Node.js爬虫只会Cheerio?来试试Puppeteer!
简介
上篇文章我们学习了如何通过 Cheerio 来爬取静态页面,但是我们没有办法处理动态渲染页面的数据
关于 Cheerio 的学习请查看 都 2023 年了还不会 Node.js 爬虫?快学起来!今天我们学习如何使用 Puppeteer 来轻松地完成我们解决不了的爬虫任务
什么是Puppeteer
Puppeteer 是一个由 Google 开发的 Node.js 库,它提供了一组用于控制 Headless Chrome 的 API。
Headless Chrome 是 Chrome 浏览器的无界面版本,可以用于模拟用户行为、测试网站、爬取数据等多种用途。
Puppeteer 提供了一系列的 API,可以让我们控制 Chrome 浏览器的各种行为,例如打开网页、模拟用户操作、获取网页内容等。
总之,Puppeteer 是一个非常强大且易于使用的工具,可以帮助我们轻松地完成各种 Web 自动化和爬虫任务。
Puppeteer的优势
- 完全支持最新的 Web 标准和技术:Puppeteer 支持最新的 Web 标准和技术,例如 ES6、Promise、async/await 等。这样,我们可以使用最新的 JavaScript 特性来编写爬虫代码,使代码更加简洁、易读、易维护。
- 支持动态网站的爬取:Puppeteer 可以处理 JavaScript 渲染的页面,也就是说它可以爬取动态网站,这是其他爬虫框架所不具备的优势。
- 可以模拟真实的用户行为:Puppeteer 可以模拟真实的用户行为,例如点击按钮、填写表单、滚动页面等。
- 可以生成 PDF 和截屏等多种格式的输出:Puppeteer 可以生成 PDF 和截屏等多种格式的输出,这对于需要对网站进行分析或者展示结果的情况非常有用。
- 可以与其他 Node.js 库和框架无缝集成:Puppeteer 可以与其他 Node.js 库和框架无缝集成,例如 Express、Koa、Mocha、Jest 等。这样,我们可以将 Puppeteer 用于自动化测试、Web 开发等领域。
Puppeteer基本用法
安装配置
使用 npm 安装 Puppeteer:
npm install puppeteer
Puppeteer 默认会从 Google 的服务器下载 Chrome 浏览器二进制文件,如果您的网络环境无法访问 Google 的服务器,可以通过以下方式配置 Puppeteer:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: true, // 是否启用无头模式
executablePath: '/path/to/Chrome', // Chrome 浏览器可执行文件路径
args: ['--no-sandbox'], // Chrome 启动参数
});
const page = await browser.newPage();
await page.goto('https://example.com');
// ...
await browser.close();
})();
我们通过 executablePath 和 args 选项来指定 Chrome 浏览器的可执行文件路径和启动参数
这样,我们就可以在没有网络的情况下使用 Puppeteer
打开网页
使用 puppeteer.launch() 方法启动 Chrome 浏览器,并创建一个新的页面对象:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch(); // 启动 Chrome 浏览器
const page = await browser.newPage(); // 创建一个新的页面对象
await page.goto('https://example.com'); // 打开一个网页
// ...
await browser.close();
})();
在上面的代码中,我们使用 puppeteer.launch() 方法启动 Chrome 浏览器,并使用 browser.newPage() 方法创建一个新的页面对象,然后,我们使用 page.goto() 方法打开一个网页。
launch配置
在使用 puppeteer.launch() 方法启动 Chrome 浏览器时,可以通过传递一些配置选项来控制 Chrome 浏览器的启动行为。下面是常用的配置选项:
headless:是否启用无头模式,默认为true。executablePath:Chrome 浏览器可执行文件路径。args:Chrome 启动参数。defaultViewport:默认的浏览器窗口大小。timeout:超时时间,单位为毫秒。
下面是一个使用 puppeteer.launch() 方法的示例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: true,
executablePath: '/path/to/Chrome',
args: ['--no-sandbox'],
defaultViewport: {
width: 1280,
height: 800,
},
timeout: 30000,
});
const page = await browser.newPage();
await page.goto('https://example.com');
// ...
