Vision Transformer代码
VIT总体架构
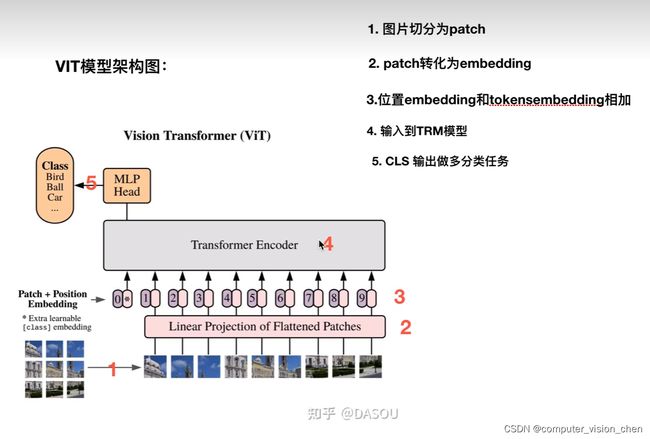
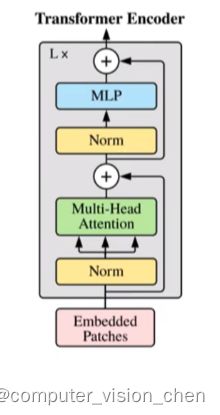
Transformer Encoder
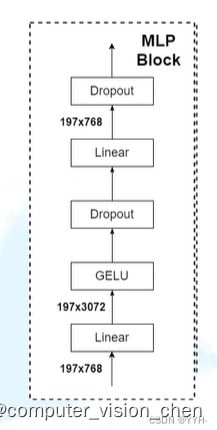
MLP block
代码
#%%
import torch
from torch import nn
from einops import rearrange,repeat
from einops.layers.torch import Rearrange
#%%
def pair(t):
return t if isinstance(t,tuple) else (t,t)
#%%
class PreNorm(nn.Module):
def __init__(self,dim,fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self,x,**kwargs):
return self.fn(self.norm(x),**kwargs)
#%%
class FeedForward(nn.Module):
def __init__(self,dim,hidden_dim,dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim,hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
return self.net(x)
#%%
class Attention(nn.Module):
def __init__(self,dim,heads=8,dim_head=64,dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads==1 and dim_head ==dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim,inner_dim * 3,bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim,dim),
nn.Dropout(dropout),
) if project_out else nn.Identity()
def forward(self,x):
qkv = self.to_qkv(x).chunk(3,dim=-1)
q,k,v = map(lambda t:rearrange(t,'b n (h d) -> b h n d',h = self.heads),qkv)
dots = torch.matmul(q,k.transpose(-1,-2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn,v)
out = rearrange(out,'b h n d -> b n (h d)')
return self.to_out(out)
#%%
class Transformer(nn.Module):
def __init__(self,dim,depth,heads,dim_head,mlp_dim,dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
# 把多个encoder堆叠在一起
for _ in range(depth):
self.layers.append(nn.ModuleList([
# encoder中的 多头注意力机制 + Add & Norm
PreNorm(dim,Attention(dim,heads=heads,dim_head=dim_head,dropout=dropout)),
# Feed Forward + Add & Norm
PreNorm(dim,FeedForward(dim,mlp_dim,dropout=dropout))
]))
def forward(self,x):
for attn,ff in self.layers:
# 输入到多头注意力机制 并进行 残差连接
x = attn(x) + x
# 输入到前馈神经网络 并进行 残差连接
x = ff(x) + x
return x
#%%
class VIT(nn.Module):
def __init__(self,*,image_size,patch_size,num_classes,dim,depth,heads,mlp_dim,pool='cls',channels=3,dim_head=64,emb_dropout=0.,dropout=0.):
super().__init__()
image_height,image_width = pair(image_size) #224x224
patch_height,patch_width = pair(patch_size) #16x16
# 图片的高和宽必须分别整除patch_height和patch_width
assert image_height % patch_height ==0 and image_width % patch_width ==0,'Image dimensions must be divisible by the patch_size'
num_patches = (image_height//patch_height) * (image_width//patch_width)
patch_dim = channels * patch_height * patch_width # 把patch展平后的维度
assert pool in {'cls','mean'},'pool类型必须是cls token或者平均池化'
'''模块一:把每个patch转换为embedding'''
self.to_patch_embedding = nn.Sequential(
# (样本数,通道数,高上划分的patch数,宽上划分的patch数)-> (样本数,(patch的高,patch的宽),(patch在高上的个数,patch在宽上的个数,通道道数))
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)',p1=patch_height,p2=patch_width),
# 1.把patch拉平,变成patch_dim。 2.把patch_dim变成dim,即embedding需要的维度。
nn.Linear(patch_dim,dim),
)
'''模块二:生成位置编码'''
# dim是encoder需要的维度,num_patches+1是把cls的位置编码也给加上去了
# nn.Parameter是pytorch的一个类,用于将一个张量标记为模型的参数,训练过程中模型将更新这些参数以最小化损失函数
# torch.randn(1,2,3) 生成一个形状为(1,2,3)的符合正态分布的随机数
self.pos_embedding = nn.Parameter(torch.randn(1,num_patches+1,dim))
self.cls_token = nn.Parameter(torch.randn(1,1,dim))
self.dropout = nn.Dropout(emb_dropout)
'''模块三:transformer的encoder'''
self.transformer = Transformer(dim,depth,heads,dim_head,mlp_dim,dropout)
# 池化操作
self.pool = pool
# 不做任何操作
self.to_latent = nn.Identity()
'''模块四:mlp_head'''
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim,num_classes)
)
def forward(self,img):
x = self.to_patch_embedding(img)
b,n,_ = x.shape
cls_tokens = repeat(self.cls_token,'() n d -> b n d',b=b)
x = torch.cat((cls_tokens,x),dim=1)
x+=self.pos_embedding[:,:(n+1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim=1) if self.pool == 'mean' else x[:,0]
x = self.to_latent(x)
return self.mlp_head(x)
#%%
v = VIT(
image_size = 224,
patch_size = 16,
num_classes = 1000,# 最后cls拿出来做linear层的时候映射到多少个维度上
dim = 1024,
depth = 6, # encoder的个数
heads = 16, # 多头注意力机制的头
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
#%%
img = torch.randn(1,3,224,224)
preds = v(img)
preds.shape
#%%
补充
Vision Transformer(ViT)PyTorch代码全解析(附图解)
https://blog.csdn.net/weixin_44966641/article/details/118733341