数据分析三剑客之Numpy
数据分析三剑客:Numpy,Pandas,Matplotlib
1.简介
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
numpy是基于c语言开发,所以这使得numpy的运行速度很快,高效率运行就是numpy的一大优势。
首先·我们要导入numpy包,一般我们都把它命名为np:
In [1]: import numpy as np 接着就可以生成一个numpy一维数组:
In [2]: a = np.array([[1,2,3]],dtype=np.int32)
In [3]: a
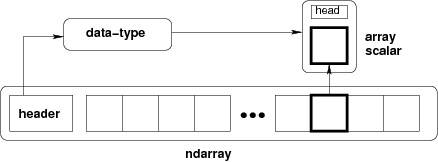
Out[3]: array([1, 2, 3]) numpy中定义的最重要的数据结构是称为ndarray的n维数组类型,这个结构引用了两个对象,一块用于保存数据的存储区域和一个用于描述元素类型的dtype对象:
2.WHY?
二维数组的生成在python中我们还可以用到list列表,如果用list来表示[1,2,3],由于list中的元素可以是任何对象,所以list中保存的是对象的指针,如果要保存[1,2,3]就需要三个指针和三个整数对象,是比较浪费内存资源和cpu计算时间的,而ndarray是一种保存单一数据类型的多维数组结构,在数据处理上比list列表要快上很多,在这里我们可以用%timeit命令来检测两者的数据处理速度:
In [9]: a = range(1000)
In [10]: %timeit[i**2 for i in a]
381 µs ± 6.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [11]: b = np.arange(1000)
In [12]: %timeit b**2
1.41 µs ± 18 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) 由于相同数据大小的array运算直接作用到元素级上这一numpy特性,结果显而易见,在数据处理上numpy数组比使用for循环的list列表快的不是一点两点。
3.常用操作
这里生成一个3×3的矩阵作为例子:
In [2]: data = np.array([[1,2,3],[4,5,6],[7,8,9]]) # 等价于data=np.arange(1,10).reshape(3,3)
In [3]: data
Out[3]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]) 查看矩阵信息:
In [6]: data.shape # 返回元组,表示n行n列
Out[6]: (3, 3)
In [7]: data.dtype # 返回数组数据类型
Out[7]: dtype('int32')
In [8]: data.ndim # 返回是几维数组
Out[8]: 2 转换数据类型:
In [11]: a = data.astype(float) # 拷贝一份新的数组
In [12]: a.dtype
Out[12]: dtype('float64')数组之间的计算:
In [15]: data+data
Out[15]:
array([[ 2, 4, 6],
[ 8, 10, 12],
[14, 16, 18]])
In [16]: data*data
Out[16]:
array([[ 1, 4, 9],
[16, 25, 36],
[49, 64, 81]])可以看出相同规格的数组计算是直接作用在其元素级上的,那不同的规格的数组是否能进行运算呢,我们来看下这个例子:
In [18]: data1 = np.array([[1,2],[1,2]]) #生成一个2x2numpy数组
In [19]: data+data1
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 data+data1
ValueError: operands could not be broadcast together with shapes (3,3) (2,2) 我们可以看出不同规格的数组一起计算的话是会报出广播错误的,那是不是可以下结论了,别急我们再来看下方两个特殊例子:
In [20]: data2 = np.array([[1,2,3]])
In [21]: data + data2
Out[21]:
array([[ 2, 4, 6],
[ 5, 7, 9],
[ 8, 10, 12]])
In [22]: data3 = np.array([[1],[2],[3]])
In [23]: data+data3
Out[23]:
array([[ 2, 3, 4],
[ 6, 7, 8],
[10, 11, 12]])data2数组的列数量与data数组相等,data3数组的行数量与data数组相等,这两个numpy数组虽然规格与data数组不一样,但却依然可以与data数组进行运算。
数组的切片:
In [24]: data[:2] # 沿着行(axis=0)进行索引
Out[24]:
array([[1, 2, 3],
[4, 5, 6]])
In [25]: data[:2,:2] # 先沿着行(axis=0)进行索引,再沿着列(axis=1)进行索引
Out[25]:
array([[1, 2],
[4, 5]])
In [26]: data[1,0:2] # 下标是从0开始
Out[26]: array([4, 5])这里需要注意的是,切片操作是在原始数组上创建一个视图view,这只是访问数组数据的一种方式。 因此原始数组不会被复制到内存中,传递的是一个类似引用的东西,与上面的astype()方法是两种不同的拷贝方式,这里我们来看一个例子:
In [32]: a = data[1]
In [33]: a
Out[33]: array([4, 5, 6])
In [34]: a[:] = 0
In [35]: data
Out[35]:
array([[1, 2, 3],
