MySQL之分布式事务
写在前面
当数据库进行了分库分表 之后为了保证数据的一致性。不可变的就需要引入跨数据的事务解决方案,这种解决方案我们叫做分布式事务。本文就一起来看下分布式事务相关的内容。
在8.0 版本上学习。
1:实战
为了能够更好的理解理论知识,我们先来简单看个实战,这里基于MySQL8来进行试验。我们知道,单机的事务一般是下边这样:
开启事务:
[begin|start transaction|start transaction with consistent snapshot]
提交事务:
commit
回滚事务:
rollback
分布式事务也是类似的,只不过命令有所不同,下面来看下。
1.1:准备库和表
CREATE SCHEMA db;
USE db;
CREATE TABLE `t` (
`id` INT NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb3 COLLATE=utf8_unicode_ci;
INSERT INTO t VALUES(1);
INSERT INTO t VALUES(2);
1.2:启动xa最终commit
- 打开两个会话A,B
- 在会话A启动xa,并执行一些更新操作
mysql> xa start 'xa-first';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t value(333);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t value(444);
Query OK, 1 row affected (0.00 sec)
- 在会话A执行xa end结束操作
mysql> xa end 'xa-first';
Query OK, 0 rows affected (0.00 sec)
- 在会话A执行xa prepare准备提交
mysql> xa prepare 'xa-first';
Query OK, 0 rows affected (0.00 sec)
- 在会话B执行查询
此时查询不到,因为会话A的事务还没有提交(分布式事务也是事务啊!):
mysql> select * from t;
+----+
| id |
+----+
| 1 |
| 2 |
+----+
2 rows in set (0.00 sec)
- 在会话A执行查询
mysql> select * from t;
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the PREPARED state
PREPARED状态,不让查,为啥???
- 在会话A执行xa commit提交
mysql> xa commit 'xa-first';
Query OK, 0 rows affected (0.00 sec)
- 在会话B执行查询
因为事务提交了所以可以正常查询:
mysql> select * from t;
+-----+
| id |
+-----+
| 1 |
| 2 |
| 333 |
| 444 |
+-----+
4 rows in set (0.00 sec)
1.3:启动xa最终rollback
- 打开两个会话A,B
- 在会话A启动xa,并执行一些更新操作
mysql> xa start 'xa-second';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t values(555);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t values(666);
Query OK, 1 row affected (0.00 sec)
- 在会话A执行xa end结束操作
mysql> xa end 'xa-second';
Query OK, 0 rows affected (0.00 sec)
- 在会话A执行xa prepare准备提交
mysql> xa prepare 'xa-second';
Query OK, 0 rows affected (0.00 sec)
- 在会话B执行查询
此时查询不到,因为会话A的事务还没有提交(分布式事务也是事务啊!):
mysql> select * from t;
+-----+
| id |
+-----+
| 1 |
| 2 |
| 333 |
| 444 |
+-----+
4 rows in set (0.00 sec)
- 在会话A执行查询
mysql> select * from t;
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the PREPARED state
PREPARED状态,不让查,为啥???
