web前端工程师面试题手册(2022最新版基础、核心、进阶)
目录
1.前端基础
1.1 | HTTP/HTML/浏览器
• 说一下 http 和 https
• tcp 三次握手,一句话概括
• TCP 和 UDP 的区别
• WebSocket 的实现和应用
• HTTP 请求的方式,HEAD 方式
• 一个图片 url 访问后直接下载怎样实现?
• 说一下 web Quality(无障碍)
• 几个很实用的 BOM 属性对象方法?
• 说一下 HTML5 drag api
• 说一下 http2.0
• HTTP2.0 的特性
• 补充 400 和 401、403 状态码
• fetch 发送 2 次请求的原因
Cookie、sessionStorage、localStorage 的区别
• 介绍知道的 http 返回的状态码
• 说说 302,301,304 的状态码
• http 常用请求头
• 强,协商缓存
• 讲讲 304
• 强缓存、协商缓存什么时候用哪个
• 怎么看网站的性能如何
• 前端/web性能优化
• GET 和 POST 的区别
• 301 和 302 的区别
• HTTP 支持的方法
• http 常见的请求方法
• 如何画一个三角形
• 状态码 304 和 200
• 说一下浏览器缓存
• HTML5 和 CSS3 用的多吗?你了解它们的新属性吗?有在项目中用过吗?
• 在地址栏里输入一个 URL,到这个页面呈现出来,中间会发生什么?
• 浏览器输入 URL /网址到页面加载显示完成/渲染发生了什么?
• 常见的 HTTP 的头部
• cache-control 的值有哪些
• 浏览器在生成页面的时候,会生成那两颗树?
• csrf 和 xss 的网络攻击及防范
• 介绍 HTTP 协议(特征)
• 说一下对 Cookie 和 Session 的认知,Cookie 有哪些限制?
1.2 | CSS
• 说一下 css 盒模型
• 画一条 0.5px 的线
• link 标签和 import 标签的区别
• transition 和 animation 的区别
• Flex 布局
• BFC(块级格式化上下文,用于清楚浮动,防止 margin 重叠等)
• 垂直居中的方法
• 关于 JS 动画和 css3 动画的差异性
• 说一下块元素和行元素
• 多行元素的文本省略号
• 双边距重叠问题(外边距折叠)
• position 属性 比较
• 浮动清除
• css3 新特性
• CSS 选择器有哪些,优先级呢
• 清除浮动的方法,能讲讲吗
• 怎么样让一个元素消失,讲讲
• 介绍一下盒模型
• css 动画如何实现
• 如何实现图片在某个容器中居中的?
• 如何实现元素的垂直居中
• CSS3 中对溢出的处理
• float 的元素,display 是什么
• 隐藏页面中某个元素的方法
• 三栏布局的实现方式,尽可能多写,浮动布局时,三个 div 的生成顺序
有没有影响
• 什么是 BFC
• calc 属性
• 有一个 width300,height300,怎么实现在屏幕上垂直水平居中
• display:table 和本身的 table 有什么区别
• position 属性的值有哪些及其区别
• z-index 的定位方法
• 如果想要改变一个 DOM 元素的字体颜色,不在它本身上进行操作?
• 对 CSS 的新属性有了解过的吗?
• 用的最多的 css 属性是啥?
• line-height 和 height 的区别
• 设置一个元素的背景颜色,背景颜色会填充哪些区域?
• 知道属性选择器和伪类选择器的优先级吗
• inline-block、inline 和 block 的区别;为什么 img 是 inline 还可以设置宽高
• 用 css 实现一个硬币旋转的效果
• 了解重绘和重排吗,知道怎么去减少重绘和重排吗,让文档脱离文档流有哪些方法
• CSS 画正方体,三角形
• overflow 的原理
• 清除浮动的方法
• box-sizing 的语法和基本用处
• 两个嵌套的 div,position 都是 absolute,子 div 设置 top 属性,那么
这个 top 是相对于父元素的哪个位置定位的。
• 说说盒子模型
• 相对布局和绝对布局,position:relative 和 obsolute。
• flex 布局
• block、inline、inline-block 的区别。
• css 的常用选择器
• css 布局
• css 定位
• relative 定位规则
• 垂直居中
• css 预处理器有什么
1.3 | JavaScript
• get 请求传参长度的误区
• 补充 get 和 post 请求在缓存方面的区别
• 说一下闭包
• 说一下类的创建和继承
• 如何解决异步回调地狱
• 说说前端中的事件流
• 如何让事件先冒泡后捕获
• 说一下事件委托
• 说一下图片的懒加载和预加载
• mouseover 和 mouseenter 的区别
• JS 的 new 操作符做了哪些事情
• 改变函数内部 this 指针的指向函数(bind,apply,call 的区别)
• JS 的各种位置,比如 clientHeight,scrollHeight,offsetHeight ,以
及 scrollTop, offsetTop,clientTop 的区别?
