Linux常用命令(一)
参考文档:http://c.biancheng.net/linux_tutorial/
一、查看文本文件
1、cat命令(concatenate)
cat命令可以用来显示文本文件的内容(类似于 DOS 下的type命令)
基本格式如下:
# 显示文件内容
[root@localhost ~]# cat [选项] 文件名
常用选项:
| 选项 | 含义 |
|---|---|
| -E | 在每行结束处显示"$" |
| -n | 对输出的所有行进行编号 |
| -b | 同 -n 不同,此选项表示只对非空行进行编号 |
| -s | 当遇到有连续 2 行以上的空白行时,就替换为 1 行的空白行 |

注意,
cat命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。 因此,cat命令适合查看不太大的文件。
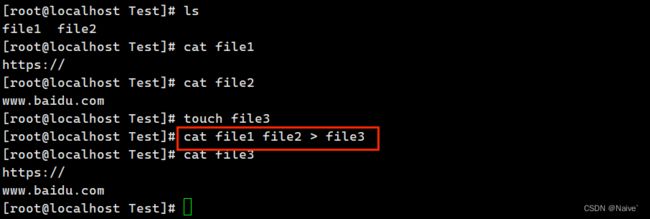
cat命令也可以把几个文件内容附加到另一个文件中,即连接合并文件,基本格式如下:
# 连接合并文件
[root@localhost ~]# cat 文件1 文件2 > 文件3
2、more命令
more 命令可以分页显示文本文件的内容,此命令的基本格式如下:
[root@localhost ~]# more [选项] 文件名
常见选项(命令比较简单,一般不用什么选项):
| 选项 | 含义 |
|---|---|
| -n | 一次显示的行数,n 代表数字 |
| +n | 从第 n 行开始显示文件内容,n 代表数字 |
more 命令的执行会打开一个交互界面,常用的交互命令如下:
| 交互指令 | 功能 |
|---|---|
| h 或 ? | 显示 more 命令交互命令帮助 |
| q 或 Q | 退出 more |
| v | 在当前行启动一个编辑器。 |
| :f | 显示当前文件的文件名和行号 |
| 回车键 | 向下移动一行。 |
| 空格键 | 向下移动一页。 |
| = | 显示当前行的行号。 |
| / 字符串 | 搜索指定的字符串。 |
| d | 向下移动半页。 |
| b | 向上移动一页。 |
3、less命令
less 命令的作用和 more 十分类似,都用来浏览文本文件中的内容,不同之处在于,less功能比more更丰富,使用h可以查看操作帮助
less 命令的基本格式如下:
[root@localhost ~]# less [选项] 文件名
4、head命令
head 命令可以显示指定文件前若干行的文件内容,其基本格式如下:
[root@localhost ~]# head [选项] 文件名
常用选项:
| 选项 | 含义 |
|---|---|
| -n k | 这里的 K 表示行数,该选项用来显示文件前 K 行的内容;使用 “-K” 也可以 |
注意,如不设置显示的具体行数,则默认显示
10行的文本数据。
 可以看到,使用
可以看到,使用head -n 5 /etc/passwd 命令和 head -5 /etc/passwd 的效果是一样的
5、tail命令
tail 命令和 head 命令正好相反,它用来查看文件末尾的数据,其基本格式如下:
[root@localhost ~]# tail [选项] 文件名
常用的选项:
| 选项 | 含义 |
|---|---|
| -n K | 这里的 K 指的是行数,该选项表示输出最后 K 行 |
| -c K | 这里的 K 指的是字节数,该选项表示输出文件最后 K 个字节的内容 |
| -f | 输出文件变化后新增加的数据。 |
 可以看到,使用
可以看到,使用 tail -n 3 /etc/passwd 命令和 tail -3 /etc/passwd 的效果是一样的
- 使用
-f选项来监听文件的新增内容

二、vim编辑器
vim是vi的改进版,它增加了一些功能,比如语法高亮、多级撤销、多窗口、代码补全等。vim也兼容vi的大部分命令。使用 Vim编辑文件时,存在 3 种工作模式,分别是命令模式、输入模式和末行模式,这 3 种工作模式可随意切换

1、vim命令模式
使用 vim编辑文件时,默认处于命令模式。此模式下,可使用方向键上、下、左、右键移动光标的位置,还可以对文件内容进行复制、粘贴、替换、删除等操作。
