一篇文章 Redis 从 0 到 1
欢迎指出错误
目录
文章目录
-
-
- 目录
- Redis 简介 & 安装
-
-
- 简介
- 安装
-
- Redis 的启动、停止和连接
- Redis 配置
- Redis 的单线程+多路IO复用
-
-
- 三种 IO 概念
-
- Redis 中的五种数据类型 & 基本操作
-
-
- String
- Hash
- List(列表)
- Set
- ZSet
-
- Redis 的基本指令
- Redis 事务
-
-
- Multi、Exec、discard。Redis 事务的三条指令。
- Redis 事务中的错误
- Redis 监视
-
- Redis 的持久化
-
- RDB
-
- RDB 如果持久化?
- 修改备份规则
- 如何恢复 RDB 的备份?
- AOF
-
- AOF 的 Rewite 机制。
- 修改备份规则
- 如何恢复 AOF 的备份?
- 关于 RDB AOF & 持久化的一些建议。
- Redis 的主从复制
-
- Redis 主从复制具体操作
-
- 主从复制的的配置修改
- 启动三个 Redis
- 设置主从关系
- 主从复制之薪火相传
- 主从复制之哨兵(sentinel)模式
-
- 配置哨兵模式
- 启动 sentinel
- 哨兵原则
- 主从复制 - 复制原理
- Redis 集群
-
-
- 什么是集群?
- Redis 集群实现的原理
- 安装 ruby
- 创建集群实例
- 集群中的故障
- 解决 Redis 集群中常见的坑
-
- Redis 常见问题 & 解决方法
-
-
- 缓存穿透、缓存击穿、缓存雪崩
- 缓存和数据库双写的一致性
-
- SpringBoot2 整合 Redis
- 参考文章
-
Redis 简介 & 安装
简介
redis 是一个开源的使用ANSI C语言编写、基于内存亦可持久化的日志型、Key-Value数据库,并提供了对多种编程语言的支持。
redis 是一个高性能的 nosql 数据库,与常规的关系型数据库不同的是。MySQL 主要将数据储存在磁盘中,而 redis 将数据储存在内存中(MySQL 其实也可以将数据储存在内存中)。
redis 中没有用户的概率但是可以设置密码,通常情况下并不设置密码。因为验证过程会损耗资源。
redis 默认有 16 个库,下标为 0 - 15。可以通过配置文件修改库的数量。
redis 可以做数据的持久化
原子性,因为 redis 是单线程的。
安装
wget http://download.redis.io/releases/redis-3.2.5.tar.gz # 下载 Redis 压缩包
tar -zxvf redis-3.2.5.tar.gz # 解压压缩包
cd redis-3.2.5 # 进入解压好的文件
yum install gcc # 安装 gcc 编译工具
make && make install # 编译安装
Redis 的启动、停止和连接
# Redis 的启动依赖配置文件与 Nginx 类似
redis-server # 启动 redis-server
redis-server /xxx/redis.conf # 指定配置文件启动 redis。这两种启动模式都是前台启动,后台启动需要修改配置,见下面 Redis 配置。
redis-cli shutdown # 停止redis
redis-cli -hIP -p端口 # 连接 Redis。Redis 中没有用户的概念但是有密码的概念。
redis-cli --raw # 可以解决 redis 中文乱码问题。
Redis 配置
在已经解压的文件中你可以找到 Redis 的默认配置文件。
配置文件详解太多,你可以去百度。也可以去我的个人网站下载到本地细细品味。yundongis.me
Redis 的单线程+多路IO复用
⚠️ 在 Redis6.0 中已经支持了多线程。
三种 IO 概念
-
阻塞式 IO
你要上厕所,你敲了敲门,结果厕所里有人。于是你就啥都不做。站在门口干等着。
-
非阻塞式 IO
你要上厕所,你敲了敲门,结果厕所里有人。可是你实在是憋不住了不定的窍门。翻译成代码如下
while(true){ data = socket.read(); // 你敲门询问是否有人 if(data!= error){ // 判断是否有人 // 处理内急问题 break; } } -
单线程+多路IO复用
你要上厕所,你敲了敲门,结果厕所里有人。可是俗话说:人不能被尿憋死。于是你去找其他没人的厕所。但是你很急很急,每一步走到都会压迫膀胱,让你酸爽至极。于是你出 $100 请了一个过路人让他帮你找厕所。找到了就过来通知你。
但是还没有结束,你找到了一个很靠谱的过路人。他给了你三种找厕所的方案。分别是 select、poll、epoll
-
select
过路人帮你一个厕所一个厕所的问:“里面有没有人呀~”。但是一次只能帮你问 1024 次。
-
poll
过路人帮你一个厕所一个厕所的问:“里面有没有人呀~”。不限次数。直到问到为止。
-
epoll
好巧不巧,找的过路人刚好是全国厕所管理员。他早就预料了到了这一切,他用探测仪安满了厕所。只要有人从厕所出来。他就会收到通知然后在通知你。就像每个厕所都有独立的 ID 一样。
-
Redis 中的五种数据类型 & 基本操作
⚠️ 虽然说有五种数据类型。但是他都是以 key-value 形式储存的。这里的五种数据类型值的是 Map 中的 value 不同。如:“aaa” -> “aaa” 。“bbb” -> (“yyy” -> “xxx”)。
如果你是 Java 程序员可以理解为。
Map<"Key","java.lang.Object"> map。

String
就是普通字符串类型。一个 key 对应一个 value。String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
String 是 Redis 中最常用的数据类型。
常用于
-
缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到 redis 中,redis 作为缓存层,mysql 做持久化层,降低 mysql 的读写压力。
