Python解析MDX词典数据并保存到Excel
原始数据和处理结果:
https://gitcode.net/as604049322/blog_data/-/tree/master/mdx
下载help.mdx词典后,我们无法直接查看,我们可以使用readmdict库来完成对mdx文件的读取。
安装库:
pip install readmdict
对于Windows平台还需要安装python-lzo:
pip install python-lzo
使用Python读取的示例:
from readmdict import MDX
mdx_file = "help.mdx"
mdx = MDX(mdx_file, encoding='utf-8')
items = mdx.items()
for key, value in items:
word = key.decode().strip()
print(word, value.decode())
break
a
可以看到,词典详情数据以JavaScript脚本形式存在,我们可以使用正则+json进行解析:
import re
json.loads(re.findall('"data":(\[.+\])}\);', value.decode())[0])
[{'id': 'a',
'isroot': True,
'topic': 'a',
'describe': '英[ə; eɪ]美[ə; e]art. 一'}]
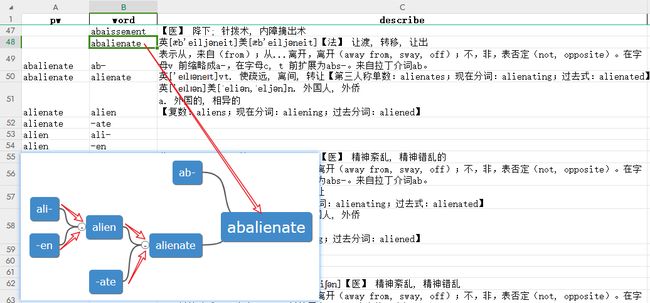
当然这只是最简单的一种情况,下面我们看看一个存在树形关系的单词的例子:
from readmdict import MDX
import re
mdx_file = "help.mdx"
mdx = MDX(mdx_file, encoding='utf-8')
items = mdx.items()
for key, value in items:
word = key.decode().strip()
topic = json.loads(re.findall('"data":(\[.+\])}\);', value.decode())[0])
if word == "abalienate":
print(word, topic)
break
abalienate [{'id': 'abalienate', 'isroot': True, 'topic': 'abalienate', 'describe': "英[æb'eiljəneit]美[æb'eiljəneit]【法】 让渡, 转移, 让出"}, {'id': 'ab-', 'parentid': 'abalienate', 'direction': 'left', 'topic': 'ab-', 'describe': '表示从,来自(from);从...离开,离开(away from, sway, off);不,非,表否定(not, opposite)。在字母v 前缩略成a-,在字母c, t 前扩展为abs-。来自拉丁介词ab。'}, {'id': 'alienate', 'parentid': 'abalienate', 'direction': 'left', 'topic': 'alienate', 'describe': "英['eɪlɪəneɪt]vt. 使疏远, 离间, 转让\n【第三人称单数:alienates;现在分词:alienating;过去式:alienated】"}, {'id': 'alien', 'parentid': 'alienate', 'direction': 'left', 'topic': 'alien', 'describe': "英['eɪlɪən]美[ˈeliən,ˈeljən]n. 外国人, 外侨\na. 外国的, 相异的\n【复数:aliens;现在分词:aliening;过去分词:aliened】"}, {'id': '-ate', 'parentid': 'alienate', 'direction': 'left', 'topic': '-ate', 'describe': [['表动词,“做,造成”。']]}, {'id': 'ali-', 'parentid': 'alien', 'direction': 'left', 'topic': 'ali-', 'describe': [['= other, to change, 表示“其他的,改变状态”,来源于拉丁语 alius "another, other, different."']]}, {'id': '-en', 'parentid': 'alien', 'direction': 'left', 'topic': '-en', 'describe': [['表名词,“人或物”,有时构成小词或昵称。']]}]
同时我们可以看到有部分词的描述可能会嵌套列表。
下面我们的目标是将每个单词都处理成如下形式:

最终的完整代码为:
from readmdict import MDX
import re
import json
import csv
def get_describe(describe):
if isinstance(describe, (list, tuple)):
return ';'.join(get_describe(i) for i in describe)
else:
return describe
def deal_node(node, result=[], num=-1):
chars = "■□◆▲●◇△○★☆"
for k, (d, cs) in node.items():
if num >= 0:
d = d.replace('\n', '')
result.append(f"{' '*num}{chars[num]} {k}: {d}")
if cs:
deal_node(cs, result, num+1)
def get_row(topic):
id2children = {}
root = {}
for d in topic:
node = id2children.get(d.get("parentid"), root)
tmp = {}
node[d['id']] = (get_describe(d['describe']), tmp)
id2children[d['id']] = tmp
name, (describe, _) = list(root.items())[0]
txts = []
deal_node(root, txts)
other = "\n".join(txts)
return name, describe, other
mdx_file = "help.mdx"
mdx = MDX(mdx_file, encoding='utf-8')
items = mdx.items()
data = []
for key, value in items:
word = key.decode().strip()
topic = json.loads(re.findall('"data":(\[.+\])}\);', value.decode())[0])
name, describe, other = get_row(topic)
data.append((name, describe, other))
with open(mdx_file.replace('.mdx', '-UTF8 .csv'), 'w', newline='', encoding='u8') as f:
cw = csv.writer(f, delimiter=',')
cw.writerow(["单词", "释义", "扩展"])
cw.writerows(data)