• JS 拖拽功能的实现
• 异步加载 JS 的方法
• Ajax 解决浏览器缓存问题
• JS 的节流和防抖
• JS 中的垃圾回收机制
• eval 是做什么的
• 如何理解前端模块化
• 说一下 CommonJS、AMD 和 CMD
• 对象深度克隆的简单实现
• 实现一个 once 函数,传入函数参数只执行一次
• 将原生的 ajax 封装成 promise
• JS 监听对象属性的改变
• 如何实现一个私有变量,用 getName 方法可以访问,不能直接访问
• ==和===、以及 Object.is 的区别
• setTimeout、setInterval 和 requestAnimationFrame 之间的区别
• 实现一个两列等高布局,讲讲思路
• 自己实现一个 bind 函数
• 用 setTimeout 来实现 setInterval
• JS 怎么控制一次加载一张图片,加载完后再加载下一张
• 代码的执行顺序
• 如何实现 sleep 的效果(es5 或者 es6)
• 简单的实现一个 promise
• 实现 JS 中所有对象的深度克隆(包装对象,Date 对象,正则对象)
• 简单实现 Node 的 Events 模块
• 箭头函数中 this 指向举例
• JS 判断类型
• 数组常用方法
• 数组去重
• 闭包 有什么用
• 事件代理在捕获阶段的实际应用
• 去除字符串首尾空格
• 性能优化
• 来讲讲 JS 的闭包吧
• 能来讲讲 JS 的语言特性吗
• 如何判断一个数组(讲到 typeof 差点掉坑里)
• 你说到 typeof,能不能加一个限制条件达到判断条件
• JS 实现跨域
• JS 基本数据类型
• JS 深度拷贝一个元素的具体实现
• 重排和重绘,讲讲看
• JS 的全排列
• 跨域的原理
• 不同数据类型的值的比较,是怎么转换的,有什么规则
• null == undefined 为什么
• this 的指向 哪几种
• 暂停死区
• AngularJS 双向绑定原理
• 写一个深度拷贝
• 有一个游戏叫做 Flappy Bird,就是一只小鸟在飞,前面是无尽的沙
漠,上下不断有钢管生成,你要躲避钢管。然后小明在玩这个游戏时候
老是卡顿甚至崩溃,说出原因(3-5 个)以及解决办法(3-5 个)
• 编写代码,满足以下条件: (
1)Hero("37er");执行结果为 Hi! This
is 37er (
2)Hero("37er").kill(1).recover(30);执行结果为 Hi!
This is 37er Kill 1 bug Recover 30 bloods (
3)
Hero("37er").sleep(10).kill(2)执行结果为 Hi! This is 37er //等
待 10s 后 Kill 2 bugs //注意为 bugs (双斜线后的为提示信息,不
需要打印)
• 什么是按需加载
• 说一下什么是 virtual dom
• webpack 用来干什么的
• ant-design 优点和缺点
• JS 中继承实现的几种方式,
• 写一个函数,第一秒打印 1,第二秒打印 2
• Vue 的生命周期
• 简单介绍一下 symbol
• 什么是事件监听
• 介绍一下 promise,及其底层如何实现
• 说说 C++,Java,JavaScript 这三种语言的区别
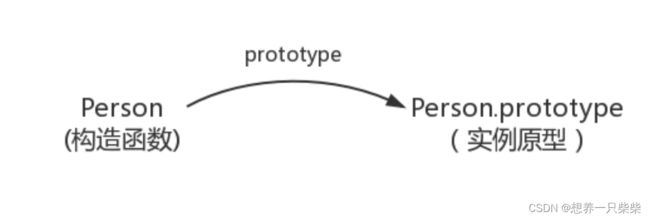
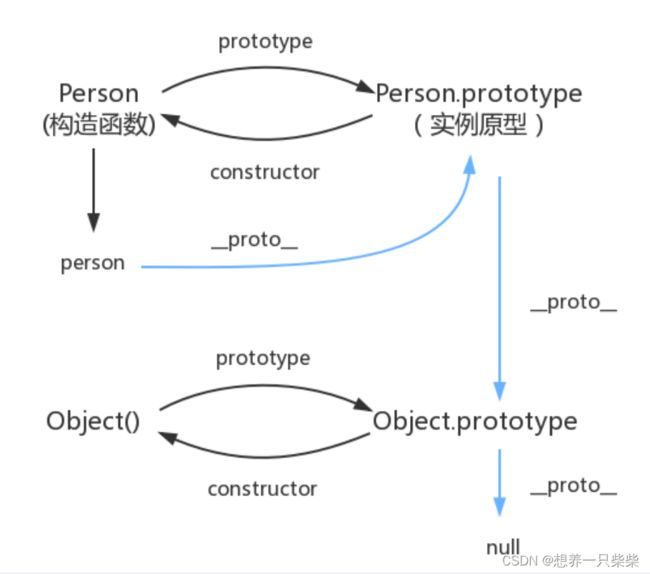
• JS 原型链,原型链的顶端是什么?Object 的原型是什么?Object 的原
型的原型是什么?在数组原型链上实现删除数组重复数据的方法