await browser.close();
})();
在上面的代码中,我们使用了常用的配置选项:
headless选项设置为true,启用无头模式。executablePath选项指定 Chrome 浏览器的可执行文件路径。args选项指定 Chrome 启动参数,例如--no-sandbox表示禁用沙盒模式。defaultViewport选项指定默认的浏览器窗口大小。timeout选项指定超时时间为 30 秒。
下面是更详细的配置列表:
puppeteer.launch({
headless: true, // 是否以无头模式运行浏览器,默认为true
executablePath: '', // 可执行文件路径,如果不指定则自动下载
args: [], // 命令行参数数组
ignoreDefaultArgs: false, // 是否忽略默认的命令行参数
defaultViewport: null, // 默认视窗大小,null表示自动设置
slowMo: 0, // 延迟毫秒数,用于调试
timeout: 30000, // 超时时间,单位为毫秒
devtools: false, // 是否打开DevTools面板,默认为false
pipe: false, // 是否将浏览器启动的I/O连接通过管道传递,默认为false
handleSIGINT: true, // 是否在收到SIGINT信号时关闭浏览器,默认为true
handleSIGTERM: true, // 是否在收到SIGTERM信号时关闭浏览器,默认为true
handleSIGHUP: true, // 是否在收到SIGHUP信号时关闭浏览器,默认为true
env: {}, // 环境变量对象
userDataDir: '', // 用户数据目录路径
dumpio: false, // 是否将浏览器I/O输出到进程的stdout和stderr中,默认为false
executablePath: '', // 可执行文件路径,如果不指定则自动下载
ignoreHTTPSErrors: false, // 是否忽略HTTPS错误,默认为false
ignoreCertificateErrors: false // 是否忽略SSL证书错误,默认为false
});
获取元素
使用 page.$() 方法获取一个元素:
const element = await page.$('selector');
在上面的代码中,我们使用 page.$() 方法获取一个元素。
其中,selector 参数可以是 CSS 选择器、XPath 表达式或者其他选择器。
点击按钮
使用 element.click() 方法点击一个按钮:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await element.click();
await browser.close();
})();
在上面的代码中,我们使用 element.click() 方法点击一个按钮。
填写表单
使用 element.type() 方法填写表单:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await element.type('text');
await browser.close();
})();
在上面的代码中,我们使用 element.type() 方法填写表单。其中,text 参数是要填写的文本内容。
截屏
使用 page.screenshot() 方法截屏:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();
在上面的代码中,我们使用 page.screenshot() 方法截屏,并将截屏保存为 PNG 格式的文件。
还有很多常见的puppeteer基本用法,这里不一一介绍,用到的时候去官方文档查看对应的API即可
Puppeteer进阶用法
模拟用户行为
点击元素
使用 element.click() 方法模拟点击元素:
await element.click();
在上面的代码中,我们使用 element.click() 方法模拟点击元素。
输入文本
使用 element.type() 方法输入文本:
await element.type('text');
在上面的代码中,我们使用 element.type() 方法输入文本。其中,text 参数是要输入的文本。
选择选项
使用 element.select() 方法选择选项:
await element.select('value');
在上面的代码中,我们使用 element.select() 方法选择选项。其中,value 参数是要选择的选项值。
滚动页面
使用 page.evaluate() 方法执行 JavaScript 代码来滚动页面:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
let previousHeight;
while (true) {
const currentHeight = await page.evaluate(() => {
return document.documentElement.scrollHeight;
});
if (currentHeight === previousHeight) {
break;
}
previousHeight = currentHeight;
await page.evaluate(() => {
window.scrollBy(0, window.innerHeight);
});
await page.waitForTimeout(1000);
}
const content = await page.$('#content');
console.log(await content.textContent());
