WaveNet:一种语音合成的模型
一、引言
通过对原始信号进行建模来生成高保真的语音,文章提出了WaveNet语音生成模型。
1、可以生成类似真人的语音。
2、是基于扩展因果卷积的新架构,新的架构有非常大的感受野。
3、可以产生不同的声音。
4、可以用于语音识别和音乐合成。
二、WaveNet:
在这里,我们看到其模型最核心的概念就是条件概率模型:

其中所有的音频采样都受到所有先前时间步的影响。
因果卷积网络示意图为:

因为模型只有因果卷积,而没有递归连接,模型训练速度快于RNN,特别对于很长的序列。对于因果卷积,存在的一个问题是需要很多层或者很大的filter来增加卷积的感受野。我们通过大小排列来的扩大卷积来增加感受野。扩大卷积(dilated convolution)是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。示意图如下:
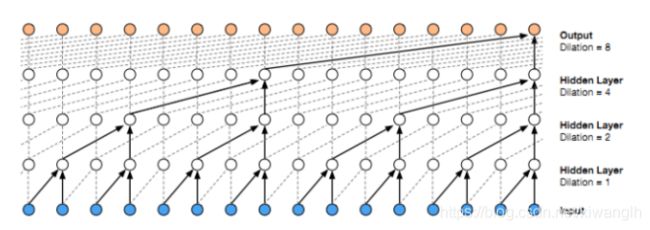
扩大卷积(dilated convolution)可以使模型在层数不大的情况下有非常大的感受野。
三、softmax distribution:
在使用混合样本进行建立条件分布模型时,这里采用了softmax distributions进行建模,其原因是softmax分布更加的灵活。其中我们用到了一个softmax函数,其函数公式为:
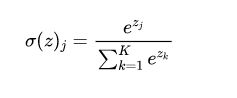
因为它只会被用在网络中的最后一层,用来进行最后的分类和归一化。Softmax用于多分类神经网络输出,目的是让大的更大。
因为原始音频通常存储为16位的整数值序列,这就要求我们的softmax层需要输出65536个概率值来进行建模所有的可能性,故我们先对数据进行一次u-law companding transformation将其量化为256个可能性。

