编译原理期末复习
引论
计算机程序设计语言及编译
编译:将 高级语言 翻译成 汇编语言或机器语言 的过程
编译器的结构
语言及其文法
字母表上的运算
字母表 ∑ 1 \sum {}_{1} ∑1和 ∑ 2 \sum {}_{2} ∑2的乘积
{ 0 , 1 } { a , b } = { 0 a , 0 b , 1 a , 1 b } \{0, 1\}\{a, b\} = \{0a, 0b,1a,1b \} {0,1}{a,b}={0a,0b,1a,1b}
字母表 ∑ \sum ∑的n次幂
∑ 0 = { ε } \sum {}^{0} = \{ \varepsilon \} ∑0={ε}
{ 0 , 1 } 3 = { 000 , 001 , 010 , 011 , 100 , 101 , 110 , 111 } \{0, 1\}^3=\{000, 001, 010, 011, 100, 101, 110, 111\} {0,1}3={000,001,010,011,100,101,110,111}
字母表 ∑ \sum ∑的正闭包
∑ + = ∑ ∪ ∑ 2 ∪ ∑ 3 ∪ … ∑^+ = ∑ ∪ ∑^2 ∪ ∑^3 ∪ … ∑+=∑∪∑2∪∑3∪…
{ a , b , c , d } + = { a , b , c , d , a a , a b , a c , a d , b a , b b , b c , b d , … , a a a , a a b , a a c , a a d , a b a , a b b , a b c , … } \{a, b, c, d \}^+ = \{a, b, c, d, aa, ab, ac, ad, ba, bb, bc, bd, …, aaa, aab, aac, aad, aba, abb, abc, …\} {a,b,c,d}+={a,b,c,d,aa,ab,ac,ad,ba,bb,bc,bd,…,aaa,aab,aac,aad,aba,abb,abc,…}
字母表的正闭包:长度正数的符号串构成的集合
字母表 ∑ \sum ∑的克林闭包
∑ ∗ = ∑ 0 ∪ ∑ + = ∑ 0 ∪ ∑ ∪ ∑ 2 ∪ ∑ 3 ∪ … ∑^* = ∑^0 ∪ ∑^+ = ∑^0 ∪ ∑ ∪ ∑^2 ∪ ∑^3 ∪ … ∑∗=∑0∪∑+=∑0∪∑∪∑2∪∑3∪…
{ a , b , c , d } ∗ = { ε , a , b , c , d , a a , a b , a c , a d , b a , b b , b c , b d , … , a a a , a a b , a a c , a a d , a b a , a b b , a b c , … } \{a, b, c, d \}^* = \{\varepsilon,a, b, c, d, aa, ab, ac, ad, ba, bb, bc, bd, …, aaa, aab, aac, aad, aba, abb, abc, …\} {a,b,c,d}∗={ε,a,b,c,d,aa,ab,ac,ad,ba,bb,bc,bd,…,aaa,aab,aac,aad,aba,abb,abc,…}
字母表的克林闭包:任意符号串(长度可以为零)构成的集合
串
设 ∑ 是一个字母表, ∀ x ∈ ∑ ∗ \forall x \in ∑^* ∀x∈∑∗ ,x称为是∑上的一个串
串上的运算—连接
x = d o g , y = h o u s e x y = d o g h o u s e x = dog,y=house \ \ \ \ \ xy=doghouse x=dog,y=house xy=doghouse
串上的幂运算
s 0 = ε s^0 = \varepsilon s0=ε
s n = s n − 1 s s^n = s^{n-1}s sn=sn−1s
文法的定义
文法的形式化定义
G = ( V T , V N , P , S ) G = (V_T,V_N,P,S) G=(VT,VN,P,S)
V T V_T VT: 终结符集合,是文法定义的语言的基本符号,有时也称为 token
V N V_N VN: 非终结符结合,是用来表示语法成分的符号,有时也称为“语法变量”
P P P: 产生式,描述了将终结符和非终结符组合成串的方法
- 产生式的一般形式: α → β \alpha \rightarrow \beta α→β
- α ∈ ( V N ⋃ V T ) + \alpha \in (V_N \bigcup V_T )^+ α∈(VN⋃VT)+,且 α \alpha α中至少包含 V N V_N VN中的一个元素
- β ∈ ( V N ⋃ V T ) ∗ \beta \in (V_N \bigcup V_T )^* β∈(VN⋃VT)∗
S S S: 开始符号,是该文法中的最大的语法成分
产生式的简写
$a \rightarrow b_1, a \rightarrow b_2,…, a \rightarrow b_n $ 简写为: a → b 1 ∣ b 2 ∣ . . . ∣ b n a \rightarrow b_1|b_2|...|b_n a→b1∣b2∣...∣bn
b 1 , b 2 , . . . b n b_1,b_2,...b_n b1,b2,...bn是 a a a 的候选式
语言的定义
推导:
如果有产生式 α → β ∈ P α→β∈P α→β∈P,那么可以将符号串 γ α δ γαδ γαδ 中的 α α α替换为 β β β 即将 γ α δ γαδ γαδ 重写为 γ β δ γβδ γβδ,这个替换记做
γ α δ ⇒ γ β δ γαδ\Rightarrow γβδ γαδ⇒γβδ,叫做文法中的符号串 γ α δ γαδ γαδ 直接推导出 γ β δ γβδ γβδ
推导和归约

