面试经典刷题)挑战一周刷完150道-Python版本-第2天(22个题)
一、轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。

这用于旋转一个整数列表 nums 中的元素。
k %= len(nums):这一行的目的是确保 k 的值在合理的范围内,因为如果 k 大于列表的长度 len(nums),旋转是循环的,所以我们取余数来确保 k 在合适的范围内,以避免不必要的重复旋转。比如,如果列表长度是 5,k 是 7,那么实际上只需要旋转 2 步,所以取余数后 k 的值为 2。
nums[:]:这是一个列表切片操作,它表示对整个列表 nums 进行操作。
nums[-k:]:这部分代码是将列表的末尾 k 个元素切片出来,这些元素将会成为旋转后的新列表的开头部分。负数索引表示从列表末尾开始计数。
nums[:-k]:这部分代码是将列表的除了末尾 k 个元素之外的部分切片出来,这些元素将会成为旋转后的新列表的末尾部分。
nums[:] = nums[-k:] + nums[:-k]:最后,将切片出来的两部分重新连接起来,然后用这个新列表来替换原来的列表 nums,实现了右旋转 k 步的操作。
总结一下,这段代码通过切片操作和取余数的方式,实现了将整数列表向右旋转 k 步的功能。这是一种非常有效的方法,因为它不需要额外的空间来存储旋转后的列表。
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
k %= len(nums)
nums[:] = nums[-k:] + nums[:-k]
二、罗马数字转整数
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。

使用Python中的字典数据结构。
这段代码是一个用于将罗马数字转换为整数的 Python 函数。它采用了一种巧妙的方法,通过定义一个字典 d 来存储罗马数字与整数之间的映射关系,然后遍历输入的罗马数字字符串 s,根据字典中的映射关系逐个字符进行转换并求和,最终返回整数结果。
下面是对这段代码中涉及的专业知识点的详细解释:
-
字典 (Dictionary):Python 中的字典是一种数据结构,用于存储键值对(key-value pairs)。在这段代码中,字典
d用来存储罗马数字和对应的整数值。例如,'I'对应整数1,'V'对应整数5,以此类推。 -
enumerate 函数:
enumerate是一个内置函数,用于同时获取列表或字符串的索引和值。在这段代码中,enumerate(s)用于遍历罗马数字字符串s,并返回每个字符的索引和字符本身。 -
sum 函数:
sum也是一个内置函数,用于计算可迭代对象(如列表)中所有元素的和。在这里,sum用来计算转换后的整数值的总和。 -
切片操作:
s[max(i-1, 0):i+1]这部分代码是在字符串s上进行切片操作。它用于提取当前字符以及前一个字符(如果存在)的子字符串。这是为了处理罗马数字中的特殊情况,如 IV 表示 4,IX 表示 9,XL 表示 40 等。切片的范围是从max(i-1, 0)开始到i+1结束,确保不会出现负数索引,并且始终包括当前字符。 -
字典的 get 方法:
d.get(s[max(i-1, 0):i+1], d[n])用于从字典d中获取与罗马数字子字符串对应的整数值。如果子字符串不存在于字典中,它将返回d[n],即默认的整数值,这是因为通常情况下单个罗马数字字符对应的整数值。
总结一下,这段代码展示了如何使用字典、遍历、切片和内置函数来实现一个高效的罗马数字转整数的函数。通过建立映射关系,遍历输入字符串并根据特殊情况进行处理,最终返回整数结果。这是一个典型的算法问题,要求熟悉字符串操作和字典的使用。
class Solution:
def romanToInt(self, s: str) -> int:
d = {'I':1, 'IV':3, 'V':5, 'IX':8, 'X':10, 'XL':30, 'L':50, 'XC':80, 'C':100, 'CD':300, 'D':500, 'CM':800, 'M':1000}
return sum(d.get(s[max(i-1, 0):i+1], d[n]) for i, n in enumerate(s))
让我们使用输入字符串 “MCMXCIV” 来演示上面提供的代码的每一步过程。这个输入字符串代表罗马数字 “1994”。
-
初始化字典
d,它包含了罗马数字字符和对应的整数值的映射: -
开始遍历输入字符串 “MCMXCIV”:
-
第一个字符 “M”,索引
i为0:- 切片操作
s[max(i-1, 0):i+1]返回 “M”。 - 字典
d中查找 “M” 对应的整数值,即d['M'],结果为1000。
- 切片操作
-
第二个字符 “C”,索引
i为1:- 切片操作
s[max(i-1, 0):i+1]返回 “MC”。 - 字典
d中查找 “MC” 对应的整数值,由于 “MC” 不在字典中,使用默认值d[n],即d['C'],结果为100。
- 切片操作
-
第三个字符 “M”,索引
i为2:- 切片操作
s[max(i-1, 0):i+1]返回 “CM”。 - 字典
d中查找 “CM” 对应的整数值,即d['CM'],结果为800。
- 切片操作
-
第四个字符 “X”,索引
i为3:- 切片操作
s[max(i-1, 0):i+1]返回 “XC”。 - 字典
d中查找 “XC” 对应的整数值,即d['XC'],结果为80。
- 切片操作
-
第五个字符 “C”,索引
i为4:- 切片操作
s[max(i-1, 0):i+1]返回 “C”。 - 字典
d中查找 “C” 对应的整数值,即d['C'],结果为100。
- 切片操作
-
第六个字符 “I”,索引
i为5:- 切片操作
s[max(i-1, 0):i+1]返回 “CI”。 - 字典
d中查找 “CI” 对应的整数值,由于 “CI” 不在字典中,使用默认值d[n],即d['I'],结果为1。
- 切片操作
-
第七个字符 “V”,索引
i为6:- 切片操作
s[max(i-1, 0):i+1]返回 “IV”。 - 字典
d中查找 “IV” 对应的整数值,即d['IV'],结果为3。
- 切片操作
-
-
计算整数结果,即对上述步骤得到的整数值求和:
return sum([1000, 100, 800, 80, 100, 1, 3])
- 最终结果为
1984,这是罗马数字 “MCMXCIV” 转换为整数的结果。
这个代码通过逐个字符遍历罗马数字字符串,根据字典中的映射关系进行转换,然后对转换后的整数值进行求和,得到了正确的整数结果。
三、整数转罗马数字
规则和上边一样,但是这次要求是整数转罗马数字

使用列表实现
class Solution:
def intToRoman(self, num: int) -> str:
val = [
1000, 900, 500, 400,
100, 90, 50, 40,
10, 9, 5, 4, 1
]
syb = [
"M", "CM", "D", "CD",
"C", "XC", "L", "XL",
"X", "IX", "V", "IV",
"I"
]
roman_num = ''
i = 0
while num > 0:
for _ in range(num // val[i]):
roman_num += syb[i]
num -= val[i]
i += 1
return roman_num
四、N字形变换
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。

