图论初步(存储+最短路)
文章目录
-
- 一、 引入
- 二、基础知识
- 三、图的表示(存储结构)
-
- (一)*直接存边
- (二)邻接矩阵
- (三)邻接表
- (四)链式前向星
- 四、最短路
-
- (一)Floyd
- (二)Dijkstra
一、 引入
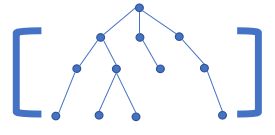
作为一名 OIer ,从变量,到数组,再到 STL,最后是树,我们已经接触了许多不同形态的数据结构,现整理如下4种:
| 集合 | 链表、队列、栈等 |
|---|---|
 |
 |
| 树 | 图 |
 |
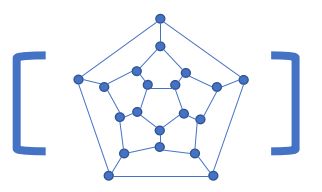 |
我们今天要谈的就是第4种数据结构—— 图 。
二、基础知识
注:带星号的内容是补充内容
-
定义: 图 (Graph) 是由若干给定的顶点及连接两顶点的边所构成的图形。
-
功能: 通常用来描述某些事物之间的某种 特定关系 (顶点用于代表事物,边用于表示两个事物间所具有某种关系 )。
-
组成:( 二元组: G = ( V ( G ) , E ( G ) ) G=(V(G),E(G)) G=(V(G),E(G)) )
- V ( G ) V(G) V(G) : 点集 (vertex set) ,对于 V V V 中的每个元素,我们称其为 顶点 (vertex) 或 节点 (node),简称 点 。
- E ( G ) E(G) E(G) 为 V ( G ) V(G) V(G) 各结点之间边的集合,称为 边集 (edge set)。
-
种类 & 特定术语:
-
无向图 (边没有指定方向的图):
- E E E 中的每个元素为一个无序二元组 ( u , v ) (u,v) (u,v),称作 无向边 (undirected edge),简称 边 (edge)。
- 设 e = ( u , v ) e=(u,v) e=(u,v),其中 ,则 u u u 和 v v v 称为 e e e 的 端点 (endpoint)。
-
有向图(边具有指定方向的图):
- E E E 中的每一个元素为一个有序二元组 ( u , v ) (u,v) (u,v),有时也写作 u → v u \to v u→v,称作 有向边 (directed edge) 或 弧 (arc),在不引起混淆的情况下也可以称作 边 (edge)。
- 设 e = u → v e=u \to v e=u→v,则此时 u u u 称为 e e e 的 起点 或 弧头 (tail) , v v v 称为 e e e 的 终点 或 弧尾 (head) 。
- 起点和终点也称为 e e e 的 端点 (endpoint)。并称 u u u 是 v v v 的直接前驱, v v v 是 u u u 的直接后继。
-
*混合图 ( 无向图 + 有向图 ):
- E E E 中既有向边,又有无向边。
-
带(赋)权图( 边上带有权值的图 ):
- G G G 的每条边 e k = ( u k , v k ) e_k=(u_k,v_k) ek=(uk,vk) 都被赋予一个数作为该边的 权 。
-
- 如果这些权都是正实数,就称 G G G 为 正权图;反之,为 负权图。
-
其它术语:
-
对于两顶点 u u u 和 v v v ,若存在边 ( u , v ) (u,v) (u,v),则称 u u u 和 v v v 是 相邻的 (adjacent)。
-
路径 (path): 相邻顶点的序列。
-
圈 (cycle): 起点和终点重合的路径。
-
连通图 (connected graph) : 任意两点之间都有路径连接的图。
-
自环 (loop): 对 E E E 中的边 e = ( u , v ) e=(u,v) e=(u,v),若 u = v u=v u=v,则 e e e 被称作一个自环。
-
度 (degree) : 与一个顶点 v v v 关联的边的条数,记作 d ( v ) d(v) d(v) 。( 度 = 入度 + 出度,记作 d ( v ) = d − ( v ) + d + ( v ) d(v)=d^-(v)+d^+(v) d(v)=d−(v)+d+(v) )
在有向图中:
- 入度 (in-degree): 以点 v v v 为弧头的边的数目称为该顶点的入度,记作 d − ( v ) d^-(v) d−(v)。
-
- 出度 (out-degre): 以点 v v v 为弧尾的边的数目称为该顶点的出度,记作 d + ( v ) d^+(v) d+(v)。
*握手定理(图论基本定理):对于任何无向图 G = ( V , E ) G=(V,E) G=(V,E),有 ∑ v ∈ V d ( v ) = 2 ∣ E ∣ \sum_{v \in V}d(v)=2 \left|E\right| ∑v∈Vd(v)=2∣E∣,进一步有 ∑ v ∈ V d − ( v ) = ∑ v ∈ V d + ( v ) = ∣ E ∣ \sum_{v \in V}d^-(v)=\sum_{v \in V}d^+(v)=\left|E\right| ∑v∈Vd−(v)=∑v∈Vd+(v)=∣E∣。