句型和句子
- 如 果 S ⇒ ∗ α , α ∈ ( V T , V N ) ∗ , 则 称 α 是 G 的 一 个 句 型 如果S\Rightarrow{}^*\alpha,\alpha \in(V_T,V_N)^*,则称\alpha是G的一个句型 如果S⇒∗α,α∈(VT,VN)∗,则称α是G的一个句型
- 一个句型中既可以包含终结符,又可以包含非终结符,也可能是空串
- 如 果 S ⇒ ∗ w , w ∈ V T ∗ , 则 称 w 是 G 的 一 个 句 型 如果S\Rightarrow{}^*w,w \in V_T^*,则称w是G的一个句型 如果S⇒∗w,w∈VT∗,则称w是G的一个句型
- 句子是不包含非终结符的句型
由文法 G 的开始符号 S 推导出的所有句子构成的集合称为文法 G 生成的语言,记为 L(G)
语言上的运算
例: 令 L = { A , B , … , Z , a , b , … } L=\{A,B,…,Z, a,b,…\} L={A,B,…,Z,a,b,…}, D = { 0 , 1 , … , 9 } D=\{0,1,…,9\} D={0,1,…,9}。则 L ( L ⋃ D ) ∗ L(L\bigcup D)^* L(L⋃D)∗表示的语言是标识符
文法的分类
- 0型文法 无限制文法: ∀ α → β ∈ P \forall \alpha \rightarrow \beta \in P ∀α→β∈P, α \alpha α 中至少包含一个非终结符
- 1型文法(CSG) 上下文有关文法: ∣ α ∣ ≤ ∣ β ∣ |\alpha| \leq |\beta| ∣α∣≤∣β∣
- 2型文法(CFG) 上下文无关文法: α ∈ V N \alpha \in V_N α∈VN
- 3型文法(RG) 正则文法: A → w B A \rightarrow wB A→wB或 A → w A \rightarrow w A→w
CFG的分析树

短语
给定一个句型,其分析树中的每一棵子树的边缘称为该句型的一个短语
- 如果子树只有父子两代结点,那么这棵子树的边缘称为该句型的一个直接短语
二义性文法
如果一个文法可以为某个句子生成多棵分析树,则称这个文法是二义性的。
词法分析
正则表达式
正则表达式的定义
ξ \xi ξ 是一个RE, L ( ξ ) = { ξ } L(\xi)=\{ \xi \} L(ξ)={ξ}
如果 a ∈ ∑ a \in \sum a∈∑,则a是一个RE, L ( a ) = { a } L(a) = \{a\} L(a)={a}
假设r和s都是RE,表示的语言分别是 L ( r ) L(r) L(r)和 L ( s ) L(s) L(s),则
- r|s是一个RE, L ( R ∣ S ) = L ( R ) ∪ L ( s ) L(R|S) = L(R)∪L(s) L(R∣S)=L(R)∪L(s)
- rs是一个RE, L ( r s ) = L ( r ) L ( s ) L(rs) = L(r)L(s) L(rs)=L(r)L(s)
- r ∗ r^* r∗是一个RE, L ( R ∗ ) = ( L ( r ) ) ∗ L(R^*)=(L(r))^* L(R∗)=(L(r))∗
- ®是一个RE, L ( ( r ) ) = L ( r ) L((r)) = L(r) L((r))=L(r)
十进制整数的RE
- ( 1 ∣ . . . ∣ 9 ) ( 0 ∣ . . . ∣ 9 ) ∗ ∣ 0 (1|...|9)(0|...|9)^*|0 (1∣...∣9)(0∣...∣9)∗∣0
正则定义
c语言中标识符的正则定义
- digit → 0|1|2|…|9
- letter_ |B|…|Z|a|b|…|z|_
有穷自动机
有穷自动机
系统只需要根据当前所处的状态和当前面临的输入信息就可以决定系统的后继行为。每当系统处理了当前的输入后,系统的内部状态也将发生改变。
转换图
结点
- 初始状态(开始状态):只有一个,由
start箭头指向 - 终止状态(接受状态):可以有多个,用双圈表示
带标记的有向边:如果对于输入a,存在一个从状态p到状态q的转换,就在p、q之间画一条有向边,并标记上a
FA定义(接受)的语言
- 给定输入串x,如果存在一个对应于串x的
从初始状态到某个终止状态的转换序列,则称串x被该FA接收 - 由一个有穷自动机M接收的所有串构成的集合称为是
该FA定义(或接收)的语言,记为 L ( M ) L(M) L(M)

最长子串匹配原则
当输入串的多个前缀与一个或多个模式匹配时,总是选择最长的前缀进匹配。
有穷自动机的分类
确定的有穷自动机(DFA)
M = ( S , ∑ , δ , s 0 , F ) M = (S,\sum,\delta,s_0,F ) M=(S,∑,δ,s0,F)
- S:有穷状态集
- ∑ \sum ∑:输入字母表,即输入符号集合
- δ \delta δ:将 S × ∑ S×\sum S×∑映射到
S的转换函数。 ∀ s ∈ S , a ∈ ∑ , δ ( s , a ) \forall s \in S,a\in \sum,\delta(s,a) ∀s∈S,a∈∑,δ(s,a)表示从状态s触发,沿着标记为a的边所能到达的状态。 - s 0 s_0 s0:开始状态(初始状态)
- F F F:接受状态(终止状态)集合

非确定的有穷自动机(NFA)
M = ( S , ∑ , δ , s 0 , F ) M = (S,\sum,\delta,s_0,F ) M=(S,∑,δ,s0,F)
- S:有穷状态集
- ∑ \sum ∑:输入字母表,即输入符号集合
- δ \delta δ:将 S × ∑ S×\sum S×∑映射到 2 S 2^S 2S 的转换函数。 ∀ s ∈ S , a ∈ ∑ , δ ( s , a ) \forall s \in S,a\in \sum,\delta(s,a) ∀s∈S,a∈∑,δ(s,a)表示从状态s触发,沿着标记为a的边所能到达的状态
集合。 - s 0 s_0 s0:开始状态(初始状态)
- F F F:接受状态(终止状态)集合

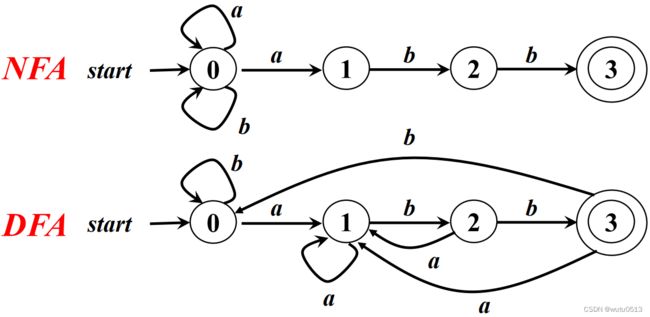
NFA和NFA的等价性
-
对任何非确定的有穷自动机N,存在定义同一语言的确定的有穷自动机D
-
对任何确定的有穷自动机D,存在定义同一语言的非确定的有穷自动机N
-
DFA和NFA可以识别相同的语言
带有 ξ \xi ξ 边的NFA
M = ( S , ∑ , δ , s 0 , F ) M = (S,\sum,\delta,s_0,F ) M=(S,∑,δ,s0,F)
- S:有穷状态集
- ∑ \sum ∑:输入字母表,即输入符号集合
- δ \delta δ:将 S × ( ∑ ∪ { ξ } ) S×(\sum∪ \{ \xi \}) S×(∑∪{ξ})映射到 2 S 2^S 2S 的转换函数。 ∀ s ∈ S , a ∈ ∑ ∪ { ξ } , δ ( s , a ) \forall s \in S,a\in \sum ∪ \{ \xi \},\delta(s,a) ∀s∈S,a∈∑∪{ξ},δ(s,a)表示从状态s触发,沿着标记为a的边所能到达的状态
集合。 - s 0 s_0 s0:开始状态(初始状态)
- F F F:接受状态(终止状态)集合

