Flink 系例之 SQL 案例 - 订单统计
本期示例:
将对电商实时订单进行聚合计算,分以下两个维度进行:
1. 统计每 1 分钟的订单数量、用户数量、销售额、商品数
2. 统计每个分类的订单总数量、用户总数量(未去重)、销售额、商品数
流程说明:

1. 通过模拟电商平台订单简要数据,向 Kafka 消息队列中推送 mq 数据;
2. 通过 flink 集群,建立 SQL 流批处理任务;
3.Kafka 做为 SQL 数据流的输入源,并建立 source 数据表;
4. 通过 SQL 建立查询视图,将聚合算子的结果通过视图输出;
5.Mysql 做为 SQL 数据流的输出源,并建立 sink 数据表;
6. 执行 insert 操作,并在 flink 集群中建立 Task Job 任务,将聚合结果视图输出到 sink 表;
操作过程
1. 前期准备工作
1. 搭建 Flink 集群,保持集群可用,并处于启动状态
2. 开启 flink-sql-client 客户端
3. 搭建 Kafka 消息队列中间件服务,并启动服务,保持 9092 端口可连接
4. 创建 mysql 数据库相关表
5. 上述服务搭建过程,省略...(或参见历史相关文章)
mysql 相关表,如下:
每分钟订单统计表
CREATE TABLE`min_order_count` (
`time_str`varchar(40) NOT NULL,
`order_num`int(8) DEFAULT NULL,
`sales_amount`decimal(12,2) DEFAULT NULL,
`user_num`int(8) DEFAULT NULL,
`count_num`int(8) DEFAULT NULL,
PRIMARY KEY (`time_str`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4分类订单统计表
CREATE TABLE`type_order_count` (
`goods_type`varchar(40) NOT NULL,
`order_num`int(8) DEFAULT NULL,
`sales_amount`decimal(12,2) DEFAULT NULL,
`user_num`int(8) DEFAULT NULL,
`count_num`int(8) DEFAULT NULL,
PRIMARY KEY (`goods_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4参见:flink 启动与退出命令
# 只需启动master主机即可,会自动发送指令启动slaves
./bin/start-cluster.sh
# 停止集群
./bin/stop-cluster.sh
# 启动sql客户端(依赖集群)
./bin/sql-client.sh embedded
# 退出窗口
quit;订单数据结构
{
"orderId": "202103201105397126154",
"userName": "褚贰",
"goodsType": "母婴",
"orderTime": "2021-03-20 11:05:39",
"orderTimeSeries": 1616209539712,
"price": 118.82,
"num": 3,
"totalPrice": 356.46
}2. 统计每 1 分钟的订单数量
2.1 订单数据 source 表
1. 在 flinkSQL 窗口,建立 source 表,并通过连接器从 kafka 中获取数据流;
-- 创建订单来源表(获取kafka数据流)
CREATE TABLE order_source (
orderId STRING,
userName STRING,
goodsType STRING,
price DECIMAL(12, 2),
num INT,
orderTime STRING,
orderTimeSeries BIGINT,
totalPrice DECIMAL(12, 2),
ts AS TO_TIMESTAMP(FROM_UNIXTIME(orderTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss')),
WATERMARK FOR ts as ts - INTERVAL'5'SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'order_behavior',
'properties.bootstrap.servers' = '192.168.1.1:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
-- 查看一张表或者视图的 Schema。
DESCRIBE order_source;示例解读:
-- 表示将orderTimeSeries时间戳转换为ts时间格式
ts AS TO_TIMESTAMP(FROM_UNIXTIME(orderTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss'))
-- 设置水印,表示按ts时间定义水印位,允许5秒延迟,防止数据并没有严格按时间顺序流入后,对窗口内数据进行再计算
WATERMARK FOR ts as ts - INTERVAL '5' SECOND
-- 通过计算列产生一个处理时间列(PROCTIME()内置时间函数)
proctime as PROCTIME(),
-- scan.startup.mode 指offset的消费模式,有五种模式:
earliest-offset表示从topic中最初的数据开始消费
latest-offset表示从topic中最新的数据开始消费
group-offsets表示从topic中指定的group上次消费的位置开始消费,所以必须配置group.id参数
