List集合详解
目录
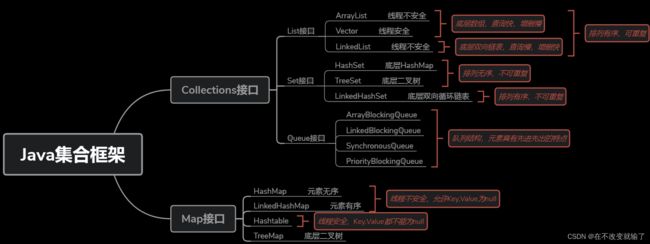
1、集合是什么?
1.1、集合与集合之间的关系
2、List集合的特点
3、遍历集合的三种方式
3.1、foreach(增强佛如循环遍历)
3.2、for循环遍历
3.3、迭代器遍历
4、LinkedList和ArrayList的区别
4.1、为什么ArrayList查询会快一些?
4.2、为什么LinkedList查询会慢一些?
4.3总结--面试常问:
4.3.1、为什么linkedList查询会比Arraylist查询慢?
4.3.2、linkedlist集合和arraylist集合的区别
5、List调优:
5.1、集合的底层
5.2、ArrayList集合的动态扩容机制
5.2.1、触发扩容机制的条件
5.2.2、扩容的流程
5.3、如何进行性能调优呢?--面试常问
6、list集合底层对象去重原理
6.1、流程:
1、集合是什么?
1、简单来说,集合就是一个存放数据的容器,并且可以对存储的内容进行增删改查
2、集合的类型主要有三种
- list集合
- set集合
- map集合
1.1、集合与集合之间的关系
2、List集合的特点
1、有序
2、可以重复
3、具备容器的基本特点,可以进行增删改查
3、遍历集合的三种方式
3.1、foreach(增强佛如循环遍历)
-
// foreach(增强for循环)
-
for (Object object : list) {
-
System.out.println(object);
-
}
3.2、for循环遍历
-
// for循环遍历
-
-
for (
int
i
=
0; i < list.size(); i++) {
-
System.out.println(list.get(i));
-
}
3.3、迭代器遍历
-
// 迭代器
-
Iterator
iterator
= list.iterator();
-
while (iterator.hasNext()) {
-
System.out.println(iterator.next());
-
}
4、LinkedList和ArrayList的区别
-
LinkedList的特点:修改查询慢,新增删除快
-
arraylist集合的特点:修改查询快,新增删除慢
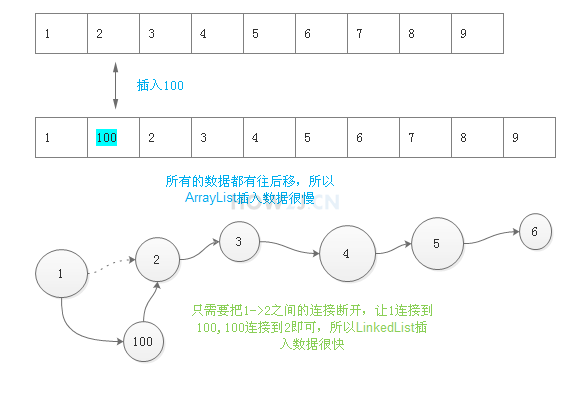
为什么新增删除ArrayList会慢些?
4.1、为什么ArrayList查询会快一些?
ArrayList 是基于数组实现的动态数组,它支持随机访问,可以根据元素的下标快速访问对应元素。具体来说,它内部维护了一个数组,通过索引访问数组元素的时间复杂度为 O(1)。因此 ArrayList 最适合读操作比较频繁的场景。

ArrayList从原理上就是数据结构中的数组,也就是内存中一片连续的空间,这意味着,当我
get(index)的时候,我可以根据数组的(首地址+偏移量),直接计算出我想访问的第index个元素在内存中的位置。
4.2、为什么LinkedList查询会慢一些?
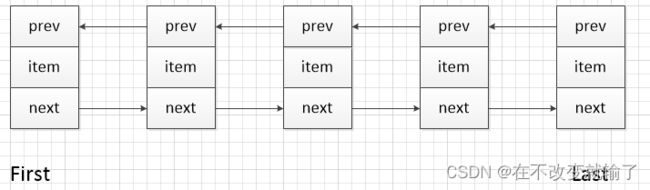
LinkedList 是基于链表实现的,它是一个双向链表,每个节点都有指向前驱节点和后继节点的引用
LinkedList 不支持随机访问,因为它是基于链表数据结构实现的,而链表与数组不同,没有类似于数组的下标操作。
在链表中,每个元素通过指针连接到下一个元素,因此查询链表中的某个元素时,需要从链表的头部或尾部开始遍历,逐个比较元素的值,直到找到所需的元素。
这样的查询方式,与使用数组下标直接查找元素相比,时间复杂度要高很多
4.3总结--面试常问:
4.3.1、为什么linkedList查询会比Arraylist查询慢?
