last_hidden_state vs pooler_output的区别
一、问题来源:
from transformers import AutoTokenizer, AutoModel
import torch
# Load model from HuggingFace Hub
MODEL_NAME_PATH = 'xxxx/model/bge-large-zh'
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME_PATH)
model = AutoModel.from_pretrained(MODEL_NAME_PATH)
模型结构如下:
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 1024, padding_idx=0)
(position_embeddings): Embedding(512, 1024)
(token_type_embeddings): Embedding(2, 1024)
(LayerNorm): LayerNorm((1024,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-23): 24 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=1024, out_features=1024, bias=True)
(key): Linear(in_features=1024, out_features=1024, bias=True)
(value): Linear(in_features=1024, out_features=1024, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=1024, out_features=1024, bias=True)
(LayerNorm): LayerNorm((1024,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=1024, out_features=4096, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=4096, out_features=1024, bias=True)
(LayerNorm): LayerNorm((1024,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=1024, out_features=1024, bias=True)
(activation): Tanh()
)
)
Q1、cls的值和pooler的值是一样的吗?
Q2、最后的pooler层和hidden层是什么关系?
二、实验证明:
Q1、cls的值和pooler的值是一样的吗?
# Sentences we want sentence embeddings for
sentences = ["开心", "快乐", "难过", "天气", "今天会有大大的台风吗?"]
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt', max_length=200)
# for retrieval task, add an instruction to query
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
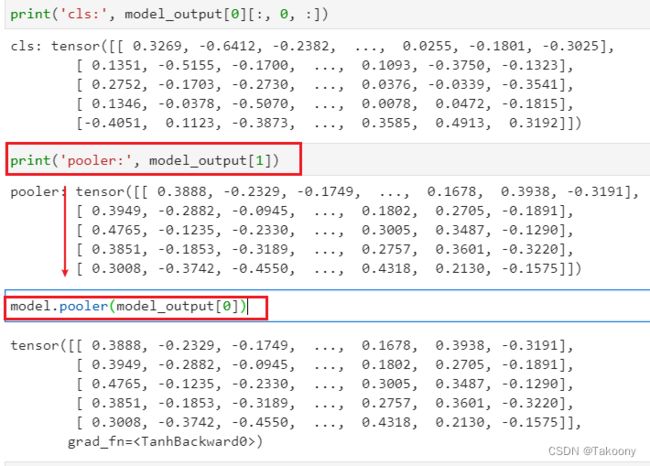
print(‘cls:’, model_output[0][:, 0, :])
cls: tensor([[ 0.3269, -0.6412, -0.2382, ..., 0.0255, -0.1801, -0.3025],
[ 0.1351, -0.5155, -0.1700, ..., 0.1093, -0.3750, -0.1323],
[ 0.2752, -0.1703, -0.2730, ..., 0.0376, -0.0339, -0.3541],
[ 0.1346, -0.0378, -0.5070, ..., 0.0078, 0.0472, -0.1815],
[-0.4051, 0.1123, -0.3873, ..., 0.3585, 0.4913, 0.3192]])
print(‘pooler:’, model_output[1])
pooler: tensor([[ 0.3888, -0.2329, -0.1749, ..., 0.1678, 0.3938, -0.3191],
[ 0.3949, -0.2882, -0.0945, ..., 0.1802, 0.2705, -0.1891],
[ 0.4765, -0.1235, -0.2330, ..., 0.3005, 0.3487, -0.1290],
[ 0.3851, -0.1853, -0.3189, ..., 0.2757, 0.3601, -0.3220],
[ 0.3008, -0.3742, -0.4550, ..., 0.4318, 0.2130, -0.1575]])
cls的值和pooler的值不一样
Q2、最后的pooler层和hidden层是什么关系?
理论层面:
transformers.models.bert.modeling_bert.BertModel.forward方法中这么一行代码:
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
pooler的定义:
self.pooler = BertPooler(config) if add_pooling_layer else None
BertPooler的定义:
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
从上面的源码可以看出,pooler_output 就是[CLS]embedding又经历了一次全连接层的输出
数据层面:
model.pooler(model_output[0])
tensor([[ 0.3888, -0.2329, -0.1749, ..., 0.1678, 0.3938, -0.3191],
[ 0.3949, -0.2882, -0.0945, ..., 0.1802, 0.2705, -0.1891],
[ 0.4765, -0.1235, -0.2330, ..., 0.3005, 0.3487, -0.1290],
[ 0.3851, -0.1853, -0.3189, ..., 0.2757, 0.3601, -0.3220],
[ 0.3008, -0.3742, -0.4550, ..., 0.4318, 0.2130, -0.1575]],
grad_fn=)
pooler_output 就是[CLS]embedding又经历了一次全连接层的输出
三、结论:
pooler就是将[CLS]这个token再过一下全连接层+Tanh激活函数,作为该句子的特征向量
四、Bert的Pooler_output的由来
我们知道,BERT的训练包含两个任务:MLM和NSP任务(Next Sentence Prediction)。 对这两个任务不熟悉的朋友可以参考:BERT源码实现与解读(Pytorch) 和 【论文阅读】BERT 两篇文章。
其中MLM就是挖空,然后让bert预测这个空是什么。做该任务是使用token embedding进行预测。
而Next Sentence Prediction就是预测bert接受的两句话是否为一对。例如:窗前明月光,疑是地上霜 为 True,窗前明月光,李白打开窗为False。
所以,NSP任务需要句子的语义信息来预测,但是我们看下源码是怎么做的。
class BertForNextSentencePrediction(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.cls = BertOnlyNSPHead(config) # 这个就是一个 nn.Linear(config.hidden_size, 2)
...
def forward(...):
...
outputs = self.bert(...)
pooled_output = outputs[1] # 取pooler_output
seq_relationship_scores = self.cls(pooled_output) # 使用pooler_ouput送给后续的全连接层进行预测
...
从上面的源码可以看出,在NSP任务训练时,并不是直接使用[CLS]token的embedding作为句子特征传给后续分类头的,而是使用的是pooler_output。个人原因可能是因为直接使用[CLS]的embedding效果不够好。
但在MLM任务时,是直接使用的是last_hidden_state,有兴趣可以看一下