常用的词嵌入(Word Embedding)方法及其原理(超详细的李宏毅视频课笔记)
文章目录
- 0 前言
- 1 计算机读取word的方式
- 2 Word Embedding
- 3 By context
-
- 3.1 count based
- 3.2 prediction based
- 3.3 Prediction-based - Sharing Parameters
-
- 3.3.1 原理
- 3.3.2 模型训练
- 3.4 Prediction-based - Various Architectures
-
- 3.4.1 连续词汇(continuous bag of word,CBOW)
- 3.4.2 Skip-gram
- 4 Word Embedding 的应用
-
- 4.1 Solving analogies
- 4.2 Multi-lingual Embedding
- 4.3 Multi-domain Embedding
- 4.4 Document Embedding
0 前言
本文由整理李宏毅老师视频课笔记和个人理解所得,详细讲述了word embedding的原理及实现方法。有问题欢迎在评论区交流,我会及时回复。
1 计算机读取word的方式
一般的计算机读取word的方法有几种:

-
1-of-N encoding(one-hot encoding):每一个词汇都当做一个符号,都用向量来描述,这个方法是有不足的,这样词汇和词汇之间的相关性反映不出来,而且过于稀疏。
-
Word Class:建立word class,把有相同性质的word放在同一个 class内,将词汇进行分类,这个方法也比较粗糙,比如动物也分了很多种,不能完全概况。
-
Word Embedding:每一个的词汇也用向量来描述,但是每一个维度是一个属性。word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达。通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中。与one-hot编码和word class相比,词嵌入可以将更多的信息塞入更低的维度中。
2 Word Embedding
Word Embedding是一种无监督学习方法,通过让模型阅读大量词汇,就可以知道这个embedding的feature vector长什么样子:

就是找一个神经网络,输入是一个词汇,输出该词对应的word embedding 的 vector。因为输入就是一堆语言的训练集,但是我们没有标签,不知道embedding长什么样。所以说是无监督的。

这里可以用自编码器吗?不行。如果用独热码当作输入,没办法输出任何东西,因为独热码本身并没有什么含义。
3 By context
在word embedding中,你要了解词汇的含义可以通过上下文得到:

比如两句类似的话:蔡某某宣誓就职;马某某宣誓就职。那么就说明蔡某某和马某某是很类似的两个东西。
3.1 count based
怎么体现两个词汇是类似的? 词汇 w 1 w_1 w1和 w 2 w_2 w2常在同一篇文字中出现,那说明 V ( w 1 ) \mathrm{V}\left(\mathrm{w}_{\mathrm{1}}\right) V(w1)和 V ( w 2 ) \mathrm{V}\left(\mathrm{w}_{\mathrm{2}}\right) V(w2)比较接近。