推论: 在任意图中,度数为奇数的点必然有偶数个。
-
*阶 (order): 图 G G G 的点数 $ \left| V(G) \right| $ 。
-
树 (tree): 没有圈的连通图。
-
森林 (forest): 没有圈的非连通图。
-
**有向环 (暂无): **一条至少含有一条边且起点和终点相同的有向路径。
-
有向无环图 (DAG): 没有环的有向图。
-
三、图的表示(存储结构)
注:带星号的内容是补充内容。以下内容中,n代表节点总数,m代表边总数。距离均为无向图。
(一)*直接存边
//定义 & 初始化
struct Edge { int u, v; };
vector<Edge> E;
E.resize((m << 1) + 5);
//存边
for (int i = 1, u, v; i <= m; i++) {
scanf("%d%d", &u, &v);
E[i].u = E[i + m].v = u;
E[i].v = E[i + m].u = v;
}
//遍历与u相邻的所有点,并输出 & 输出总数
int cnt = 0;
for (int i = 1; i <= m << 1; i++)
if (E[i].u == u)
printf("%d ", v), cnt++;
printf("\n%d", cnt);
//判断u,v之间是否存在某条边
for (int i = 1; i <= m; i++)
if (E[i].u == u && E[i].v == v)
return true;
return false;
-
实现
使用一个结构体数组来存边,数组中的每个元素都包含一条边的起点与终点(带边权的图还包含边权)。
-
特点 & 应用
-
优点:
-
在 Kruskal 算法(最小生成树) 中,由于需要将边按边权排序,需要直接存边。
-
在有的题目中,需要多次建图(如建一遍原图,建一遍反图),此时既可以使用多个其它数据结构来同时存储多张图,也可以将边直接存下来,需要重新建图时利用直接存下的边来建图。
-
-
缺点:由于直接存边的遍历效率低下,一般不用于遍历图。
-
-
时间复杂度
查询是否存在某条边: O ( m ) O(m) O(m)。
遍历与一个点相关的所有边: O ( m ) O(m) O(m)。
遍历整张图: O ( n m ) O(nm) O(nm)。
空间复杂度: O ( m ) O(m) O(m)。
(二)邻接矩阵
//定义 & 初始化
int G[MAXN][MAXN];
//存边
for (int i = 1; i <= m; i++) {
scanf("%d%d", &u, &v);
G[u][v] = G[v][u] = 1;
}
//遍历与u相邻的所有点,并输出 & 输出总数
int cnt = 0;
for (int v = 1; v <= n; v++)
if (G[u][v])
printf("%d ", v), cnt++;
printf("\n%d", cnt);
//判断u,v之间是否存在某条边
return G[u][v];
-
实现
使用一个二维数组
G来存边,其中 G u , v G_{u,v} Gu,v 为 1 表示存在 u u u 到 v v v 的边,为 0 表示不存在。特别地,如该图为无向图,则有 G u , v = G v , u G_{u,v}=G_{v,u} Gu,v=Gv,u。
如果是带边权的图,则可以在 G u , v G_{u,v} Gu,v 中存储 u u u 到 v v v 的边的边权。
-
特点 & 应用
在无向图中,任一顶点 i i i 的度为第 i i i 列(或第 i i i 行)所有非零元素的个数。
在有向图中,顶点 i i i 的出度为:第 i i i 行所有非零元素的个数,入度为:第 i i i 列所有非零元素的个数
-
优点: 可以 O ( 1 ) O(1) O(1) 查询一条边是否存在。
-
缺点:
-
邻接矩阵只适用于没有重边(或重边可以忽略,比如求最短路的时候取最小边权)的情况。
-
由于邻接矩阵在稀疏图上效率很低(尤其是在点数较多的图上,空间无法承受),所以一般只会在稠密图上使用邻接矩阵。
-
-
-
时间复杂度
查询是否存在某条边: O ( 1 ) O(1) O(1)。
遍历与一个点相关的所有边: O ( n ) O(n) O(n)。
遍历整张图: O ( n 2 ) O(n^2) O(n2)。
空间复杂度: O ( n 2 ) O(n^2) O(n2)。
(三)邻接表
//定义 & 初始化
vector<int> G[MAXN];
//存边
for (int i = 1, u, v; i <= m; i++) {
scanf("%d%d", &u, &v);
G[u].push_back(v);
G[v].push_back(u);
}
//遍历与u相邻的所有点,并输出 & 输出总数
for (auto v : G[u])
printf("%d ", v);
printf("\n%d", G[u].size());
//判断u,v之间是否存在某条边
for (auto i : G[u])
if (i == v)
return false;
return true;
-
实现
使用一个动态数组
vector G[MAXN]来存边,其中 G u G_u Gu 存储的是与点 u u u 相关的所有边的信息(终点、边权等)。 -
特点 & 应用
- 优点:存各种图都很适合,除非有特殊需求(如需要快速查询一条边是否存在,且点数较少,可以使用邻接矩阵)。
尤其适用于需要对一个点的所有出边进行排序的场合。
-
时间复杂度
查询是否存在某条边: O ( d ( n ) ) O(d(n)) O(d(n)), 如果事先进行了排序就可以使用 二分 做到 O ( log ( d ( u ) ) ) O(\log(d(u))) O(log(d(u))))。
遍历与一个点相关的所有边: O ( d ( u ) ) O(d(u)) O(d(u))。
遍历整张图: O ( n + m ) O(n+m) O(n+m)。
空间复杂度: O ( m ) O(m) O(m)。
(四)链式前向星
//定义 & 初始化
struct Edge {
int next, to;
} edge[MAXN];
int head[MAXN];
//存边
int cnt = 0;
void AddEdge (int u, int v) {
size[u]++, size[v]++;
edge[++cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
for (int i = 1, u, v; i <= m; i++) {
scanf("%d%d", &u, &v);
AddEdge(u, v);
AddEdge(v, u);
}
//遍历与u相邻的所有点,并输出 & 输出总数
int tot = 0;
for (int i = head[u]; i; i = edge[i].next)
printf("%d ", edge[i].to), tot++;
printf("\n%d", tot);
//判断u,v之间是否存在某条边
for (int i = head[u]; i; i = edge[i].next)
if (edge[i].to == v)
return true;
return false;
-
实现
本质上是用链表实现的邻接表,不同在于,链式前向星是给每条边编上号,然后规定遍历顺序。
- 与邻接表类似,链式前向星存储的是与每个节点所关联的边,所以链式前向星也需存储每一条边的终点(及权值)。我们用边结构体中的 t o to to 表示第 i i i 条边所指向的点,用 q q q 表示第 i i i 条边的权值。
- 现在我们需要处理在遍历时的顺序。我们用 h e a d x head_x headx 表示点 x x x 指向的第一条边的编号,而边结构体中的 n e x t next next 表示该边的下一条边的编号。遍历时,循环变量初值 i i i 即为所需遍历点 u u u 的 h a e d u haed_u haedu,而每次 i i i 则被赋值为 e d g e i . n e x t edge_i.next edgei.next。
- 定义完变量后我们需要考虑如何添加一条边,假定添加一条起点为 u u u,终点为 v v v,权值为 w w w 的边。
- 统计边序号的变量 c n t cnt cnt 自加,即 c n t ← c n t + 1 cnt \leftarrow cnt+1 cnt←cnt+1(初值为0)。
- 赋该边的权值 e d g e c n t . w ← w edge_{cnt}.w \leftarrow w edgecnt.w←w。
- 由于在 h e a d u head_u headu 前加入了这条边,所以 e d g e c n t . n e x t ← h e a d u edge_{cnt}.next \leftarrow head_u edgecnt.next←headu。
- 此时,由于第 c n t cnt cnt 条边成为了第一个遍历对象,所以 h e a d u ← c n t head_u \leftarrow cnt headu←cnt。
-
特点 & 应用
-
优点:
- 存各种图都很适合。
- *由于边是带编号的,有时会非常有用,而且如果 c n t cnt cnt 的初始值为奇数,存双向边时
i ^ 1即是i的反边(常用于 网络流)。
-
缺点: 不能快速查询一条边是否存在,也不能方便地对一个点的出边进行排序。
-
-
时间复杂度
查询是否存在某条边: O ( d ( n ) ) O(d(n)) O(d(n))。
遍历与一个点相关的所有边: O ( d ( u ) ) O(d(u)) O(d(u))。
遍历整张图: O ( n + m ) O(n+m) O(n+m)。
空间复杂度: O ( m ) O(m) O(m)。
四、最短路
(一)Floyd
//定义 & 读入
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (i != j) F[i][j] = INF;
for (int i = 1, u, v, w; i <= m; i++) {
scanf("%d%d%lf", &u, &v, &w);
F[u][v] = min(F[u][v], w); //防止重边
}
//具体算法
void Floyd () {
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
F[i][j] = min(F[i][j], F[i][k] + F[k][j]);
}
-
实现
-
我们定义一个数组 F k , i , j F_{k,i,j} Fk,i,j,表示只允许经过结点 1 1 1 到 k k k,即在子图 V ′ = 1 , 2 , . . . , k V^{\prime}=1,2,...,k V′=1,2,...,k 中的路径,结点 i i i 到结点 j j j 的最短路长度。很显然, F n , i , j F_{n,i,j} Fn,i,j 就是结点 到结点 的最短路长度。
-
接下来考虑如何求出 F F F 数组的值。
-
F 0 , i , j = { 0 i = j + ∞ ( i , j ) ∉ E w ( i , j ) ( i , j ) ∈ E \begin{equation} F_{0,i,j} = \left\{ \begin{aligned} 0 & \quad & i=j\\ +\infty & \quad & (i,j) \notin E\\ w(i,j) & \quad & (i,j) \in E\\ \end{aligned} \right. \end{equation} F0,i,j=⎩ ⎨ ⎧0+∞w(i,j)i=j(i,j)∈/E(i,j)∈E
i = j i=j i=j ,即从自己到自己,则 F 0 , i , j = 0 F_{0,i,j}=0 F0,i,j=0。
i , j i,j i,j 无边相连,则 F 0 , i , j = + ∞ F_{0,i,j}=+\infty F0,i,j=+∞。
i , j i,j i,j 有边相连,则 F 0 , i , j = w ( i , j ) F_{0,i,j}=w(i,j) F0,i,j=w(i,j)。
-
F k , i , j F_{k,i,j} Fk,i,j: F k , i , j = min ( F k − 1 , i , j , F k − 1 , i , k + F k − 1 , k , j ) F_{k,i,j}=\min(F_{k-1,i,j},F_{k-1,i,k}+F_{k-1,k,j}) Fk,i,j=min(Fk−1,i,j,Fk−1,i,k+Fk−1,k,j) 。其中,
F k − 1 , i , j F_{k-1,i,j} Fk−1,i,j,为不经过 k k k 点,经过 1 1 1 到 k − 1 k-1 k−1 的从 i i i 到 j j j 的最短路径。
F k − 1 , i , k F_{k-1,i,k} Fk−1,i,k,为经过 1 1 1 到 k − 1 k-1 k−1 从 i i i 到 k k k 的最短路。
F k − 1 , k , j F_{k-1,k,j} Fk−1,k,j,为经过 1 1 1 到 k − 1 k-1 k−1 从 k k k 到 j j j 的最短路。
故, F k − 1 , i , k + F k − 1 , k , j F_{k-1,i,k}+F_{k-1,k,j} Fk−1,i,k+Fk−1,k,j 为先经过 1 1 1 到 k − 1 k-1 k−1 从 i i i 到 k k k,再经过 1 1 1 到 k − 1 k-1 k−1 从 k k k 到 j j j 的最短路。
即是,经过 k k k 点,从 i i i 到 j j j 的最短路径。
-
-
-
优化
时间上已经不能优化了,而空间上,我们可以省略数组的第一维,于是可以改成
F[i][j] = min(F[i][j], F[i][k] + F[k][j]);。But……Why……
我们注意到 F k , i , j F_{k,i,j} Fk,i,j 的涵义是第一维为 k − 1 k-1 k−1 这一行和这一列的所有元素的最小值,包含了 F k − 1 , i , j F_{k-1,i,j} Fk−1,i,j,那么我在原地进行更改也不会改变最小值的值,因为如果将该三维矩阵压缩为二维,则所求结果 F i , j F_{i,j} Fi,j一开始即为原 F k − 1 , i , j F_{k-1,i,j} Fk−1,i,j 的值,最后依然会成为该行和该列的最小值。
故可以压缩。
-
Question & Answer
Q1: 为什么中间点 k k k 需在最外层枚举?
