PAT (Basic Level) Practice 1045~1066
PTA Basic Level Practice 解题思路和代码,主要用的是 C++。每22题一篇博客,可以按目录来进行寻找。
文章目录
- 1045 快速排序
- 1046 划拳
- 1047 编程团体赛
- 1048 数字加密
- 1049 数列的片段和
- 1050 螺旋矩阵
- 1051 复数乘法
- 1052 卖个萌
- 1053 住房空置率
- 1054 求平均值
- 1055 集体照
- 1056 组合数的和
- 1057 数零壹
- 1058 选择题
- 1059 C语言竞赛
- 1060 爱丁顿数
- 1061 判断题
- 1062 最简分数
1045 快速排序
思路:
对于每一个元素,如果其比左侧的最大值要大,比右侧的最小值要小,那么它就符合主元的定义,所以具体的做法就是:
先遍历一遍数组,找出每个元素左侧的最大值;再遍历一遍数组,找出每个元素右侧的最小值,最后遍历一遍数组,找出符合主元要求的所有数,最后打印输出。时间复杂度为 O ( n ) O(n) O(n)。
- 用 leftMax 数组来保存 A 中对应元素左侧的最大值。假设当前下标是 i,比较其前一个元素 A[i - 1] 和前一个元素左侧的最大值 leftMax[i - 1],谁更大,谁就是 A[i] 左侧的最大值;寻找右侧最小值同理。
- 然后就是升序输出的问题,因为符合要求的主元都是比左侧的元素要大,因此放入到 ans 数组中的元素也一定是升序排列的。
- 最后要注意一下输出的格式,第三个测试点中结果没有主元,所以输出第一行中主元的个数为0,第二行是一个空行,所以最后要加一句 cout << endl;
#include 另一种做法:在快速排序中,每一趟排序后,主元一定到达了最终的位置。因此先对初始数组进行拷贝,然后对它进行排序。排序后对两个数组进行逐个元素的比较,元素位置不发生变化且比左侧的最大值都要大的元素一定可以做主元。
另外提一点,在对数据进行频繁的访问操作时,数组的效率要比 vector 高很多。但这不能说明数组一定比 vector 好,vector 拥有很多强大的功能,也可以存储很多种类型,相比之下数组还是太单一了点。如果只是对一组数据进行简单的频繁访问,可以选择数组,否则用 vector 更加方便。
#include 1046 划拳
#include 1047 编程团体赛
#include 1048 数字加密
思路:
将整数 A 和 B 分别倒置,此时就将整数的个位放到了字符串的第一位。然后获取两者的长度,对于较短的,在字符串的末尾补上 ‘0’,相当于在整数的高位补了0。然后从字符串的最后一位(整数的最高位)开始遍历,一直到字符串的第一位(整数的个位),逐个加密逐个输出即可得到加密后的结果,这样就就省去了再定义一个 string 对象保存加密结果了。
注意:
- 位数不够需要补0参与加密,而不是将多余的字符直接输出。
- 奇数位,偶数位指的是数位的奇偶性,而不是位上的数字的奇偶性。
- i 从 max(lena, lenb) 开始不断减小,而不是 lena 或 lenb,否则会漏解的。
- 用的是下标遍历,下标是偶数时,对应的是奇数位,规则是反过来的。
经验:
- 用 string C; 来代替 char C[13]; 数组更加简便。
- 三元运算符的效率比 if-else 更高。
- 判断下标奇偶性可以用与运算,效率更高。x & 1,结果为1是奇数,结果为0是偶数,和奇偶判断是一样的。注意不能写成 i & 1 ==
0,因为 ‘==’ 的运算优先级比 ‘&’ 更高,写成这样会先运算 1 == 0 倒置全是 false 了。取而代之可以写成 (i & 1) == 0 或者 !(i & 1)。 - reverse() 函数用于将数组或字符串倒置,在头文件 algorithm 中。
- append() 函数是在字符串的末尾添加指定个数的字符,头文件 iostream 就已经包含了
#include 1049 数列的片段和
#include 1050 螺旋矩阵
思路:
寻找 m - n 最小差值的过程类似于判断是否为素数,其实也就是寻找 N 的最接近因子对的过程,从 n = 1 枚举到 n * n > N,如果 N 能被 n 整除,就令 m = N / n。在退出循环后得到的就是满足 m - n 差值最小的 m,也是大于等于 N \sqrt N N 中最小的一个因子。然后再令 n = N / m 即可得到满足 m - n 差值最小的 n。用 sort() 函数对输入的数组 A 进行排序,用 memset() 函数将二维螺旋数组 B 的所有元素初始化为0。