原则为:计算内积 V ( w i ) ⋅ V ( w j ) \mathrm{V}\left(\mathrm{w}_{\mathrm{i}}\right) \cdot \mathrm{V}\left(\mathrm{w}_{\mathrm{j}}\right) V(wi)⋅V(wj),计算w1和w2同时在一篇文章中出现的次数 N i , j N_{\mathrm{i}, \mathrm{j}} Ni,j,这两个值越接近则说明这两个词义接近。
3.2 prediction based
学习一个NN(Neural Network),W代表输入的词汇。NN可以根据前一个输入的 W i − 1 W_{i-1} Wi−1,输出下一个可能出现的 W i W_i Wi。
输入是 W i − 1 W_{i-1} Wi−1的1-of-N encoding,输出下一个词汇 W i W_i Wi的概率。
这样可以把第一个hidden layer 的输入 z z z拿出来,用这个z代表一个word的embedding feature:
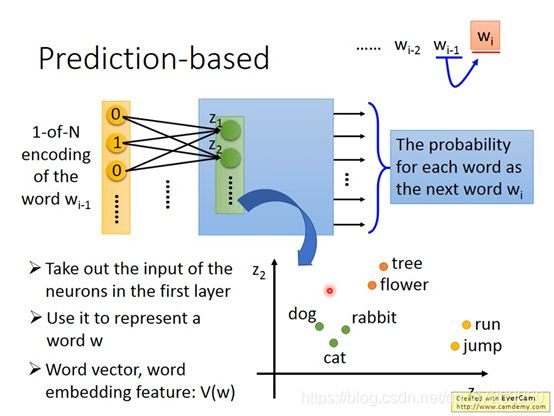
是怎么理解是根据上下文(by context)来判定的呢?假设训练数据是:
蔡某某( W i − 1 W_{i-1} Wi−1)宣誓就职( W i W_i Wi);
马某某( W i − 1 W_{i-1} Wi−1)宣誓就职( W i W_i Wi);
输入之后,都会希望输出“宣誓就职”的概率是高的:
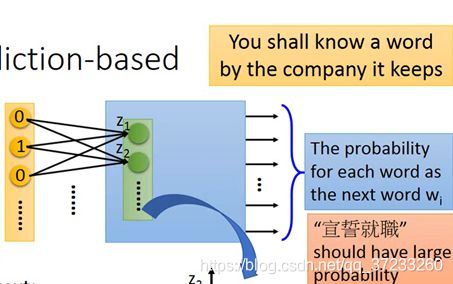
假设输入是蔡某某和马某某,这就必须要通过在第一层参数 w w w转换的时候,将马和蔡投影到同一个空间的位置,当我们考虑输出靠近的时候,就自动考虑输入前就需要靠近了。就找到这个word embedding。
3.3 Prediction-based - Sharing Parameters
3.3.1 原理
但可能觉得即使是给了上文一个词,那么下文也很难猜出来,因为这种组合是很多的。怎么办呢?可以把input拓展了到很多个词汇,比如十个。将这些word的排在一起,同时输入到NN中,但是要保证这些word位置固定,比如 W i − 1 W_{i-1} Wi−1和 W i − 2 W_{i-2} Wi−2是需要结在一起的。
所谓结在一起就是:这些词汇的编码向量同一个维度所对应的weight是一样的,图中用同样颜色表示:
为什么呢?一个显而易见的理由是,如果不这么做,同一个word在 W i − 1 W_{i-1} Wi−1和 W i − 2 W_{i-2} Wi−2的位置经过变换之后得到的embedding就会不同,而且可以减少参数量。
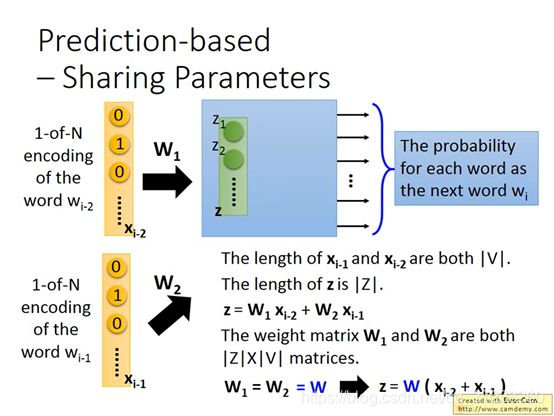
x i − 1 x_{i-1} xi−1, x i − 2 x_{i-2} xi−2的长度就是V的绝对值, z z z的长度也是取绝对值。有: z = W 1 x i − 2 + W 2 x i − 1 \mathbf{z}=\mathbf{W}_{1} \mathbf{x}_{\mathrm{i}-\mathbf{2}}+\mathbf{W}_{2} \mathbf{x}_{\mathrm{i}-1} z=W1xi−2+W2xi−1
权值矩阵 W 1 \mathbf{W}_{1} W1 , W 2 \mathbf{W}_{\mathbf{2}} W2都是|Z|×|V|的规模。因为有 W 1 = W 2 = W \mathbf{W}_{1}=\mathbf{W}_{\mathbf{2}}=\mathbf{W} W1=W2=W,所以有:
z = W ( x i − 2 + x i − 1 ) z=W\left(x_{i-2}+x_{i-1}\right) z=W(xi−2+xi−1)
3.3.2 模型训练
那么怎么才能使得这些W是相同的呢?
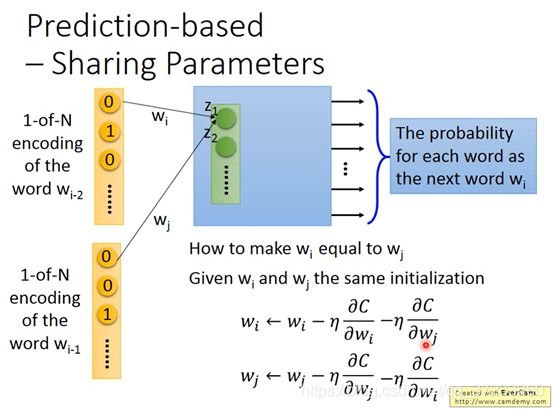
做法是这样,首先是给一样的初始值,
然后计算偏微分:

为了保持相同的更新速度,两者都是减去一样的值,可以确保在训练的过程中永远都是接在一起的。
怎么训练呢?这个训练都是无监督的。收集到一个数据集,输入前两个词,就能输出下一个词:
3.4 Prediction-based - Various Architectures
这个模型有很多变形:

