RNN模型与NLP应用笔记(1):类别特征数据处理基础知识(One-hot Encoding)
一.写在前面
今天主要介绍循环神经网络(RNN)。
作为深度学习小白,同样是入门RNN花了一段时间,同样也在查看了众多大佬们的笔记和视频后,终于弄懂了RNN的基础知识,深感好记性不如烂笔头,此系列博客参考王树森老师、李沐老师等大佬们的教材和讲解视频,若理解有误,还望读者斧正。
在正式进入循环神经网络之前,我们需要理解该模型的数据处理基础方式。
此小节主要记录categorical feature(类别特征)的常见处理方式:One-hot coding(独热编码)
机器学习的数据通常由类别特征,这些特征往往是文字或者字符串的形式展示,
我们需要把这些类别特征转化成机器学习模型能理解的数值特征 。
目录
一.写在前面
二.引入
三.文本处理基本原理
四.总结
五.参考资料
(多图预警)
二.引入
我们用一个例子来具体讲解开的类别特征的处理方式:
如下图是一张表,这张表的每一行是一个人的数据 包括年龄、性别、国籍
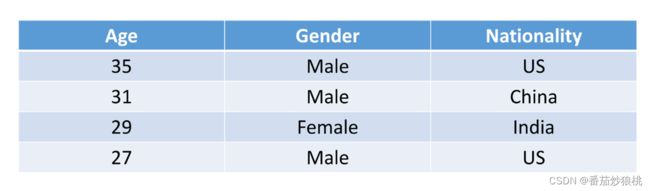
我们需要把这些数据变成机器学习模型可以理解的数值特征,
第一列是年龄,年龄本身就是数值特征,所以不用做处理,数值特征的特点是可以比较大小。
(Eg: 35岁的人比31岁的人年龄大)

第二列是性别, 性别是二元特征,我们可以用一个数字来表示性别,用数字0表示女性,用1表示男性。这样一来,性别就表示为一个标量,0或者1

第三列是国籍,比如美国、中国、印度。国籍是开的类别特征,机器学习并不理解国籍(需要用数值进行表示),所以我们要把国籍编码成数值向量,世界上约有197个国家,我们首先用一个1-197的整数来表示国家,可以建立一个字典,把国籍应设为1-197的整数。
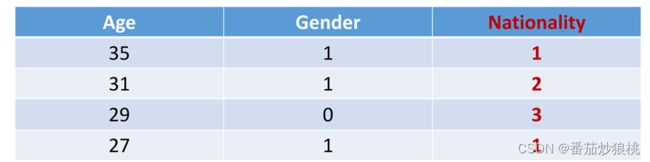
可以建立一个字典,把国籍应设为1-197的整数,比如美国对应1中国对应2印度对应3等等,我们要从1开始数,而不能从0开始数,之后会解释原因,经过这种映射,国籍就表示成了1-197之间的整数

用数字替换后的国家列表展示如下图,但根据前面的叙述,数字特征的特点是可以进行大小比较,仅仅把国籍表示为1-197之间的整数,还是不行,一个整数只是一个类别,它们之间不能比较大小,把中国表示为2印度表示为3,这个数字并不代表印度大于中国,这些整数只是类别而已 并不是真正的数值特征,所以要进一步对国籍做one-hot Encoding(独热编码)
用one-hot向量来表示国级,比如美国对应数字1所以用这个197位的向量来表示美国就是一个长度为197的向量,其第一个元素是1,其余元素是0(如下图所示)。同理,中国是用数字2来表示的,在One-hot编码中,对应的长度为197的向量中,第二个元素为1,其余元素为0。
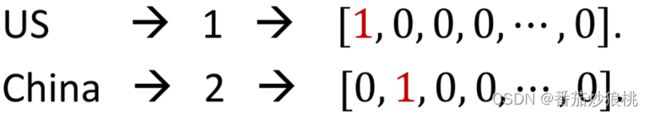
因此,依照One-hot编码,可以得到如下的表格。(其中向量长度为197表示的是全世界的国家数)如图:

有197个国家,所以每个向量都是197位的,我刚才说我们要从1开始数,美国对应1,中国对应数字2,印度对应数字3,不能从0开始数,是因为我们要把数字0保留,用来表示未知或者缺失的国籍,数据库里经常会有缺失数据,有人可能不愿意填写国籍,这就造成了缺失,缺失的国籍就用零来表示,数字0的one-hot的向量就是个全零的向量(197位全部为0)
因此,在这个例子里面,我们用一个199维的向量表示一个人的特征,比如这个人28岁,女性,国籍是中国 她的特征向量就是这个199维的向量,一个维度表示年龄,一个维度表示性别,用197维的弯号向量来表示国籍

同理如下图所示,对于一个36岁男性国籍未知的人的特征,使用One-hot编码依旧是个199维的向量。
 我们用一个197维的全零向量来表示未知国籍,处理开类别特征的时候, 我用one-hot向量来表示国籍,每个国籍都用197维的向量来表示。
我们用一个197维的全零向量来表示未知国籍,处理开类别特征的时候, 我用one-hot向量来表示国籍,每个国籍都用197维的向量来表示。
有可能你会有疑问,用一个数字表示国籍行不行呢?(为什么要用one-hot coding)
比如,用1表示美国 用2表示中国 3表示印度,这样一来,名字就变成了数字,就可以做数值计算了,而且用一个数字表示可以节省197倍的存储与计算,这样不是更好么?
当然这是不行的,否则我们就不需要one-hot Encoding,假如我们用1表示美国,数字2表示中国,数字3表示印度,那么我们把美国与中国的特征加起来,1+2就等于3于是:美国+中国=印度,这样的特征完全不合理。
用one-hot的特征向量更合理,把美国与中国的弯号的特征向量加起来,就可以得到等于一个新的特征向量,如下图所示,该特征向量的第一个和第二个元素都是1,其余元素是0。
得到的这个特征向量表示的是既有美国国籍,也有中国国籍,我们可以发现,做机器学习的时候,不能用一个标量来表示类别特征,这样做是无意义的,正确的做法是用one-hot向量来表示Categorical Features(类别特征)

三.文本处理基本原理
在自然语言处理(NLP)的应用中,数据都是文本,文本可以分割成很多单词,我们需要把单词表示成数值向量,每个单词就是一个类别,如果字典里有10000个单词,那么就有10000个类别。显然单词就是Categorical Features(类别特征),我们用处理Categorical Features(类别特征)的方法,把单词变成数值向量
文本处理的第一步是把文本分割成单词,一段话、一篇文章或者一本书可以表示成一个字符串。可以把document分割成很多单词,这个操作叫做tokenization(分词)
比如下图的这句话 to be or not to be,可以分割成这些单词,可以被若干个单词(词元),to,be,or,not,to,be。tokenization把文本变成单词的列表

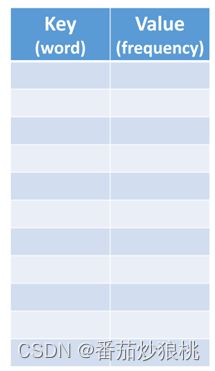
第二步是计算词频。也就是每个单词出现的次数可以用一个哈希表来计数,如图,一开始的时候哈希表是空的。
我们举例说明哈希表的更新方式,
假如单词w不在表里面,这就说明w还没有出现在文本里,到目前为止,我只看到w一次,所以我把w加入哈西表 让他的词品等于1。
假如单词w在哈希表里面,说明w之前出现在文本里,只需要把它的词频加1。
举个例子,我们挨个处理下面列表里的单词:

假设此时对应的哈希表如下图:

处理到单词to的时候,我查一下哈希表,如图所示,发现哈希表里面有处有该词,它的词频是398。

这说明to已经出现在文章里398次了,现在这个单词又出现了一次,于是把表里的词频加1,如下图所示,此时,从398变成399。

如图,处理到单词b 发现表里面有b这个单词,发现它已经出现在文章里131次了

此时单词b又出现了一次,如下图,所以把该词的词频由131变成132。

针对单词or在表里找不到的情况,如下图,这说明文章里还没有出现过or这个单词,这是单词沃尔第一次出现在文章里, 于是把or插入表里,把词频设置为1。(如下图所示)

如下图,完成统计词频之后,把哈希表做一个排序,让单词按照词频递减的顺序排列。表的最前面是词频最高的,表最后是词频最低的。

如图,然后就把磁频成是index,从1开始数,词频最高的词的index(索引)就是是1,这个例子里一共有8个单词,每个词对应一个1-8之间的正整数,这个表就叫做字典,可以把单词映射到一个数字(根据词频排列顺序赋予索引下标),字典里单词的个数叫做vocabulary即词汇量。这个例子里vocabulary等于8,英语里大约有10000个常用词。

然后,统计词频之后,你会发现字典里有几十万甚至上百万个单词,统计词频的目的就是保留常用词,去掉低频词。比如,你可以保留词频最高的10000个词,删掉其余单词。
思考一下,为什么要删掉低频词呢?
很多低频词汇是名字或者姓氏,假如笔者的名字出现在一个数据集里面,它的频率肯定会很低,在大多数的应用里面姓氏没有意义,低频词还有可能是拼写错误造成的,假如你把prince的c写成s 那么就创造了一个新的单词,这种词的频率也很低,在很多应用里去掉这些低频词没有危害,去掉低频词的另一个原因是我们不希望vocabulary太大。
下一步做one-hot coding的时候,向量的维度就是vocabulary, vocabulary越大,one-hot向量的维度就会越高,这会让计算变慢,接下来后续章节说到Word Embedding的时候你会看到vocabulary越大,模型参数就会越多,这很容易造成模型的过拟合,删掉低频词就可以大幅减小vocabulary(词汇量)。减小vocabulary(词汇量)是有好处的。
到目前为止,我们已经完成了两个步骤:
第一步 tokenization把文本分割成单词的列表
第二步建立一个字典,把每个单词映射到一个正整数
现在开始第三步,对单词做one-hot Encoding
如图,首先通过查字典把每个单词进行设到一个正整数,一个单词的列表就变成了正整数的列表,如果有必要,就进一步把这些正整数变成one-hot向量。

这些one-hot向量的维度等于vocabulary 在这个例子里面vocabulary是8。所以one-hot向量的维度就等于8,刚才讲过字典里的低频词可能会被删掉,所以有些词在字典里找不到,如图所示,假如把to be的be错误拼写成bi, 这个词在字典里就找不到,做one-hot Encoding的时候,此时可以忽略掉这个词,也可以把它编码成0。

感谢大家的阅读,下一章节将详细叙述文本处理。
四.总结
文本处理三步骤:
1. tokenization把文本分割成单词的列表
2.建立一个字典,把每个单词映射到一个正整数
3. 对单词做one-hot Encoding
五.参考资料
https://github.com/wangshusen/DeepLearning