主要就是控制好换向。
n = numRows:这一行将输入参数 numRows 的值赋给变量 n,以便稍后使用。numRows 表示 Z 字形中的总行数。
if n == 1::这是一个条件判断语句,检查行数是否为 1。如果行数为 1,说明无需进行 Z 字形变换,直接返回原始字符串 s。
res = [‘’] * n:创建一个长度为 n 的空字符串列表 res,用于存储 Z 字形变换后的字符串。
sign = -1:初始化一个变量 sign,用于表示方向的变化。在 Z 字形变换中,字符串从上往下走再从下往上走,交替变换方向,因此初始值为 -1。
i = 0:初始化一个变量 i,用于表示当前字符串要放在 res 列表的哪一行。
for ch in s::这是一个循环,遍历输入字符串 s 中的每个字符。
res[i] += ch:将当前字符 ch 添加到 res[i] 行的字符串中,表示将字符放置在当前行。
if i == 0 or i == n - 1::这是一个条件判断语句,用于检查是否需要改变方向。当 i 为 0(在 Z 字形的顶部行)或者 i 为 n - 1(在 Z 字形的底部行)时,需要改变方向。sign 被乘以 -1,从而改变方向。
i += sign:根据方向变量 sign 更新 i 的值,以便将下一个字符放在正确的行。
最后,通过 ‘’.join(res) 将 Z 字形变换后的字符串列表连接成一个字符串,然后返回这个字符串作为结果。
class Solution:
def convert(self, s: str, numRows: int) -> str:
n = numRows #行数
if n == 1:
return s
res = [''] * n
sign = -1
i =0
for ch in s:
res[i] += ch
if i == 0 or i ==n-1:#在第一行和最后一行转向
sign = -sign
i += sign
return ''.join(res)
五、验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。

使用双指针和字符串中的方法。
s[left].isalnum 是一个在编程中常见的表达式,用于检查字符串中特定位置的字符是否是字母或数字。
s是一个字符串。[left]表示在字符串s中的某个位置,其中left是一个索引或位置的变量或值。.isalnum()是一个字符串的方法,用于检查字符串是否由字母和/或数字组成。s[left].isalnum()表达式的结果是一个布尔值,如果s中的第left个字符是字母或数字,则结果为True,否则为False。
这个表达式通常用于字符串处理中的条件判断,以确定特定位置的字符是否满足某些要求,例如,用于验证密码是否包含字母和数字等。
class Solution:
def isPalindrome(self, s: str) -> bool:
left =0
right = len(s) - 1
while left < right:
while left <right and not s[left].isalnum():
left += 1
while left <right and not s[right].isalnum():
right -= 1
if left >= right:
break
if s[left].lower() != s[right].lower():
return False
left += 1
right -= 1
return True
六、判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?

最先想到的是双指针方法。
贪心思想(每一步都考虑当下情况下的最优解)
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
a = 0
b = 0
while a < len(s) and b <len(t):
if s[a] == t[b]:
a += 1
b += 1
return a == len(s)
动态规划思想
但是动态规划思想花的时间比较多。
-
首先,代码初始化了一些变量和数据结构:
n表示字符串s的长度。m表示字符串t的长度。f是一个二维列表,用于动态规划,其维度为(m + 1) x 26,其中 26 表示小写英文字母的个数,每一行代表字符串t中的一个字符,每一列代表小写英文字母。f[i][j]表示字符t[i]后面第一个字符j出现的位置。初始化时,所有元素都被设置为m,表示不可达的索引。
-
接下来,代码使用两层循环填充动态规划表
f,具体操作如下:- 从
m - 1开始往前遍历字符串t中的每个字符(从最后一个字符开始)。 - 对于每个字符,内部再次遍历小写英文字母
a到z。 - 如果当前字符
t[i]的 ASCII 值减去'a'的 ASCII 值等于当前遍历的小写英文字母的编号j,则说明当前字符是小写英文字母j,因此更新f[i][j]为当前位置i。 - 如果当前字符不等于小写英文字母
j,则将f[i][j]设置为f[i+1][j],即字符j出现在下一个字符的位置。
- 从
-
接下来,代码初始化了一个指针
i,用于指示在字符串t中的匹配起点,初始值为 0。 -
然后,代码进入一个循环,遍历字符串
s中的每个字符,其中k表示当前匹配字符在字符串s中的索引:- 将当前匹配字符
s[k]转换为对应的小写英文字母编号j。 - 如果
f[i][j]等于m,表示在字符串t的待匹配范围中不存在待匹配字符s[k],匹配失败,函数返回False。 - 否则,将匹配起点
i更新为f[i][j] + 1,表示下一次匹配将从字符串t中的下一个位置开始。
- 将当前匹配字符
-
最后,如果成功匹配了字符串
s中的所有字符,函数返回True,表示s是t的子序列。
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
n = len(s)
m = len(t)
f = [[m] * 26 for _ in range(m + 1)] # f的行数比m多了一行,是为了使原本的最后一行m-1的更新规则与其他行统一; 初始值都是不可达索引
for i in range(m - 1, -1, -1):
for j in range(26):
if ord(t[i] ) - ord('a') == j:
f[i][j] = i # i位字符本身,首次出现的位置就是i
else:
f[i][j] = f[i + 1][j] # 其他字符跟随后一位的信息
i = 0 # t的匹配起点,初始为0,从[0, m-1]进行匹配
for k in range(n):
j = ord(s[k]) - ord('a') # 获取当前匹配的字符编号
if f[i][j] == m:
return False # t的待匹配范围中不存在待匹配字符,匹配失败
i = f[i][j] + 1 # 否则更新匹配起点为匹配字符的下一位
return True
这个代码使用动态规划的思想来预处理字符串 t 中每个字符后面第一次出现的位置,然后通过指针 i 在 t 中按顺序查找匹配字符,从而判断 s 是否为 t 的子序列。这个算法具有较好的时间复杂度,可以高效地处理大型字符串。
七、三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。

