【Python】自动解析markdown中的图片并保存
python自动化下载/上传md中图片实在是太方便了
1.起因
为什么需要python来下载md里面的图片?原因很简单,那就是需要把图片保存下来,上传到第二个图床(迁移)
对于阿里云OSS来说,有两种迁移办法
- 使用官方的数据导出功能
- 使用api接口遍历oss目录下载所有图片
这两种办法都不是那么方便,所以我选择了第三种
- 解析本地md文件中的img url,下载图片并保存到本地
那要怎么做呢?
2.教程
我在github找到了这个项目 Deali-Axy/Markdown-Image-Parser
作者的代码写的很棒,但是README里面却少了一个重要的启动教程,那就是你需要在当前目录下创建一个files文件夹(md文件放到这里面),对应启动项里面开启的根目录
if __name__ == '__main__':
files_list = get_files_list(os.path.abspath(os.path.join('.', 'files')))
随后,执行python spider.py,开始运行,脚本会自动将md转成html并下载图片
我将作者的代码进一步细化,并修改了一部分bug建议使用我fork的版本
https://github.com/musnows/Markdown-Image-Parser
2.1 UnicodeDecodeError
在启动的时候,你可能会遇到这个报错
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byt
解决办法参考 点我
解决办法是将打开文件编码的utf-8 修改成ISO-8859-1
with open(file, encoding='ISO-8859-1') as f:
md_content = f.read()
2.2 request failed
因为作者并没有写判断,此时就会出现一个严重问题:本地图片也会进行requests请求
比如我的md里面就有一些图片是本地的img/图片文件名,这个代码依旧对这个路径当做网络路径进行请求,于是就出现了报错
所以就需要在download_pics函数中对url进行判断,这里可以写成下面的格式(因为我知道我的阿里云OSS链接里面不包含img文件夹,所以img/的图片是本地文件
def download_pics(url, file,MDfilename):
if 'img/' in url:
print('不处理本地图片: ', url)
return
但是这样其实还是有点呆呆的,我们直接判断http在不在里面不就知道是不是网络图片了
def download_pics(url, file,MDfilename):
if 'http' not in url:
print('不处理本地图片: ', url)
return
2.3 图片保存路径
默认情况下,图片会保存到子文件夹下的markdown文件名目录
targer_dir = os.path.join(dirname,assert_dir)
if not os.path.exists(targer_dir):
os.mkdir(targer_dir)
这样其实非常非常不方便管理,有几个md文档就有几个md图片路径,可太难受了
所以我们需要注释掉这部分代码,直接选择一个根目录进行图片的保存
targer_dir ='./files/img/' # 所有图片都保存到 ./files/img/ 文件夹里面
2.4 try/except
作者代码里面的最最最大漏洞,那就是没有对for循环里面的请求进行try/except
这样就会导致,如果有一个图片请求失败,整个进程会直接终止!
那么问题就来了,即便这个程序会在遍历的时候打印当前处理的文件名字,但这需要用户去翻命令行输出,再找到到底是哪一个图片发生错误,非常非常非常难受!
如果重新执行,那就相当与把已经下好的图片又重下一遍,浪费OSS的流量。
所以我们必须要给for循环内部添加上异常捕获,如果遇到错误,就将这个图片的url存下来,继续往后执行!
for file in files_list:
print(f'正在处理:{file}')
with open(file, encoding='ISO-8859-1') as f:
md_content = f.read()
pics_list = get_pics_list(md_content)
print(f'发现图片 {len(pics_list)} 张')
for index, pic in enumerate(pics_list):
try:
print(f'正在下载第 {index + 1} 张图片...')
MDfilename = os.path.basename(file) # 当前处理的md文件的名字
download_pics(pic, file,MDfilename)
time.sleep(0.5) # 避免下载超速
except KeyboardInterrupt:
os.abort()
except:
print(traceback.format_exc())
if MDfilename not in err_img:
err_img[MDfilename]=[]
# 添加图片
err_img[MDfilename].append(pic)
print("图片获取错误:",pic)
time.sleep(1)
print(f'处理完成。')
write_file('err.json',err_img)
print(f'写入err完成')
完整代码见我的github仓库
2.5 上传到lsky图床
现在我要迁移的图床是lsky,所以为了方便,可以在将图片保存到本地的同时,将图片上传到lsky图床
注意,上传之前,请在用户组将图片上传的格式改为原始文件命名,否则重命名了那就什么都没了!

还发现了一个离谱的问题,那就是一些图片上传了之后,lsky还是会给他改名字!!!
比如这个gif,他的alt里面是原始名字,但是url并不是!!!你说这离谱不
解决方法那就是把本地的图片打一个压缩包,传到云服务器后台存储路径中覆盖一遍,把没有的图片给添加上
unzip -o ~/docker/img.zip -d ~/docker/lsky/storage/app/uploads/23/02
上传之前,先获取token
def lsky():
url = "服务器地址/api/v1/tokens"
params = {
'email':'账户邮箱',
'password':'密码'
}
res = requests.post(url, params=params) # 请求api
return res.json()
结果如下
{'status': True, 'message': 'success', 'data': {'token': '这里会返回token'}}
随后是上传的代码,注意兰空必须要用open 'rb'重新打开一边图片,所以参数给img_path也就是图片的路径即可
# 兰空图床
def lsky_upload(img_path:str):
url = "你的兰空图床服务器/api/v1/upload"
header = {
"Authorization": "Bearer 你的兰空token",
"Accept": "application/json"
}
img = open(img_path, 'rb')
params = {'strategy_id': 1}
myfiles = {'file': img}
res = requests.post(url, headers=header, params=params,
files=myfiles) # 请求api
return res.json()
在download_pics的末尾添加如下代码,并对兰空图床的返回值进行判断,如果上传错误,同样添加到错误图片中!
# 上传lsky
res = lsky_upload(img_path=f"{targer_dir}/{filename}")
print(res)
if not res['status']:
global err_img
if MDfilename not in err_img:
err_img[MDfilename]=[]
err_img[MDfilename].append(url)
print("兰空上传错误!",url)
time.sleep(1)
上传成功的返回值status是True
3.开始自动化上传
将上面的bug修改好了之后,就可以正式运行,在保存图片到本地的同时,上传到兰空图床了!

图片也都成功保存到本地了
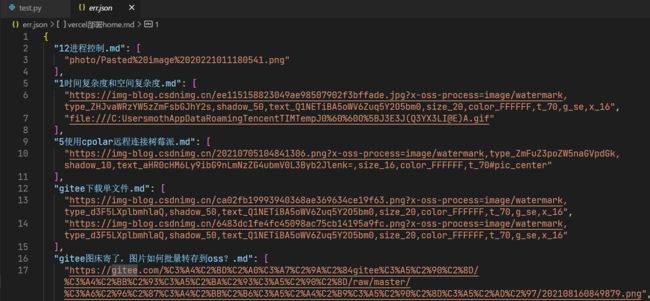
上传完毕之后,也能在err里面看到错误的图片路径,以便重新处理。
可以看到这里面有一部分是gitee和csdn的链接,这些图片有防盗链,而且图片尾部添加了其他字段,导致lsky没有办法将其识别为图片(却少图片格式后缀)
不过我的目标是将阿里云OSS的图片转到lsky,这些本来就不是阿里云OSS的图片和我的目的无关!
做完这一切,最让我感慨的是,我的阿里云oss里面有1g的图片,实际用的却只有下面这一丢丢;其他估计都是重复上传的