- 在会话A执行xa rollback回滚
mysql> xa rollback 'xa-second';
Query OK, 0 rows affected (0.00 sec)
- 在会话A执行查询
查询不到,以为回滚了:
mysql> select * from t;
+-----+
| id |
+-----+
| 1 |
| 2 |
| 333 |
| 444 |
+-----+
4 rows in set (0.00 sec)
实战结束,接着来看理论。
2:理论
2.1:为什么需要分布式事务
任何技术和事务都不是凭空产生的,肯定都是有某种力量的推动,而对于技术而言,这种力量来源于哪里呢?毫无疑问,是用户,看如下几个例子:
1:现在有A,B两个服务,通过同步调用方式来进行通信,当请求量达到一定的量级,这种同步的调用方式可能会将B服务的系统资源耗尽,比如CPU,线程资源等,这个时候怎么办呢?自然是降低请求量,那么如何降低请求量呢?有如下的几个办法:
1.1:让B服务多复制几份,注意!!!这个时候集群就出现了
1.2:让B需要处理的消息,暂时存储在某个地方,消息一部分一部分的给B而非一次全部塞过去,注意!!!这样就有了JMS,就有了消息队列
2:一个单体的数据库,随着业务的发展,存储的数据越来越多,用户的访问量也越来越大,逐渐的我们会发现如下的几个问题
2.1:数据存不下了,怎么办?那就只能把数据分开存储,注意!!!这样就有了分库分表
2.2:数据库的读压力太大了,已经快要扛不住了,怎么办?那就再将数据复制到其他几个数据库,专门负责读吧,注意!!!这样就有了读写分离
那么我们这里要看的分布式事务,是要解决什么问题呢?解决因为分库分表带来的数据一致性问题。业务初期表都是在一个数据库里,但当分到多个库里,比如一个一张订单表,一张订单详情表,就需要通过分布式事务来解决。看下图:
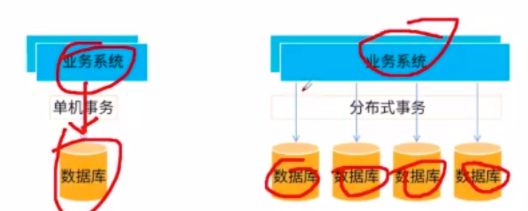
2.2:分布式事务
2.2.1:什么叫分布式事务
在分布式的环境下,不同的节点,整体事务的一致性叫做分布式事务。或者是多个小的事务组合在一起,保证数据一致性,就叫做分布式事务。
多个节点,如果是有的节点事务成功了,有的节点事务失败了,那么对于外界来说,整体的数据就是不一致的,参考下图:
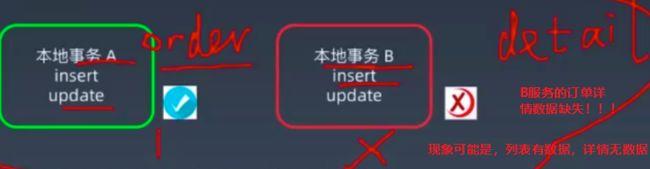
2.2.2:分布式事务哪些类型
分布式事务的类型我们也可以分为强一致性和弱一致性,如下:
强一致性(数据库提供保证):
简单讲就是,效果同单机事务,数据永远是一致的,此时需要引入某种协调机制。场景如金融交易类
弱一致性(业务侧提供保证):
简单将就是,在一段时间内数据可以是不一致的,然后通过某些定时补偿机制,柔性事务框架(tcc,saga等)达到数据的最终一致性。场景如T+1操作(转账隔天到账),电商类操作。
强一致性的数据库协议是XA(MySQL提供了具体的实现,即文章开头的实战例子),弱一致性(柔性事务)一般是通过业务冲正实现。
3:刚性事务
3.1:XA分布式事务协议角色
- 应用程序
Application program,简称AP。负责开始事务,执行各种操作,以及结束事务。 - 事务管理器
事务框架如seata扮演的就是这里的角色。
Transactin Manager,简称TM,负责给事务分配唯一标识,管理事务(提交,回滚等)
- 资源管理器
resource manager ,简称RM,负责具体的数据存取,如MySQL
结构参考下图:
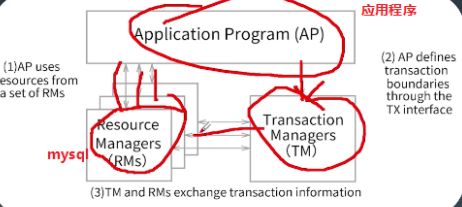
XA协议需要资源管理器和事务管理器两个角色,并定义了协议相关的接口(后面分析到),不管是资源管理器还是协议管理器都需要按照接口规范来提供实现,目前MySQL数据库在5.0版本就已经提供了具体实现,这样资源管理器就已然是提供了具体支持。为了让规范java对于事务管理器的实现,jdk按照XA协议定义了java的规范接口,这个接口规范就叫做JTA,JTA当前具体的实现框架有Atomikos,nirayana,seata等。
最后看下AP,TM,RM对应的具体都是啥:
AP:我们的应用程序,即写代码的地方
TM:如seata,atomikos,nirayana框架
RM:MySQL,也可以是mq等其它存储数据的中间件,只要按照XA协议提供具体实现即可。
3.2:XA分布式事务协议接口
- xa-start
开启一个事务分支,之后就可以开始调用RM来执行数据库操作了。AP调用TM完成。 - xa-end
结束一个事务分支,之后就无法继续调用RM执行数据库操作了。AP调用TM完成。
xa-start和xa-end之间是真实的数据库CRUD操作。
- xa-prepare
询问RM是否准备好提交事务,AP调用TM(TM调用RM)完成,如果该阶段成功就可以准备事务了。
处于prepare状态的RM会话内无法执行任何操作,包括select,不知道为啥!