• 什么是 js 的闭包?有什么作用,用闭包写个单例模式
• promise+Generator+Async 的使用 参考回答:
• 事件委托以及冒泡原理。
• 写个函数,可以转化下划线命名到驼峰命名
• 深浅拷贝的区别和实现
• JS 中 string 的 startwith 和 indexof 两种方法的区别
• JS 字符串转数字的方法
• let const var 的区别 ,什么是块级作用域,如何用 ES5 的方法实现
块级作用域(立即执行函数),ES6 呢
• ES6 箭头函数的特性
• setTimeout 和 Promise 的执行顺序
• 有了解过事件模型吗,DOM0 级和 DOM2 级有什么区别,DOM 的分级是什
么
• 平时是怎么调试 JS 的
• JS 的基本数据类型有哪些,基本数据类型和引用数据类型的区别,NaN
是什么的缩写,JS 的作用域类型,undefined==null 返回的结果是什
么,undefined 与 null 的区别在哪,写一个函数判断变量类型
• setTimeout(fn,100);100 毫秒是如何权衡的
• JS 的垃圾回收机制
• 写一个 newBind 函数,完成 bind 的功能。
• 怎么获得对象上的属性:比如说通过 Object.key()
• 简单讲一讲 ES6 的一些新特性
• call 和 apply 是用来做什么?
• 了解事件代理吗,这样做有什么好处
• 如何写一个继承?
• 给出以下代码,输出的结果是什么?原因? for(var i=0;i<5;i++)
{ setTimeout(function(){ console.log(i); },1000); }
console.log(i)
• 给两个构造函数 A 和 B,如何实现 A 继承 B?
• 如果已经有三个 promise,A、B 和 C,想串行执行,该怎么写?
• 知道 private 和 public 吗
• 基础的 js
• async 和 await 具体该怎么用?
• 知道哪些 ES6,ES7 的语法
• promise 和 await/async 的关系
• JS 的数据类型
• JS 加载过程阻塞,解决方法。
• JS 对象类型,基本对象类型以及引用对象类型的区别
• JavaScript 中的轮播实现原理?假如一个页面上有两个轮播,你会怎么
实现?
• 怎么实现一个计算一年中有多少周?
• 面向对象的继承方式
• JS 的数据类型
• 引用类型常见的对象
• es6 的常用
• class
• 口述数组去重
• 继承
• es6 的常用特性
• 箭头函数和 function 有什么区别
• new 操作符原理
• bind,apply,call
• bind 和 apply 的区别
• 数组的去重
• 闭包
• promise 实现
• assign 的深拷贝
• 说 promise,没有 promise 怎么办
• 事件委托
• 箭头函数和 function 的区别
• arguments 参考回答:
• 箭头函数获取 arguments
• Promise
• 事件代理
• Eventloop
2 | 前端核心
2.1| 服务端编程
• JSONP 的缺点
• 跨域(jsonp,ajax)
• 如何实现跨域
• dom 是什么,你的理解?
• 关于 dom 的 api 有什么
2.2 | Ajax
• ajax 返回的状态
• 实现一个 Ajax
• 如何实现 ajax 请求,假如我有多个请求,我需要让这些 ajax 请求按照
某种顺序一次执行,有什么办法呢?如何处理 ajax 跨域
• 写出原生 Ajax
• 如何实现一个 ajax 请求?如果我想发出两个有顺序的 ajax 需要怎么
做?
• Fetch 和 Ajax 比有什么优缺点?