然后在 while 循环中将 A 数组的元素依次填充到数组 B 中,因为 sort() 函数是从小到大的排序,所以我用 k 来标记数组的尾部下标,填充一个 k 的值就减1,当 k 的值小于0时表明填充完了,从而退出 while 循环。填充过程的基本思路是,用 d 的值来标记填充的方向,继续当前方向填充的标志是 B[i][j] = 0 且 i 或 j 并未到达数组边界。因为题目表明了输入的都是正整数,所以可以用元素值为0表明还没有被填充过

注意:
- i 和 j 要初始化为 -1,因为第一次进入 for 循环时 i 和 j 分别加了1。
- 退出一个 for 循环后,i 和 j 的值会与一开始填充的路线偏离,所以在下一个 for 循环时加1或减1来让路线回正。
经验:
- 对于任意一个正整数 N,其因子对中,一定有一个 ≤ N \le \sqrt N ≤N,而另一个 ≥ N \ge \sqrt N ≥N,因此 N 只需要从 1 枚举到 N \sqrt N N。
- 二维数组的初始化用 memset() 函数就很方便。
- 对于这种模拟类的题目,详细的写出其过程更有助于理清解题思路。
#include 1051 复数乘法
#include 1052 卖个萌
题目有一个隐含条件没有说明:左手和左眼之间要加左括号,右眼和右手之间要加右括号。这一题我不知道为什么控制端就是不能输出特殊字符,所以索性就不做了,贴上柳神代码的链接:1052. 卖个萌 (20)-PAT乙级真题。
1053 住房空置率
#include 1054 求平均值
思路:
读者可以阅读一下PAT OJ 刷题必备知识总结 12 sscanf 与 sprintf 中的内容。sscanf 会将 a 中符合 %lf 格式的内容写入 temp,sprintf 会将 temp 中的内容以 %.2lf 的格式写入 b。执行完这两步后,比较 a 中的每一位与 b 中的对应位是否相等,只有符合题目要求的数才会相等。如果不相等,令 flag 等于1。然后进行判断,只有同时满足 falg 为0,temp 的值在 [-1000, 1000] 之内才是题目所求的合法数。然后更新和与计数,最后按照题目规定的格式输出即可。输出的时候要注意,只有一个合法数时,应当输出 “number” 而不是 “numbers”。
#include 1055 集体照
思路:
这一题首先要结合测试用例仔细理解一下题目的意思,按照排队规则还原一下队伍的情况如下所示,可以知道它的排列是整体先从高到低,然后身高相等时再按照字典序排序。因此在得到输入后应首先按要求对整个队伍进行一次排列。要使名字和身高同时更换顺序,最好就是用结构体。定义一个结构体数组 person 来保存所有的排队人员。

解决了排序问题,就需要将所有人依次按照规则放入每一行中。由于说了后排的人输出在上方,所以很自然地我们就能从数组的头部一个个往每一行排入。用 n 来标记目前该排哪个人,用 r 来表明排到了哪一行,两者初始值都为0。用 m 来表示每一行需要排多少人,最上方一行需要 N % K + N / K(想一想为什么?)个人,下方的每一行都是 N / K 个人。因为当 r = 0 时 m = N % K + N / K。假设现在在第一行,需要排四个人,也就是 Joe,Tom,Nick 和 Bob。按照题目要求,就是先把最高的 Joe 排好,后面就一个放 Joe 的右边,一个放 Joe 的左边,以此往复,而在我们的视角内,就是先排好 Joe,然后 Tom 放左边,Nick 放右边,Bob 又放到左边。如果用一个数组 line 来表示当前行,那么就应该是如下的形式:
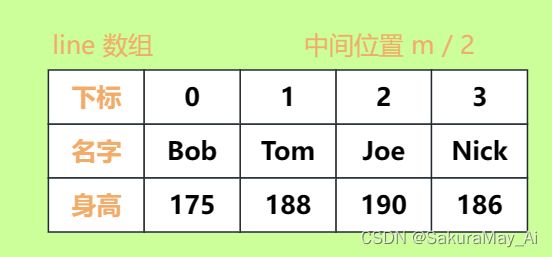
所以我的思路就是,在排每一行的人时,将 person 数组中下标 n ~ n + m 的人依次拿出来放入 line 数组,先放左边的,再放中间最高的,最后放右边的。中间的位置是 m / 2(比如一行4个人时,中间位置的下标就是 4 / 2 = 2;一行3个人时,中间位置的下标就是 3 / 2 = 1),用 j 来标记应该放在 line 数组中的哪个位置。