await browser.close();
})();
在上面的代码中,我们使用 Puppeteer 打开一个需要滚动的网页,并模拟滚动操作,直到页面滚动到底部,然后获取页面中的内容。
处理动态内容
等待元素出现
使用 page.waitForSelector() 方法等待元素出现:
await page.waitForSelector('selector');
在上面的代码中,我们使用 page.waitForSelector() 方法等待元素出现。
其中,selector 参数可以是 CSS 选择器、XPath 表达式或者其他选择器。
等待页面加载完成
使用 page.waitForNavigation() 方法等待页面加载完成:
await page.goto('https://example.com');
await page.waitForNavigation();
在上面的代码中,我们使用 page.goto() 方法打开一个网页,并使用 page.waitForNavigation() 方法等待页面加载完成。
处理验证码
Puppeteer 可以通过打码平台来识别验证码。以下是一个使用打码平台的示例:
const antiCaptcha = require('anticaptcha');
const client = new antiCaptcha('API_KEY');
const image = await page.screenshot({ encoding: 'base64' });
const taskId = await client.createTask({
type: 'ImageToTextTask',
body: image,
});
const solution = await client.getTaskSolution(taskId);
await page.type('#captcha', solution.text);
在上面的代码中,我们使用 page.screenshot() 方法获取验证码图片,并使用打码平台识别验证码,最后将识别结果输入到验证码输入框中。
处理登录
以下是一个使用 Puppeteer 处理登录的示例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com/login');
await page.type('#username', 'your-username');
await page.type('#password', 'your-password');
await page.click('#login-button');
await page.waitForNavigation();
const content = await page.$('#content');
console.log(await content.textContent());
await browser.close();
})();
在上面的代码中,我们使用 page.goto() 方法打开登录页面,并使用 page.type() 方法输入用户名和密码,最后使用 page.click() 方法提交登录表单,然后获取页面中的内容。
定时爬取
puppeteer可以实现定时爬取数据,以下是一个使用 Puppeteer 配合 node-schedule 实现定时爬取的示例:
const puppeteer = require('puppeteer');
const schedule = require('node-schedule');
// 每隔一段时间执行一次爬取数据函数
const job = schedule.scheduleJob('自动爬虫任务', '30 20 * * * *', async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
// 模拟滚动到页面底部
await page.evaluate(async () => {
await new Promise(resolve => {
let totalHeight = 0;
const distance = 100;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 100);
});
});
// 等待列表加载完成
await page.waitForSelector('.list-item');
// 获取列表数据
const listItems = await page.$$('.list-item');
const data = await Promise.all(listItems.map(async listItem => {
const title = await listItem.$eval('.title', el => el.textContent);
const description = await listItem.$eval('.description', el => el.textContent);
return { title, description };
}));
console.log(data);
await browser.close();
});
// 取消定时任务
// job.cancel();
在这个示例中,我们使用node-schedule库创建了一个定时任务,每小时的0分执行一次。在任务中包含了获取数据的代码,与前面的示例类似。如果需要取消定时任务,可以使用job.cancel()方法。
自动化测试
Puppeteer 可以用于自动化测试,以下是一个使用 Puppeteer 进行自动化测试的示例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.title();