排序加双指针。
本题目的难点是去除一些重复解。
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n =len(nums)
res=[]
if(not nums or n < 3):
return []
nums.sort()
res=[]
for i in range(n):
if(nums[i]>0):
return res
if(i > 0 and nums[i] == nums[i-1]):
continue
L = i+1
R = n-1
while(L < R):
if(nums[i]+nums[L]+nums[R] == 0):
res.append([nums[i],nums[L],nums[R]])
while(L<R and nums[L] == nums[L+1]):
L +=1
while(L<R and nums[R] == nums[R-1]):
R -=1
L =L+1
R = R-1
elif(nums[i]+nums[L]+nums[R]>0):
R =R-1
else:
L =L+1
return res
L += 1 和 L = L + 1 都是用于递增变量 L 的表达式,它们在功能上是等价的,都会将 L 的值增加 1。然而,它们之间存在一些细微的区别和联系:
-
功能相同:无论是
L += 1还是L = L + 1,它们都执行相同的操作,即将变量L的值增加 1。 -
可读性:
L += 1通常被认为更加简洁和清晰,因为它明确地表示对变量L进行递增操作。相比之下,L = L + 1包含了更多的字符,可能会稍显复杂。 -
原地操作:
L += 1是一个原地操作(in-place operation),它将递增操作应用于变量L,而不创建新的对象。这在某些情况下可能更加高效,尤其是在处理大型数据结构时。 -
不同的语言和用法:在不同的编程语言和上下文中,
L += 1和L = L + 1可能会有微妙的差异。一些编程语言可能会更加偏向于一种写法,或者对于特定类型的变量会有一些区别。
总之,L += 1 和 L = L + 1 在功能上是一样的,它们都用于递增变量的值。选择使用哪种写法通常取决于个人偏好、代码风格和语言惯例。在绝大多数情况下,推荐使用 L += 1,因为它更加简洁和清晰,而且是一个原地操作。
八、文本左右对齐
给定一个单词数组 words 和一个长度 maxWidth ,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。
你应该使用 “贪心算法” 来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格 ’ ’ 填充,使得每行恰好有 maxWidth 个字符。
要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
文本的最后一行应为左对齐,且单词之间不插入额外的空格。
注意:
单词是指由非空格字符组成的字符序列。
每个单词的长度大于 0,小于等于 maxWidth。
输入单词数组 words 至少包含一个单词。

一个方法是字符串模拟。
class Solution:
def fullJustify(self, words: List[str], maxWidth: int) -> List[str]:
res, line, str_num = [], [], 0
for word in words:
# line中所有单词加一起的长度 + line中单词(单词与单词之间原生需要1个空格)之间的间距数 + 当前需要判断的单词长度
# 上述之和大于等于maxWidth时会溢出,为什么等于时也会溢出?因为若新加入Word,会新增加1个间距(即空格长度)
if str_num + len(line)-1 + len(word) >= maxWidth:
for i in range(maxWidth - str_num):
line[i%max(len(line)-1, 1)] += ' ' #循环将每个空格依次加到每个单词之间的间距上
res.append(''.join(line))
line, str_num = [], 0
line.append(word)
str_num += len(word)
return res + [' '.join(line).ljust(maxWidth)]
-
res是用于存储最终格式化后的文本行的列表,line是当前正在处理的一行文本的单词列表,str_num记录了当前行中所有单词的字符总数。 -
代码通过迭代遍历输入的单词列表
words,逐个处理每个单词word。 -
在处理每个单词时,代码首先检查当前行是否可以容纳该单词。这个检查是通过比较
str_num + len(line)-1 + len(word)(即当前行的字符总数、单词之间的间距数和要添加的单词的长度)是否大于等于maxWidth来完成的。如果大于等于maxWidth,表示当前行已经无法容纳更多单词,需要进行文本对齐操作。 -
如果需要进行文本对齐,代码会进入一个循环,该循环的目的是将额外的空格添加到当前行的单词之间,以使得当前行的字符总数等于
maxWidth。这个循环通过遍历当前行中的字符,将额外的空格均匀地分配到单词之间的间距上,从而实现文本对齐。这里使用了取余运算符%来循环分配空格。 -
一旦完成了文本对齐,代码将当前行的文本添加到
res列表中,并清空line和str_num,以准备处理下一行。 -
在处理单词时,如果当前行还可以容纳更多单词,代码将当前单词
word添加到line列表中,并更新str_num。 -
最后,代码返回格式化后的文本行的列表
res,并对最后一行进行左对齐操作,以满足maxWidth。
专业知识点:
- 文本对齐:这段代码涉及了文本对齐的概念,文本对齐是指将文本按照一定的格式排列,使其在页面上看起来整齐、美观。在这个代码中,采用了左对齐(左边对齐)的方式,即在单词之间插入空格,使得每一行的字符数达到
maxWidth。 - 字符串处理:代码中使用了字符串的各种方法,如计算字符串长度、连接字符串、循环遍历字符串等。这是字符串处理的基本操作。
- 动态规划:虽然这不是严格的动态规划问题,但代码中使用了一个二维列表
f来记录字符位置,这种数据结构与动态规划中的表格类似,用于存储中间结果。
九、盛最多水容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。
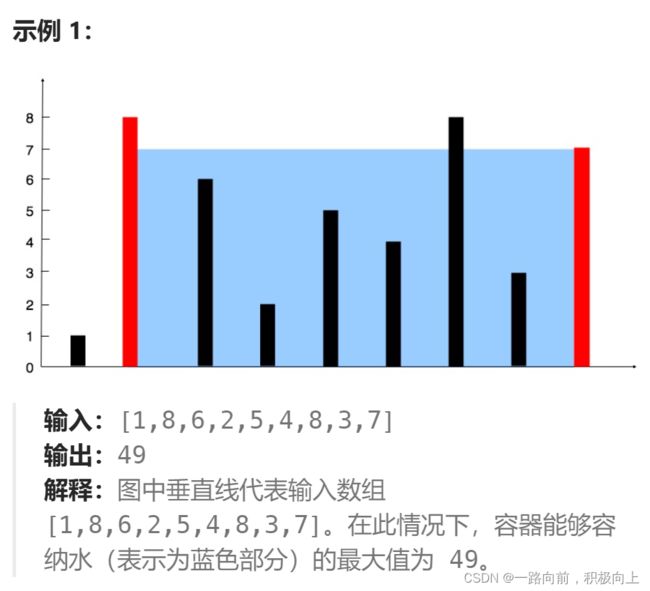
双指针方法
class Solution:
def maxArea(self, height: List[int]) -> int:
i, j, res = 0, len(height) - 1, 0
while i < j:
if height[i] < height[j]:
res = max(res, height[i] * (j - i))
i += 1
else:
res = max(res, height[j] * (j - i))
j -= 1
return res
十、两数之和II-输入有序数组
给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。
以长度为 2 的整数数组 [index1, index2] 的形式返回这两个整数的下标 index1 和 index2。
你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
你所设计的解决方案必须只使用常量级的额外空间。

