PVT论文Pytorch代码解读
PVT论文代码实现
论文地址:https://arxiv.org/abs/2102.12122v2
Pytorch代码地址:https://github.com/whai362/PVT
PVT结构图
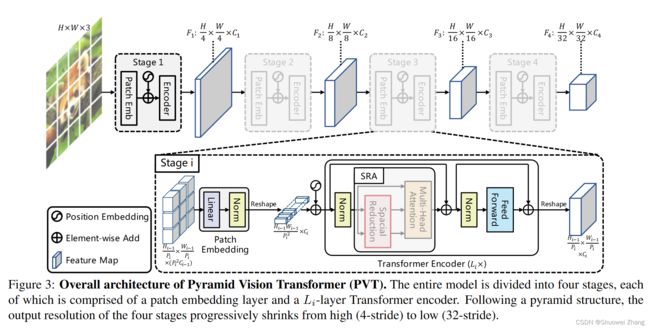
PVT有什么用
-
PVT将金字塔结构结合到了Transformer中,提高特征图的分辨率,有利于将Transformer应用到语义分割、目标检测等下游任务中。

-
提出了Spatial-Reduction Attention来替代原来的Multi-Head Attention,显著降低运算成本。

PVT结构代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
__all__ = [
'pvt_tiny', 'pvt_small', 'pvt_medium', 'pvt_large'
]
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio) # 相当于下采样
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
# B,N,T,Tc -> B,T,N,Tc
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
# B,QK,N,H,C -> ... -> QK,B,T,N,Tc
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# 把k,v拆分出来
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding 切图重排
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
# f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
# 图像切分重排 Conv2d写法
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) # 把输入图片切成多个小块
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2) # 切完之后还需要将他变成 [B,N,C]
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
num_patches = patch_embed.num_patches if i != num_stages - 1 else patch_embed.num_patches + 1
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
pos_drop = nn.Dropout(p=drop_rate)
block = nn.ModuleList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j],
norm_layer=norm_layer, sr_ratio=sr_ratios[i])
for j in range(depths[i])])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"pos_embed{i + 1}", pos_embed)
setattr(self, f"pos_drop{i + 1}", pos_drop)
setattr(self, f"block{i + 1}", block)
self.norm = norm_layer(embed_dims[3])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for i in range(num_stages):
pos_embed = getattr(self, f"pos_embed{i + 1}")
trunc_normal_(pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
# return {'pos_embed', 'cls_token'} # has pos_embed may be better
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else: # 维度不同的话,需要插值
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages): # 有几个stage就循环几次
patch_embed = getattr(self, f"patch_embed{i + 1}")
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
# patch_emded操作(切片)
x, (H, W) = patch_embed(x)
if i == self.num_stages - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
pos_embed_ = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
pos_embed = torch.cat((pos_embed[:, 0:1], pos_embed_), dim=1) # 在最后一个stage时 加cls_token
else:
# positional embedding操作
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
# 为什么只在最后一层加cls_token?
# 一个是加在前面没啥意义;
# 另一个是如果加在前面,在emb时,图片的切块和还原维度会受到影响。
x = pos_drop(x + pos_embed)
# 进Transformer Block
for blk in block:
x = blk(x, H, W)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0] # 第0列代表cls_token
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def pvt_tiny(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_small(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_medium(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_large(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_huge_v2(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[128, 256, 512, 768], num_heads=[2, 4, 8, 12], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 10, 60, 3], sr_ratios=[8, 4, 2, 1],
# drop_rate=0.0, drop_path_rate=0.02)
**kwargs)
model.default_cfg = _cfg()
return model