timestamp表示从topic中指定的时间点开始消费,指定时间点之前的数据忽略,需结合'scan.startup.timestamp-millis'配置一起使用
specific-offsets表示从topic中指定的offset开始,这个比较复杂,需要手动指定offset,结合'scan.startup.specific-offsets'配置一起使用查询 SQL:
-- 查询结果
select orderId,userName,goodsType,orderTime,orderTimeSeries,price,num,totalPrice,ts from order_source;
-- 统计每种订单类型的总量
select goodsType,count(orderId) as orderCount from order_source group by goodsType;
-- 统计每种订单类型的总价
select goodsType,sum(totalPrice) as totalPrice from order_source group by goodsType;
-- 基于时间字段排序
select orderId,userName,goodsType,totalPrice from order_source order by ts;
-- 查询时间排序的前3条记录。注意:LIMIT 查询需要有一个 ORDER BY 。
select orderId,userName,goodsType,totalPrice from order_source order by ts limit 3;2.2 建立订单数据 sink 表
1. 订单聚合计算后,需要将结果存入到数据库,通过连接器建立 mysql 数据流输出表(mysql 表需要提前建立)
-- 创建按分钟统计表
CREATE TABLE min_order_count_sink (
time_str STRING,
order_num INT,
user_num INT,
sales_amount DECIMAL(12, 2),
count_num INT,
PRIMARY KEY (time_str) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.1:3306/flink?useUnicode=true&characterEncoding=utf-8',
'driver' = 'com.mysql.jdbc.Driver',
'table-name' = 'min_order_count',
'username' = 'root',
'password' = 'root'
);
-- 查看一张表或者视图的 Schema。
DESCRIBE min_order_count_sink ;2.3 创建查询视图
-- 创建按每1分钟统计订单数的视图
CREATE VIEW count_min_order_view AS
SELECT DATE_FORMAT(TUMBLE_START(ts, INTERVAL'1'MINUTE), 'HH:mm') as window_start,
DATE_FORMAT(TUMBLE_END(ts, INTERVAL'1'MINUTE), 'HH:mm') as window_end,
COUNT(orderId) as order_num,
COUNT(userName) as user_num,
SUM(totalPrice) as sales_amount,
SUM(num) as count_num
FROM order_source
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE);-- 讲解
TUMBLE_START(ts, INTERVAL '1' MINUTE):返回TIMESTAMP类型;返回窗口的起始时间(包含边界)。例如[00:10,00:15)窗口,返回00:10。
TUMBLE_END(ts, INTERVAL '1' MINUTE):返回TIMESTAMP类型;返回窗口的结束时间(包含边界)。例如[00:00, 00:15]窗口,返回00:15。
GROUPBYTUMBLE(ts, INTERVAL '1' MINUTE), goodsType:组合分组统计字段:ts时间属性(1分钟内所有数据)和goodsTypeTUMBLE函数:用在GROUPBY子句中,用来定义滚动窗口。2.4 建立 JOB 任务
在 SQL 窗口执行以下 insert 后,并会在 flink 平台建立 job 任务,JOB 任务运行后,按窗口规则将统计结果从视图中插入到 sink 数据输出表。
-- 将视图数据插入到按每分统计的维度表
insert into min_order_count_sink
select window_end as time_str,
cast(order_num asINT),
cast(user_num asINT)
,cast(sales_amount asDECIMAL)
,cast(count_num asINT)
from count_min_order_view;2.5 按类型统计订单信息
创建 Mysql 输出表
-- 创建按类型统计订单信息
CREATE TABLE type_order_count_sink (
goods_type STRING,
order_num INT,
user_num INT,
sales_amount DECIMAL(12, 2),
count_num INT,
PRIMARY KEY (goods_type) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.1:3306/flink?useUnicode=true&characterEncoding=utf-8',
'driver' = 'com.mysql.jdbc.Driver',
'table-name' = 'type_order_count',
'username' = 'root',
'password' = 'root'