- xa-commit
通过RM提交事务分支,AP调用TM,TM调用RM完成。 - xa-rollback
通知RM回滚事务,AP调用TM,TM调用RM完成 - xa-recover
需要回复的xa事务
3.3:MySQL对于xa的支持
MySQL在5.0版本中完成了对于xa的支持,可以通过show ENGINEs查看是否支持分布式事务,如下就是截图:

MySQL对应的xa协议语句如下(本文开头实战例子已经用过了):
xa start xid
开启一个事务分支,xid是事务分支的唯一标示,TM通过此标识唯一管理一个RM
xa end xid
通过事务分支唯一标示xid,结束一个事务分支
xa prepare xid
通过事务分支唯一标示,准备一个事务分支
xa commit xid
通过事务分支唯一标示,提交一个事务分支
xa rollback xid
通过事务分支唯一标示,回滚一个事务分支
xa rollback
列出所有处于prepare状态的事务分支
需要注意,单机事务和分布式事务是互斥的,即通过了xa start开启了一个新的分布式事务分支,则不能通过start transaction启动一个本地事务,知道xa commit,或xa rollback。同理,如果是通过start transaction启动了本地单机事务,也无法通过xa start启动分布式事务分支,知道本地单机事务执行了commit,或rollback。
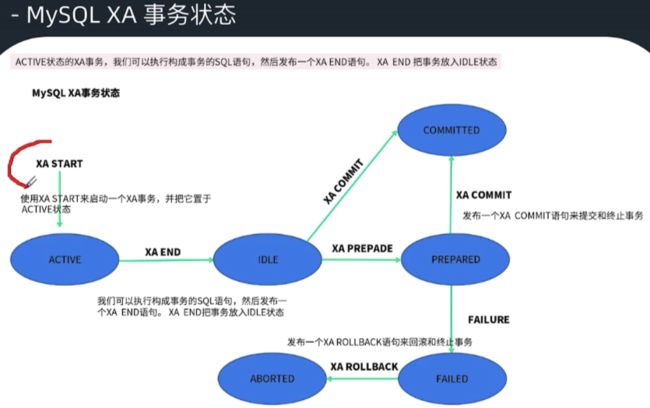
3.4:XA事务的状态
xa start:变为active状态
xa end:变为IDLE状态
xa prepared:变为prepared状态
xa commited:变为committed状态
xa rollback:变为aborted状态
如下图:
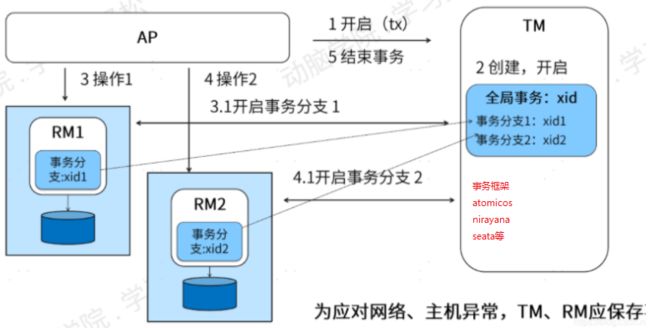
3.5:xa事务完整执行过程
参考下图:
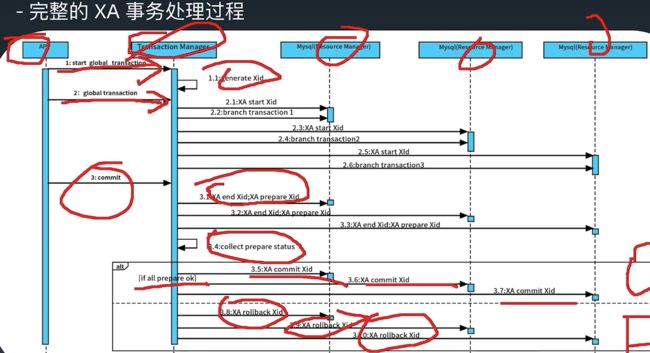
可以看到对于AP来说,只需要start transaction,以及commit,所有的细节,如xa start,xa end,xa prepare,xa commit,xa rollback TM已经给我们封装好了,
异常情况分析:
1:业务sql执行过程中,即执行xa end前,某个RM崩溃?
TM给所有的RM执行xa rollback。