答:首先呢,arraylist他的底层的数据结构呢是一个数组,因为是数组,我们就可以直接的使用数组的get(index)方法直接的获取到数组中的元素,不需要进行遍历就可以拿到数组中的元素,但是linkedlist呢它的底层数据结构是一个双向的链表,而链表结构无法和数组一样通过get(index)直接获取到元素,只能够通过遍历去挨个查找,但是这样不仅使用了更多的资源以及更多的时间,虽然 LinkedList 不支持随机访问,但是它提供了一些查询元素的方法,比如 getFirst()、getLast()、indexOf()、lastIndexOf(),它们会沿着链表进行查询,直到找到对应的元素或者到达链表的末尾。
4.3.2、linkedlist集合和arraylist集合的区别
答:首先这两个集合的最本质上的区别就是两者的底层的数据结构是不同的,而数据结构的不同从而也导致了,两者增删改查效率的一些不同,首先arraylist集合它的特点就是,查询修改快,新增删除慢,因为是数组结构嘛,所以导致了只要在一个指定位置一移除或者增加了一条数据,那么整个数组这条数据后面的所有的数据都会进行移动,是非常耗费资源的,但是linkedlist呢他的底层就是一个链表结构,这种结构有个好处,就是移除了集合中的某个元素只需要改变那个元素的前驱节点和后继节点的指向就可以了,所以效率非常的快
查询的话我就不讲了刚刚问过了
5、List调优:
5.1、集合的底层
集合的底层是什么呢?:答案是数组
那么为什么明明数组的长度是不可变的,但是集合就可以呢?
这里就涉及到了集合的动态数组扩容机制
5.2、ArrayList集合的动态扩容机制
5.2.1、触发扩容机制的条件
首先arraylist刚开始的默认长度为10,当往数组里添加内容的时候,当添加的数据长度达到10时,arraylist就会出发扩容机制
5.2.2、扩容的流程
首先创建一个新的数组,这个新数组的长度是原来数组的1.5倍,然后再使用arrays.copyof()的方法将老数组中的数据复制到新的数组之中 扩容完后,再将新的数据添加到新的数组之中去
5.3、如何进行性能调优呢?--面试常问
选择合适的容器:不同的场景下需要使用不同的容器。如前所述,ArrayList 适用于读取操作比较多的场景,而 LinkedList 适用于插入和删除频繁的场景。在选择容器时,需要根据实际情况进行权衡和选择。
指定初始值:在创建 ArrayList 容器时,可以指定其大小,避免频繁调整数组大小带来的性能损耗。在实际应用中,往往需要根据数据量的大小进行估算。如果确实无法估算,可以使用默认大小的初始化方法,不过记得为容器预留出一些空间,以便能够加载新元素。
尽量减少扩容操作:扩容是比较耗时的操作,可以尝试通过预估所需容量来预先分配更多的容量,以减少扩容的次数。在进行大量元素添加操作时,可以使用 addAll(Collection c) 方法,将多个元素一同添加到 List 容器中,以避免使用 add(E e) 方法频繁进行扩容操作。
避免频繁的查询操作:除了 ArrayList 支持随机访问以外,其他容器需要进行遍历操作才可以得到元素。在进行查询操作时,需要尽量避免频繁的遍历操作,可以使用相应的查询方法,如 getFirst()、getLast()、indexOf()、lastIndexOf() 等。如果确实需要进行遍历操作,可以考虑使用 ListIterator 接口,以进行快速的遍历和查询。
6、list集合底层对象去重原理
6.1、流程:
遍历老集合,将集合中的每一条数据进行比较,如果新的集合中不包含条件中的数据,那么就将其放到新数组中去,看代码!

但是此时有个问题,这样子判断真的可以吗?答案是不行的
如果老集合中的数据是基本类型,那应该可以
但是如果是引用类型,就必须重写eqluas方法。为什么?
因为如果不进行重写,那么条件中进行判断的就是内存地址了,如果重写了,就是真正的比较值了,所以List去重复是根据重写的equals方法来的
注:过几天具体写一下ArrayList的扩容机制以及LinkedList如何去创建一个堆栈容器,还搞得不是很懂️