【linux】基本工具gcc/g++及Makefile
文章目录
- 一、程序翻译过程
-
- 1、程序的翻译过程
- 2、理解选项的含义
- 3、动态链接与静态链接
- 二、Linux项目自动化构建工具-make/Makefile
-
- 1、背景
- 2、实例说明
- 3、原理
- 4、语法
- 5、为什么gcc不更新文件
- 6、推导规则
- 三、小程序——进度条
-
- 1、sleep 和 \n
- 2、行缓冲区概念
- 3、\r 和 \n
- 4、fflush(stdout)
- 5、倒计时的实现
- 6、进度条实现
一、程序翻译过程
在C语言的最后几节我们讲到了一个程序是如何进行编译链接的,这里我们回顾一下前面的知识,然后开始新的内容
1、程序的翻译过程
1、预处理(也可以叫做 预编译):头文件展开,自动删除注释,宏的自动替换,条件编译…
2、编译:把我们的C语言代码转换成为汇编代码
3、汇编:把汇编代码转换为二进制(不是可执行的,二进制目标文件不能被执行)
4、链接:把我们写的C语言代码和C标准库中的代码合起来
2、理解选项的含义
在linux中,我们如果直接gcc/g++ test.c(文件名),就会跳过上面的4个步骤,直接生成最终的a.out可执行程序(对应windows下面的.exe文件),所以我们在linux中,一步步操作,这样便于理解:

3、动态链接与静态链接
我们写的C语言代码中,写入的scanf和printf等等函数,并不是我们写好的,而是C标准库提供给我们的接口,我们直接拿来使用就行了。我们只是调用了库函数,并没有对应的实现!只有当链接的时候,对应的实现才和我们的代码关联起来。这就有了链接
链接本质:我们调用库函数的时候和标准库如何关联的问题
这种关联就包括动态和静态
• 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
• 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。gcc hello.o –o hello
• gcc默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。
总结:
动态链接:受库升级或者被删除的影响,形成的可执行程序小,节约资源
静态链接:不受库升级或者被删除的影响,形成的可执行程序大,网络、磁盘、内存
linux下的命名:
• 动态库 : lib XXXXX .so
• 静态库 : lib XXXXX .a
去掉前缀lib和对应的后缀就是库的名字。举例:libc.so.6就是C的标准库
对于动态库和静态库而言,动态库是系统自带的,我们安装系统之后就可以直接使用;静态库则需要我们安装的,也就是说:静态库并不是直接拷贝动态库的内容。
安装静态库的命令:sudo yum install -y glibc-static
安装完成之后,在原来的命令后面加上 -static,就是静态库编译了:

系统为了支持我们编程,给我们提供了标准库.h(告诉我们怎么用)标准的动态库和静态库.so/.a(告诉我们方法实现有,直接去找就可以)
windows下的动态库:.dll 静态库:.lib
我的代码+库的代码=可执行程序!
二、Linux项目自动化构建工具-make/Makefile
1、背景
1、 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
2、一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
3、makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
4、make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
5、make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2、实例说明
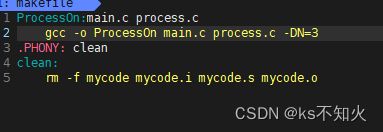
对于makefile,想要使用make命令,必须要有makefile名字的文件(m可以大写为M)。在makefile内部编写一定的依赖规则之后,我们使用make就可以执行对应程序了,可以省略gcc test.c -o test
的编译命令
步骤1:创建一个makefile文件,并且在makefile文件里面编辑好对应的依赖关系和依赖方法


步骤2:make执行程序

这样就不用再写gcc编译了
3、原理
makefile的原理最核心的就是:依赖关系和依赖方法
对于上面的样例来说:
makefile文件中,第一行表示依赖关系:mycode文件依赖于mycode.c实现的,mycode依赖于mycode.c。但仅仅有依赖关系是不够的,还要知道什么原因才依赖的,这就是依赖方法。第二行中,mycode是经过gcc编译生成的,即gcc就是依赖方法
4、语法

上图第一行仍然依赖关系,当时下面必须是tap键的空格,而不是我们直接按空格键
** .PHONY:被关键字修饰的对象是一个伪目标,这个伪目标总是被执行的
我们使用make clear就可以删除mycode文件
那么怎么理解:伪目标总是被执行的这句话呢?

但是如果修改makefile文件:


注意:对于makefile来说,第一条指令是默认规定直接make就可以执行的,比如上面的gcc
5、为什么gcc不更新文件
上面我们可以看到gcc对于最新版本的可执行文件是不会执行成功的,这是因为:mycode.c的modify时间比mycode的modify时间早,即在最新的mycode.c生成的mycode是不会被gcc再次执行的,除非把mycode.c的modfiy时间更改到比mycode的modfiy时间晚,才能执行gcc
但是如果.PHONY修饰之后,就能够执行是因为:.PHONY修饰之后,就不遵循这个所谓的时间规则
6、推导规则
我们按照上面程序翻译过程的步骤来拆分,最终结果是一样的


对于makefile内部的依赖关系来说,mycode依赖于mycode.o,但是此时并没有mycode.o,所以就要寻找mycode.o的依赖对象mycode.s,mycode.s继续找它的依赖对象mycode.i,mycode.i继续找它的依赖对象mycode.c。因为mycode.c存在,所以执行程序是从下到上的
这里我们只是推导,实际中我们没必要这么麻烦,直接一条gcc指令就可以完成
三、小程序——进度条
我们直接基于上面的mycode.c文件里面写
1、sleep 和 \n


我们可以看到,明明printf在sleep前面执行的,为什么是先休眠2秒,再打印出you can see me …呢?
实际上,这就是一个缓冲区的问题,我们的确先执行的printf,后执行的sleep,但是先执行的printf不是直接打印在显示器上面的,而是进入了缓冲区。这就是为什么先休眠了2秒再打印内容的
2、行缓冲区概念
但是我们加上\n就不会先休眠再打印内容,可以直接先打印出内容,只是为什么呢?
这是因为:\n具有刷新缓冲区的作用,我们把\n称为行缓冲
我们来看看:
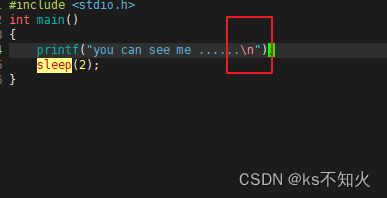

我们可以看到是先打印内容,再休眠2秒
3、\r 和 \n
\r :回车
\n :换行
在语法层面上\n既有回车,又有换行的作用,但是原始作用要区分清楚
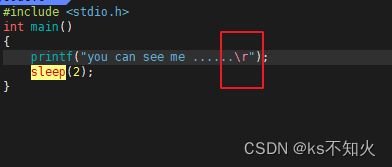

不显示的原因就是我们回车\r将之前的内容全部覆盖掉了,并且在缓冲区也回到了起始位置,导致了程序结束也没有打印
4、fflush(stdout)


5、倒计时的实现

我们知道\r是回到起始位置,但是不控制格式为2d的话,打印结果为10,90,80,70,60…,所以我们要覆盖第一个位置,采用2d控制格式,并且fflush(stdout)

6、进度条实现
我们和学习数据结构的时候一样,采用三个文件的方式进行:
makefile: