Hadoop下载安装及HDFS配置教程
Hadoop下载安装及HDFS配置教程
前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
简言之,Hadoop的核心就是解决两个问题,一是存储(采用HDFS),二是计算(采用MapReduce编程模型)
一、Hadoop HDFS简单集群框架原理
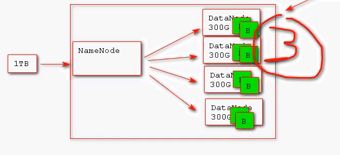
NameNode:整个hdfs集群的管理者,不存储实际文件数据,只记录文件数据的元数据信息(如,数据切分为多少块block,每块数据及其备份数据存储在哪台服务器节点上(NameNode))
DataNode:真正用来存储数据的节点
Block(数据块):既然要分布式处理,就要将数据切分,然后分布在各个服务器节点上。Block就是由NameNode对数据文件进行切分的最小单元。在hadoop2.x版本中一个Block块为128M;在hadoop1.x版本中一个Block块为64M;
Replice(副本):HDFS集群为了保证数据高可用性,默认会对一个数据块进行3次备份(讲白了,就是对每一个Block备份3次,这3次备份数据分别合理的分配在不同的服务器上,防止一个服务器挂掉,数据就丢失或者损坏的问题)
机房 长啥样?我是没见过,如果有机会见见也是极好的,不过网传大概就这样吧,不知道我对于万一所有机房都被坏人干掉了的担心是否多余(天真脸)
二、Hadoop安装准备
1、安装虚拟机VMware
Hadoop框架运行组lunix系统之上,那么window系统上如何运行Hadoop呢?这就需要虚拟机了。VMWare (Virtual Machine ware)是一个“虚拟PC”软件公司,它的产品可以使你在一台机器上同时运行二个或更多Windows、DOS、LINUX系统。简单来说是一种软件,用它可以在一个系统中装另外一个系统。这就满足了我们window系统上安装lunix系统的需求。
1.1 VMware Workstation Pro 15.5下载
链接:https://pan.baidu.com/s/1Z3H3SNKgmvcAYD7_Q1rQlQ
提取码:0zty
1.2 虚拟机安装
一直下一步直到安装完成,虚拟机秘钥:
https://blog.csdn.net/qq_35995514/article/details/98473444
2、在虚拟机上安装CentOS系统
2.1 CentOS系统下载
https://www.jianshu.com/p/a63f47e096e8
2.2 CentOS系统安装:
https://www.runoob.com/w3cnote/vmware-install-centos7.html
