【系统设计系列】缓存
系统设计系列初衷
System Design Primer: 英文文档 GitHub - donnemartin/system-design-primer: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
中文版: https://github.com/donnemartin/system-design-primer/blob/master/README-zh-Hans.md
初衷主要还是为了学习系统设计,但是这个中文版看起来就像机器翻译的一样,所以还是手动做一些简单的笔记,并且在难以理解的地方对照英文版,根据自己的理解在AI的帮助下进行翻译和知识扩展。
缓存

资料来源:可扩展的系统设计模式
什么是缓存
缓存(Cache)是计算机科学中的一种技术,它通过在内存或硬盘等存储设备中临时存放经常访问的数据,以减少数据访问时间和提高程序运行效率。缓存的主要作用是减少数据读取时间、降低系统负载、提高数据处理速度,从而使计算机系统能够更快地响应用户的请求。
缓存可以提高页面加载速度,并可以减少服务器和数据库的负载。在这个模型中,分发器先查看请求之前是否被响应过,如果有则将之前的结果直接返回,来省掉真正的处理。
数据库分片均匀分布的读取是最好的。但是热门数据会让读取分布不均匀,这样就会造成瓶颈,如果在数据库前加个缓存,就会抹平不均匀的负载和突发流量对数据库的影响。
客户端缓存
缓存可以位于客户端(操作系统或者浏览器),服务端或者不同的缓存层。比如在浏览器中存储访问过的网页文件(如 HTML、CSS、JavaScript 等),以便下次访问时能够更快地加载页面内容,提高用户体验。
CDN 缓存
CDN 也被视为一种缓存。CDN节点通过共享数据减少数据传输时间,提高数据的访问速度。
Web 服务器缓存
反向代理和缓存(比如 Varnish)可以直接提供静态和动态内容。Web 服务器同样也可以缓存请求,返回相应结果而不必连接应用服务器。
数据库缓存
数据库的默认配置中通常包含缓存级别,针对一般用例进行了优化。调整配置,在不同情况下使用不同的模式可以进一步提高性能。
应用缓存
基于内存的缓存比如 Memcached 和 Redis 是应用程序和数据存储之间的一种键值存储。由于数据保存在 RAM 中,它比存储在磁盘上的典型数据库要快多了。RAM 比磁盘限制更多,所以例如 least recently used (LRU) 的缓存无效算法可以将「热门数据」放在 RAM 中,而对一些比较「冷门」的数据不做处理。
Redis 有下列附加功能:
- 持久性选项
- 内置数据结构比如有序集合和列表
有多个缓存级别,分为两大类:数据库查询和对象:
- 行级别
- 查询级别
- 完整的可序列化对象
- 完全渲染的 HTML
一般来说,你应该尽量避免基于文件的缓存,因为这使得复制和自动缩放很困难。
数据库查询级别的缓存
当你查询数据库的时候,将查询语句的哈希值与查询结果存储到缓存中。这种方法会遇到以下问题:
- 很难用复杂的查询删除已缓存结果。
- 如果一条数据比如表中某条数据的一项被改变,则需要删除所有可能包含已更改项的缓存结果。
对象级别的缓存
将您的数据视为对象,就像对待你的应用代码一样。让应用程序将数据从数据库中组合到类实例或数据结构中:
- 如果对象的基础数据已经更改了,那么从缓存中删掉这个对象。
- 允许异步处理:workers 通过使用最新的缓存对象来组装对象。
建议缓存的内容:
- 用户会话
- 完全渲染的 Web 页面
- 活动流
- 用户图数据
何时更新缓存
由于你只能在缓存中存储有限的数据,所以你需要选择一个适用于你用例的缓存更新策略。
缓存模式(读取缓存)

应用从存储器读写。缓存不和存储器直接交互,应用执行以下操作:
- 在缓存中查找记录,如果所需数据不在缓存中
- 从数据库中加载所需内容
- 将查找到的结果存储到缓存中
- 返回所需内容
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached 通常用这种方式使用。
添加到缓存中的数据读取速度很快。缓存模式也称为延迟加载。只缓存所请求的数据,这避免了没有被请求的数据占满了缓存空间。
缓存的缺点:
- 请求的数据如果不在缓存中就需要经过三个步骤来获取数据,这会导致明显的延迟。
- 如果数据库中的数据更新了会导致缓存中的数据过时。这个问题需要通过设置 TTL 强制更新缓存或者直写模式来缓解这种情况。
- 当一个节点出现故障的时候,它将会被一个新的节点替代,这增加了延迟的时间。
直写模式(写缓存)