[0, 0, 0],
[7, 8, 9]])当切片对象a改变时,data的对应值也会跟着改变,这是在我们日常数据处理中有时会疏忽的一个点,最安全的复制方法是使用
copy() 方法进行浅拷贝:
In [36]: a = data[1].copy()
In [37]: a
Out[37]: array([0, 0, 0])
In [38]: a[:]=9
In [39]: data
Out[39]:
array([[1, 2, 3],
[0, 0, 0],
[7, 8, 9]])数组的布尔索引:
In [43]: data
Out[43]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [44]: data>3
Out[44]:
array([[False, False, False],
[ True, True, True],
[ True, True, True]])
In [45]: data[data>3] # 找出大于3的元素
Out[45]: array([4, 5, 6, 7, 8, 9])数组的逻辑表达处理:
In [46]: np.where(data>3,1,0) # 大于3的标记为1,小于等于3的标记为0
Out[46]:
array([[0, 0, 0],
[1, 1, 1],
[1, 1, 1]])数组的常用统计操作:
In [47]: data.mean(axis=0) # 沿着行(axis=0)进行索引,求出其平均值
Out[47]: array([4., 5., 6.])
In [49]: data.std() # 求出全部元素的方差
Out[49]: 2.581988897471611
In [50]: (data>3).sum() # 统计数组中元素大于3的个数
Out[50]: 6
In [51]: data.any() # 数组中是否存在一个或多个true
Out[51]: True
In [52]: data.all() # 数组中是否全部数都是true
Out[52]: True
In [53]: data.cumsum(0) # 沿着行(axis=0)进行索引,进行累加
Out[53]:
array([[ 1, 2, 3],
[ 5, 7, 9],
[12, 15, 18]], dtype=int32)
In [54]: data.cumprod(1) # 沿着列(axis=1)进行索引,进行累乘
Out[54]:
array([[ 1, 2, 6],
[ 4, 20, 120],
[ 7, 56, 504]], dtype=int32)数组的排序操作:
In [55]: data=np.random.randn(4,4)
In [56]: data
Out[56]:
array([[ 1.58669867, 1.57692769, -1.85828013, 1.17201164],
[ 1.68160714, -0.83957549, -0.33771694, -0.33782379],
[-0.03148106, -0.97819034, 0.51126626, -0.08184963],
[-0.02822319, -0.31934723, 0.70764701, 0.80444954]])
In [57]: data.sort(0) # 沿着行(axis=0)进行索引,并进行升序排序
In [58]: data
Out[58]:
array([[-0.03148106, -0.97819034, -1.85828013, -0.33782379],
[-0.02822319, -0.83957549, -0.33771694, -0.08184963],
[ 1.58669867, -0.31934723, 0.51126626, 0.80444954],
[ 1.68160714, 1.57692769, 0.70764701, 1.17201164]])
In [59]: data[::-1] # 降序操作
Out[59]:
array([[ 1.68160714, 1.57692769, 0.70764701, 1.17201164],
[ 1.58669867, -0.31934723, 0.51126626, 0.80444954],
[-0.02822319, -0.83957549, -0.33771694, -0.08184963],
[-0.03148106, -0.97819034, -1.85828013, -0.33782379]])注意:直接调用数组的方法的排序将直接改变数组而不会产生新的拷贝。
矩阵运算:
In [62]: x=np.arange(9).reshape(3,3)
In [63]: x
Out[63]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [64]: np.dot(x,x) # 矩阵相乘
Out[64]:
array([[ 15, 18, 21],
[ 42, 54, 66],
[ 69, 90, 111]])
In [65]: x.T # 矩阵转置
Out[65]:
array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])在numpy中的linalg中有还有很多矩阵运算,比如svd分解,qr分解,cholesky分解等等。
numpy数据的读取和保存:
In [68]: np.save('name',data)
In [69]: np.load('name.npy')
Out[69]:
array([[-0.03148106, -0.97819034, -1.85828013, -0.33782379],
[-0.02822319, -0.83957549, -0.33771694, -0.08184963],
[ 1.58669867, -0.31934723, 0.51126626, 0.80444954],
[ 1.68160714, 1.57692769, 0.70764701, 1.17201164]])