对于CentOS系统的安装,我建议新手直接选择【典型】配置即可,不必设置太多自定义选项。系统安装关键两点和在电脑上安装window系统一样,选择系统位置和分配磁盘空间。
2.3 JDK安装和环境配置:
https://www.cnblogs.com/maomao999/p/9764251.html
三、Hadoop安装和HDFS配置
1、下载Hadoop
到Apache官方网站下载自己对应版本即可
https://hadoop.apache.org/releases.html
2、建议保留安装的初始CentOS系统,然后克隆这个初始系统,进行Hadoop的相关配置
因为CentOS系统安装一次很麻烦,不必要每次都安装一次,保留安装好的初始系统,后面搭建集群的时候,只需要克隆这个初始系统就可以了。

3、添加ip地址和hostname以及ip和hostname的关联
3.1查看ip地址
ifconfig
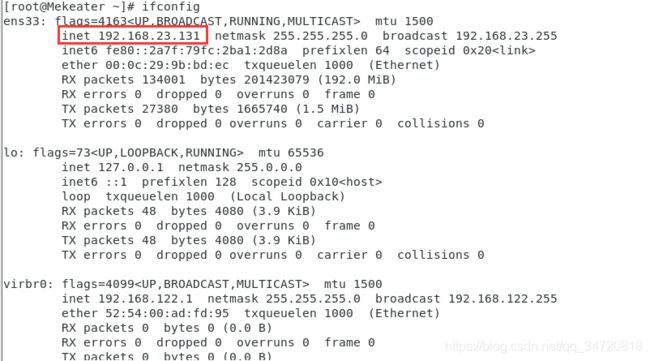
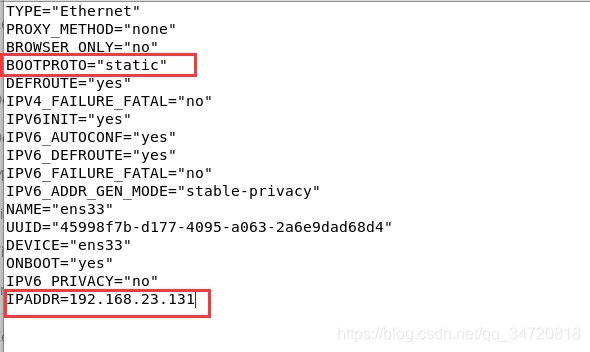
3.2 添加ip地址到ifcfg-ens33文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
注意:BOOTPROTO要修改为static,不然CentOS的ip地址是动态的,下次重启系统可能就不是我们配置的那个ip了,导致无法在浏览器查看
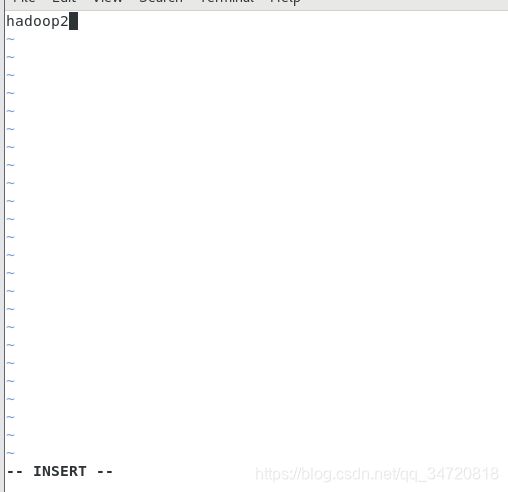
3.3 修改hostname名字
vim /etc/hostname
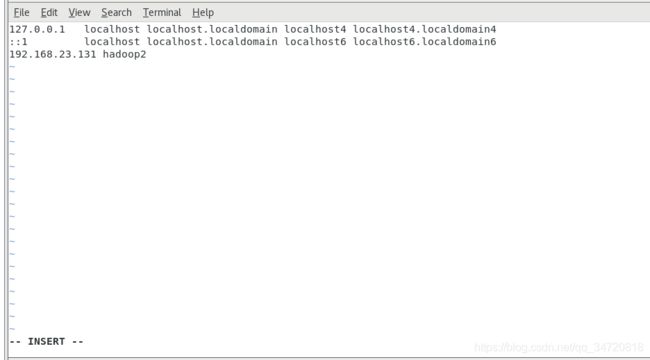
3.4 将ip与hostname关联
vim /etc/hosts
3.5 重启系统
reboot
4、将hadoop压缩包通过Xftp传到CentOS系统中
Xftp 6 下载:
链接:https://pan.baidu.com/s/1CmUg_MKi3cbAKaR8306A6Q
提取码:w42m


5、解压hadoop压缩包
tar -zxvf hadoop-2.9.2.tar.gz

5.1 hadoop文件结构
bin文件夹:里面都是可执行的二进制脚本文件
etc/hadoop文件夹:里面都是hadoop系统配置文件,后面对于hadoopp的配置文件都在这个目录。
sbn文件夹:里面都是可执行的二进制脚本文件,里面包括HDFS的启动,关闭
share文件夹:里面是hadoop的文档和运行核心包
6、配置hadoop环境变量
编辑环境变量
vim /etc/profile
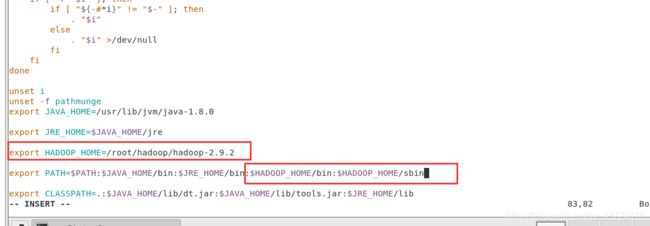
重新加载配置
source /etc/profile
验证hadoop是否加入环境变量
echo $PATH
![]()