双指针方法。有序数组使用复杂度更加低。
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
a , b = 0 ,len(numbers)-1
while a<b:
s = numbers[a] +numbers[b]
if s> target:
b -= 1
elif s <target:
a +=1
else:
return a+1 ,b+1
return []
也可以暴力模拟+哈希表优化。复杂度更高。
(直接暴力会超时。)
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
num_dict = {}
for i, num in enumerate(numbers):
complement = target - num
if complement in num_dict:
return [num_dict[complement] + 1, i + 1]
num_dict[num] = i
这段代码是用于在一个升序排列的整数列表 numbers 中找到两个数,使它们的和等于给定的目标值 target。以下是对这个代码的详细解读以及相关的专业知识点:
-
num_dict是一个字典数据结构,用于存储数字和它们在numbers列表中的索引的映射关系。字典的键是数字,值是数字在列表中的索引。 -
代码通过使用
enumerate函数遍历numbers列表,获取每个数字及其索引。enumerate函数会返回一个迭代器,每次迭代产生一个元组,包含数字在列表中的索引和数字本身。 -
在遍历过程中,对于每个数字
num,代码计算其补数complement,即target - num。这是因为要找到两个数的和等于目标值target,那么其中一个数就是target - num。 -
代码接着检查
complement是否已经存在于num_dict字典中。如果存在,说明找到了两个数,它们的和等于目标值target,于是返回这两个数在列表中的索引(索引从 1 开始,所以需要在返回时加 1)。 -
如果
complement不在num_dict中,代码将当前数字num以及它的索引i存储到num_dict中。这样,如果后续的数字可以与num相加等于target,就可以在num_dict中找到相应的索引。
专业知识点:
-
哈希表:这段代码使用了哈希表(字典
num_dict)来存储数字和它们的索引,以实现快速的查找操作。哈希表是一种常见的数据结构,用于存储键-值对,并通过哈希函数将键映射到特定的存储位置,以实现快速的查找、插入和删除操作。 -
双指针:虽然这个代码中没有明显的双指针操作,但它通过使用两个索引来查找两个数,其中一个索引是当前遍历的数字
num的索引,另一个索引是在num_dict中查找补数的索引。这种双索引的方法也常用于解决查找问题。 -
时间复杂度:由于
numbers是升序排列的,该算法的时间复杂度为 O(n),其中 n 是numbers列表中的数字数量。这是因为在遍历列表时,大多数操作都是常数时间的哈希表查找。这使得该算法非常高效。
十一、加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。

这里主要用到数组。也用到贪心。
数组(Array)是一种数据结构,用于存储相同类型的元素集合,这些元素按照线性顺序排列,并且可以通过索引来访问。数组通常具有固定的大小(静态数组)或动态扩展的能力(动态数组/列表),不同编程语言中的数组实现方式和特性可能会有所不同。
在Python中,数组的概念可以分成两类:列表(List)和NumPy数组。
- 列表(List):
- 列表是 Python 中内置的数据结构,用于存储一组有序的元素。
- 列表中的元素可以是不同类型的,甚至可以包含其他列表(嵌套列表)。
- 列表的大小可以动态调整,即你可以随时添加或删除元素。
- 列表的索引从0开始,通过索引可以访问和修改列表中的元素。
- 列表使用方括号
[]来表示,例如:my_list = [1, 2, 3]。
示例:
my_list = [1, 2, 3, 4, 5]
print(my_list[0]) # 输出: 1
- NumPy数组:
- NumPy是Python中用于科学计算的库,提供了高性能的多维数组(通常是同类型的数据)。
- NumPy数组的大小是固定的,创建后无法更改。
- NumPy数组支持丰富的数学和数组操作,例如矩阵运算、统计分析等。
- NumPy数组通常用于科学计算、数据分析和机器学习等领域。
- 创建NumPy数组需要导入NumPy库,通常使用
numpy.array()函数来创建数组。
示例:
import numpy as np
my_array = np.array([1, 2, 3, 4, 5])
print(my_array[0]) # 输出: 1
总结:
- 列表是Python内置的通用数据结构,可以包含不同类型的元素,具有动态大小。
- NumPy数组是专门用于数值计算的数据结构,通常包含相同类型的元素,具有高性能和丰富的数学操作。在科学计算和数据分析领域广泛应用。
- 在Python中,术语“数组”通常可以指代列表或NumPy数组,具体取决于上下文。
# 解法1
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
n = len(gas)
cur_sum = 0
min_sum = float('inf')
for i in range(n):
cur_sum += gas[i] - cost[i]
min_sum = min(min_sum, cur_sum)
if cur_sum < 0: return -1
if min_sum >= 0: return 0
for j in range(n - 1, 0, -1):
min_sum += gas[j] - cost[j]
if min_sum >= 0:
return j
return -1
# 解法2
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
start = 0
curSum = 0
totalSum = 0
for i in range(len(gas)):
curSum += gas[i] - cost[i]
totalSum += gas[i] - cost[i]
if curSum < 0:
curSum = 0
start = i + 1
if totalSum < 0: return -1
return start
这两种方法都是用来解决加油站(Gas Station)问题,目标是找到一个出发点,从这个出发点开始沿途加油和消耗油的操作,使得最终能够回到出发点。
以下是对这两种方法的中文解读:
解法1:
这个解法使用了两个变量 cur_sum 和 min_sum 来跟踪当前的加油和消耗情况。首先,它遍历了加油站的数量,计算了每一站的加油和消耗之差,然后将这个差值加到 cur_sum 中。同时,它还维护了一个 min_sum 变量,用于记录遍历过程中 cur_sum 的最小值。
然后,它进行了两次检查:
- 如果
cur_sum的总和小于0,说明无法完成整个循环,因此返回 -1,表示无法找到合适的出发点。 - 如果
min_sum大于等于0,说明整个循环中的所有站点都可以作为出发点,因为它们都能够满足沿途的加油需求。这时返回0,表示从第一个加油站出发即可。
最后,如果前面的检查都不符合条件,它再次遍历加油站,但这次是从最后一个站点开始向前遍历。在这个过程中,它继续更新 min_sum,如果遇到一个站点使得 min_sum 大于等于0,就返回该站点的索引,表示这是一个可能的出发点。如果遍历完整个数组都没有找到出发点,就返回 -1。
解法2:
这个解法使用了两个变量 start、curSum 和 totalSum。其中,start 用于记录可能的出发点,curSum 用于跟踪当前的加油和消耗情况,totalSum 用于记录整个循环的加油和消耗之差。
它的核心思想是遍历加油站,从第一个站点开始,计算 curSum 和 totalSum。如果 curSum 变为负数,说明当前的出发点不合适,因此将 start 更新为下一个站点,并将 curSum 重置为0。
最后,它进行了两次检查:
- 如果
totalSum总和小于0,说明无法完成整个循环,因此返回 -1,表示无法找到合适的出发点。 - 否则,返回
start,表示找到了可能的出发点。
这两种方法都是解决加油站问题的有效策略,它们在不同方面进行了优化。解法1在两次遍历中使用了 min_sum 变量来找到可能的出发点,而解法2则在单次遍历中实时更新 start 和 curSum,降低了计算的复杂性。两种方法的核心思想都是通过不断调整可能的出发点,找到一个合适的出发点,使得整个循环可以顺利完成。
十二、分发糖果
n 个孩子站成一排。给你一个整数数组 ratings 表示每个孩子的评分。
你需要按照以下要求,给这些孩子分发糖果:
每个孩子至少分配到 1 个糖果。
相邻两个孩子评分更高的孩子会获得更多的糖果。
请你给每个孩子分发糖果,计算并返回需要准备的 最少糖果数目 。

贪心,数组。
也可以是两次遍历。
class Solution:
def candy(self, ratings: List[int]) -> int:
n = len(ratings)
left = [0] * n
for i in range(n):
if i > 0 and ratings[i] > ratings[i - 1]:
left[i] = left[i - 1] + 1
else:
left[i] = 1
right = ret = 0
for i in range(n - 1, -1, -1):
if i < n - 1 and ratings[i] > ratings[i + 1]:
right += 1
else:
right = 1
ret += max(left[i], right)
return ret
十三、旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
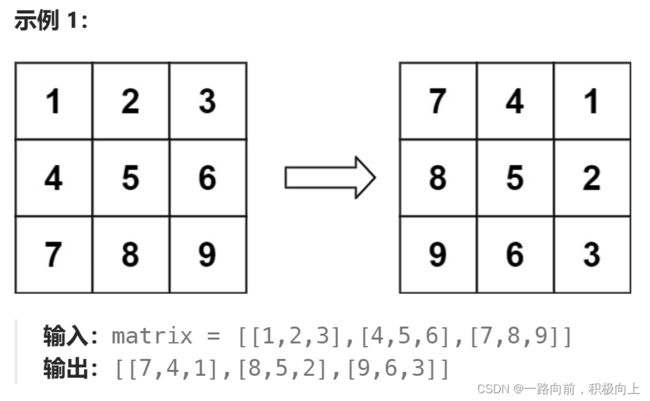
数组,模拟。
采用两步就可以简单实现。(已经做过测试实验)
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
n = len(matrix)
for i in range(n):
for j in range(i,n):
matrix[i][j],matrix[j][i] = matrix[j][i], matrix[i][j]
for i in range(n):
matrix[i]=matrix[i][::-1]
-
matrix[i]:这部分表示从列表(或二维列表中的一行)中选择第i行(或字符串中的第i个字符)。在Python中,列表和字符串都可以使用索引来获取其中的元素。 -
=matrix[i][::-1]:这部分是对选定的列表(或字符串)进行切片操作。切片操作是Python中常用的技巧,用于提取或变换列表或字符串的一部分。具体来说:matrix[i]表示选取了第i行(或字符串中的第i个字符)。[::-1]表示对选取的部分进行切片,使用-1作为步长(stride),这意味着从尾部向头部逆序遍历选取的部分。
这句代码的作用是将列表 matrix 中的第 i 行(或字符串中的第 i 个字符)逆序排列。例如,如果 matrix[i] 是一个列表 [1, 2, 3, 4],执行 matrix[i] = matrix[i][::-1] 后,matrix[i] 将变成 [4, 3, 2, 1]。
-
切片操作:在Python中,切片操作是一种非常强大的方式,用于从列表、字符串和其他序列类型中提取或变换数据。切片操作包括起始索引、终止索引和步长(stride)。在这个例子中,使用
[::-1]作为切片,步长为-1,实现了逆序排列的效果。 -
逆序排列:逆序排列是一种常见的数据操作,用于颠倒数据的顺序。在这个例子中,通过逆序排列,列表或字符串中的元素会从后往前排列。这对于处理需要倒序的情况非常有用。
十四、螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
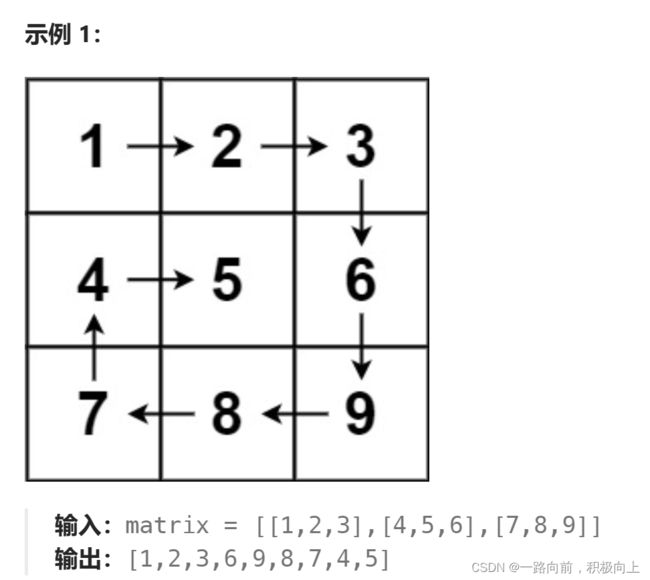
采用模拟的方法,加上数组的方法。
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
if not matrix: return []
l, r, t, b, res = 0, len(matrix[0]) - 1, 0, len(matrix) - 1, []
while True:
for i in range(l, r + 1): res.append(matrix[t][i]) # left to right
t += 1
if t > b: break
for i in range(t, b + 1): res.append(matrix[i][r]) # top to bottom
r -= 1
if l > r: break
for i in range(r, l - 1, -1): res.append(matrix[b][i]) # right to left
b -= 1
if t > b: break
for i in range(b, t - 1, -1): res.append(matrix[i][l]) # bottom to top
l += 1
if l > r: break
return res
这段代码实现了螺旋顺序(顺时针)遍历二维矩阵的功能。
-
首先,检查输入的矩阵
matrix是否为空。如果为空,则返回一个空列表,因为没有元素可以遍历。 -
接下来,初始化了五个变量:
l、r、t、b和res。这些变量用于追踪当前螺旋遍历的边界和结果。 -
进入一个无限循环,循环内的代码会不断遍历矩阵的边界,直到所有元素都被遍历完毕。循环中的逻辑如下:
-
从左到右遍历当前的顶部边界(
l到r列),将元素添加到结果列表res中。 -
将
t(顶部边界)向下移动一行,表示上方的行已经被遍历。 -
检查是否上边界
t大于下边界b,如果是,则退出循环,因为所有行都已遍历完。 -
从上到下遍历当前的右边界(
t到b行),将元素添加到结果列表res中。 -
将
r(右边界)向左移动一列,表示右侧的列已经被遍历。 -
检查是否左边界
l大于右边界r,如果是,则退出循环,因为所有列都已遍历完。 -
从右到左遍历当前的底部边界(
r到l列),将元素添加到结果列表res中。 -
将
b(底部边界)向上移动一行,表示下方的行已经被遍历。 -
检查是否上边界
t大于下边界b,如果是,则退出循环,因为所有行都已遍历完。 -
从底到顶遍历当前的左边界(
b到t行),将元素添加到结果列表res中。 -
将
l(左边界)向右移动一列,表示左侧的列已经被遍历。 -
检查是否左边界
l大于右边界r,如果是,则退出循环,因为所有列都已遍历完。
-
-
最后,返回结果列表
res,其中包含了按照螺旋顺序遍历矩阵的所有元素。
通过不断更新边界的方式,模拟了螺旋顺序遍历矩阵的过程,将遍历的元素逐个添加到结果列表中。这是一个常见的矩阵遍历问题,使用了双指针和循环来实现。
十五、矩阵置0
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
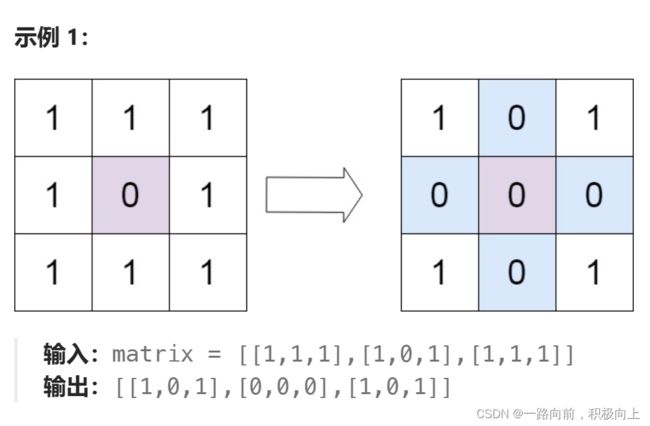
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
row = len(matrix)
col = len(matrix[0])
row0_flag = False
col0_flag = False
# 找第一行是否有0
for j in range(col):
if matrix[0][j] == 0:
row0_flag = True
break
# 第一列是否有0
for i in range(row):
if matrix[i][0] == 0:
col0_flag = True
break
# 把第一行或者第一列作为 标志位
for i in range(1, row):
for j in range(1, col):
if matrix[i][j] == 0:
matrix[i][0] = matrix[0][j] = 0
#print(matrix)
# 置0
for i in range(1, row):
for j in range(1, col):
if matrix[i][0] == 0 or matrix[0][j] == 0:
matrix[i][j] = 0
if row0_flag:
for j in range(col):
matrix[0][j] = 0
if col0_flag:
for i in range(row):
matrix[i][0] = 0
这段代码的目标是将一个二维矩阵中的所有包含0的行和列都置零(将0所在的行和列全部置零),并且在原地修改输入的矩阵 matrix。
以下是对这段代码的解读:
-
首先,获取矩阵的行数
row和列数col,以及两个标志变量row0_flag和col0_flag,它们用来标记第一行和第一列是否有0。 -
使用两个循环遍历第一行和第一列,检查是否有0出现。如果在第一行中找到0,将
row0_flag设置为True,表示第一行需要被置零。如果在第一列中找到0,将col0_flag设置为True,表示第一列需要被置零。 -
接下来,使用两个嵌套的循环遍历除第一行和第一列之外的所有元素。如果发现某个元素为0,将其对应的第一行和第一列的元素设置为0,作为标记。
-
第二次遍历矩阵,将根据标记位的情况,将对应的行和列置零。具体操作是,如果某个元素所在的行的标记位为0,或者该元素所在的列的标记位为0,就将该元素置零。
-
最后,处理第一行和第一列,如果
row0_flag为True,则将第一行全部置零;如果col0_flag为True,则将第一列全部置零。
这段代码的核心思想是使用第一行和第一列作为标记位,通过两次遍历,第一次标记需要置零的行和列,第二次根据标记位置零矩阵中的元素。这样可以在原地修改矩阵,将包含0的行和列都置零。
十六、生命的游戏
根据 百度百科 , 生命游戏 ,简称为 生命 ,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态: 1 即为 活细胞 (live),或 0 即为 死细胞 (dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你 m x n 网格面板 board 的当前状态,返回下一个状态。