);
-- 查看一张表或者视图的 Schema。
DESCRIBE type_order_count_sink ;基于时间窗口的聚合统计查询
示例 1
-- 使用Event Time统计每个分类每分钟的订单数示例
SELECT
TUMBLE_START(ts, INTERVAL'1'MINUTE) as window_start,
TUMBLE_END(ts, INTERVAL'1'MINUTE) as window_end,
goodsType,
COUNT(orderId)
FROM order_source
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE), goodsType;-- 讲解
TUMBLE_START(ts, INTERVAL '1' MINUTE):返回TIMESTAMP类型;返回窗口的起始时间(包含边界)。例如[00:10,00:15)窗口,返回00:10。
TUMBLE_END(ts, INTERVAL '1' MINUTE) :返回TIMESTAMP类型;返回窗口的结束时间(包含边界)。例如[00:00, 00:15]窗口,返回00:15。
GROUPBYTUMBLE(ts, INTERVAL '1' MINUTE), goodsType:组合分组统计字段:ts时间属性(1分钟内所有数据)和goodsTypeTUMBLE函数:用在GROUPBY子句中,用来定义滚动窗口。示例 2
-- 统计每个分类过去1分钟的订单数,每30秒更新1次,即1分钟的窗口,30秒滑动1次。
SELECT
HOP_START (ts, INTERVAL'30'SECOND, INTERVAL'1'MINUTE),
HOP_END (ts, INTERVAL'30'SECOND, INTERVAL'1'MINUTE),
goodsType,
COUNT (orderId)
FROM order_source
GROUP BY HOP (ts, INTERVAL'30'SECOND, INTERVAL'1'MINUTE), goodsType;-- 讲解
HOP_START (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE):返回TIMESTAMP类型;返回窗口的起始时间(包含边界)。例如[00:10, 00:15) 窗口,返回00:10 。
HOP_END (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE):返回TIMESTAMP类型; 返回窗口的结束时间(包含边界)。例如[00:00, 00:15) 窗口,返回00:15。
GROUP BY HOP (ts, INTERVAL '30' SECOND, INTERVAL '1' MINUTE), goodsType: 组合分组统计字段:ts时间属性(每次加载30秒,但统计1分钟内所有数据)和goodsType
HOP函数: 用在groupby子句中,用来定义滑动窗口。示例 3
SELECT DATE_FORMAT(TUMBLE_START(ts, INTERVAL'1'MINUTE), 'HH:mm') as window_start,
DATE_FORMAT(TUMBLE_END(ts, INTERVAL'1'MINUTE), 'HH:mm') as window_end,
COUNT(orderId)
FROM order_source
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE);-- 讲解
DATE_FORMAT:对时间格式化,如:
DATE_FORMAT(TUMBLE_ROWTIME(ctime, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS')创建统计结果视图
-- 创建按每1分钟统计分类订单数的视图
CREATE VIEW count_type_order_view AS
SELECT
goodsType as goods_type,
COUNT(orderId) as order_num,
COUNT(userName) as user_num,
SUM(totalPrice) as sales_amount,
SUM(num) as count_num
FROM order_source
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE), goodsType;-- 讲解
GROUPBYTUMBLE(ts, INTERVAL '1' MINUTE), goodsType:组合分组统计字段:ts时间属性(1分钟内所有数据)和goodsTypeTUMBLE函数:用在GROUPBY子句中,用来定义滚动窗口。2.6 建立 JOB 任务
同样在 SQL 窗口执行以下 insert 后,并会在 flink 平台建立 job 任务,JOB 任务运行后,按窗口规则将统计结果从视图中插入到 sink 数据输出表。
-- 将视图数据插入到按每分统计的维度表
insert into type_order_count_sink
select goods_type,
cast(order_num asINT),
cast(user_num asINT),
cast(sales_amount asDECIMAL(12, 2)),
cast(count_num asINT)
from count_type_order_view;2.7 常用 SHOW 命令
-- 目前 Flink SQL 支持下列 SHOW 语句:
SHOW CATALOGS
SHOW DATABASES
SHOW TABLES
SHOW VIEWS
SHOW FUNCTIONS结果展示
提交任务

flink 集群运行 JOB 作业

查询 Mysql 统计表
查询分类表输出的统计结果
SELECT * FROM`type_order_count`
查询分钟表输出的统计结果
SELECT * FROM`min_order_count` ORDER BY time_str DESC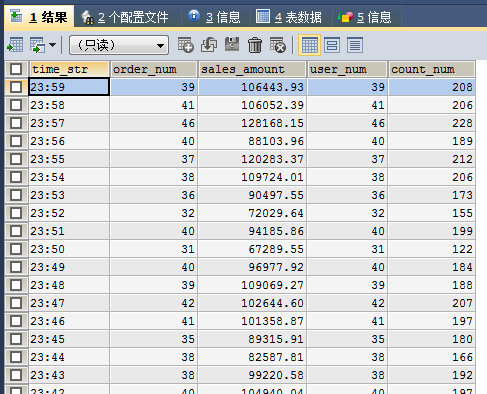
问题处理
问题 1
[ERROR] Could not execute SQL statement. Reason: java.lang.RuntimeException: RowTime field should not be null, please convert it to a non-null long value. Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSourceFactory' in the classpath.
处理:缺少包,补充:lib/flink-table-common-1.11.1.jar
问题 2
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'jdbc' that implements 'org.apache.flink.table.factories.DynamicTableSourceFactory' in the classpath.
处理:缺少包,补充:lib/flink-connector-jdbc_2.12-1.11.1.jar
问题 3
[ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.TableException: Sort on a non-time-attribute field is not supported.
处理:流处理结果需要根据 时间属性 按照升序进行排序。
问题 4
-- 在 ts 上定义 watermark,ts 成为事件时间列 Caused by: java.lang.RuntimeException: RowTime field should not be null, please convert it to a non-null long value.
处理:ts 时间类型不能为空,时间需要做格式转换,如:ts AS TO_TIMESTAMP (FROM_UNIXTIME (orderTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss'))
问题 5
[ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Field types of query result and registered TableSink default_catalog.default_database.order_sink do not match. Query schema: [goods_type: VARCHAR(2147483647), count_num: BIGINT NOT NULL] Sink schema: [id: BIGINT, goods_type: VARCHAR(2147483647), count_num: INT]
处理:count_num 查询结果类型为 BIGINT,而 sink 的输出表字段类型为 INT, 需强转
insert into order_sink select goods_type,cast(count_num as INT) as count_num from count_order_type_view;
问题 6
[ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Field types of query result and registered TableSink default_catalog.default_database.order_sink do not match. Query schema: [goods_type: VARCHAR(2147483647), count_num: INT NOT NULL] Sink schema: [id: BIGINT, goods_type: VARCHAR(2147483647), count_num: INT]
处理:注意:此处已是对 count_num 做了转换后的错误提示,从字段分析来看是 ID 缺少输入值,可以在用 0 来表示 id 的自增主键值(select 0 from table),为 0 则 mysql 识别会默认自增值代替;
问题 7
[ERROR] Could not execute SQL statement. Reason:java.lang.IllegalStateException: please declare primary key for sink table when query contains update/delete record.
处理:当查询包含更新 / 删除记录时,请声明接收器表的主键。
问题 8
JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy Caused by: java.io.IOException: Cannot connect to the client to send back the stream Caused by: java.net.ConnectException: Connection refused
处理:如果在 flink WEB UI 上停止 job,则有可能会导制 kafka 和 mysql 拒绝连接,netstat -apn|grep 9092 查看端口,大量 TIME_WAIT 状态;因没有设置 job 的重启策略,则需要重启 flink 服务;
问题 9
关于 flinkSQL 中的并行度设置
处理:目前 flink 1.11 sql 是不支持 source/sink 并行度配置的,flink sql 中各算子并行度默认是根据 source 的 partition 数或文件数来决定的;