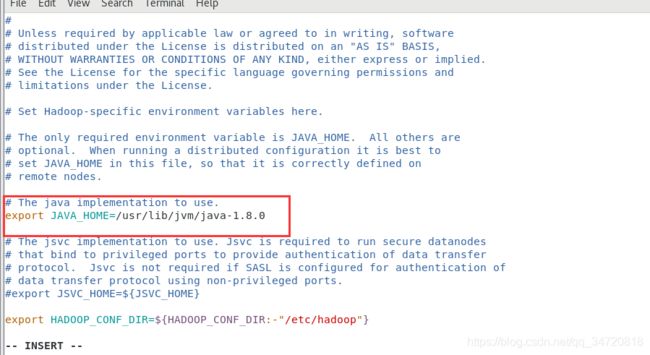
7、配置hadoop-env.sh
将JAVA的路径配置到hadoop的环境文件中
vim /root/hadoop/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
8、配置core-sit.xml
vim /root/hadoop/hadoop-2.9.2/etc/hadoop/core-site.xml
1、配置哪台机器为namenode
fs.defaultFS
hdfs://hadoop2:9000
2、默认hadoop的配置将数据放在系统临时目录中:/tmp/hadoop-${user.name},系统临时目录可能会导致集群数据的不安全,因此修改配置,将数据存放在指定的目录,本文将数据存放在解压后的hadoop-2.9.2的下的data文件夹下
hadoop.tmp.dir
/root/hadoop/hadoop-2.9.2/data
9、配置hdfs-site.xml(用来对hdfs文件系统做相关配置)
vim /root/hadoop/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
1、修改block的副本数据,因为本次hdfs是单机版的集群,只有一个服务器,3个副本也没有地方放,所以,把副本数修改为1
dfs.replication
1
2、修改root的权限,这样可以让非root用户也可以操作hdfs
dfs.permissions.enabled
false
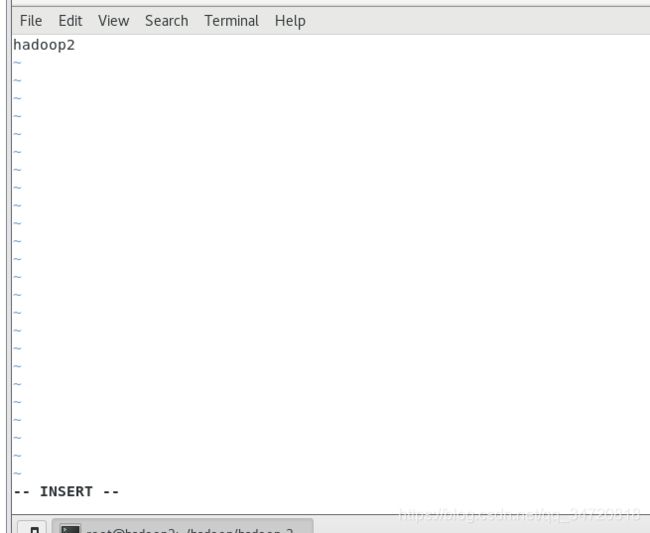
10、配置slaves文件,就是配置哪些机器为DataNode节点,跟随NameNode同时启动
vim /root/hadoop/hadoop-2.9.2/etc/hadoop/slaves
本机既作NameNode又充当DataNode
11、格式化NameNode(仅仅第一次需要格式化)
就像U盘一样,插到windows系统上需要格式化为windows的文件系统,插到lunix系统上需要格式化为lunix的文件系统
hdfs namenode -format
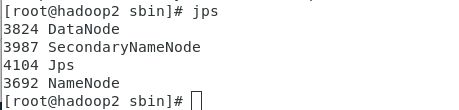
12、启动hdfs集群
start-dfs.sh
查看是否启动成功
jps
如下图则启动成功
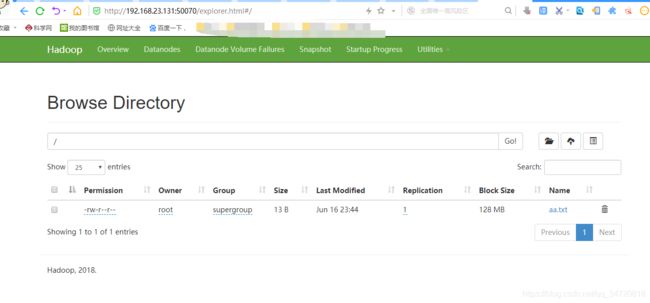
13、上传文件数据到hdfs
如将aa.txt文件上传到hdfs的根目录(/)
hdfs dfs -put ./aa.txt/
14、访问hdfs可视化管理界面
关闭防火墙
systemctl stop firewalld
在浏览器中输入 IP地址:50070即可查看