2:全部prepare后,某RM崩溃,怎么办?
TM给所有的RM执行xa rollback
3: xa commit时某个RM崩溃?
TM重试,直到成功,一直不成功,业务侧需要有补偿机制,保证成功
使用xa来实现分布式事务的话,因为在commit或者是rollback之前,数据库资源都是锁定的,所以会严重影响并发性能,如果是长事务的话,性能会退化为原来的十分之一左右,如果是时间比较短的短事务的话,性能退化相对好些,大概是原来的三分之一。所以因为性能问题如果是不必要的话,还是要慎重使用xa事务。因此,xa适合用在低并发&短事务的场景中。
xa会导致性能的严重衰退。
4:BASE柔性事务
CAP对于大规模并不是十分适用的,因为为了保证A,可能需要很多额外的机器和组件,从而成本会比较高,为了保证C,大规模集群会降低SLO, 因此就有了BASE 。
BASE的BA:basically available,基本可用,是对可用的妥协,当部分节点不可用时,服务依然是可用的
BASE的S:soft state,柔性状态,即数据暂时的不一致的状态,或者是从不一致到一直变化的过程
BASE的E:eventually consistency,最终一致,即数据最终是一致的
接下来我们看下实现BASE柔性事务都有哪些模式和框架。
4.1:柔性事务模式
4.1.1:TCC
需要手动补偿事务(cancel这一步需要写代码,如try阶段执行了insert,则在cancel要写对应的delete,try阶段将id=1的name值从张三修改为例子,则在cancel要写对应的代码将)。
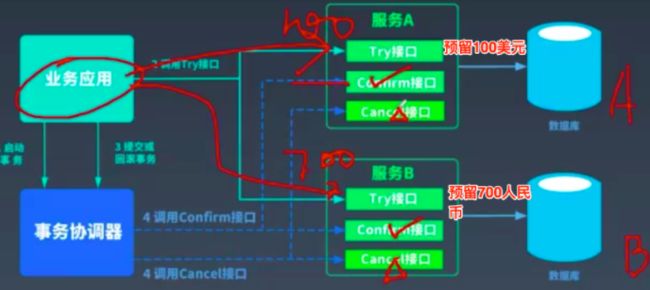
4.1.1.1:TCC核心内容
TCC,是try,confirm,cancel这三个单词的简称,即TCC分为两个阶段,第一个是T阶段,尝试预留资源(如扣减余额场景判断是否足够扣减,足够则先通过冻结预留资源,注意需要事务),第二个是Confirm/Cancel阶段,如果是所有的事务try都成功,则执行confirm(如扣减余额场景,真正的去扣减用户的余额,注意需要事务),否则执行cancel回滚try操作预留的资源(注意cancel需要根据不同的业务来提供具体的程序,如扣减余额场景)。具体如下:
T:try,完成业务检查(如扣减余额够扣嘛?),预留资源
C:confirm,真正的执行业务操作,如果是try成功,这一阶段一定会成功,因为已经完成了业务检查(如余额肯定是够扣减的)