A1: 由于 F k F_k Fk 是由 F k − 1 F_{k-1} Fk−1 转移而来的,所以我们可以将枚举的中间点 k k k 视为 DP 的阶段,因此 k k k 作为阶段必须在最外层枚举。
-
特点
是用来求任意两个结点之间的最短路的,即多源最短路。
复杂度比较高,但是常数小,容易实现。
适用于任何图,不管有向无向,边权正负,但是最短路必须存在。(不能有负环)
-
应用
- 给一个正权无向图,找一个最小权值和的环。e.g. Sightseeing Trip
- 已知一个有向图中任意两点之间是否有连边,要求判断任意两点是否连通。e.g. 还没找到。。。
-
复杂度
时间复杂度: O ( N 3 ) O(N^3) O(N3),
空间复杂度: O ( N 2 ) O(N^2) O(N2)。
(二)Dijkstra
//定义 & 读入
struct Edge {
int v, w;
Edge (int V, int W) { v = V, w = W; }
};
struct Node {
int u, dis;
Node (int U, int Dis) { u = U, dis = Dis; }
bool operator < (Node x) const { return dis > x.dis; }
};
vector<Edge> G[MAXN];
int dis[MAXN];
bool vis[MAXN]
for (int i = 1, u, v, w = 1; i <= m; i++) {
scanf("%d%d", &u, &v);
G[u].push_back(Edge(v, w));
G[v].push_back(Edge(u, w));
}
//具体算法
int Dijkstra (int S, int T) {
for (int i = 1; i <= n; i++)
dis[i] = INF, vis[i] = 0;
dis[S] = 0;
priority_queue<Node> Q;
Q.push(Node(S, 0));
while (!Q.empty()) {
int u = Q.top().u;
Q.pop();
if (vis[u]) continue;
vis[u] = true;
for (auto v : G[u])
if (dis[v.v] > dis[u] + v.w)
dis[v.v] = dis[u] + v.w,
Q.push(Node(v.v, dis[v.v]));
}
return dis[T];
}
-
流程
将结点分成两个集合:已确定最短路长度的点集(记为 S S S 集合)的和未确定最短路长度的点集(记为 T T T 集合)。一开始所有的点都属于 T T T 集合。
-
初始化 d i s s = 0 dis_s=0 diss=0,其他点的 d i s dis dis 均为 + ∞ +\infty +∞。
-
然后重复以下操作,直到 T T T 集合为空,算法结束。
- 从 T T T 集合中,选取一个最短路长度最小的结点,移到 S S S 集合中。
- 对那些刚刚被加入 S S S 集合的结点的所有出边执行松弛操作。
-
-
优化 & 时间复杂度
- 暴力: 不使用任何数据结构进行维护,每次 2 操作执行完毕后,直接在 T T T 集合中暴力寻找最短路长度最小的结点。1 操作总时间复杂度为 O ( m ) O(m) O(m),2 操作总时间复杂度为 O ( n 2 ) O(n^2) O(n2),全过程的时间复杂度为 O ( n 2 + m ) = O ( n 2 ) O(n^2+m)=O(n^2) O(n2+m)=O(n2)。
- *二叉堆: 每成功松弛一条边 ( u , v ) (u,v) (u,v),就将 v v v 插入二叉堆中(如果 v v v 已经在二叉堆中,直接修改相应元素的权值即可),1 操作直接取堆顶结点即可。共计 O ( m ) O(m) O(m) 次二叉堆上的插入(修改)操作, O ( n ) O(n) O(n) 次删除堆顶操作,而插入(修改)和删除的时间复杂度均为 O ( log n ) O(\log n) O(logn),时间复杂度为 O ( ( n + m ) log n ) = O ( m log n ) O((n+m) \log n)=O(m \log n) O((n+m)logn)=O(mlogn)。
- 优先队列: 和二叉堆类似,但使用优先队列时,如果同一个点的最短路被更新多次,因为先前更新时插入的元素不能被删除,也不能被修改,只能留在优先队列中,故优先队列内的元素个数是 O ( m ) O(m) O(m) 的,时间复杂度为 O ( m log m ) O(m \log m) O(mlogm)。
-
特点 & 应用
是一种求解 非负权图 上单源最短路径的算法。
本质是贪心。
持续更新中。。。(话说我好慢)