-
删除
快捷键 功能描述 x 删除光标处的字符。若在 x之前加上一个数字n,则删除从光标所在位置开始向右的n个字符。X 删除光标前面的字符。若在 X之前加上一个数字n,则删除从光标前面那个字符开始向左的n个字符。dd 删除光标所在的整行。前面加上数字n,则删除当前行以及其后的n-1行。 D 或 d$ 删除从光标所在处开始到行尾的内容 。 dw 删除一个单词。若光标处在某个单词的中间,则从光标所在位置开始删至词尾。前面加数字n,表示删除n个指定的单词。 -
复制
快捷键 功能描述 yy 复制光标所在的整行。在 yy 前可加一个数字 n,表示复制当前行及其后 n-1 行的内容。 Y 或 y$ 两命令功能一样,都是复制从光标所在处开始到行尾的内容。 yw 复制一个单词。若光标处在某个词的中间,则从光标所在位置开始复制至词尾。同 yy 命令一样,可在 yw 之前加一个数字 n,表示复制 n 个指定的单词。 -
粘贴
快捷键 功能描述 p 将剪贴板中的内容粘贴到光标后 P(大写) 将剪贴板中的内容粘贴到光标前 -
撤销
快捷键 功能描述 u 该命令撤销上一次所做的操作。多次使用 u 命令会一步一步依次撤销之前做过的操作(在一次切换到文本输入模式中输入的所有文本算一次操作)。 U 该命令会一次性撤销自上次移动到当前行以来做过的所有操作,再使用一次 U 命令则撤销之前的 U 命令所做的操作,恢复被撤销的内容。 -
查找文本
在
命令模式或末行模式下,可以使用/来检索要查找的文本# 在文件中查找字符串"root" /root注意:在末行模式查找过程中,是严格区分大小写的。如果想忽略大小写,则输入命令
:set ic;调整回来输入:set noic -
光标移动
快捷键 功能描述 w 或 W 光标移动至下一个单词的单词首 b 或 B 光标移动至上一个单词的单词首 e 或 E 光标移动至下一个单词的单词尾 nw 或 nW n 为数字,表示光标向右移动n 个单词 nb 或 nB n 为数字,表示光标向左移动 n 个单词 0 或 ^ 光标移动至当前行的行首 $ 光标移动至当前行的行尾 n$ 光标移动至当前行只有 n 行的行尾,n为数字 gg 光标移动到文件开头 G 光标移动至文件末尾 nG 光标移动到第 n 行,n 为数字 :n 编辑模式下使用的快捷键,可以将光标快速定义到指定行的行首
2、vim输入模式
使 vim 进行输入模式的方式是在命令模式状态下输入 i、I、a、A、o、O 等插入命令(各指令的具体功能如表 3 所示),当编辑文件完成后按Esc键即可返回命令模式。
| 快捷键 | 功能描述 |
|---|---|
| i | 插入命令,会将文本插入到光标所在位置之前 |
| I | 插入命令,会将文本插入到光标所在行的行首 |
| a | 追加文本命令,会将文本追加到光标当前位置之后 |
| A | 追加文本命令,会将文本追加到光标所在行的末尾 |
| o | 空行插入命令,将在光标所在行的下面插入一个空行,并将光标置于该行的行首 |
| O | 空行插入命令,将在光标所在行的上面插入一个空行,并将光标置于该行的行首 |
3、vim末行模式
末行模式用于对文件中的指定内容执行保存、查找或替换等操作。
使 Vi 切换到末行模式的方法是在命令模式状态下按:键,此时 vim 窗口的左下方出现一个:符号,这是就可以输入相关指令进行操作了。
| 快捷键 | 选项功能 |
|---|---|
| :q | 不保存就退出 Vim 编辑器 |
| :q! | 不保存,且强制退出 Vim 编辑器 |
| :w | 保存但是不退出 Vim 编辑器 |
| :w 新文件名 | 另存到新的文件 |
| :wq | 保存并退出 Vim 编辑器 |
| :x | 若当前编辑文件曾被修改过,则vi会保存该文件,否则直接退出。 |
| :x! | 保存文本,并退出 Vim 编辑器 |
指令执行后 Vim 会自动返回命令模式。如想直接返回命令模式,按
Esc即可。
三、Linux文本处理三剑客
1、sed命令
vim 采用的是交互式文本编辑模式,可以用键盘命令来交互性地插入、删除或替换数据中的文本。而 sed 命令不同,它采用的是流编辑模式,最明显的特点是,在 sed 处理数据之前,需要预先提供一组规则,sed 会按照此规则来编辑数据。
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 每次仅读取一行内容;
- 根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
sed 命令的基本格式如下:
[root@localhost ~]# sed [选项] [脚本命令] 文件名
常用选项及其含义:
| 选项 | 含义 |
|---|---|
| -e 脚本命令 | 该选项会将其后跟的脚本命令添加到已有的命令中。 |
| -f 脚本命令文件 | 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
| -n | 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
| -i | 此选项会直接修改源文件,慎用。 |
2、awk命令
与 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
awk 命令的基本格式为:
[root@localhost ~]# awk [选项] '脚本命令' 文件名
常用的选项及其含义:
| 项 | 含义 |
|---|---|
| -F fs | 指定以 fs 作为输入行的分隔符,awk 命令默认分隔符为空格或制表符。 |
| -f file | 从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令。 |
awk 的强大之处在于脚本命令,它由 2 部分组成,分别为匹配规则和执行命令,如下所示:
'匹配规则{执行命令}'
这里的匹配规则,和 sed 命令中的 address 部分作用相同,用来指定脚本命令可以作用到文本内容中的具体行,可以使用字符串(比如 /demo/,表示查看含有 demo 字符串的行)或者正则表达式指定。另外需要注意的是,整个脚本命令是用单引号''括起,而其中的执行命令部分需要用大括号{}括起来。
在 awk 程序执行时,如果没有指定执行命令,则默认会把匹配的行输出;如果不指定匹配规则,则默认匹配文本中所有的行。

3、grep命令
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用 grep 命令。
grep 命令的由来可以追溯到 UNIX 诞生的早期,在 UNIX 系统中,搜索的模式(patterns)被称为正则表达式(regular expressions),为了要彻底搜索一个文件,有的用户在要搜索的字符串前加上前缀 global(全面的),一旦找到相匹配的内容,用户就像将其输出(print)到屏幕上,而将这一系列的操作整合到一起就是
global regular expressions print,而这也就是 grep 命令的全称。
grep命令是用来在每一个文件中(或特定输出上)搜索特定的字符模式,当使用 grep 时,包含指定字符模式的每一行内容,都会被打印(显示)到屏幕上。
grep 命令的基本格式如下:
[root@localhost ~]# grep [选项] 模式 文件名
模式指的是要么是字符(串),要么是正则表达式。
常用的选项以及各自的含义:
| 选项 | 含义 |
|---|---|
| -c | 仅列出文件中包含模式的行数 |
| -i | 忽略模式中的字母大小写 |
| -l | 列出带有匹配行的文件名 |
| -n | 在每一行的最前面列出行号 |
| -v | 列出没有匹配模式的行 |
| -w | 把表达式当做一个完整的单字符来搜寻,忽略那些部分匹配的行 |
如果是搜索多个文件,grep 命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep 命令的结果将显示每一个包含匹配模式的行。
# 将当前目录下的文件列表重定向到demo1.txt文件中
[root@localhost ~]# ls -l > demo1.txt
# 在demo1.txt文件中找出匹配Music的项
[root@localhost ~]# grep Music demo1.txt
drw-rw-r--. 2 root root 6 1月 6 20:36 Music
# 使用-c选项可以统计个数
[root@localhost ~]# grep -c Music demo1.txt
1