C:cancel,如果是T阶段失败,则释放T阶段预留的资源,即回滚T事务产生的影响(如扣减余额场景,向冻结表中添加了100的扣减金额,则这一步需要从冻结表中删除这条记录,消除影响,恢复到初始状态,注意这里的冻结表需要我们额外创建,并开发相关程序)
TCC对业务是具有比较强的侵入性的,因为TCC中,RM不需要像XA那样具备分布式事务的能力,所有分布式事务相关的逻辑都是通过编码的方式来实现的,即在每个服务中我们都要实现相对应的try接口,confirm接口和cancel接口,参考下图:
4.1.1.2:TCC需要注意的问题
- 允许空回滚
如果是try没有成功,cancel也要允许执行,并且不能造成数据一致性问题,如在转账的场景中try阶段要冻结用户的100元,但是最终没有冻结成功,则在cancel阶段不能反向冻结这100元,而是应该什么都不做,因为try本来就什么都没有做。相关的框架要考虑到这种情况的处理。 - 防悬挂
当cancel早于try收到,此时可能出现先执行cancel,后执行try的情况,那么try就没有机会取消了,这种情况叫做悬挂,应该防止这种情况的发生。
比如转账的场景中,在try阶段要冻结用户的100元人民币,cancel阶段取消冻结用户的100元人民币,如果是cancel先执行的话,那么用户的100元人民币就永远冻结了。相关的框架要考虑到这种情况的处理。
- 幂等
不管是try,confirm,cancel,都需要时幂等的,即多次调用的效果和一次调用是一样的。相关的框架要考虑到这种情况的处理。
比如转账的场景中,try阶段要冻结用户的100元人民币,如果是调用多次就多次冻结用户的钱,那就出问题了。转100,却少了300 o(╥﹏╥)o。
4.1.2:AT
AT的A是automatic的意思,即一种自动的分布式事务模式,这里我们可以和手动的TCC来对比看,手动的TCC手动是体现在cancel阶段,需要开发人员来实现对应的取消try逻辑,而AT的自动也体现在这里,因为这个取消的逻辑是自动生成的。另外AT不同于TCC,其是两阶段的,即直接提交事务,以及回滚事务,如下图:
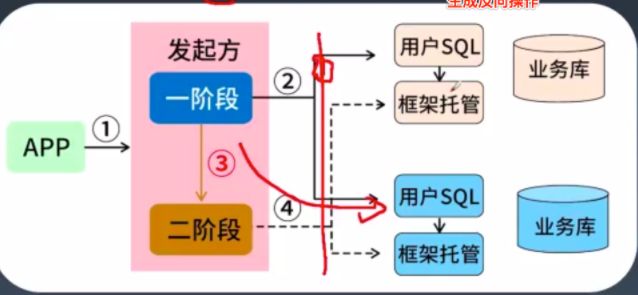
但是目前这种方式使用的是不多的,因为这里要实现automatic需要有支持解析sql为反向操作sql的框架的支持,但是目前还没有一种框架可以做到百分之百的支持(因为sql太灵活了,各种写法,就像积木一样,你可以搭建成各种样式的!!!)。所以在业务中就不要考虑这种方式了。