四、Gated activation units:
对于门控激活函数来说,在WaveNet模型中引入激活函数,其原因是在数据分布中,绝大多数是非线性的,而一般神经网络计算是线性的,引入激活函数就是在神经网络中引入了非线性,强化了网络学习的能力。加入激活函数也充分的组合了特征。
在这里的gated activation模块,其公式为:
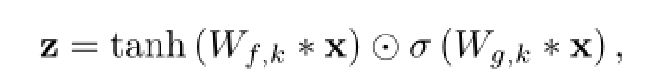
其中运用了tanh函数于sigmoid函数进行相乘,其中k是层索引,f为滤波器,g为一个门,W是一个可学习的卷积滤波器。其tanh函数为双曲正切函数,tanh和sigmoid都属于饱和函数,现在z的输出值范围在(-1,1)之间。通过tanh函数和sigmoid函数,解决了梯度消失问题。梯度消失/梯度爆炸:浅层的梯度计算需要后面各层的权重及激活函数层数乘积,可能出现前层比后层学习率小或大的问题,具有不稳定性。
Relu函数:该函数比较简单,公式为:relu=max(0, x)。其函数不是一奇函数,在神经网络中可以保留关键信息,去除噪音,可以使模型更加的具有鲁棒性。
在这里的激活函数中,不适用Relu函数而使用tanh函数是因为若在这里直接使用Relu函数将导致梯度消失问题,tanh函数是一奇函数,其求导之后范围仍在(0,1)之间。能更好的缓解梯度消失问题。
五、Residual and skip connections:
我们使用了residual 和skip connection技术来使模型更快收敛,并且使梯度能传到到更深层模型。其 剩余块和整个构架的概述为:
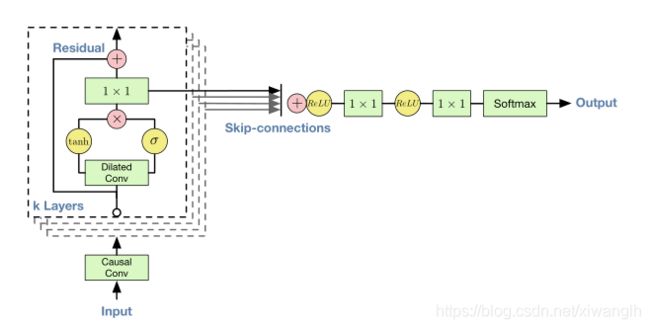
residual:对于残差网络来说,其公式为:![]()
深度学习会由于梯度过小问题出现梯度消失与梯度爆炸问题,梯度过小使得梯度在从目标函数向回传播时训练误差极小。如果一个网络深度越深,它在训练集上训练网络得效率就会减弱。残差得好处就是结构简单,解决了极深条件下深度卷积神经网络性能退化得问题。
skip connections:跳跃连接,用于残差网络中,作用在比较深得网络中,解决训练过程中得梯度消失和梯度爆炸问题。它可以将输出表述为输入和输入得一个非线性叠加。
六、Conditional WaveNet:
接收额外的输入h进行建模,通过条件分布建模,可以指定WaveNet生成我们想要得到的音频信息。其公式为:
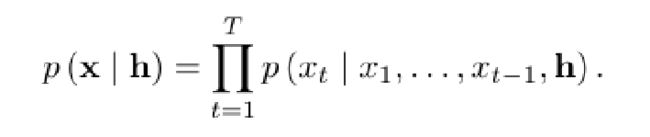
我们提出了两种条件建模方法:global conditioning和local conditioning。
global conditioning:接受单额外输入h,该额外输入在所有得时间点影响模型得输出。其激活函数变为:
![]()
local conditioning:现有一时间序列ht,通过对原始数据低采样率获得,通过转置卷积网络(上采样)将时间序列转换为和语音序列一样分辨率的新时间序列y。将其作用于激活单元。其激活单元公式变为:
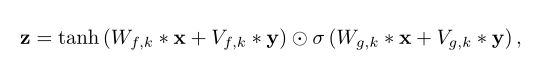
七、Experiments:
Multi-speaker speech generation:
WaveNet是一自回归的结构,在其没有条件输入情况下仍可产生语音,只不过是一些没有意义的噪声。该实验通过一个包含与多人的语音信息的语料库进行训练,在此实验中,我们没有规定其要说什么类型,什么方面的话,给的条件为发言者的id信息,没有文本,所以模型可以生成不存在的类似于人的发音的语音。存在着很多的不自然的地方,所以有很大的缺陷。 一个单一的WaveNet的模型可以基于任何一个编码的发言人id进行条件建模,有足够的能力去提取出所有的特征,说明此模型是强大的,除了提取声音之后,其还可以提取音频中的其他特征。
Text-to-speech:
TTS中的wavenet是根据输入文本的语言特征进行局部调节。 TTS合成的目标是在给定要合成的文本的情况下呈现自然发音的语音信号。
TTS可以看作是一个序列到序列的映射问题;从离散符号序列(文本)到实值时间序列(语音信号)。TTS可以分成两部分:文本分析和语音合成。
文本分析是通过一些前端的处理,将文本以一个词序列进行输入,输出一语音序列。 语音合成部分以上下文相关的音素序列作为输入,输出合成的语音波形。这一部分主要包括韵律预测和语音波形生成。
Music:
在音乐合成中,我们通过WaveNet条件建模的方式,让模型生成特定标签的声音,通过这中方式生成的音乐是有缺陷的,我们只能通过聆听产生的样本进行主观的评估来判断生成音乐的好坏,在其数据集中的标签有很多的噪声和遗漏。我们从测试数据集中随机选择一些固定样例作为评估数据集,用这个评估数据集生成的语音发送给打分的团队。我们通过和其他模型的比较来对比其效果。每个模型都是相互独立实施的。