应用使用缓存作为主要的数据存储,将数据读写到缓存中,而缓存负责从数据库中读写数据。
- 应用向缓存中添加/更新数据
- 缓存同步地写入数据存储
- 返回所需内容
应用代码:
set_user(12345, {"foo":"bar"})缓存代码:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)由于存写操作所以直写模式整体是一种很慢的操作,但是读取刚写入的数据很快。相比读取数据,用户通常比较能接受更新数据时速度较慢。缓存中的数据不会过时。
直写模式的缺点:
- 由于故障或者缩放而创建的新的节点,新的节点不会缓存,直到数据库更新为止。缓存应用直写模式可以缓解这个问题。
- 写入的大多数数据可能永远都不会被读取,用 TTL 可以最小化这种情况的出现。
回写模式(写缓存)
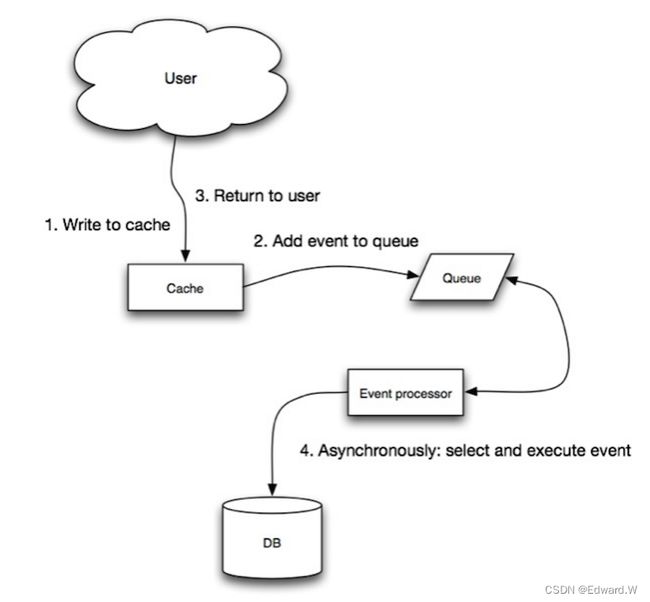
在回写模式中,应用执行以下操作:
- 在缓存中增加或者更新条目
- 异步写入数据,提高写入性能。
回写模式的缺点:
- 缓存可能在其内容成功存储之前丢失数据。
- 执行直写模式比缓存或者回写模式更复杂。
刷新
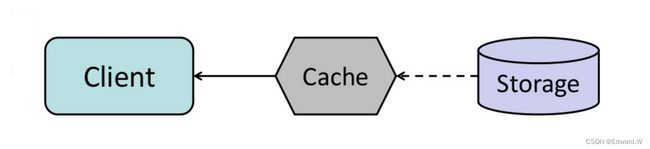
资料来源:从缓存到内存数据网格
你可以将缓存配置成在到期之前自动刷新最近访问过的内容。
如果缓存可以准确预测将来可能请求哪些数据,那么刷新可能会导致延迟与读取时间的降低。
刷新的缺点:
- 不能准确预测到未来需要用到的数据可能会导致性能不如不使用刷新。
缓存的缺点:
- 需要保持缓存和真实数据源之间的一致性,比如数据库根据缓存无效。
- 需要改变应用程序比如增加 Redis 或者 memcached。
- 无效缓存是个难题,什么时候更新缓存是与之相关的复杂问题。
延迟双删(更新缓存)
延迟双删是一种缓存删除策略,主要用于解决缓存数据和数据库数据不一致的问题。当缓存数据被删除时,延迟双删策略会暂时保留缓存中的数据,并在一定时间后或达到一定条件时再将其删除。这种策略可以在一定程度上避免缓存穿透、缓存击穿等问题,同时减轻数据库的压力。

以下是缓存延迟双删的主要步骤:
- 删除缓存:当需要删除某个缓存条目时,首先在缓存系统中删除该条目。
- 更新数据库:将缓存条目的删除操作记录到数据库中,并更新数据库中的相应记录。这样可以确保缓存数据和数据库数据保持一致。
- 延迟删除:在缓存条目被删除后,将其加入一个延迟队列,设置一个延迟时间。当延迟时间到达时,再执行缓存条目的删除操作。
- 刷新缓存:在缓存条目被删除并延迟一段时间后,其他访问该缓存条目的请求会触发一个刷新操作,将最新的数据从数据库中读取并更新缓存。
- 超时处理:如果延迟队列中的缓存条目在延迟时间内未被处理,可以设置一个超时时间。当超时时间到达时,对延迟队列中的缓存条目执行删除操作。
通过上述步骤,缓存延迟双删策略可以确保在高并发场景下,缓存数据和数据库数据保持一致,同时减轻数据库的压力。需要注意的是,在实际应用中,应根据具体场景和需求调整延迟时间和超时时间。
那么为什么要延时双删呢,有这么几个原因:
- 避免脏数据:在使用缓存的场景下,可能会出现事务 A 对某个数据进行修改,而事务 B 在修改之前读取了该数据,导致事务 B 读取到的数据是脏数据。延时双删可以确保在事务 A 更新数据库后,再删除缓存,避免事务 B 读取到脏数据。
- 减轻数据库压力:在高并发场景下,大量的缓存删除操作可能会导致数据库压力增加。通过延时双删策略,可以延迟缓存删除操作,分散数据库压力。
- 提高缓存性能:延时双删可以减少缓存系统与数据库之间的交互次数,提高缓存系统的性能。
- 确保一致性:在延时双删策略下,缓存删除操作会在数据库更新后执行,确保了缓存数据与数据库数据的一致性。