-
计数器:redis 是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
-
session:常见方案 spring session + redis 实现 session 共享,自定义 Token 等。
使用方法(完整使用方法见 https://www.redis.net.cn/order/)
get <key> # 查询对应键值
set <key> <value> # 添加键值对
append <key> <value> # 将给定的追加到原值的末尾
strlen <key> # 获得值的长度
setnx <key> <value> # 只有在 key 不存在时设置 key 的值。
incr <key> # 将 key 中储存的数字值增加 1,只能对数字操作。如果不存在 就会创建。一个值为 1 的数据。
decr <key> # 将 值减 1,如果不存在 ,就创建一个 -1 的数据
incrby/decrby <key> <步长> # 将 中储存的值增/减 <步长>,没有就创建。
mset <k1> <v1> <k2> <v2> # 同时设置多个键值对
mget <k1> <k2> # 同时获取一个或多个 覆写 所储存的字符串值,从 <起始位置> 开始。如果 key 不存在会创建。<起始位置> 之前数据使用 `\x00` 代替
setex <key> <过期时间> <value> # 设置键值的同时,设置过期时间,单位秒。
getset <key> <value> # 以新换旧,设置了新值同时获得旧值。(会返回旧值)
Hash
Redis hash 是一个键值对集合
Redis hash 是一个 String 类型的 field 和 value 的映射表,hash 特别适合用于储存对象
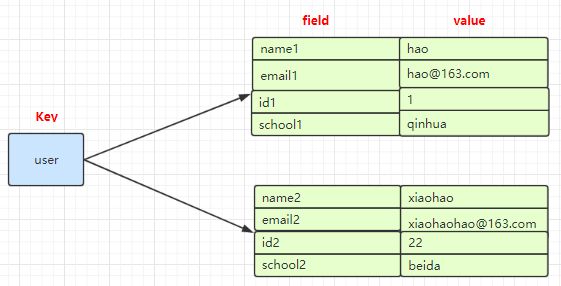
常用于
- 缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
使用方法:(完整使用方法见 https://www.redis.net.cn/order/)
所有的 hash 命令都是 h 开头的。
hset <key> <field> <value> # 给 集合中的 键赋值
hget <key> <field> # 从 集合 键取出 value。
hmset <key> <f1> <v1> <f2> <v2> # 批量设置 hash 的值。
hexists key <field> # 查看哈希 key 中,给定域 是否存在。
hkeys <key> # 列出该 hash 集合的所有的 field。
hvals <key> # 列出该 hash 集合的所有 value
hincrby <key> <field> <increment> # 为哈希表 key 中的域 field 的值加上增量 increment。
hsetnx <key> <field> <value> # 将哈希表 key 中的域 field 的值设置为 value,当且仅当域 field 不存在。
List(列表)
单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以从头部(左边)或者尾部(右边)插入数据
它的底层是个双向链表,对两端的操作性能很高。通过索引下标的操作中间节点性能会较差。
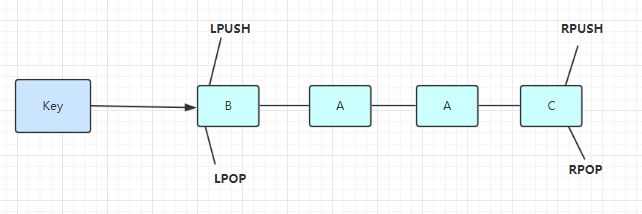
常用于
- timeline:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。
使用方法(完整使用方法见 https://www.redis.net.cn/order/)
命令都以 l 开头,如 lpush、lrange
lpush/rpush <key> <v1> <v2> # 从 左边/右边 插入一个或者多个值。
lpop/rpop <key> # 从 左边/右边 吐出一个值,如果值没有键就消毁。会返回销毁的值。
rpoplpush <k1> <k2> # 从 列表右边吐出一个值,插到 的右边
lrange <key> <起始位置> <结束位置> # 按照索引下标获得元素(从左到右)。0 至 -1 打印全部
lindex <key> <下标> # 按照下标获得元素(从左到右)
llen <key> # 获得列表长度
linsert <ket> before <value> <new value> # 在 的后面插入 。如果 存在相同值只会插入第一个查询到的(从左到右)。
lrem <key> <n> <value> # 从左边删除 个 (从左到右)。 为相同值
Set
Redis ser 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要储存一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员变量是否在一个 set 集合内的重要接口,这个也是 list 不能提供的。
Redis 的 set 是 String 类型的无序集合,它底层其实是一个 value 为 null 的 hash 表,所以添加,删除,查找的复杂度都是O(1)。
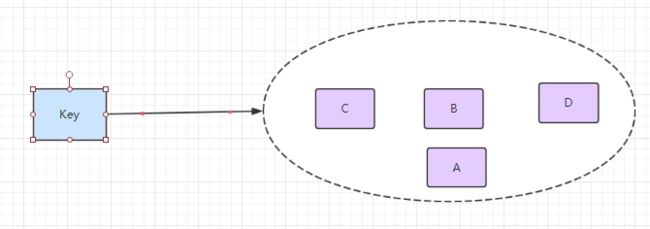
常用于
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现
- 秒杀,一个人不能重复参加秒杀活动。
基本操作(完整使用方法见 https://www.redis.net.cn/order/)
命令都是以 s 开头的 sset 、srem、scard、smembers、sismember
sadd <key> <v1> <v2> # 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 merber 元素将被忽略。会返回成功的个数
smembers <key> # 取出该集合的所有值
sismenmber <key> <value> # 判断集合 是否为含有该 值,有返回 1,没有返回0。
scard <key> # 返回该集合的元素个数
srem <key> <v1> <v2> ... # 删除 集合中的某个元素
spop <key> # 随机从该集合中吐出一个值,会移除该元素。
srandmember <key> <n> # 随机从该集合中取出 个值,不会从集合中删除。
sinter <k1> <k2> # 返回两个集合的交集元素
sunion <k1> <k2> # 返回两个集合的并集元素
sdiff <k1> <k2> # 返回两个集合的差集元素
ZSet
Redis 有序集合 zset 与普通集合 set 非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score)。这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员,集合的成员是唯一的,但是评分可以是重复的。
因为元素是有序的,所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
⚠️ (有序集合中的元素不可以重复,但是score 分数 可以重复,就和一个班里的同学学号不能重复,但考试成绩可以相同)。

常用于
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
基本使用(完整使用方法见 https://www.redis.net.cn/order/)
有序集合的命令都是 以 z 开头 zadd 、 zrange、 zscore
zadd <key> <s1> <v1> <s2> <v2>... # 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
zrange <key> <start> <stop> [WITHSCORES] # 返回有序集 key 中,下标在 之间的元素,带 WITHSCORES,可以让分数一起和值返回到结果集。
zrangbyscore <key> <min> <max> [WITHSCORES] [limit offset count] # 返回有序集 key 中,所以 score 值介于 min 和 max 之间(包括等于 min 或者 max )的成员。有序集成员按 score 值递增(从小到大)次序排序。
zrevrangebyscore <key> <max> <min> [WITHSCORES] [limit offset count] # 同上,改为从大到小排序。
zincrby <key> <increment> <value> # 为元素的 score 加上增量
zrem <key> <value> # 删除该集合下,指定 的元素
zcount <key> <min> <max> # 统计该集合,分数区间内的元素个数
zrank <key> <value> # 返回该值在集合中的排名,从 0 开始。
Redis 的基本指令
更多指令查看 http://www.redis.net.cn/order
keys * # 查看当前库的所有键
exists <key> # 判断某个键是否存在
type <key> # 查看键的类型
del <key> # 删除某个键
expire <key> <scconds> # 设置键值的过期时间,单位秒
ttl <key> # 查看还有多少秒过期,-1 表示永久不过期,-2 表示已过期
dbsize # 查看当前数据库的 key 的数量
Flushdb # 清空当前库
Flushall # 通杀全部库
Redis 事务
Redis 中的事务并不具备关系型数据库的特点。Redis 中的事务更像是将几条命令集合起来,一起操作,如果某一条数据出现问题也不会回滚。
Multi、Exec、discard。Redis 事务的三条指令。
-
Multi
说明事务开始,接下来可以编写事务内的操作。
-
Exec
提交事务。
-
discard
中断事务。
Redis 事务中的错误
-
Redis 的报告错误,会取消整个事务。
Redis 的报告错误更像是一种编译错误。例如:你将 set 写成了 sett,就会出现这个错误。
-
Redis 的执行错误。不会取消整个事务,只会在错误代码代码地方报错。
例如:
set number a命令出现了一个字符串,接下来你又使用incr number增加 1 。但是 number 并不是 数字类型。就会出现执行错误。但是!这个事务不会回滚也不会中断。只会在incr number操作中报错。然后接着继续执行。
Redis 监视
watch 命令可以对每个 key 进行监视(在 multi 之前)。如果在事务执行时与其监视时的值不一致那么事务将会被打断。(其他事务中的操作也不会执行)
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> set a a
OK
127.0.0.1:6379> set b b
OK
127.0.0.1:6379> set c c
OK
127.0.0.1:6379> WATCH b
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set a aa
QUEUED
127.0.0.1:6379> set b bb
QUEUED
127.0.0.1:6379> set c cc
QUEUED
127.0.0.1:6379> EXEC # 在执行 Exec 之前使用其他客户端将 b 修改为了 'bbb'
(nil)
127.0.0.1:6379> mget a b c
1) "a"
2) "bbb"
3) "c"
使用 unwatch 可以停止监视。当然在执行 exec discard 之后也会停止监视。
Redis 的持久化
什么是持久化?Redis 是将数据存储在内存中。就意味着只要机器断电,那么就会出现数据丢失的情况。但是Redis 同时也提供了两种持久化的方式,将数据写入磁盘中。
RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的 Snapshot 快照,它恢复时是将快照文件直接读到内存里。
RDB 如果持久化?
Redis 会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用临时文件替换上次持久化好的文件。RDB 的缺点是最后一次持久化后的数据可能丢失。
Linux 中引入了 “写时复制技术”。即当我需要写的时候,才会进行复制。避免了多进程中对效率的影响
修改备份规则
你可在 redis.conf 中修改 RDB 保存位置 & 保存策略。
当然你也可以在 redis-cli 中对 redis 执行手动保存操作。只需要输入命令
save。save命令会导致 Redis 全部阻塞,直至操作完成。
dbfilename dump.rdb # 设置备份文件名
dir ./ # 设置备份文件的保存位置
# 保存策略(条件)。
save 900 1 # 900 秒内发生 1 次修改就会触发持久化
save 300 10 # 300 秒内发生 10 次修改就会触发持久化
save 60 10000 # 60 秒内发生 10000 次修改就会触发持久化
# 回想上方 **最后一次持久化后的数据可能丢失** 。有可能出现在一次持久化后,10 秒内又进行了 10 次更改。但是不满足策略没有进行持久化。可是 Redis 异常关闭了。那么那 10 次更改就会丢失。
# ⚠️ 正常的 `shutdown` 关闭 Redis 也会触发持久化。
stop-wirtes-on-bgsave-error yes # 当 Redis 无法写入磁盘的话,直接关掉 Redis 的写操作。
rdbcompression yes # 进行 rdb 保存时,将文件压缩
rdbchecksum yes # 在储存快照后,还可以让 Redis 使用 CRC64 算法来进行数据校验,但是这样做会增加大约10% 的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
如何恢复 RDB 的备份?
只要将备份文件放到,Redis.conf 中设置的目录中备份数据会直接加载。
AOF
以日志的形式来记录每个写操作,将 Redis 执行过的所有写指令记录下来。只许追加文件但不可以改写文件(RDB 是重写原备份文件)。
AOF 的 Rewite 机制。
因为 AOF 采用了问价追加的方式记入日志,那么文件必然会越来越大。再这种情况下新增了重写机制。当 AOF 文件的大小超过所设定的阈值时,Redis 就会启动 AOF 文件的内容压缩。只保留可以恢复数据的最小指令集。当人你也可以使用
BGREWRITEAOF来开启手动压缩。
-
Redis 是怎样实现重写的?
AOF 文件持续增大时,会 fork 出一条新的进程来将遍历 Redis 库中的现有数据,将数据反编译成写操作语句记入再一个临时文件夹中。操作完成后再替换原有的 AOF 文件。
# 主要压缩了不必要的写操作。如: set a a set a aa set a aaa # 那么最后 a 的值一定为 aaa。但是 AOF 会记录三条记录。其中前两条是不必要的,冗余的。Redis 的重写也主要是将这两条数据抹去。但是不会读取原 AOF,以节省资源。 -
什么时候会重写?
当系统载入时或者上次重写完毕时,Redis 会记录此时 AOF 大小为
base_size。如果满足以下公式就会发生重写。当前大小 >= base_size. + base_size * auto-aof-rewrite-percentage。且 base_size >= auto-aof-rewrite-min-size
# Redis.conf 配置中设置。 AOF Rewrite auto-aof-rewrite-percentage 100 # 设置百分比 auto-aof-rewrite-min-size 64mb # 设置重写大小的阈值
修改备份规则
AOF 默认是不开启的。
appendonly no # 是否开启 AOF 。
appendfilename "appendonly.aof" # AOF 默认的文件名。
dir ./ # 对 RDB 和 AOF 同时生效。建议换成绝对路径
# AOF 的同步规则。
# appendfsync always # 始终同步,每次 Redis 的写入都会立刻记入日志
appendfsync everysec # 默认 每秒同步,每秒记入日志一次,如果当机。本秒的数据可能丢失
# appendfsync no # 把同步时机交给操作系统。
# AOF Rewrite,避免文件过大。
auto-aof-rewrite-percentage 100 # 设置百分比
auto-aof-rewrite-min-size 64mb # 设置重写大小的阈值
如何恢复 AOF 的备份?
和 RDB 一样,放入指定的文件夹中即可。Redis 在启动时会重新执行一边 AOF 中的写操作。
关于 RDB AOF & 持久化的一些建议。
-
RDB 更加节省空间,因为 RDB 储存的是数据而 AOF 储存的是指令。
-
RDB 的恢复速度更快。原因同上。
-
虽然 RDB 使用了 fork 。但是面对庞大数据时,还是比较消耗性能的。
-
RDB 最后一次持久化后的数据可能丢失。
前提条件。持久化规则:30 秒内进行 60 次更改就触发持久化。
有可能出现在一次持久化后,10 秒内又进行了 10 次更改。但是不满足策略没有进行持久化。可是 Redis 异常关闭了。那么那 10 次更改就会丢失。
-
如果 AOF 和 RDB 同时开启,那么 RDB 将不生效。Redis 会采用 AOF。
-
AOF 备份机制更稳健,丢失数据概率更低。
-
AOF 的备份可读,可以处理误操作。
-
AOF 开启每次读写都同步的话,有一定的性能压力。
-
如果只是保存临时数据完全可以不启用缓存。如:保存用户 Token,保存有时效的验证码。
Redis 的主从复制
-
是什么?
主从复制就是主机数据更新后根据配置和策略,自动同步到备机的 master/slaver 机制,master 以写为主,slave 以读为主
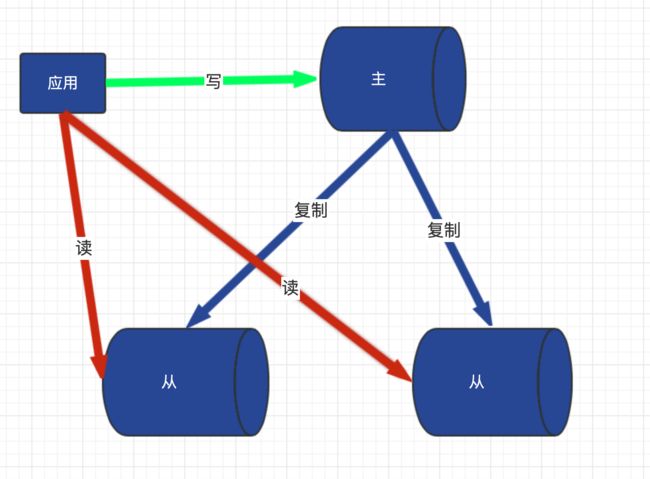
-
用途
- 读写分离,性能扩展
- 容灾快速恢复
Redis 主从复制具体操作
Redis 的理想状态下,使用 一主二仆 模式即一个主机两个从机。其中主机可以读写(一般主机只写不读),从机只能读。
主从复制的的配置修改
案例需要:三台主机,但是我手上没有,只能通过修改端口模拟了。
⚠️ 如果要外网访问需要将 redis.conf 文件中的 bind 注释掉。
⚠️ 新增的配置文件修改了的参数会覆盖原有的默认配置文件中的参数。
⚠️ 以下配置文件只是一个参考,你可以参考上方的 [Redis 配置](#Redis 配置) 编写自己的配置文件。当然三个主机的配置信息也可以不同。
⚠️ 将之前开启的 redis 服务关闭。
我新建了三个配置,其中 6379 端口为主服务器,6380、6381 端口为从服务器。
-
使用 vim 新增加配置文件
redis_6379.conf# 引入默认的 Redis.conf 配置文件。⚠️ 如果要外网访问需要将 include 引入的 redis.conf 文件中的 bind 注释掉。 include /root/redis/redis-3.2.5/redis.conf # 让外部网络可以访问到 redis。no 为关闭保护 protected-mode no # Redis 是否后台执行 daemonize yes # 设置 pid 文件。关于 pid 文件详情可以百度。 pidfile /var/run/redis_6379.pid # 设置端口 port 6379 # 指定 Log 文件保存地址 logfile "/root/redis/logs/redis_6379.log" # 设置 RDB 持久化的文件。防止名字重复 dbfilename dump_6379.rdb # 设置 RDB 文件保存地址 dir /root/redis/rdbs/ # 设置主从关系。PS:主从关系可以通过配置设置,也可以通过命令设置。为了方便演示其他功能,我采用的是命令的方式。如果你觉得命令麻烦完全可以打开这个设置,⚠️ 但是下方 ·设置主从关系· 这一步就不用执行 ·redis-cli -h xxx -p xx· 了 # slaveof 127.0.0.1 6379 # 关闭 AOF 持久化 appendonly no -
使用 vim 新增加配置文件
redis_6380.conf# 引入默认的 Redis.conf 配置文件。⚠️ 如果要外网访问需要将 redis.conf 文件中的 bind 注释掉。 include /root/redis/redis-3.2.5/redis.conf # 让外部网络可以访问到 redis。no 为关闭保护 protected-mode no # Redis 是否后台执行 daemonize yes # 设置 pid 文件。关于 pid 文件详情可以百度。 pidfile /var/run/redis_6380.pid # 设置端口 port 6380 # 指定 Log 文件保存地址 logfile "/root/redis/logs/redis_6380.log" # 设置 RDB 持久化的文件。防止名字重复 dbfilename dump_6380.rdb # 设置 RDB 文件保存地址 dir /root/redis/rdbs/ # 设置主从关系。PS:主从关系可以通过配置设置,也可以通过命令设置。为了方便演示其他功能,我采用的是命令的方式。如果你觉得命令麻烦完全可以打开这个设置,⚠️ 但是下方 ·设置主从关系· 这一步就不用执行 ·redis-cli -h xxx -p xx· 了 # slaveof 127.0.0.1 6379 # 关闭 AOF 持久化 appendonly no -
使用 vim 新增加配置文件
redis_6381.conf# 引入默认的 Redis.conf 配置文件。⚠️ 如果要外网访问需要将 redis.conf 文件中的 bind 注释掉。 include /root/redis/redis-3.2.5/redis.conf # 让外部网络可以访问到 redis。no 为关闭保护 protected-mode no # Redis 是否后台执行 daemonize yes # 设置 pid 文件。关于 pid 文件详情可以百度。 pidfile /var/run/redis_6381.pid # 设置端口 port 6381 # 指定 Log 文件保存地址 logfile "/root/redis/logs/redis_6381.log" # 设置 RDB 持久化的文件。防止名字重复 dbfilename dump_6381.rdb # 设置 RDB 文件保存地址 dir /root/redis/rdbs/ # 设置主从关系。PS:主从关系可以通过配置设置,也可以通过命令设置。为了方便演示其他功能,我采用的是命令的方式。如果你觉得命令麻烦完全可以打开这个设置,⚠️ 但是下方 ·2.设置主从关系· 这一步就不用执行 ·redis-cli -h xxx -p xx· 了 # slaveof 127.0.0.1 6379 # 关闭 AOF 持久化 appendonly no
启动三个 Redis
redis-server redis_6379.conf
redis-server redis_6380.conf
redis-server redis_6380.conf
# 使用 ps 查看是否启动成功。
ps -ef | grep redis-server # 启动成功的截图放在了下面。

如果启动失败,可以去配置中设置的 log 文件查看失败的原因。
设置主从关系
以下操作都建立在通过
redis-cli -h xxx -p xx登陆成功后。
- 查看当前 redis 的主从关系。
# 可以使用 ·info replication· 命令查看当前登陆 redis 的主从关系。
127.0.0.1:6379> info replication
# Replication
role:master # <- 这行表明了它是主服务器,未设置主从关系的 redis 默认都是主服务器。
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
- 设置主从关系
slaveof 这个命令可以让当前登陆的 redis 成为某个实例的从服务器。
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 # 设置 6379 端口的实例为当前服务的主。⚠️ 如果配置中设置了就不需要了。
OK
127.0.0.1:6381> info replication # 再次查看状态。
# Replication
role:slave # 状态已经改成 slave
master_host:127.0.0.1 # 主服务器的 IP
master_port:6379 # 主服务器的 端口
master_link_status:up # 主服务器的状态 up 为正常运行,down 为主服务停止运行。
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_repl_offset:15
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
- 查看 6379 端口主服务器的状态
127.0.0.1:6379> info replication
# Replication
role:master # 说明这是一个主服务器
connected_slaves:2 # 说明他有两个从服务器,详情如下。
slave0:ip=127.0.0.1,port=6381,state=online,offset=435,lag=1
slave1:ip=127.0.0.1,port=6380,state=online,offset=435,lag=1
master_repl_offset:435
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:434
127.0.0.1:6379>
这时,6379 端口的主服务器可以进行读写,6380、6381 端口只能进行读。同时 6379 的全部数据都会同步到 6380、6381 中。
关于主从服务器之间的说明。
- 从服务器在连接上主服务器后会拥有与主服务器同样的数据,与数据插入的时间无关
- 主服务器 down 掉后,从服务器会进入等待状态。等待主服务上线。
- 从服务器 down 掉后,主服务器就损失一个从服务器。从服务器上线后需要重新编写主从关系。
- 从机不可写数据。
主从复制之薪火相传

Redis 主从复制的薪火相传相传比较好理解。见上图你因为就明白了。就是将服务器们串行化,当主服务器 6379 宕机时。顺位的从服务器 6380 可以使用,命令 slaveof no one 放弃自己的从服务的定位,转为主服务器。
更具上图也可以得知他们的主从关系。6379 是 6380 的主服务器,6380 是 6381 的主服务器。
主从复制之哨兵(sentinel)模式
能后台监视主机是否故障,如果发生了故障根据投票数自动将从服务器转换为主服务器。哨兵模式的本质就是开启一个哨兵的服务器监视启动的 Redis 服务器。如果你细心的话可以在解压的 redis 文件中看到
sentinel.conf。里面是哨兵相关的配置。这里我就不多说了,一般使用默认即可。如果你想了解请移步 yundongis.me 。下载中文版,查看。
配置哨兵模式
哨兵模式基于 一主二仆 模式,前面我已经讲过哨兵模式 redis 已经给了默认的配置,一般情况下是不需要进行修改的。具体各个配置参数你也可以百度一下。这里我只说两样配置。
vim sentinel.conf 修改配置,我建议你先 cp 出一份备份。以防万一。
sentinel monitor mymaster 127.0.0.1 6379 2 # redis 默认配置
# ·mymaster· 是你给主服务起的名称可以随意。·127.0.0.1· 是你监视的主服务器 IP。·6379· 是主服务器端口。·2· 代表需要两台从服务器同意才可以转移主服务器,所以使用哨兵模式最好有三台从服务器。
daemonize yes # sentinel 默认是前台启动的。加上这个配置可让其后台运行。
# 偷偷告诉你 sentinel 其实就是 redis 那么有多少 redis 配置可以用在 sentinel? 你可自己试试。
启动 sentinel
redis-sentinel sentinel.conf
# 记住要指定你修改好的 sentinel.conf 。
哨兵原则
当主服务器宕机后,新主上位遵循以下规则。
-
选优先级靠前的
Redis.conf 中
slave-priority参数可以设置,优先级。数值越小优先级越高。 -
选择偏移量较大的
就是那个从服务器,连接主服务器时间较长(最先备份数据的)。
-
选择 runid 最小的从服务器。
每个 redis 实例启动后都会随机生成一个 40 位的 runid。
主服务恢复连接后,将转变为从服务器。
主从复制 - 复制原理
- 每次从机连通后,都会给主机发送 sync 指令。告诉主机,我是你的从机。麻烦把数据给我下。
- 主机收到信息后立即进行持久化操作。发送 RDB 文件给从机。
- 从机收到 RDB 文件后,进行加载。
- 之后每次主机的写操作,都会立刻发送给从机,从机执行相同命令。

Redis 集群
什么是集群?
Redis 集群实现了对 Redis 的水平扩容,即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点储存总数据的 1/N 。
Redis 集群通过分区(partition)来提供一定程度的可用性。即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
Redis 集群实现的原理
假设在 redis 集群下有三个 redis 可写实例(主服务器)。分别是 R1、R2、R3。Redis 集群要做的就是将 key 为 k1、k2、k3 的数据分别储存在 R1、R2、R3 中。首先,在安装 Redis 集群时 Redis 会将各个实例库分配好对应插槽,例如一共有 300 个插槽。 R1 对应 0 ~ 100 的插槽,R2 对应 101 ~ 200,R3 对应 201 ~ 300。 在储存 key 时使用 CRC16(key) 算法,计算 key 的值然后放入对应的插槽(实例库)。
如果你了解 Hash 算法,可以想象成是一种 Hash 的实践。可写实例对应 Hash 值,数据对应 Hash 下的链表。
安装 ruby
Redis 的集群依赖 ruby 脚本。
yum install ruby
yum install rubygems
创建集群实例
-
创建 6 个 redis.conf 配置
具体配置信息可以参考上方的主从复制。但是要新增以下三条。
# 打开集群模式 cluster-enabled yes # 设定节点配置文件。这里的节点文件会自动生成,自需要配置好路径即可。 cluster-config-file "/root/tools/redis/confs/nodes-6379.conf" # 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。 cluster-node-timeout 15000
-
启动 6 个 Redis
redis-server 6379.conf redis-server 6380.conf redis-server 6381.conf redis-server 6389.conf redis-server 6390.conf redis-server 6391.conf # 启动完成后就会生成 nodes 节点文件。路径就是你上面配置的。
-
合并 6 个节点文件
打开你解压的 redis 目录下,cd 到 src 文件夹下面。
⚠️ 执行命令之前一定保证以下三个必要条件
-
必须使用真实 IP 地址,我这里因为使用的是公有云服务器所以设置的是公网 IP 。如果你使用的内网可以使用 192.168.xx.xx 内网地址。
-
必须将 redis 端口加 10000。开放,如:
我有 6 台 redis 实例端口分别是:6379、6380、6381、6389、6390、6391。那么就要在防火墙中打开,6379、6380、6381、6389、6390、6391、16379、16380、16381、16389、16390、16391。或者直接将防火墙关闭。
-
保证各个 redis 中没有数据。如果存在数据使用。 flushall 和 cluster reset ,命令进行清除。
# 这一步其实就是将 6 个节点放到一个集群中。 # ⚠️ 一个集群至少要有三个主节点 # ⚠️ 下方 --replicas 1 参数表示。我们希望集群每个主节点都创建一个从节点 # ⚠️ 生产环境中。尽量保证每个 Redis 都运行在不同 IP 地址上 ./redis-trib.rb create --replicas 1 118.25.181.91:6379 118.25.181.91:6380 118.25.181.91:6381 118.25.181.91:6389 118.25.181.91:6390 118.25.181.91:6391如果报错可以参考下方的 [解决 Redis 集群中常见的坑](#解决 Redis 集群中常见的坑) 。
正常截图执行成功截图如下:Redis 会为集群自动创建主从复制。主从关系
-
-
集群操作命令
-
注意事项
# ⚠️ 集群中不能使用 mset mget 等。一次可以操作多条 key 的命令。因为 key 可能不再一个实例中! -
基本操作指令
# 连接 redis 集群。为可写实例(主服务器)端口。 [root@VM_0_8_centos ~] redis-cli -c -p <port> # 查看集群信息 127.0.0.1:6379> cluster nodes # 使用 {} 将 key 分配到一个集群中 127.0.0.1:6379> set k1{ks} k1 127.0.0.1:6379> set k2{ks} k2 127.0.0.1:6379> set k2{ks} k2 # 那么 k1 k2 k3 就会在一个实例中了。 # 计算 key 的插槽值 cluster keyslot <key> # 返回插槽目前包含的键值对应数量 CLUSTER COUNTKEYSINSLOT <slot> # 返回 count 个 slot 插槽中的 key CLUSTER GETKEYSINSLOT <slot> <count>
-
集群中的故障
-
如果主节点下线?从节点能否自动升为主节点?
主节点下线后,从节点会自动升级为主节点。
-
主节点恢复后,主从关系如何?
主节点下线后又上线,会转变为从服务器。
-
如果所有每一段插槽的主从节点都当掉,redis 服务是否还能继续?
如果每一段的插槽主从服务器都当掉,Redis 集群会宕机。
redis.conf 中
cluster-require-full-coverage参数可以设置是否 16384 个插槽都正常的时候才能对外提供服务。
解决 Redis 集群中常见的坑
-
执行
./redis-trib.rb出错。报错信息如下:/usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require’: cannot load such file – redis (LoadError)
from /usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require’
from /usr/local/bin/redis-trib.rb:25:in `’
解决方法:
# 使用 gem 安装 redis 库 gem install redis # ⚠️ 但是!!! 这个命令连接的库是国外的,所以执行会非常的慢!以下是修改 gem 源地址。 gem sources --remove https://rubygems.org/ # 删除默认源代码镜像 gem sources -a https://mirrors.ustc.edu.cn/rubygems/ #添加科大源 -
执行
gem install redis命令时出错。报错信息如下:Fetching: redis-4.1.2.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.3.0.解决方法
# 安装 curl [root@VM_0_8_centos ~] yum install curl # 安装RVM [root@VM_0_8_centos ~] curl -L get.rvm.io | bash -s stable -
执行
curl -L get.rvm.io | bash -s stable命令受阻。信息如下:# 执行 curl -L get.rvm.io | bash -s stable 命令时,可能会出现连接失败。不用管它,一直重试就行。
[root@VM_0_8_centos ~] curl -L get.rvm.io | bash -s stable
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 194 100 194 0 0 89 0 0:00:02 0:00:02 --:–:-- 89
100 24535 100 24535 0 0 4108 0 0:00:05 0:00:05 --:–:-- 8873
Downloading https://github.com/rvm/rvm/archive/1.29.9.tar.gz
Downloading https://github.com/rvm/rvm/releases/download/1.29.9/1.29.9.tar.gz.asc
gpg: 已创建目录‘/root/.gnupg’
gpg: 新的配置文件‘/root/.gnupg/gpg.conf’已建立
gpg: 警告:在‘/root/.gnupg/gpg.conf’里的选项于此次运行期间未被使用
gpg: 钥匙环‘/root/.gnupg/pubring.gpg’已建立
gpg: 于 2019年07月10日 星期三 16时31分02秒 CST 创建的签名,使用 RSA,钥匙号 39499BDB
gpg: 无法检查签名:没有公钥
GPG signature verification failed for ‘/usr/local/rvm/archives/rvm-1.29.9.tgz’ - ‘https://github.com/rvm/rvm/releases/download/1.29.9/1.29.9.tar.gz.asc’! Try to install GPG v2 and then fetch the public key:
gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
or if it fails:
command curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
command curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import -
In case of further problems with validation please refer to https://rvm.io/rvm/security
- 两种解决方法
```bash
# 执行命令
[root@VM_0_8_centos ~] gpg2 --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
```
或者
```bash
# 执行命令
[root@VM_0_8_centos ~] command curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
[root@VM_0_8_centos ~] command curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import -
```
```bash
# 查看配置文件
[root@VM_0_8_centos ~] find / -name rvm -print
/usr/local/rvm
/usr/local/rvm/src/rvm
/usr/local/rvm/src/rvm/bin/rvm
/usr/local/rvm/src/rvm/lib/rvm
/usr/local/rvm/src/rvm/scripts/rvm
/usr/local/rvm/bin/rvm
/usr/local/rvm/lib/rvm
/usr/local/rvm/scripts/rvm
# 激活RVM,使配置生效
[root@VM_0_8_centos ~] source /usr/local/rvm/scripts/rvm
# 下载 RVM 依赖
[root@VM_0_8_centos ~] rvm requirements
# 查看rvm库中已知的ruby版本
[root@VM_0_8_centos ~] rvm list known
# 安装 2.3.8 版的 ruby
[root@VM_0_8_centos ~] rvm install ruby-2.3.8
# 使用 2.3.8 版本
[root@VM_0_8_centos ~] rvm use 2.3.8
# 设为默认
[root@VM_0_8_centos ~] rvm use 2.3.8 --default
# 删除一个已知版本
[root@VM_0_8_centos ~] rvm remove 2.0.0
# 查看当前版本
[root@VM_0_8_centos ~] ruby -v
# ⚠️ 执行到这一步,我估计你到已经忘记自己是为了解决什么问题。让我来告诉你:
# 你该执行:
gem install redis
&&
./redis-trib.rb create --replicas 1 118.25.181.91:6379 118.25.181.91:6380 118.25.181.91:6381 118.25.181.91:6389 118.25.181.91:6390 118.25.181.91:6391
Redis 常见问题 & 解决方法
缓存穿透、缓存击穿、缓存雪崩
-
缓存穿透
-
描述
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为 “-1” 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。

-
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id <= 0 的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将 key-value 对写为 key-null ,缓存有效时间可以设置短点,如 30 秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个 id 暴力攻击
-
-
缓存击穿
-
描述:
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
-
解决方案:
- 将热点缓存失效时间设置为 -1。
-
-
缓存雪崩
-
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至 down 机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
-
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
-
缓存和数据库双写的一致性
就是一条数据更新时,先修改 redis 中的值,还是 mysql 中的值的问题。
如下三种策略你可以想想有什么不足。(如果两条请求一起来时会发生什么?)
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
终极解决办法:
-
mysql 加上监视器
-
代码串联化。
假设:A 修改了数据 D1 。那么就可以使用 D1 的 ID 当作锁。直至完成双写操作完成在解锁。
SpringBoot2 整合 Redis
https://www.jianshu.com/p/9be5d9c13bec
源码在 Github 中
参考文章
Redis(一)、Redis五种数据结构
实例解读什么是Redis缓存穿透、缓存雪崩和缓存击穿
缓存穿透、缓存击穿、缓存雪崩区别和解决方案
扩展内容
github
个人博客