用 i 来标记 person 数组,而 person[n] 固定是放在中间位置的。排左边时,i 从 n +1 开始,因为是先放一个左边,再放一个右边,所以 i 每次循环是自增2;而 j 是从 m / 2 - 1 开始往 0 的方向走,然后将 person[i].name 给到 line[j]即可。右边 j 则是从 m / 2 + 1 开始往 m 的方向走,i 依然是每次循环自增2。排完一行后,进入下次循环前,要令 n += m,因为有 m 个人已经排完了。
注意:
我一开始用的是双端队列来表示每一行,然后用 push_front 和 push_back 来实现左插入和右插入,这样就不用考虑数组下标的问题。但是会超时,所以才改用直接通过下标访问数组的方式(毕竟插入元素需要移动比直接访问更耗时)。
经验:
- 两个条件的 cmp 函数用一个三目运算符就能实现,新技能 get。
- 不需要用二维数组来保存,排完一行就输出一行,空间利用更少,代码也更简洁。
#include 1056 组合数的和
思路:
输入 N 个数,每个数字既可能做个位数也有可能做十位数,分别会出现 N - 1 次。所以每个数 n 所产生和是 (n * 10 + n) * (N - 1) = n * 11 * (N - 1)。
#include 1057 数零壹
思路:
由于输入可能有空格,所以用 getline 来获取字符串。枚举字符串中的字符,若是字母,将其转换为小写字母后计算序号加到 sum 上。利用二进制除法来统计0和1的个数即可。
#include 1058 选择题
思路:
定义 score 数组保存每一题的满分,opts 为选项数,cor 为正确选项个数,ans 数组保存每一题的正确选项,也即正确答案。然后照常获取所有的输入,用一个 c = getchar() 来过滤掉输入流中的回车。
定义 stuScore 数组保存每个学生的得分,wrongCnt 数组保存每一题的错误次数,maxWrong 保存最大的错误次数。第一层 for 循环用 i 枚举每一个学生。因为每个学生的答题情况包含所有的选择题,且没有题号标记,只是用左右括号隔开然后顺序输入,所以用 cur 来记录题号,因此在每一层循环中都需要将题号 cur 置0。
因为学生的答题情况用一行字符串表示,而我思考后决定只对三种字符情况做判断,所以在这里用 c = getchar() 来处理比直接用 string 来接受一整行的输入更加方便。
- 当 c 为 ‘(’ 时表明到了下一题,cur 加1且清空学生的选择 temp;
- 当 c 为字母时,是学生的选择,将其加入 temp;
- 当 c 为 ‘)’ 时就需要判断对错了,将 temp 与 ans[cur] 作比较,正确的话则增加得分 stuScore[i] += score[cur];错误的话该题错误次数 wrongCnt[cur] 加1。然后检查是否需要更新 wrongCnt。
输入完后按题目要求输出即可。
注意:
仔细思考和试错过后发现选项个数 opts、正确选项个数 cor 在后面用不上,所以就没有用数组来保存。因为即便加上“如果学生的选择数不等于正确选项个数判错”,由于数据量和选项数比较少,并不会带来更多的时长优化,而为此还需要多加一层判断,得不偿失。
#include 1059 C语言竞赛
思路:
基本思路就是定义一个 map 字典: id_pz_ck,其中键是参赛者的 ID,值是一个 pair;pair 的 first 成员是奖品,second 成员是布尔值,表明其是否被查询过。
通过 insert 函数来将新的键值对插入到 map 中,构造键值对的方式是用花括号括起来。通过 find() 函数来查找键是否在字典中,返回的是指向该键的迭代器,如果没有这个键,返回的就是字典的尾后迭代器。
#include 1060 爱丁顿数
思路:
将数组从大到小排序,排好序就是如下图所示:

然后从下标 i = 1 开始枚举数组中的元素。从题目的要求可以这么理解,当 i = 6 时,a[i] = 7,因为数组是递减的,说明从 1 ~ 6 这六天的英里数都是大于6的,就满足了 E = 6 (满足有 6 天骑车超过 6 英里)。当 i = 7 时,a[i] = 6,说明从 1 ~ 7 这七天的英里数不全都大于 7,不满足 E = 7。再往后就肯定都不满足了,所以输出前一个满足条件的 i,即 i - 1。
注意:
- 是超过,因此要用大于号。
- 测试用例会出现如 3 3 3 3 5 这种,此时 E = 2;再如1 1 1 1 这种,此时 E = 0;再入 0 0 0 2 0,此时 E = 1;
#include 1061 判断题
#include