) as providers,
e.* from evaluate_info e left join evaluate_detail d on e.id = d.eid and d.class1=-1 where 1 = 1
-- 分组统计 相加,除法,保留俩位小数
select sum(tp) OVER (PARTITION BY date_part('week',day::timestamp)) as tps,
sum(fp) OVER (PARTITION BY date_part('week',day::timestamp)) as fps,
sum(fn) OVER (PARTITION BY date_part('week',day::timestamp)) as fns,
sum(tp+fp) OVER (PARTITION BY date_part('week',day::timestamp)) as tpfps,
sum(tp+fn) OVER (PARTITION BY date_part('week',day::timestamp)) as tpfns,
tp*1.0/(tp+fp),tp*1.0/(tp+fn),(tp+fp)*1.0/(tp+fn),
CAST(tp*100.0/(tp+fp) as DECIMAL(18,2)) as tpRate,1-CAST(tp*1.0/(tp+fp) as DECIMAL(18,2)) as recall,
date_part('week',day::timestamp),* from evaluate_detail
where day like '%2022%' and class1 = -1;