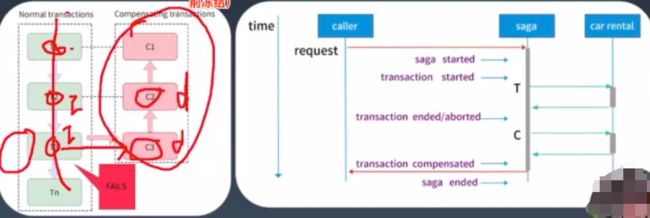
4.1.3:SAGA
saga由多个小事务组成,每个小事务都有对应的回滚逻辑事务,这种方式更符合常规的思维方式,所以当前这种模式是使用的最多的,如下图:
4.2:柔性事务的隔离级别
注意是量分布式事务作为一个整体来分析。
- 原子性
基本(atomicity),正常情况下保证(分布式事务无法做到百分之百的没有问题,所以需要一些额外的补偿机制)。 - 一致性
在某些时间点,是不一致的。但最终是一致的。 - 隔离性
在某些时间点,不满足隔离性,因为本质上每个数据库上的事务还是独立的,只不过所有的小事务在逻辑上组成了整体的分布式事务。 - 持久性
分布式事务最终都提交成功之后是持久的(因为每个独立的事务肯定是满足持久性的,所以整体的分布式事务也是满足持久性的)。
4.3:柔性事务框架
4.3.1:seata
seata是阿里和蚂蚁金服共同开发的分布式事务框架,支持TCC模式,AT模式两种。
4.3.2:hmily
hmily 支持TCC,模式,功能更加全面,也有UI操作界面,可以考虑使用起来。
base柔性事务也可以说是业务侧的分布式事务,因为需要在业务测编写响应的代码来保证分布式事务的一致性,在db侧其实还是单机事务的,所以,这种方式,对于性能的并不是非常严重,即略有衰退,大概衰退为原来的百分之六十到百分之七十左右,因此这种方式适合用在高并发&长事务中。
4.3.3:shardingsphere
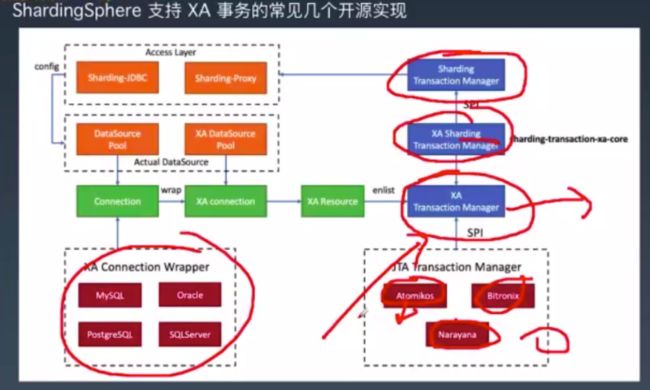
shardingsphere准确来说并不是一个分布式事务框架,因为其只是对相关的框架做了封装,如下对基于XA的刚性事务框架atomikos,nirayana的封装结构图:
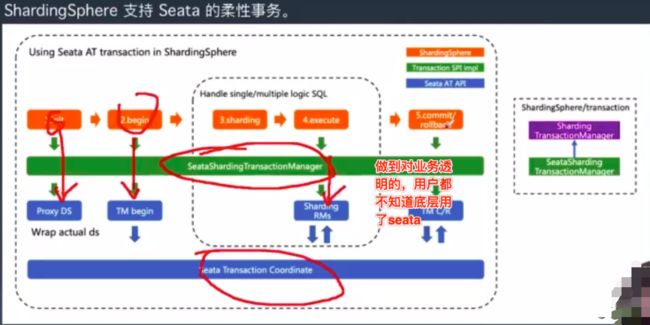
如下是对柔性事务框架的支持:
写在后面
参考文章列表
总结
分布式事务是为了解决微服务场景下跨多服务多数据库组件操作的数据库一致性问题,分为刚性事务和柔性事务,其中XA协议是实现刚性事务,对应的框架有atmikos,nirayana,seata,柔性事务TCC,框架tcc transaction,seata。刚性事务属于同步操作,适合于短时间的小事务,实现强一致性。柔性事务实现的最终一致性。
seata即支持xa的刚性事务,也支持tcc的柔性事务。我们说seata支持不同的事务模式。