3.4.1 连续词汇(continuous bag of word,CBOW)
利用前一个和后一个词汇,预测中间的词汇。训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
3.4.2 Skip-gram
利用中间的词汇,预测前一个和后一个词汇。
CBOW( Continuous Bag of Words)和 Skip-gram 语言模型的工具就是Word2vec。
实际上可以通过这个模型发现,这个NN并不深,只有一个线性的hidden layer,作者本人说他自己用的特别好,toolkit很强,不用deep也能做。
4 Word Embedding 的应用
4.1 Solving analogies
如果把国家和首都对应在一起,或者把一个动词的三个时态放在一起,这些词汇之间都有一个类似的关系。

如果把word vector两两相减,然后投影到另外一个空间,如果一个词和另一个词有从属关系,那么相减之后的结果会落在邻近区域。
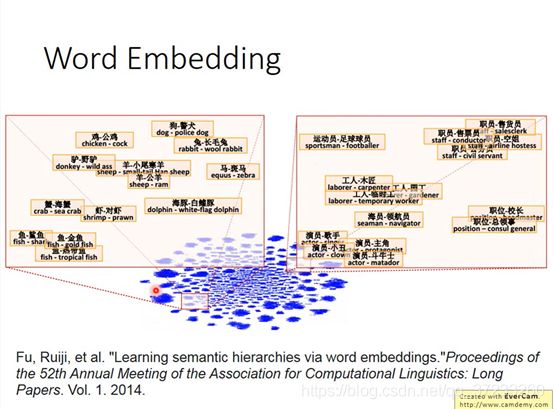
那么从属关系的词之间有这么一个性质,可以有以下的一些推论:

比如:“罗马:意大利 = 柏林:?”,这个可以通过刚刚的性质,由:
V ( Germany ) ≈ V ( Berlin ) − V ( Rome ) + V ( Italy ) \begin{gathered} V(\text { Germany }) \\ \approx V(\text { Berlin })-V(\text { Rome })+V(\text { Italy }) \end{gathered} V( Germany )≈V( Berlin )−V( Rome )+V( Italy )
来得到最接近的vector,那么最后的答案是“德国”。
4.2 Multi-lingual Embedding
通过中文和英文的两个语料库(corpus)单独地去训练一组word vector,可以发现中文和英文的word vector完全没有任何关系,每个维度对应的含义没有任何联系。
因为,训练word vector靠的是上下文之间的关系,所以如果你的corpus里没有中英文混杂的话,那么机器就无法判断中英文词汇之间的关系。
但是如果事先已知一部分中英文的词汇的对应关系,然后再分别得到一组中文vector和英文vector,接下来就可以学习一个模型把事先知道的中英文对应的那些词汇,通过映射到空间中的同一个点(绿色底子汉字或者绿色英文代表已知中英文对应关系的词汇),接下来,如果遇到新的未知的中文或者英文词汇,将英文和中文的word vector投到一个空间后,可以相互靠近,达到类似翻译的效果。

4.3 Multi-domain Embedding
不仅限于文字,也可以对影像做embedding:
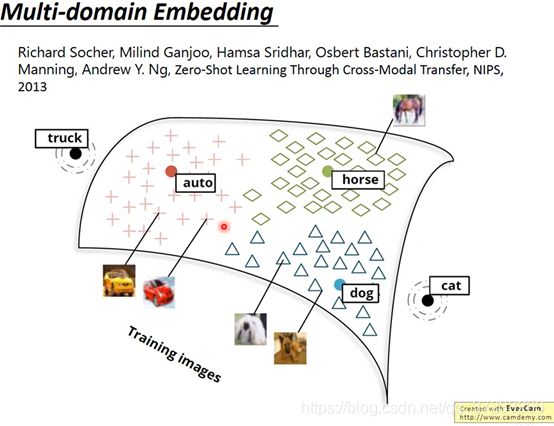
在影像分类的时候,模型很难分类新增加的其他类的图片,但是这种Model会找到image和word vector之间的映射关系,所以即使这个model之前没有见过猫的图片,也能将猫图project到“cat”的word vector。就是一种跨域的embedding。
4.4 Document Embedding
也可以把一个document变成一个vector:

最简单的方法是把一个document变成一个bag of word,然后用自编码器可以学习出这个document的semantic embedding。但是这样是不够的,因为词汇顺序代表了很多含义:

比如这两个句子换个顺序,可能意思完全相反了。
具体可见:
Reference:
1.word embedding定义: https://www.zhihu.com/question/32275069/answer/80188672
2.Multi-lingual Embedding部分的讲解:https://blog.csdn.net/weixin_41894030/article/details/107632476