从正则表达式到有穷自动机


从NFA到DFA的转换


自顶向下
自顶向下分析概述
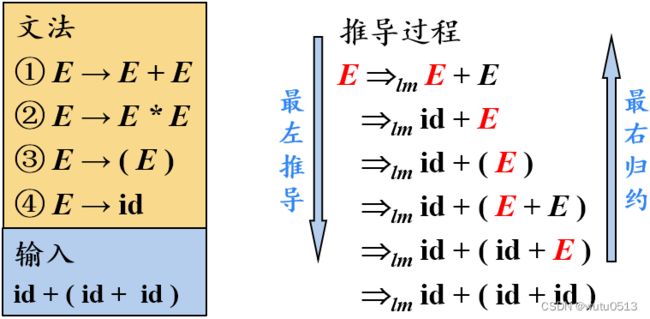
最左推导
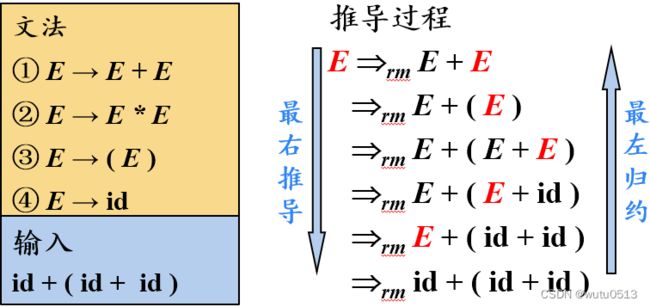
最右推导
自顶向下的语法分析采用最左推导方式
- 总是选择每个句型的
最左非终结符进行替换 - 根据输入流中的
下一个终结符,选择最左非终结符的一个候选式
文法转换
消除左递归
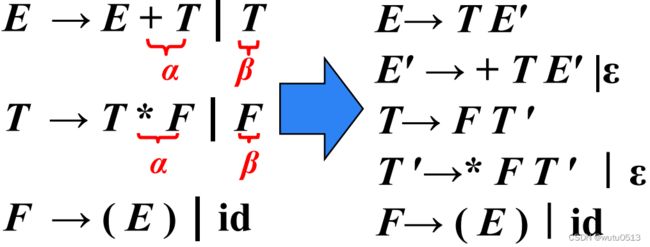

消除间接左递归
FIRST集和FOLLOW集
FIRST


FOLLOW


select


预测分析表

递归的预测分析法


非递归的预测分析法

LL1(1)文法
LL(1)文法的预测分析表项入口唯一
- 第一个“L”表示从左向右扫描输入
- 第二个“L”表示产生最左推导
- “1”表示在每一步中只需要向前看一个输入符号来决定语法分析动作
自底向上
自底向上分析概述
最左归约 反向构造最右推导
每次归约的符号串称为“句柄”,句柄是句型的最左直接短语
移入-归约分析中存在的问题:错误地识别了句柄
LR分析法
LR文法:
- L 对输入进行从左到右的扫描
- R 反向构造出一个最右推导序列
状态

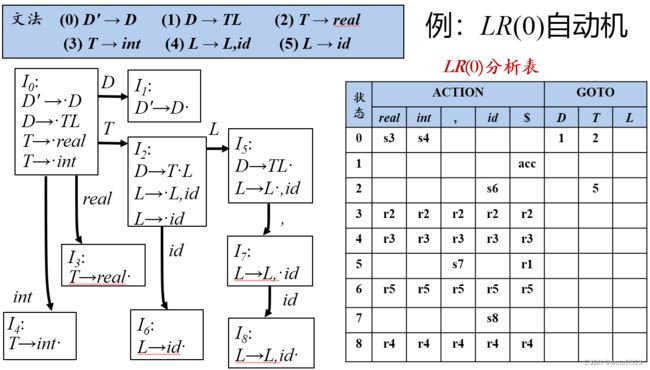
LR(0)分析
增广文法:加上新的开始符号,引入这个新的开始产生式的目的是使得文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接受状态。
LR(0)分析表

移进/归约冲突
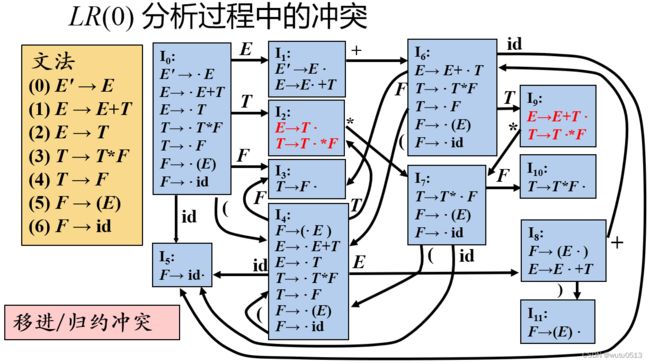
归约/归约冲突

SLR(1)分析
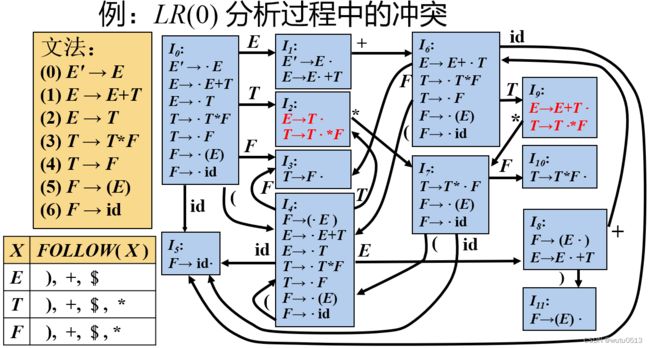



LR(1)


语法制导翻译
SDD:语法制导定义
SDT:语法制导翻译方案
终结符没有继承属性(终结符从词法分析器处获得的属性值是综合属性值)

s属性

L属性

SDT



递归

中间代码生成
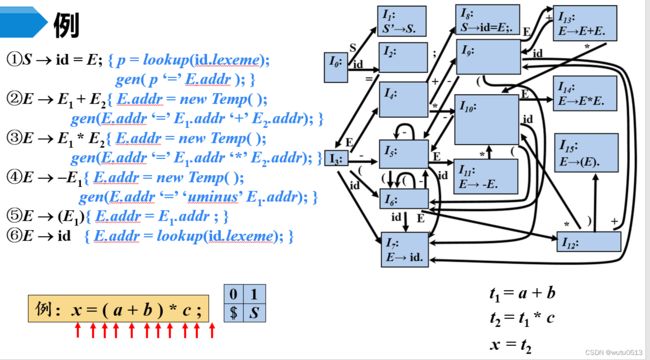
题目
用高级语言编写的程序经编译后产生的程序叫( )。
- A、源程序
- B、目标程序
- C、连接程序
- D、解释程序
答案:B
编译程序中语法分析器接收以( )为单位的输入。
- A、单词
- B、表达式
- C、产生式
- D、句子
答案:A
编译程序绝大多数时间花在( )上。
- A、词法分析
- B、目标代码生成
- C、出错处理
- D、表格管理
答案:D
文法G所产生的( )的全体,被称为该文法描述的语言
- A、句型
- B、终结符集
- C、句子
- D、非终结符集
答案:C
词法分析器用于识别( )。
- A、句子
- B、产生式
- C、单词
- D、句型
答案:C
词法分析器的加工对象是()。
- A、中间代码
- B、单词
- C、源程序
- D、元程序
答案:C
有限状态自动机能识别( )。
- A、上下文无关语言
- B、上下文有关语言
- C、正规语言
- D、0 型文法定义的语言
答案:C
( )不是DFA的成分。
- A、有穷字母表
- B、多个初始状态的集合
- C、多个终态的集合
- D、转换函数
答案:B
同正规式 ( a ∣ b ) ∗ (a|b)^* (a∣b)∗ 等价的正规式为( )。
- A、 a ∗ ∣ b ∗ a^*|b^* a∗∣b∗
- B、 ( a ∣ b ) + (a|b)^+ (a∣b)+
- C、 ( a b ) ∗ (ab)^* (ab)∗
- D、 ( a ∗ ∣ b ∗ ) + (a^*|b^*)^+ (a∗∣b∗)+
答案:D
一个正规式只能对应一个确定的有限状态自动机。
答案:✖ 可能有空
在递归下降方法中,若文法存在左递归,则会使分析过程产生( )。
- A、回溯
- B、非法调用
- C、有限次调用
- D、无限循环
答案:D
识别上下文无关语言的自动机是( )。
- A、下推自动机
- B、NFA
- C、DFA
- D、图灵机
答案:A
FOLLOW集中可以含有ε。
答案:✖
若a为终结符,则A→α·aβ为( )项目。
- A、归约
- B、移进
- C、接受
- D、待约
答案:B
LR(1) 文法都是( )。
- A、无二义性且无左递归
- B、可能有二义性但无左递归
- C、无二义性但可能是左递归
- D、可以既有二义性又有左递归
答案:C
编译程序的语法分析器必须输出的信息是( )。
- A、语法规则信息
- B、语法错误信息
- C、语法分析过程
- D、语句序列
答案:B