复制一份原始数组;
根据复制数组中邻居细胞的状态来更新 board 中的细胞状态。
class Solution:
def gameOfLife(self, board: List[List[int]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
neighbors = [(1,0), (1,-1), (0,-1), (-1,-1), (-1,0), (-1,1), (0,1), (1,1)]
rows = len(board)
cols = len(board[0])
# 从原数组复制一份到 copy_board 中
copy_board = [[board[row][col] for col in range(cols)] for row in range(rows)]
# 遍历面板每一个格子里的细胞
for row in range(rows):
for col in range(cols):
# 对于每一个细胞统计其八个相邻位置里的活细胞数量
live_neighbors = 0
for neighbor in neighbors:
r = (row + neighbor[0])
c = (col + neighbor[1])
# 查看相邻的细胞是否是活细胞
if (r < rows and r >= 0) and (c < cols and c >= 0) and (copy_board[r][c] == 1):
live_neighbors += 1
# 规则 1 或规则 3
if copy_board[row][col] == 1 and (live_neighbors < 2 or live_neighbors > 3):
board[row][col] = 0
# 规则 4
if copy_board[row][col] == 0 and live_neighbors == 3:
board[row][col] = 1
这段代码实现了康威生命游戏(Conway’s Game of Life)的逻辑,该游戏是一个模拟细胞自动机的经典问题。
-
首先,定义了一个变量
neighbors,它包含了8个可能的相邻细胞位置的偏移量。这个列表用于在遍历每个细胞时查找其相邻细胞。 -
获取输入矩阵的行数
rows和列数cols。 -
创建一个名为
copy_board的新矩阵,用于存储原始矩阵的副本。这个副本将用于计算下一代细胞状态,以确保在更新过程中不会影响到原始矩阵。 -
使用两层嵌套循环遍历原始矩阵中的每个细胞。对于每个细胞,执行以下操作:
-
初始化
live_neighbors为0,用于统计当前细胞周围的活细胞数量。 -
遍历
neighbors列表中的每个相邻位置,计算相邻位置的行r和列c。 -
检查相邻位置
(r, c)是否在矩阵范围内,且是否包含活细胞(值为1)。如果是活细胞,增加live_neighbors计数。 -
根据康威生命游戏的规则,进行细胞状态更新:
-
如果当前细胞是活细胞(值为1),并且周围活细胞数量小于2或大于3,说明当前细胞会死亡(变为0)。
-
如果当前细胞是死亡细胞(值为0),并且周围活细胞数量恰好为3,说明当前细胞会复活(变为1)。
-
-
-
最后,原地修改输入矩阵
board,根据上述规则更新每个细胞的状态。
这段代码实现了康威生命游戏的规则,通过遍历和更新每个细胞,模拟了生命的演变过程。这是一个典型的细胞自动机问题,涉及到矩阵操作和规则判断。
十七、赎金信
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。

使用哈希表数据结构。
哈希表(Hash Table)是一种常见的数据结构,用于存储键值对(key-value pairs)的集合,并且能够以常数时间复杂度(平均情况下)进行插入、查找和删除操作。它通过将键映射到特定的位置(索引)来实现高效的数据检索,这个映射函数被称为哈希函数。
以下是关于哈希表的一些相关知识:
-
哈希函数:哈希函数接受一个键作为输入,然后计算出该键对应的哈希值(hash value)。哈希值通常是一个整数,用来表示键在哈希表中的位置。好的哈希函数应该满足以下特点:
- 快速计算:哈希函数应该能够快速计算出哈希值。
- 均匀分布:哈希函数应该能够将不同的键均匀地映射到不同的哈希值,以减少冲突(多个键映射到同一位置)的发生。
-
冲突处理:由于哈希函数可能将不同的键映射到相同的位置,因此需要一种机制来处理冲突。常见的冲突处理方法包括链式哈希(将冲突的键放入链表中)和开放地址法(尝试寻找下一个可用的位置)等。
-
哈希表的实现:哈希表通常由一个数组和一个哈希函数组成。数组用来存储键值对,哈希函数用来计算键的哈希值,并确定在数组中的位置。当有多个键映射到同一位置时,可以使用链表、树等数据结构来存储这些键值对。
在Python中,哈希表的实现通常是通过字典(Dictionary)数据结构来实现的。字典是一种无序的键值对集合,可以使用大括号 {} 或者 dict() 函数创建。Python的字典使用哈希表来存储键值对,因此具有快速的查找、插入和删除操作。
哈希表是一种非常重要的数据结构,它在计算机科学中被广泛应用,用于解决各种问题,例如字典、集合、缓存等。在Python中,字典是内置的哈希表实现,为开发者提供了高效的键值对存储和检索能力。
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
if len(ransomNote) > len(magazine):
return False
return not collections.Counter(ransomNote)-collections.Counter(magazine)
这段代码的目标是判断是否能从杂志字符串 magazine 中构建出勒索信字符串 ransomNote。
-
首先,代码检查
ransomNote字符串的长度是否大于magazine字符串的长度,如果是,直接返回False。因为如果ransomNote的长度大于magazine,那么无论如何都无法从magazine中构建出ransomNote,所以可以立即返回False。 -
接下来,代码使用 Python 中的集合操作来进行判断。具体地说,它使用了
collections.Counter类来创建两个字符串的字符计数器,然后对它们进行减法操作。这个减法操作返回一个新的计数器,其中包含了ransomNote字符串中的字符减去magazine字符串中的字符。 -
最后,代码使用逻辑运算
not来检查新的计数器是否为空。如果新的计数器为空,说明ransomNote中的每个字符都可以在magazine中找到,因此可以构建出ransomNote,返回True;否则,返回False。
专业知识点:
-
字符计数器:在这段代码中,使用了
collections.Counter类来创建字符计数器。字符计数器是一种用于计算字符串中字符出现次数的数据结构。它返回一个字典,其中键是字符串中的字符,值是对应字符出现的次数。通过对字符计数器执行减法操作,可以得到字符的差集,用于比较两个字符串中字符的差异。 -
集合操作:Python提供了丰富的集合操作,如并集、交集、差集等。在这个代码中,使用减法操作来计算字符计数器的差集,从而判断是否能构建
ransomNote。
总的来说,这段代码利用字符计数器和集合操作,以一种非常简洁的方式判断是否能从 magazine 构建出 ransomNote。如果 ransomNote 中的字符都在 magazine 中,并且数量不超过 magazine,则返回 True,否则返回 False。
十八、同构字符串
给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。

哈希表
class Solution:
def isIsomorphic(self, s: str, t: str) -> bool:
s2t = {} # 存储s字符串中字符到t字符串字符的映射
t2s = {} # 存储t字符串中字符到s字符串字符的映射
for sc, tc in zip(s, t):
if (sc in s2t and s2t[sc] != tc) or (tc in t2s and t2s[tc] != sc):
# 如果当前s字符和t字符不匹配,直接返回
return False
# 更新s字符和t字符的映射关系,如果已经存储的映射不改变结果
s2t[sc] = tc
t2s[tc] = sc
return True
这段代码的目标是判断两个字符串 s 和 t 是否是同构的,也就是是否可以通过字符的一一映射将一个字符串转化为另一个字符串。下面是这段代码的解读以及其中涉及的专业知识点:
-
创建两个字典
s2t和t2s,分别用来存储从s到t的字符映射和从t到s的字符映射。 -
使用
zip(s, t)遍历两个输入字符串s和t中的字符。zip函数会将对应位置的字符一一配对。 -
在循环中,对于每一对字符
(sc, tc),执行以下操作:- 检查
s中的字符sc是否在s2t字典中,并且其映射到的字符不等于tc。如果不等于,说明当前字符无法通过映射到正确的字符,返回False,表示不同构。 - 同样地,检查
t中的字符tc是否在t2s字典中,并且其映射到的字符不等于sc。如果不等于,也返回False。 - 如果上述两个条件都没有触发,说明当前字符映射是有效的,于是更新
s2t和t2s字典,将sc映射到tc,将tc映射到sc。
- 检查
-
循环结束后,如果没有出现无法映射的情况,即两个字符串可以通过字符映射相互转化,就返回
True,表示同构。
专业知识点:
-
同构字符串:在这个代码中,同构字符串是指两个字符串中的字符能够通过一一映射互相转化,例如,如果
s中的字符'a'被映射到t中的字符'b',那么在s中的所有'a'应该都会映射到t中的'b',反之亦然。 -
字典(映射):字典是一种键-值对存储的数据结构,在这段代码中用于存储字符映射关系。字典中的键是
s或t中的字符,值是它们对应的映射字符。字典的使用可以高效地进行字符映射的检查和更新。
总的来说,这段代码通过字典和循环遍历的方式来判断两个字符串是否是同构的,如果是,返回 True,否则返回 False。同构字符串的概念在字符串处理和编程面试中经常出现。
十九、单词规律
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。