• 原生 JS 的 ajax
2.3 | 移动 web 开发
• 知道 PWA 吗
• 移动布局方案
• Rem, Em
• Rem 布局及其优缺点
• 百分比布局
• 移动端适配 1px 的问题
• 移动端性能优化相关经验
• toB 和 toC 项目的区别
• 移动端兼容性
• 小程序
• 防止手机中页面放大和缩小
• px、em、rem、%、vw、vh、vm 这些单位的区别
• 移动端适配- dpr 浅析
• 移动端扩展点击区域
• 上下拉动滚动条时卡顿、慢
• 长时间按住页面出现闪退
• ios 和 android 下触摸元素时出现半透明灰色遮罩
• active 兼容处理 即 伪类:active 失效
• webkit mask 兼容处理
• transiton 闪屏
• 圆角 bug
3.前端进阶
3.1 | 前端工程化
• Babel 的原理是什么?
• 如何写一个 babel 插件?
• 你的 git 工作流是怎样的?
• rebase 与 merge 的区别?
• git reset、git revert 和 git checkout 有什么区别
• webpack 和 gulp 区别(模块化与流的区别)
3.2 | React 框架
• angularJs 和 React 区别
• redux 中间件
• redux 有什么缺点
• React 组件的划分业务组件技术组件?
• React 生命周期函数
• React 性能优化是哪个周期函数?
• 为什么虚拟 dom 会提高性能?
• diff 算法?
• React 性能优化方案
• 简述 flux 思想
• React 项目用过什么脚手架?Mern? Yeoman?
• 你了解 React 吗?
• React 解决了什么问题?
• React 的协议?
• 了解 shouldComponentUpdate 吗?
• React 的工作原理?
• 使用 React 有何优点?
• 展示组件(Presentational component)和容器组件(Container
component)之间有何不同?
• 类组件(Class component)和函数式组件(Functional component)之间
• (组件的)状态(state)和属性(props)之间有何不同?
• 应该在 React 组件的何处发起 Ajax 请求?
• 在 React 中,refs 的作用是什么?
• 何为高阶组件(higher order component)?
• 使用箭头函数(arrow functions)的优点是什么?
• 为什么建议传递给 setState 的参数是一个 callback 而不是一个对象?
• 除了在构造函数中绑定 this,还有其它方式吗?
• 怎么阻止组件的渲染?
• 当渲染一个列表时,何为 key?设置 key 的目的是什么?
• (在构造函数中)调用 super(props) 的目的是什么?
• 何为 JSX ?
1.前端基础
1.1 | HTTP/HTML/浏览器
• 说一下 http 和 https
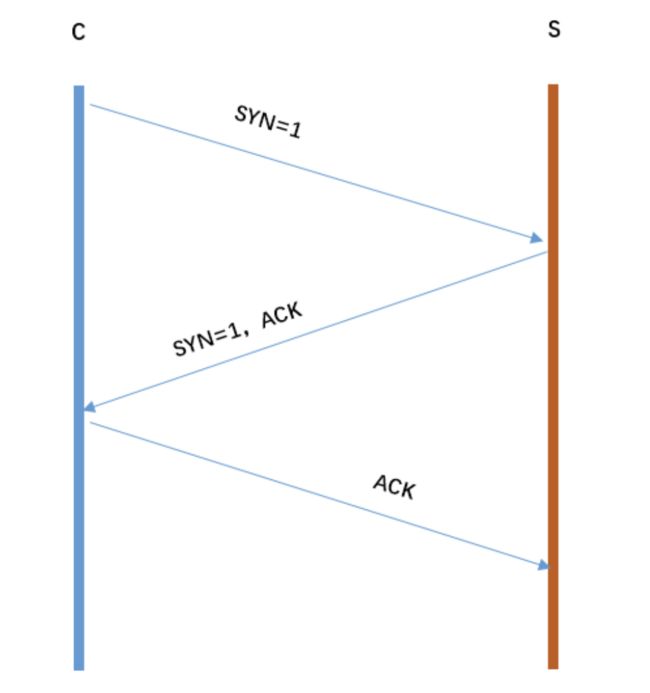
• tcp 三次握手,一句话概括
客户端和服务端都需要直到各自可收发,因此需要三次握手。
• TCP 和 UDP 的区别
• WebSocket 的实现和应用
• HTTP 请求的方式,HEAD 方式
• 一个图片 url 访问后直接下载怎样实现?
• 说一下 web Quality(无障碍)

• 几个很实用的 BOM 属性对象方法?
• 说一下 HTML5 drag api
• 说一下 http2.0
• HTTP2.0 的特性
• 补充 400 和 401、403 状态码
• fetch 发送 2 次请求的原因
Cookie、sessionStorage、localStorage 的区别
• cookie session 区别
• 介绍知道的 http 返回的状态码
• 说说 302,301,304 的状态码
• http 常用请求头
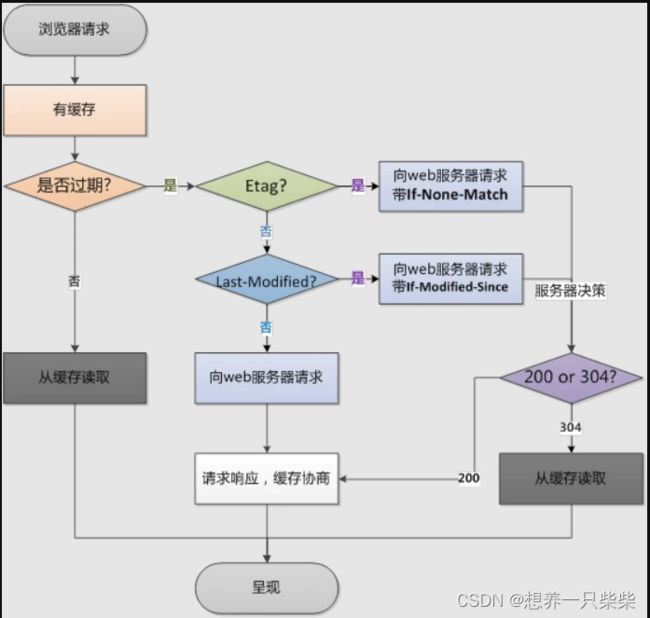
• 强,协商缓存


强缓存相关字段有 expires,cache-control。如果 cache-control 与 expires 同时存 在的话,cache-control 的优先级高于 expires。 协商缓存相关字段有 Last-Modified/If-Modified-Since,Etag/If-None-Match
• 讲讲 304
• 强缓存、协商缓存什么时候用哪个
• 怎么看网站的性能如何
• 前端/web性能优化
• GET 和 POST 的区别
或者
• 301 和 302 的区别
• HTTP 支持的方法
• http 常见的请求方法
• 如何画一个三角形
• 状态码 304 和 200
• 说一下浏览器缓存
• HTML5 和 CSS3 用的多吗?你了解它们的新属性吗?有在项目中用过吗?
• 在地址栏里输入一个 URL,到这个页面呈现出来,中间会发生什么?
• 浏览器输入 URL /网址到页面加载显示完成/渲染发生了什么?
• cookie 和 session 的区别,localstorage 和 sessionstorage 的区别
• 常见的 HTTP 的头部
• cache-control 的值有哪些
• 浏览器在生成页面的时候,会生成那两颗树?
• csrf 和 xss 的网络攻击及防范
• 介绍 HTTP 协议(特征)
• 说一下对 Cookie 和 Session 的认知,Cookie 有哪些限制?
• cookie 有哪些字段可以设置
• cookie 有哪些编码方式?
encodeURI()
• 除了 cookie,还有什么存储方式。说说 cookie 和 localStorage 的区别
1.2 | CSS
• 说一下 css 盒模型

IE盒子模型:

• 画一条 0.5px 的线
• link 标签和 import 标签的区别
• transition 和 animation 的区别
• Flex 布局
• BFC(块级格式化上下文,用于清楚浮动,防止 margin 重叠等)
• 垂直居中的方法

• 关于 JS 动画和 css3 动画的差异性
• 说一下块元素和行元素
• 多行元素的文本省略号
• visibility=hidden, opacity=0,display:none
• 双边距重叠问题(外边距折叠)
• position 属性 比较
• 浮动清除
或
• css3 新特性
• CSS 选择器有哪些,优先级呢
• 清除浮动的方法,能讲讲吗
或
• 怎么样让一个元素消失,讲讲
• 介绍一下盒模型
• css 动画如何实现
• 如何实现图片在某个容器中居中的?
• 如何实现元素的垂直居中
• CSS3 中对溢出的处理
• float 的元素,display 是什么
• 隐藏页面中某个元素的方法
• 三栏布局的实现方式,尽可能多写,浮动布局时,三个 div 的生成顺序
有没有影响
• 什么是 BFC
• calc 属性
• 有一个 width300,height300,怎么实现在屏幕上垂直水平居中
• display:table 和本身的 table 有什么区别
• position 属性的值有哪些及其区别
• z-index 的定位方法
• 如果想要改变一个 DOM 元素的字体颜色,不在它本身上进行操作?
• 对 CSS 的新属性有了解过的吗?
• 用的最多的 css 属性是啥?
• line-height 和 height 的区别
• 设置一个元素的背景颜色,背景颜色会填充哪些区域?
• 知道属性选择器和伪类选择器的优先级吗
• inline-block、inline 和 block 的区别;为什么 img 是 inline 还可以设置宽高
• 用 css 实现一个硬币旋转的效果
• 了解重绘和重排吗,知道怎么去减少重绘和重排吗,让文档脱离文档流有哪些方法
• CSS 画正方体,三角形
• overflow 的原理
• 清除浮动的方法
• box-sizing 的语法和基本用处
• 两个嵌套的 div,position 都是 absolute,子 div 设置 top 属性,那么
这个 top 是相对于父元素的哪个位置定位的。
• 说说盒子模型
• 相对布局和绝对布局,position:relative 和 obsolute。
• flex 布局
• block、inline、inline-block 的区别。
• css 的常用选择器
• css 布局
• css 定位
• relative 定位规则
• 垂直居中
• css 预处理器有什么
1.3 | JavaScript
• get 请求传参长度的误区
• 补充 get 和 post 请求在缓存方面的区别
• 说一下闭包
• 说一下类的创建和继承
• 如何解决异步回调地狱
• 说说前端中的事件流
• 如何让事件先冒泡后捕获
• 说一下事件委托
• 说一下图片的懒加载和预加载
• mouseover 和 mouseenter 的区别
• JS 的 new 操作符做了哪些事情
• 改变函数内部 this 指针的指向函数(bind,apply,call 的区别)
• JS 的各种位置,比如 clientHeight,scrollHeight,offsetHeight ,以
及 scrollTop, offsetTop,clientTop 的区别?
• JS 拖拽功能的实现
• 异步加载 JS 的方法
• 代码的执行顺序
• 如何实现 sleep 的效果(es5 或者 es6)
• 简单的实现一个 promise
• 实现 JS 中所有对象的深度克隆(包装对象,Date 对象,正则对象)
• 简单实现 Node 的 Events 模块
• 箭头函数中 this 指向举例
• JS 判断类型
• 数组常用方法
• 数组去重
• 闭包 有什么用
• 事件代理在捕获阶段的实际应用
• 去除字符串首尾空格
• 性能优化
• 来讲讲 JS 的闭包吧
• 能来讲讲 JS 的语言特性吗
• 如何判断一个数组(讲到 typeof 差点掉坑里)
• 你说到 typeof,能不能加一个限制条件达到判断条件
• JS 实现跨域
• JS 基本数据类型
• JS 深度拷贝一个元素的具体实现
• 重排和重绘,讲讲看
• JS 的全排列
• 跨域的原理
• 不同数据类型的值的比较,是怎么转换的,有什么规则

• null == undefined 为什么
• this 的指向 哪几种
• 暂停死区
• AngularJS 双向绑定原理
• 写一个深度拷贝
• 有一个游戏叫做 Flappy Bird,就是一只小鸟在飞,前面是无尽的沙
漠,上下不断有钢管生成,你要躲避钢管。然后小明在玩这个游戏时候
老是卡顿甚至崩溃,说出原因(3-5 个)以及解决办法(3-5 个)
• 编写代码,满足以下条件: (
1)Hero("37er");执行结果为 Hi! This
is 37er (
2)Hero("37er").kill(1).recover(30);执行结果为 Hi!
This is 37er Kill 1 bug Recover 30 bloods (
3)
Hero("37er").sleep(10).kill(2)执行结果为 Hi! This is 37er //等
待 10s 后 Kill 2 bugs //注意为 bugs (双斜线后的为提示信息,不
需要打印)
• 什么是按需加载
• 说一下什么是 virtual dom
• webpack 用来干什么的
• ant-design 优点和缺点
• JS 中继承实现的几种方式,
• 写一个函数,第一秒打印 1,第二秒打印 2
• Vue 的生命周期
• 简单介绍一下 symbol
• 什么是事件监听
• 介绍一下 promise,及其底层如何实现
• 说说 C++,Java,JavaScript 这三种语言的区别
• JS 原型链,原型链的顶端是什么?Object 的原型是什么?Object 的原
型的原型是什么?在数组原型链上实现删除数组重复数据的方法