if (title !== 'Example Domain') {
console.error('Title is not correct');
}
const url = await page.url();
if (url !== 'https://example.com/') {
console.error('URL is not correct');
}
await browser.close();
})();
在上面的代码中,我们使用 Puppeteer 打开一个网页,并检查页面标题和 URL 是否正确。
实战案例
CSDN作者榜
我们打开网址https://blog.csdn.net/rank/list/total来看看CSDN作者总榜
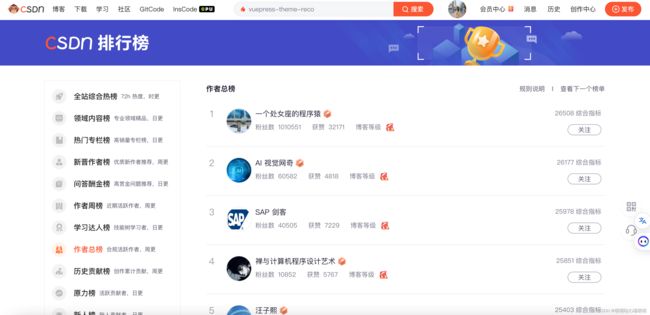
还是和静态页面一样,我们来分析一下页面结构,找到我们想要拿到的数据:

下面我们来用puppeteer来实现爬取这个作者榜:
// 无头浏览器模块
const puppeteer = require("puppeteer");
const fs = require('fs');
// 目标页面
const crawlPage = "https://blog.csdn.net/rank/list/total";
// 网页爬虫
(async function crawler() {
//创建实例
const browser = await puppeteer.launch({
//无浏览器界面启动
headless: "new",
//放慢浏览器执行速度,方便测试观察
slowMo: 100,
// 设置打开的浏览器窗口尺寸
defaultViewport: { width: 960, height: 540 },
});
// 新开一个tab页面
const page = await browser.newPage();
// 加载目标页,在 500ms 内没有任何网络请求才算加载完
await page.goto(crawlPage, { waitUntil: "networkidle0" });
// 在无头浏览器页面dom环境,获取页面数据
const authorList = await page.evaluate(() => {
const list = [];
document.querySelectorAll(".floor-rank-total .floor-rank-total-item").forEach((ele) => {
const rank = ele.querySelector(".total-content .number").innerText;
const title = ele.querySelector(".total-box dd a").innerText;
const fans = ele.querySelector(".total-box dt span:nth-child(1)").innerText;
list.push({
'排名': rank,
'作者': title,
'粉丝': fans,
});
});
return list;
});
// console.log(authorList);
// 将数据写入文件中
fs.writeFile('./csdnAuthor.json', JSON.stringify(authorList), function (err, data) {
if (err) {
throw err
}
console.log('文件保存成功');
})
// 关闭tab页
await page.close();
// 关闭实例
await browser.close();
})();
看看json文件里有什么吧:
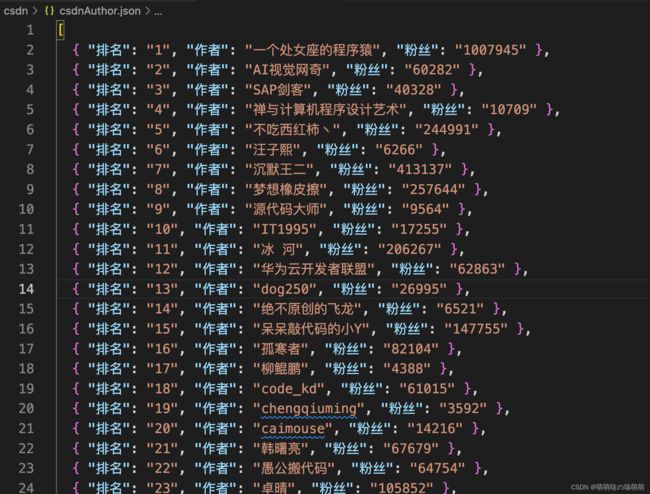
没有问题,成功拿到了我们想要的CSDN作者总榜页面的排名、作者和粉丝数量!
掘金小册
掘金小册的内容质量非常高,推荐大家可以去看一看,接下来我们来爬取一下目前发布所有的掘金小册
我们来分析一下掘金小册的页面结构,我们想要拿到的数据有:小册名称、小册简介、小册作者、小册价格
我们来用puppeteer来实现爬取,要注意的是掘金小册页面不会全部加载所有小册,因此我们需要用puppeteer模拟用户行为,将页面列表滚动到最底部,加载完所有的小册列表数据后再进行爬取:
// 无头浏览器模块
const puppeteer = require("puppeteer");
const fs = require('fs')
// 目标页面
const crawlPage = "https://juejin.cn/course";
// 网页爬虫
(async function crawler() {
//创建实例
const browser = await puppeteer.launch({
//无浏览器界面启动
headless: "new",
//放慢浏览器执行速度,方便测试观察
// slowMo: 100,
// 设置打开的浏览器窗口尺寸
defaultViewport: { width: 960, height: 540 },
});
// 新开一个tab页面
const page = await browser.newPage();
// 加载目标页,在 500ms 内没有任何网络请求才算加载完
await page.goto(crawlPage, { waitUntil: "networkidle0" });
// 模拟滚动到页面底部
await page.evaluate(async () => {
await new Promise((resolve) => {
let totalHeight = 0;
const distance = 200;
const timer = setInterval(() => {
const scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
clearInterval(timer);
resolve();
}
}, 200);
});
});
// 等待列表加载完成
await page.waitForSelector('.books-view');
// 在无头浏览器页面dom环境,获取页面数据
const articleList = await page.evaluate(() => {
const list = [];
const itemSelector = ".books-view > div:last-child > div > div > a";
document.querySelectorAll(itemSelector).forEach(async(ele) => {
const title = await ele.querySelector(".book-info .text-highlight").innerText;
const desc = await ele.querySelector(".book-info .text-highlight.desc").innerText;
const author = await ele.querySelector(".book-info .author .name").innerText;
const price = await ele.querySelector(".book-info .other .origin-price").innerText;
list.push({
'小册名称': title,
'小册简介': desc,
'小册作者': author,
'小册价格': price,
});
});
return list;
});
// console.log(articleList);
// 将数据写入文件中
fs.writeFile('./xiaoce.json', JSON.stringify(articleList), function (err, data) {
if (err) {
throw err
}
console.log('文件保存成功');
})
// 关闭tab页
await page.close();
// 关闭实例
await browser.close();
})();
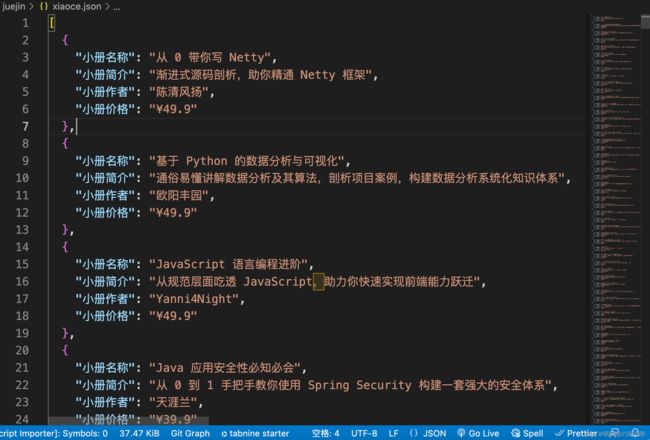
保存的JSON文件数据如下,可以看到成功获取了所有小册数据:
模拟登录
我们通过 cookie 模拟登录环境,我们去谷歌应用商店下载一个插件 “Export cookie JSON file for Puppeteer”
这个 chrome 插件直接获取 cookie 信息

然后运行这个插件,下载CSDN cookie的json文件,代码很简单:
const puppeteer = require("puppeteer");
// 通过 插件 获取的 JSON化 cookie
const cookieObjects = require("./csdn.net.cookies.json");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setViewport({ width: 1400, height: 1080 });
cookieObjects.forEach((cookie) => {
page.setCookie(cookie);
});
await page.goto("https://www.csdn.net/");
})()
运行程序,自动打开浏览器,模拟登录成功:
总结
Puppeteer 是一个功能强大的 Node.js 库,可以用于控制 Chrome 或者 Chromium 浏览器,实现自动化测试、爬虫、网页截图等功能。以下是 Puppeteer 的一些优点和缺点:
优点
- 功能强大:Puppeteer 支持大部分 Chrome DevTools 协议中的功能,包括页面截图、模拟用户操作、处理动态内容等。
- 易于使用:Puppeteer 的 API 设计简单易用,上手容易。
- 可扩展性强:Puppeteer 可以与其他 Node.js 库和工具集成,扩展其功能。
- 社区活跃:Puppeteer 有一个活跃的社区,可以获取到大量的文档、教程和示例。
缺点
- 依赖 Chrome 或者 Chromium 浏览器:Puppeteer 需要依赖 Chrome 或者 Chromium 浏览器才能运行,这会导致一定的资源占用。
- 不支持其他浏览器:Puppeteer 只支持 Chrome 和 Chromium 浏览器,不支持其他浏览器。
- 可能被网站检测到:由于 Puppeteer 可以模拟用户行为,因此有些网站可能会检测到 Puppeteer 的使用并阻止其访问。
总的来说,Puppeteer 是一个非常有用的工具,可以帮助开发人员和测试人员提高工作效率。
如果需要进行自动化测试、爬虫或者网页截图等操作,Puppeteer 是一个值得尝试的工具。
未来发展
随着互联网技术的发展和应用场景的不断扩大,爬虫技术将会得到更广泛的应用和更深入的研究。
以下是爬虫技术未来的一些发展方向:
- 智能化:随着人工智能技术的发展,我们可以将人工智能技术应用到爬虫技术中,使得爬虫可以自主学习和适应不同的网站结构。
- 安全性:随着网站安全性的提升,一些网站可能会采取更加复杂和严格的反爬虫机制。因此,未来的爬虫技术需要更加注重安全性和隐私保护。
- 大数据:随着大数据技术的发展,我们可以将爬虫技术与大数据技术相结合,用于数据分析和挖掘。
- 分布式:随着云计算技术的发展,分布式爬虫将会成为未来的趋势,可以更加高效地抓取大量数据。
总之,爬虫技术在未来将会得到更广泛和深入的应用,并且将会不断地发展和完善。