哈希表
class Solution:
def wordPattern(self, pattern: str, s: str) -> bool:
p2s = {} # pattern中的字符到s中的字符子串的映射表
s2p = {} # s中的字符字串到pattern中的字符的映射表
words = s.split(" ") # 根据空格,提取s中的单词
if len(pattern) != len(words):
return False # 字符数和单词数不一致,一定不匹配
for ch, word in zip(pattern, words):
if (ch in p2s and p2s[ch] != word) or (word in s2p and s2p[word] != ch):
# 字符与单词没有一一映射:即字符记录的映射不是当前单词或单词记录的映射不是当前字符
return False
# 更新映射,已存在的映射更新后仍然是不变的;不存在的映射将被加入
p2s[ch] = word
s2p[word] = ch
return True
这段代码的目标是判断给定的字符串 s 是否符合给定的字符模式 pattern,其中字符模式 pattern 是一个字符串,例如 "abba",而字符串 s 是一个由单词组成的字符串,例如 "dog cat cat dog"。下面是这段代码的解析以及附带的专业知识点:
-
创建两个字典
p2s和s2p,用于存储字符模式pattern中的字符到字符串s中的字符子串的映射,以及字符串s中的字符子串到字符模式pattern中的字符的映射。 -
使用
s.split(" ")将字符串s按空格分割成单词,并将结果存储在words列表中。 -
检查字符模式
pattern和单词列表words的长度是否相同,如果不相同,则返回False。因为字符数和单词数不一致,一定不匹配。 -
使用
zip(pattern, words)遍历字符模式pattern中的字符和单词列表words中的单词。对于每一对字符ch和单词word,执行以下操作:- 检查字典
p2s中是否已存在字符ch并且其映射不等于word,或者字典s2p中是否已存在单词word并且其映射不等于ch。如果满足这两个条件中的任何一个,说明字符和单词之间没有一一映射,返回False。 - 否则,更新映射关系,将字符
ch映射到word,将word映射到字符ch。
- 检查字典
-
如果循环结束后没有触发返回
False的情况,说明字符模式和单词列表之间存在一一映射关系,返回True,表示匹配成功。
专业知识点:
-
字符模式匹配:这段代码实现了字符模式匹配,其中字符模式
pattern中的每个字符都被映射到字符串s中的一个单词,并且要求每个字符模式中的字符都有唯一的映射,同时每个单词也有唯一的映射字符。这种问题通常可以使用字典来实现映射关系的检查和更新。 -
字典(映射):字典是一种键-值对存储的数据结构,在这段代码中用于存储字符和单词之间的映射关系。字典的使用可以高效地进行映射关系的检查和更新。
总的来说,这段代码通过字典和循环遍历的方式来判断字符模式和字符串是否匹配,如果匹配成功,返回 True,否则返回 False。字符模式匹配问题在字符串处理和编程面试中经常出现。
二十、有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。

哈希表
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
diffs = Counter(s) # 统计s中每个字符的待匹配数量
charDiff = len(diffs) # 统计s有多少种字符
for ch in t:
if diffs.get(ch, 0) == 0:
return False # 当前字符在s中已经匹配完了,再出现这个字符说明t中的这个字符多了,即不匹配
diffs[ch] -= 1 # 当前字符待匹配数量减一
if diffs[ch] == 0:
charDiff -= 1 # 如果一个字符的待匹配数量变为0,说明完成了一种字符的匹配,待匹配字符数量减一
return charDiff == 0 # 待匹配字符为0说明s中的所有字符匹配完,二者为异位词
这段代码的目标是判断两个字符串 s 和 t 是否是异位词,即它们包含的字符种类相同,但字符的排列顺序可以不同。下面是这段代码的解析:
-
首先,代码使用
Counter(s)统计字符串s中每个字符的出现次数,并将结果存储在名为diffs的字典中。这个字典的键是字符,值是字符在s中的出现次数。 -
使用变量
charDiff统计字符串s中有多少种不同的字符。初始值等于len(diffs),即s中不同字符的种类数量。 -
接下来,代码遍历字符串
t中的每个字符ch。对于每个字符ch,执行以下操作:- 检查字典
diffs中是否包含键ch,如果不包含,说明当前字符ch在字符串s中已经匹配完了,再次出现这个字符意味着不匹配,直接返回False。 - 如果字典中包含键
ch,将该键对应的值减一,表示匹配了一个字符。 - 如果减一后的值为 0,说明完成了一种字符的匹配,因此将
charDiff减一,表示不同字符的种类数量减一。
- 检查字典
-
最后,判断
charDiff是否等于 0。如果charDiff等于 0,说明所有字符都匹配完了,字符串s和t是异位词,返回True。否则,返回False。
这段代码利用字典和计数的方式来检查两个字符串是否是异位词。异位词问题在字符串处理中经常出现,这种解决方案是一种常见的方法。
二十一、字母的异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。

哈希表,并且使用tuple
元组常用于以下情况:
当需要创建不可变的数据集合时。
用于函数返回多个值的情况,函数可以返回一个元组,而调用函数的代码可以解包元组来获取返回的多个值。
用于字典的键,因为字典的键必须是不可变的对象,而元组是可哈希的(可用作字典的键)。
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
dict = {}
for item in strs:
key =tuple(sorted(item))
dict[key] = dict.get(key,[])+[item]
return list(dict.values())
这段代码的目标是将给定的字符串列表 strs 中的字母异位词分组在一起,并返回分组后的结果列表。
代码的主要逻辑如下:
-
创建一个空字典
dict,用于存储分组后的结果,其中字典的键是元组,元组中的元素是按字母顺序排列的单词字符,字典的值是包含相同字符排列的单词的列表。 -
遍历输入的字符串列表
strs中的每个单词item。 -
对每个单词
item进行排序,并将排序后的结果转换为元组key。这一步是为了将具有相同字母组成的单词映射到相同的键,因为字母异位词的字母排列相同。 -
使用
dict.get(key, [])来获取字典中键key对应的值,如果键不存在则返回一个空列表。然后,将当前的单词item添加到这个值列表中,形成一个分组。 -
更新字典
dict中键key对应的值为新的列表,包含了当前单词item。如果之前没有这个键key,则创建一个新的键值对。 -
最终,通过
list(dict.values())将字典中的所有值(分组后的列表)提取出来,形成一个列表,这个列表包含了所有分组后的结果。
举个例子来说明:
如果输入 strs 是 [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”],那么最终返回的结果将是 [[“eat”, “tea”, “ate”], [“tan”, “nat”], [“bat”]]。这表示具有相同字母组成的单词被分到了同一组中。
这个代码利用了字典来实现字母异位词的分组,通过将具有相同字符排列的单词映射到相同的键,然后将它们添加到同一组中,最终返回了分组的结果。这种方法在处理字母异位词问题时非常高效。
二十二、两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。

数组,哈希表
哈希和字典的区别和联系: