ICS PA1
ICS PA1
- init.sh
- make 编译加速
- ISA
- 计算机是个状态机
- 程序是个状态机
- 准备第一个客户程序
-
- parse_args
- init_rand
- init_log
- init_mem
- init_isa
- load_img
- 剩余的初始化工作
- 运行第一个客户程序
- 调试:零
-
- 断点
- TUI
- 基础设施
-
- 单步执行
- 打印寄存器状态
- 扫描内存
- 表达式求值
-
- 词法分析
- 递归求值
- 调试: 一
- 监视点
-
- 实现监视点
- 调试二
- 如何阅读手册
-
- 统计代码行数
- 总结
init.sh
在PA0中使用下面的指令初始化了一些子项目:
$bash init.sh nemu
$bash init.sh abstract-machine
在PA1中也使用了类似的指令初始化了一个子项目,用于检查红白机模拟器的按键:
$bash init.sh am-kernels
我们观察init.sh文件:
#!/bin/bash
version=ics2021
function init() {
if [ -d $1 ]; then
echo "$1 is already initialized, skipping..."
return
fi
while [ ! -d $1 ]; do
git clone -b $version https://github.com/NJU-ProjectN/$1.git
done
log="$1 `cd $1 && git log --oneline --no-abbrev-commit -n1`"$'\n'
rm -rf $1/.git
git add -A $1
git commit -am "$1 $version initialized"$'\n\n'"$log"
if [ $2 ] ; then
sed -i -e "/^export $2=.*/d" ~/.bashrc
echo "export $2=`readlink -e $1`" >> ~/.bashrc
echo "By default this script will add environment variables into ~/.bashrc."
echo "After that, please run 'source ~/.bashrc' to let these variables take effect."
echo "If you use shell other than bash, please add these environment variables manually."
fi
}
function init_no_git() {
if [ -d $1 ]; then
echo "$1 is already initialized, skipping..."
return
fi
while [ ! -d $1 ]; do
git clone -b $version https://github.com/NJU-ProjectN/$1.git
done
log="$1 `cd $1 && git log --oneline --no-abbrev-commit -n1`"$'\n'
sed -i -e "/^\/$1/d" .gitignore
echo "/$1" >> .gitignore
git add -A .gitignore
git commit --no-verify --allow-empty -am "$1 $version initialized without tracing"$'\n\n'"$log"
}
case $1 in
nemu)
init nemu NEMU_HOME
;;
abstract-machine)
init abstract-machine AM_HOME
init_no_git fceux-am
;;
am-kernels)
init_no_git am-kernels
;;
nanos-lite)
init nanos-lite
;;
navy-apps)
init navy-apps NAVY_HOME
;;
*)
echo "Invalid input..."
exit
;;
esac
依次按下按键ggvG全选,然后输入“+y”,其中“+”为系统剪切板,y为复制
似乎需要安装vim-gui-common
以$bash init.sh am-kernels为例,即为$1,调用init_no_git am-kernels。
init_no_git am-kernels中的-d $1表示;若$1为目录则为真。当我们第一次使用该指令时,我们会从github中clone子项目,并留下git记录。
make 编译加速
- 多线程
首先通过lscpu命令查看系统中有多少个CPU,然后在运行make的时候添加一个-j?的参数,其中?为查询到的CPU数量。
liaobei@liaohaijin-vm:~/ics2021$ lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
Address sizes: 45 bits physical, 48 bits virtual
字节序: Little Endian
CPU: 6
为了查看编译加速的效果,我们可以在编译的命令前添加time命令,它将会对紧跟在其后的命令的执行时间进行统计。
- ccache
ccache是一个compiler cache。安装完成后 RTFM,先查看gcc命令的所在路径:
$which gcc
/usr/bin/gcc
RTFM可知:
To use the second method on a Debian system, it’s easiest to just prepend
/usr/lib/ccache to your PATH. /usr/lib/ccache contains symlinks for all compilers
currently installed as Debian packages.
修改~/.bashrc,在最后一行加入export PATH=/usr/lib/ccache: P A T H ,然后使用 PATH,然后使用 PATH,然后使用source ~/.bashrc指令更新PATH环境变量,此时再查看gcc命令所在的路径:
which gcc
/usr/lib/ccache/gcc
现在就可以来体验ccache的效果了,清除编译结果进行测试:
time make ARCH=native mainargs=k run
# Building amtest-run [native]
+ CC src/tests/mp.c
+ CC src/tests/intr.c
+ CC src/tests/keyboard.c
+ CC src/tests/rtc.c
+ CC src/tests/hello.c
+ CC src/tests/devscan.c
+ CC src/tests/video.c
+ CC src/tests/audio.c
+ AS src/tests/audio/audio-data.S
+ CC src/tests/vm.c
+ CC src/main.c
# Building am-archive [native]
# Building klib-archive [native]
# Creating image [native]
+ LD -> build/amtest-native
/home/liaobei/ics2021/am-kernels/tests/am-tests/build/amtest-native
Try to press any key (uart or keyboard)...
Exit code = 00h
real 0m16.190s
user 0m15.494s
sys 0m1.350s
可以对比发现第二次编译的速度有明显的提升。
ISA
ISA是软件和硬件之间的接口。
ISA的本质就是一套规范。
NEMU程序本身是x86的,准确来说是x64的,不会随着你选择的ISA而变化,变化的只是在NEMU中模拟的计算机。
在nemu/文件夹执行$make menuconfig这一步时,NEMU的框架代码会把riscv32作为默认的ISA,这里我选择的架构也是riscv32。
生存手册:
- The RISC-V Instruction Set Manual (Volume I, Volume II)
- ABI for riscv
计算机是个状态机
在每个时钟周期到来的时候,计算机根据当前时序逻辑部件(存储器,计数器,寄存器)的状态,在组合逻辑部件(加法器)的作用下,计算出并转移到下一时钟周期的新状态。
Q: 计算机可以没有寄存器吗,如果可以,这会对硬件提供的编程模型有什么影响呢?
A: 寄存器是计算机中最基本的硬件组件之一,用于存储和处理数据。在没有寄存器的情况下, 计算机无法正常工作。因此,没有寄存器的计算机是不存在的。
如果我们将问题修改为:如果没有通用寄存器,计算机还可以正常工作吗?
Q: 那么答案是肯定的。事实上,早期的计算机并没有像现代计算机一样具有通用寄存器,而是使用专用寄存器喝其他类似的组件来完成任务。例如,早期的计算机使用特定的寄存器来存储指令指针,堆栈指针、程序计数器等重要的信息。
没有通用寄存器的计算机可能会使用其他方式来处理数据,例如在内存中存储数据并使用内存地址来进行操作。这种方式可能会导致较低的性能和更复杂的编程模型,因为程序员需要手动管理内存地址,并且无法像使用寄存器那样轻松的存储和操作数据。
因此,没有通用寄存器的计算机会对硬件提供的编程模型产生重大影响,需要更复杂的程序设计和更多的手动内存管理。
程序是个状态机
程序在计算机上运行的微观视角:程序是个状态机
考虑下面一段计算1+2+…+100的指令序列:
// PC: instruction | // label: statement
0: mov r1, 0 | pc0: r1 = 0;
1: mov r2, 0 | pc1: r2 = 0;
2: addi r2, r2, 1 | pc2: r2 = r2 + 1;
3: add r1, r1, r2 | pc3: r1 = r1 + r2;
4: blt r2, 100, 2 | pc4: if (r2 < 100) goto pc2; // branch if less than
5: jmp 5 | pc5: goto pc5;
由于观察上面的代码可以知道,其实这段代码执行过程中,变化的无非就是寄存器r1,r2和pc,所以我们用一个三元组(PC,r1,r2)就可以表示程序的状态,PC表示待执行的下一条指令。初始状态是(0,x,x),此处的x表示未初始化。
(0,x,x)->(1,0,x)->(2,0,0)->(3,0,1)->(4,1,1)->(3,1,2)->(4,3,2)->…->(3,4950,100)->(4,5050,100)->(5,5050,100)
- 一个是以代码(或指令序列)为表现形式的静态视角
- 另一个是以状态机的状态转移为运行效果的动态视角
准备第一个客户程序
框架代码已经实现了最简单计算机TRM(Turing Machine)。
为了支持不同的ISA,框架代码把NEMU分成两部分:ISA无关的基本框架和ISA相关的具体实现。NEMU把ISA相关的代码放在nemu/src/isa/目录下,并通过nemu/include/isa.h提供ISA相关API的声明。这样以后,nemu/src/isa/之外的其它代码旧展示了NEMU的基本框架。
在NEMU中模拟的计算机称为“客户计算机”,在NEMU中运行的程序称为“客户程序”。
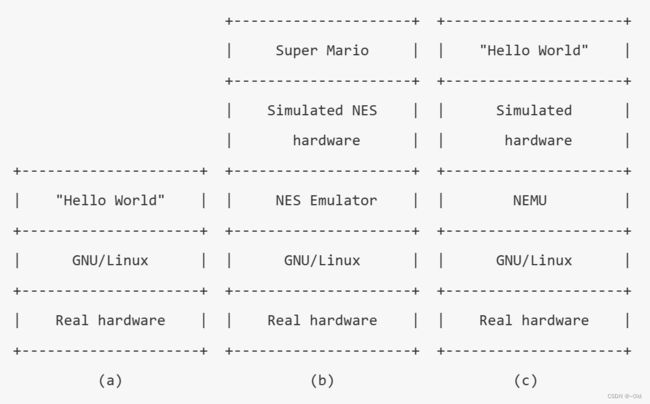
NEMU主要由4个模块构成:
- monitor
- cpu
- memory
- device
上文提到,kconfig生成了一些可以被包含到C代码中的宏定义(nemu/include/generated/autoconf.h),这些宏的名称都是形如CONFIG_xxx的形式。
为此,在nemu/include/macro.h中定义了一些专门用来对宏进行测试的宏,如IFDEF和MUXDEF.
看到这里第一次见对宏进行测试的宏,人都傻了。
另外,对三个调试有用的宏在nemu/include/debug.h中定义:
- Log()是printf的升级版,专门用来输出调试信息,同时还会输出使用Log()所在的源文件、行号和函数。当输出的调试信息过多的时候,可以很方便的定位到代码中相关的位置。
- Assert()是assert()的升级版,当测试条件为假时,在assertion fail之前可以输出一些信息
- panic()用于输出信息并结束程序,相当于无条件的assertion fail
客户程序一开始并不存在于客户计算机中,我们需要将客户程序读入到客户计算机中,这件事是monitor来负责的。于是NEMU在开始运行的时候,nemu/src/nemu-main.c中的main函数:
#include
void init_monitor(int, char *[]);
void am_init_monitor();
void engine_start();
int is_exit_status_bad();
int main(int argc, char *argv[]) {
/* Initialize the monitor. */
#ifdef CONFIG_TARGET_AM
am_init_monitor();
#else
init_monitor(argc, argv);
#endif
/* Start engine. */
engine_start();
return is_exit_status_bad();
}
首先会调用init_monitor()函数(在nemu/src/monitor/monitor.c中定义)来进行一些和monitor相关的初始化工作。
还有一个am_init_monitor函数,定义在nemu/src/monitor/monitor.c,相较于init_monitor函数简化了初始化逻辑,不知道是干嘛用的
void am_init_monitor() { init_rand(); init_mem(); init_isa(); load_img(); IFDEF(CONFIG_DEVICE, init_device()); welcome(); }通过调试反汇编可知main函数实际调用的是init_monitor函数, 因为#ifdef CONFIG_TARGET_AM为假,编译时就跳过了am_init_monitor函数,注意nemu/src/monitor/monitor.c的第22行。
init_mointor函数里面全都是函数调用,下面按照顺序进行分析:
parse_args
nemu/src/monitor/monitor.c
static int parse_args(int argc, char *argv[]) {
const struct option table[] = {
{"batch" , no_argument , NULL, 'b'},
{"log" , required_argument, NULL, 'l'},
{"diff" , required_argument, NULL, 'd'},
{"port" , required_argument, NULL, 'p'},
{"help" , no_argument , NULL, 'h'},
{0 , 0 , NULL, 0 },
};
int o;
while ( (o = getopt_long(argc, argv, "-bhl:d:p:", table, NULL)) != -1) {
switch (o) {
case 'b': sdb_set_batch_mode(); break;
case 'p': sscanf(optarg, "%d", &difftest_port); break;
case 'l': log_file = optarg; break;
case 'd': diff_so_file = optarg; break;
case 1: img_file = optarg; return optind - 1;
default:
printf("Usage: %s [OPTION...] IMAGE [args]\n\n", argv[0]);
printf("\t-b,--batch run with batch mode\n");
printf("\t-l,--log=FILE output log to FILE\n");
printf("\t-d,--diff=REF_SO run DiffTest with reference REF_SO\n");
printf("\t-p,--port=PORT run DiffTest with port PORT\n");
printf("\n");
exit(0);
}
}
return 0;
}
其中调用了getopt_long函数,通过查阅RFTM,man 3 getopt_long函数可知,需要包含getopt.h头文件。
man 3表示查阅的是库函数。
getopt_long函数签名为:
int getopt_long(int argc, char * const argv[],
const char *optstring,
const struct option *longopts, int *longindex);
其中option结构体为:
struct option {
const char *name;
int has_arg;
int *flag;
int val;
};
说白了就是执行参数的解析,比如我们在shell中执行ls -l其中-l就是命令选项,这里就是对其中的-l进行解析
init_rand
nemu/src/utils/rand.c
void init_rand() {
srand(MUXDEF(CONFIG_TARGET_AM, 0, time(0)));
}
init_log
/nemu/src/utils/log.c
void init_log(const char *log_file) {
if (log_file == NULL) return;
log_fp = fopen(log_file, "w");
Assert(log_fp, "Can not open '%s'", log_file);
}
init_mem
nemu/src/memory/paddr.c
nemu/include/memory/paddr.c
内存通过在nemu/src/memory/paddr.c中定义的大数组pmem来模拟。在客户程序运行的过程中,总是使用vaddr_read()和vaddr_write()(在nemu/memory/vaddr.c中定义)来访问模拟的内存,vaddr和paddr分别代表虚拟地址和物理地址。
init_isa
nemu/src/isa/riscv32/init.c
static void restart() {
/* Set the initial program counter. */
cpu.pc = RESET_VECTOR;
/* The zero register is always 0. */
cpu.gpr[0]._32 = 0;
}
void init_isa() {
/* Load built-in image. */
memcpy(guest_to_host(RESET_VECTOR), img, sizeof(img));
/* Initialize this virtual computer system. */
restart();
}
init_isa()有两项任务需要做:
1、第一项工作就是将一个内置的客户程序读入到内存中。
在真实的计算机系统中,计算机启动后首先会把控制权交给BIOS,BIOS经过一系列的初始化工作之后,再从磁盘中将有意义的程序读入内存中执行。
通过sudo dmesg指令可以观察启动日志观察。
我们在PA中做了简化:采取约定的方式让CPU直接从约定的内存位置开始执行。
内置客户程序就放在nemu/src/isa/riscv32/init.c中:
// this is not consistent with uint8_t
// but it is ok since we do not access the array directly
static const uint32_t img [] = {
0x800002b7, // lui t0,0x80000
0x0002a023, // sw zero,0(t0)
0x0002a503, // lw a0,0(t0)
0x0000006b, // nemu_trap
};
使用一个uint8_t类型的数组来对内存进行模拟。NEMU默认为客户计算机提供128MB的物理内存,见nemu/src/memory/paddr.c中定义的pmem:
#if defined(CONFIG_TARGET_AM)
static uint8_t *pmem = NULL;
#else
static uint8_t pmem[CONFIG_MSIZE] PG_ALIGN = {};
#endif
在nemu/include/generated/autoconf.h中定义了CONFIG_MSIZE:
#define CONFIG_MSIZE 0x8000000
我们让monitor直接把客户程序读入到一个固定的内存位置RESET_VECTOR。
guest_to_host函数定义在nemu/src/memory/paddr.c中:
uint8_t* guest_to_host(paddr_t paddr) {return pmem + paddr - CONFIG_SIZE;}
其中的类型paddr_t定义在nemu/include/common.h中:
#if CONFIG_MBASE + CONFIG_MSIZE > 0x100000000ul
#define PMEM64 1
#endif
typedef MUXDEF(PMEM64, uint64_t, uint32_t) paddr_t;
mips32和riscv32的物理地址均从0x80000000开始。因此对于mips32和riscv32,其CONFIG_MBASE将会被定义成0x80000000。将来CPU访问内存时,guest_to_host函数会将CPU要访问的内存地址映射到pmem中的相应偏移位置。
这种机制被称为地址映射
RESET_VECTOR的值在nemu/include/memory/paddr.h中定义
#define RESET_VECTOR (CONFIG_MBASE + CONFIG_PC_RESET_OFFSET)
在nemu/include/generated/autoconf.h中:
#define CONFIG_MBASE 0x8000000
#define CONFIG_PC_RESET_OFFSET 0x0
注意CONFIG_MBASE和CONFIG_MSIZE并不相同
2、init_isa()的第二项任务是初始化寄存器,这是通过restart()函数来实现的。
寄存器结构体定义在nemu/src/isa/riscv32/include/isa-def.h中:
typedef struct {
struct {
rtlreg_t _32;
} gpr[32];
vaddr_t pc;
} riscv32_CPU_state;
其中类型rtlreg_t和vaddr_t定义在nemu/include/common.h中:
typedef MUXDEF(CONFIG_ISA64, uint64_t, uint32_t) word_t;
typedef word_t rtlreg_t;
typedef word_t vaddr_t;
在nemu/src/cpu/cpu-exec.c中定义一个全局变量cpu
CPU_state cpu = {};
在include/isa.h中给类型riscv32_CPU_state一个别名,CPU_state,并使用extern关键词引用了在nemu/src/cpu/cpu-exec.c中定义的全局变量:
// The macro `__GUEST_ISA__` is defined in $(CFLAGS).
// It will be expanded as "x86" or "mips32" ...
typedef concat(__GUEST_ISA__, _CPU_state) CPU_state;
extern CPU_state_cpu;
初始化寄存器的一个重要工作就是设置cpu.pc的初值,我们需要把它设置成刚才加载客户程序的内存位置。对于mips32和riscv32,它们的0号寄存器总是存放0,因此我们也需要对其进行初始化。
load_img
nemu/src/monitor/monitor.c
static long load_img() {
if (img_file == NULL) {
Log("No image is given. Use the default build-in image.");
return 4096; // built-in image size
}
FILE *fp = fopen(img_file, "rb");
Assert(fp, "Can not open '%s'", img_file);
fseek(fp, 0, SEEK_END);
long size = ftell(fp);
Log("The image is %s, size = %ld", img_file, size);
fseek(fp, 0, SEEK_SET);
int ret = fread(guest_to_host(RESET_VECTOR), size, 1, fp);
assert(ret == 1);
fclose(fp);
return size;
}
如果运行NEMU的时候,没有给出这个参数,NEMU将会运行内置客户程序。否则将一个有意义的客户程序从镜像文件读入到内存,覆盖刚才的内置客户程序。
剩余的初始化工作
/* Initialize differential testing. */
init_difftest(diff_so_file, img_size, difftest_port);
/* Initialize devices. */
IFDEF(CONFIG_DEVICE, init_device());
/* Initialize the simple debugger. */
init_sdb();
/* Display welcome message. */
welcome();
除了welcome()函数,其余在后面实验阶段中会进行介绍。
运行第一个客户程序
Monitor的初始化工作结束后,main()函数会继续调用engine_start()函数,定义在nemu/src/engine/interpreter/init.c中:
#include
void sdb_mainloop();
void engine_start() {
#ifdef CONFIG_TARGET_AM
cpu_exec(-1);
#else
/* Receive commands from user. */
sdb_mainloop();
#endif
}
其中cpu_exec定义在nemu/src/cpu/cpu_exec.c中,sdb_mianloop定义在nemu/src/monitor/sdb/sdb.c中。我们会执行sdb_mainloop函数,即进入简易调试器(Simple Debugger)的主循环,并输出NEMU的命令提示符。
liaobei@liaohaijin-vm:~/ics2021/nemu$ make run
+ LD /home/liaobei/ics2021/nemu/build/riscv32-nemu-interpreter
/home/liaobei/ics2021/nemu/build/riscv32-nemu-interpreter --log=/home/liaobei/ics2021/nemu/build/nemu-log.txt
[src/utils/log.c:13 init_log] Log is written to /home/liaobei/ics2021/nemu/build/nemu-log.txt
[src/memory/paddr.c:36 init_mem] physical memory area [0x80000000, 0x88000000]
[src/monitor/monitor.c:39 load_img] No image is given. Use the default build-in image.
[src/monitor/monitor.c:15 welcome] Trace: OFF
[src/monitor/monitor.c:19 welcome] Build time: 15:47:19, Aug 24 2023
Welcome to riscv32-NEMU!
For help, type "help"
(nemu)
下面是sdb_mainloop函数的全貌:
void sdb_mainloop() {
if (is_batch_mode) {
cmd_c(NULL);
return;
}
for (char *str; (str = rl_gets()) != NULL; ) {
char *str_end = str + strlen(str);
/* extract the first token as the command */
char *cmd = strtok(str, " ");
if (cmd == NULL) { continue; }
/* treat the remaining string as the arguments,
* which may need further parsing
*/
char *args = cmd + strlen(cmd) + 1;
if (args >= str_end) {
args = NULL;
}
#ifdef CONFIG_DEVICE
extern void sdl_clear_event_queue();
sdl_clear_event_queue();
#endif
int i;
for (i = 0; i < NR_CMD; i ++) {
if (strcmp(cmd, cmd_table[i].name) == 0) {
if (cmd_table[i].handler(args) < 0) { return; }
break;
}
}
if (i == NR_CMD) { printf("Unknown command '%s'\n", cmd); }
}
}
is_batch_mode目前被定义为false,先跳过,然后通过rl_gets函数读取命令和参数,其中调用了readline库中的readline函数和add_history函数,接着将命令与cmd_table中的命令一 一对比并执行:
cmd_table:
static struct {
const char *name;
const char *description;
int (*handler) (char *);
} cmd_table [] = {
{ "help", "Display informations about all supported commands", cmd_help },
{ "c", "Continue the execution of the program", cmd_c },
{ "q", "Exit NEMU", cmd_q },
/* TODO: Add more commands */
{ "si", "Continue the execution in N steps, default 1",cmd_si},
{ "info", "Display the information of registers or watchpoints",cmd_info},
{ "x", "Evaluate the expression EXPR, using the result as the starting memory address, output N consecutive 4-bytes in hexadecimal",cmd_x},
{ "p", "Evaluate the expression EXPR",cmd_p},
{ "w", "Set watchpoint and program execution when the value of the expression EXPR changes",cmd_w},
{ "d", "Delete the watchpoint with sequence number n",cmd_d},
};
在命令提示符后键入c后,NEMU开始进入指令执行的主循环cpu_exec():
cpu_exec模拟了cpu的工作方式:取值、译码,执行、更新PC
/* Simulate how the CPU works. */
void cpu_exec(uint64_t n) {
g_print_step = (n < MAX_INSTR_TO_PRINT);
switch (nemu_state.state) {
case NEMU_END: case NEMU_ABORT:
printf("Program execution has ended. To restart the program, exit NEMU and run again.\n");
return;
default: nemu_state.state = NEMU_RUNNING;
}
uint64_t timer_start = get_time();
Decode s;
for (;n > 0; n --) {
fetch_decode_exec_updatepc(&s);
g_nr_guest_instr ++;
trace_and_difftest(&s, cpu.pc);
if (nemu_state.state != NEMU_RUNNING) break;
IFDEF(CONFIG_DEVICE, device_update());
}
uint64_t timer_end = get_time();
g_timer += timer_end - timer_start;
switch (nemu_state.state) {
case NEMU_RUNNING: nemu_state.state = NEMU_STOP; break;
case NEMU_END: case NEMU_ABORT:
Log("nemu: %s at pc = " FMT_WORD,
(nemu_state.state == NEMU_ABORT ? ASNI_FMT("ABORT", ASNI_FG_RED) :
(nemu_state.halt_ret == 0 ? ASNI_FMT("HIT GOOD TRAP", ASNI_FG_GREEN) :
ASNI_FMT("HIT BAD TRAP", ASNI_FG_RED))),
nemu_state.halt_pc);
// fall through
case NEMU_QUIT: statistic();
}
}
这里的nemu_state定义在nemu/include/utils.h中:
// ----------- state -----------
enum { NEMU_RUNNING, NEMU_STOP, NEMU_END, NEMU_ABORT, NEMU_QUIT };
typedef struct {
int state;
vaddr_t halt_pc;
uint32_t halt_ret;
} NEMUState;
extern NEMUState nemu_state;
而结构体类型Decode定义在nemu/include/cpu/decode.h中:
typedef struct Decode {
vaddr_t pc;
vaddr_t snpc; // static next pc
vaddr_t dnpc; // dynamic next pc
void (*EHelper)(struct Decode *);
Operand dest, src1, src2;
ISADecodeInfo isa;
IFDEF(CONFIG_DEBUG, char logbuf[80]);
} Decode;
注意在cmd_c()函数中,调用了cpu_exec(-1)传入的参数是-1,由于函数的形参定义是uint64_t,-1被解释成无符号数时候,被当成最大的无符号数,这里简单理解就是相当于死循环了,考虑到地址空间有限,里面的for循环相当于无限循环。
循环中调用fetch_decode_exec_updatepc函数,即让CPU执行当前PC指向的一条指令,然后更新PC:
static void fetch_decode_exec_updatepc(Decode *s) {
fetch_decode(s, cpu.pc);
s->EHelper(s);
cpu.pc = s->dnpc;
}
fetch_decode中调用了isa_fetch_decode函数,声明在include/isa.h中,具体实现在src/isa/riscv32/instr/decode.c中。
EHelper为Decode类型中的一个函数指针,与ISA相关,具体实现在src/isa/riscv32/instr中。后续实验中会有关于指令执行的详细说明(PA2).
此时NEMU将会运行上文提到的内置客户程序。NEMU将不断执行指令,直到遇到以下情况之一,才会退出指令执行的循环:
- 达到要求的循环次数
- 客户程序执行力nemu_trap指令。这是一条特殊的指令,在ISA手册中并不存在,它是为了在NEMU中让客户程序指示执行的结束而加入的一条认为定义的指令。为了表示客户程序是否成功结束,nemu_trap指令还会接收一个表示结束状态的参数。当客户程序执行了这条指令之后,NEMU将会根据这个结束状态参数来设置NEMU的结束状态,并根据不同的状态输出不同的结束信息,主要包括:
- HIT_GOOD_TRAP - 客户程序正确的执行
- HIT_BAD_TRAP - 客户程序错误的结束执行
- ABORT - 客户程序意外终止,并未结束执行
最终的结果如下:
(nemu) c
[src/cpu/cpu-exec.c:138 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000000c
[src/cpu/cpu-exec.c:70 statistic] host time spent = 2 us
[src/cpu/cpu-exec.c:71 statistic] total guest instructions = 4
[src/cpu/cpu-exec.c:72 statistic] simulation frequency = 2,000,000 instr/s
(nemu)
cmd_c执行完后返回值0,所以sdb_mainloop函数等待下一个命令的输入,若输入q,cmd_q返回-1,从而跳出进入简易调试器的主循环。
对于GNU/Linux上的一个程序,怎么样才算开始?怎么样才算结束?对于在NEMU中运行的程序,问题的答案又是什么呢?
与此相关的问题还有: NEMU中为什么要有nemu_trap?为什么要有monitor?
然而,如果在运行NEMU之后直接键入q退出,会发现终端输出一些错误信息:
(nemu) q
make: *** [/home/vgalaxy/ics2021/nemu/scripts/native.mk:23: run] Error 1
一开始以为是makefile的问题,定位到native.mk文件:
include $(NEMU_HOME)/scripts/git.mk
include $(NEMU_HOME)/scripts/build.mk
include $(NEMU_HOME)/tools/difftest.mk
compile_git:
$(call git_commit, "compile")
$(BINARY): compile_git
# Some convenient rules
override ARGS ?= --log=$(BUILD_DIR)/nemu-log.txt
override ARGS += $(ARGS_DIFF)
# Command to execute NEMU
IMG ?=
NEMU_EXEC := $(BINARY) $(ARGS) $(IMG)
run-env: $(BINARY) $(DIFF_REF_SO)
run: run-env
$(call git_commit, "run")
$(NEMU_EXEC)
gdb: run-env
$(call git_commit, "gdb")
gdb -s $(BINARY) --args $(NEMU_EXEC)
clean-tools = $(dir $(shell find ./tools -name "Makefile"))
$(clean-tools):
-@$(MAKE) -s -C $@ clean
clean-tools: $(clean-tools)
clean-all: clean distclean clean-tools
.PHONY: run gdb run-env clean-tools clean-all $(clean-tools)
注意这里makefile文件中的?=代表如果改变量没有被赋值,即赋予等号后的值。猜测:如果没有键入c,IMG变量就为空,所以NEMU_EXEC变量就会有问题,一开始卡在这里,也不知道如何修改,后面参考网上的解决办法,定位到cmd_q函数自身上,通过gdb调试可知,cmd_q函数返回后,控制转移到main函数,其中调用了is_exit_status_bad函数,定义在nemu/src/utils/state.c中:
只要没有键入c,键入q都会输出这样的错误信息。但是在调试的时候,不会出现这个问题。
定位相关的函数,可以知道回到键入q,退出sdb_mainloop的主循环回到main函数中:
return is_exit_status_bad();
这个is_exit_status_bad()函数如下;
int is_exit_status_bad() {
int good = (nemu_state.state == NEMU_END && nemu_state.halt_ret == 0) ||
(nemu_state.state == NEMU_QUIT);
return !good;
}
就是返回的结果就是!good,直接输入q退出,这里是返回了1,对于main函数来说返回了1意味着不对的状态,返回0才是正常状态,这里详情可以googlemain函数返回值。
由于 cmd_q 并没有改变 nemu_state.state,所以默认情况下 nemu_state.state 为 NEMU_STOP,于是 is_exit_status_bad 返回 1,就出问题了。所以我们只需要在 cmd_q 函数中添加一行 nemu_state.state = NEMU_QUIT; 即可。
调试:零
断点
这些断点的地址仅在未修改nemu/src/monitor/sdb/sdb.c的情形下有效。
-
sdb_mainloop
直接break sdb_mainloop即可
目前为0x00005555555577f0 -
cmd_c
在finish后得到
目前调用在 0x000055555555794c,跳转后地址为 0x0000555555557680 -
cpu_exec
在 sdb_mainloop 处 disas 可得到其地址
目前为 0x00005555555569a0
- fetch_decode
在 cpu_exec 处 disas 可得到其地址
目前为 0x0000555555556630
- isa_fetch_decode
在 fetch_decode 处 disas 可得到其地址
目前为 0x00005555555588b0
TUI
运行GDB后,输入layout split可以切换到TUI,详见gdb调试
为NEMU编译时添加GDB调试信息
一开始直接自己在Makefile中定义-g编译选项,后面menuconfig有相关的开启编译选项
Build Options
[*] Enable debug information
然后清除编译结果并重新编译即可,此时观察到.config文件的变化:
< # CONFIG_CC_DEBUG is not set
---
> CONFIG_CC_DEBUG=y
在nemu/查找CONFIG_CC_DEBUG:
include/config/auto.conf:23:CONFIG_CC_DEBUG=y
include/generated/autoconf.h:25:#define CONFIG_CC_DEBUG 1
Makefile:31:CFLAGS_BUILD += $(if $(CONFIG_CC_DEBUG),-ggdb3,)
通过输入make -nB观察变化,发现多了-ggdb3选项:
gcc -O2 -MMD -Wall -Werror -I/home/liaobei/ics2021/nemu/include -I/home/liaobei/ics2021/nemu/src/isa/riscv32/include -I/home/liaobei/ics2021/nemu/src/engine/interpreter -O2 -ggdb3 -fsanitize=address -DITRACE_COND=true -D__GUEST_ISA__=riscv32 -c -o /home/liaobei/ics2021/nemu/build/obj-riscv32-nemu-interpreter/src/cpu/difftest/dut.o src/cpu/difftest/dut.c
对于–ggdb3选项的作用,STFW。最显著的效果,可以发现nemu/build文件夹中多出了nemu-log.txt文件。
另外,原本所作的修改(如删除了welcome函数中的assertion fail)仍保留着(只是改变了一些宏)。
基础设施
基础设施 - 简易调试器
现在才感觉到自己对C语言一无所知
单步执行
在nemu/src/monitor/sdb/sdb.c加入:
static int cmd_si(char *args) {
int step;
if(args == NULL)
{
step = 1;
}
else
{
sscanf(args,"%d",&step);
}
cpu_exec(step);
return 0;
}
这里我使用了sscanf函数,关于这个函数的具体详细内容,建议STFW或者RTFM。
NEMU默认会把单步执行的指令打印出来,这是由nemu/src/cpu/cpu-exec.c中的debug_hook函数完成的(框架代码更新后,变为trace_and_difftest)。另外nemu/src/cpu/cpu-exec.c中的MAX_INSTR_TO_PRINT定义了最多可以打印的指令数。
打印寄存器状态
在nemu/src/monitor/sdb/sdb.c加入
static int cmd_info(char* args) {
char *arg = strtok(NULL," ");
if(arg == NULL)
{
printf("Missing parameters, Usage: info r(registers) or info w(watchpoints)\r\n");
}
else {
if(strcmp(args,"r") == 0)
{
isa_reg_display();
}
else if(strcmp(args,"w") == 0)
{
//TODO
display_watchpoint();
}
else{
printf("Usage: info r(registers) or info w(watchpoints)\r\n");
}
}
return 0;
}
这里的isa_reg_display函数定义在nemu/src/isa/riscv32/reg.c中;
#define NR_REGS ARRLEN(regs) //sizeof(regs)/sizeof(regs[0])
void isa_reg_display() {
printf("register Hexadecimal Decimal\r\n");
for(int i=0;i<32;i++)
{
printf("%-13s0x%-16x%d\r\n",regs[i],cpu.gpr[i]._32,cpu.gpr[i]._32);
}
printf("%-13s0x%-16x%d\r\n","pc",cpu.pc,cpu.pc);
}
注意这里rtlreg_t和vaddr_t都是uint32_t.
nemu/src/isa/riscv32/reg.c中还有一个isa_reg_str2val函数,后面会用到的(后面是表达式求值中含有寄存器的时候会用到)
可以尝试根据nemu_state.state打印不同的结果。
扫描内存
在nemu/src/monitor/sdb/sdb.c加入:
static int cmd_x(char *args) {
char *n = strtok(NULL," ");
char *vaddr = strtok(NULL," ");
if(n == NULL || vaddr == NULL){
printf("Usage: x N EXPR\r\n");
return 0;
}
int num;
vaddr_t addr;
sscanf(n,"%d",&num);
sscanf(vaddr,"%x",&addr);
for(int i=0;i这里仍然使用了sscanf函数来解析字符串, 实现方式不唯一,比如可以使用strtol函数。
为了方便统一,我们在针对客户程序的时候,都是使用虚拟内存这个vaddr_t相关的函数和物理内存进行区分的。
word_t vaddr_read(vaddr_t addr, int len) {
return paddr_read(addr, len);
}
其中调用了paddr_read函数,paddr_read函数调用了pmem_read函数:
uint8_t* guest_to_host(paddr_t paddr) { return pmem + paddr - CONFIG_MBASE; }
paddr_t host_to_guest(uint8_t *haddr) { return haddr - pmem + CONFIG_MBASE; }
static word_t pmem_read(paddr_t addr, int len) {
return host_read(guest_to_host(addr), len);
}
其中其中 host_read 定义在 nemu/include/memory/host.h 中:
```c
static inline word_t host_read(void *addr, int len) {
switch (len) {
case 1: return *(uint8_t *)addr;
case 2: return *(uint16_t *)addr;
case 4: return *(uint32_t *)addr;
IFDEF(CONFIG_ISA64, case 8: return *(uint64_t *)addr);
default: MUXDEF(CONFIG_RT_CHECK, assert(0), return 0);
}
}
注意这里要求以十六进制形式输出连续的 n 个 4 字节,也就是 32 位,而一个字节在内存中是 4 个单元(内存单位为 uint8_t*,即 2 位)。
表达式求值
表达式求值是一个第一次灵活运用C语言的在本实验遇到的第一个难题。
希望简易调试器能帮助我们进行一些表达式的求值,这个表达式可以带有寄存器和内存地址等内容。
词法分析
我们先来处理一种简单的情况 - 算术表达式,即待求值表达式中只允许出现以下的 token 类型:
- 十进制整数
- +, -, *, /-
- (, )
- -空格串 (一个或多个空格)
我们需要使用 regex.h(通过 man 3 regex 了解更多内容)。
首先,我们需要使用正则表达式分别编写用于识别这些 token 类型的规则。在框架代码中,一条规则是由正则表达式和 token 类型组成的二元组。这些规则会在简易调试器初始化的时候通过 init_regex() 被编译成(使用 regcomp 函数)一些用于进行 pattern 匹配的内部信息。
在 nemu/src/monitor/sdb/sdb.c 中的 init_sdb 调用了 init_regex:
void init_sdb() {
/* Compile the regular expressions. */
init_regex();
/* Initialize the watchpoint pool. */
init_wp_pool();
}
init_regex 在 nemu/src/monitor/sdb/expr.c 中。下面的代码若未特殊说明均在其中。
给出一个待求值表达式,make_token() 函数可以根据规则识别出其中的 token,并将 token 的信息依次记录到 tokens 数组中,nr_token 指示已经被识别出的 token 数目:
typedef struct token {
int type;
char str[32];
} Token;
static Token tokens[32] __attribute__((used)) = {};
static int nr_token __attribute__((used)) = 0;
Token 类型中的 str 用于记录具体的十进制整数,
下面是 make_token() 函数的实现,注意此处将空格串也记录到了 tokens 数组中(与实验指导中不太一样),还有 str 的缓冲区溢出(使用 assert(0),这体现了KISS 法则,即不要在一开始追求绝对的完美,多做单元测试):
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
nr_token = 0;
while (e[position] != '\0') {
/* Try all rules one by one. */
for (i = 0; i < NR_REGEX; i ++) {
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s",
i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
switch (rules[i].token_type) {
case TK_NOTYPE:break;
case TK_HEX:
case TK_REG:
case TK_NUM:
//tokens[nr_token].type = rules[i].token_type;
Assert((substr_len < 32),"%s","An out of buffer error occurred\r\n");
strncpy(tokens[nr_token].str,substr_start,substr_len);
tokens[nr_token].str[substr_len] = '\0';
default:
tokens[nr_token].type = rules[i].token_type;
nr_token++;
}
break;
}
}
if (i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}
这里的关键是 regexec 函数,观察下面一行:
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
对照 regexec 的函数签名为:
extern int regexec (const regex_t *_Restrict_ __preg,
const char *_Restrict_ __String, size_t __nmatch,
regmatch_t __pmatch[_Restrict_arr_
_REGEX_NELTS (__nmatch)],
int __eflags);
preg 指向编译完成后的正则表达式规则,string 为待匹配的字符串,nmatch 表示最多将几个匹配结果保存在 pmatch(数组)中。pmatch 类型为 regmatch_t,定义如下:
typedef struct
{
regoff_t rm_so; /* Byte offset from string's start to substring's start. */
regoff_t rm_eo; /* Byte offset from string's start to substring's end. */
} regmatch_t;
此处我们最多匹配一个,于是 string+pmatch.rm_so 到 string+pmatch.rm_eo 就是我们匹配的字符串。
总结来说,position 变量用来指示当前处理到的位置,并且按顺序尝试用不同的规则来匹配当前位置的字符串。当一条规则匹配成功,并且匹配出的子串正好是 position 所在位置的时候,我们就成功地识别出一个 token。Log() 宏会输出识别成功的信息。switch 语句则将 token 的信息依次记录到 tokens 数组中。
一个有趣的应用 - 语法高亮:
把源代码看作一个字符串输入到语法高亮程序中,在循环中识别出一个 token 之后,根据 token 类型用不同的颜色将它的内容重新输出一遍就可以了。如果你打算将高亮的代码输出到终端里,你可以使用 ANSI 转义码的颜色功能。
递归求值
把待求值表达式中的token都成功识别出来之后, 接下来我们就可以进行求值了. 需要注意的是, 我们现在是在对tokens数组进行处理, 为了方便叙述, 我们称它为"token表达式". 例如待求值表达式
“4 +3*(2- 1)”
根据表达式的归纳定义特性, 我们可以很方便地使用递归来进行求值. 首先我们给出算术表达式的归纳定义:
| “(”
|
|
|
|
得到 tokens 数组后,下面我们对 tokens 数组代表的字符串进行求值。我们有 expr 函数,它接受原始字符串,返回表达式的值:
word_t expr(char *e, bool *success) {
if (!make_token(e)) {
*success = false;
return 0;
}
/* TODO: Insert codes to evaluate the expression. */
// TODO();
for(int i=0;i<nr_token;i++){
if( i==0 || !(tokens[i-1].type==TK_NUM
|| tokens[i-1].type == ')'
|| tokens[i-1].type == TK_HEX
|| tokens[i-1].type == TK_REG)
)
{
switch (tokens[i].type)
{
case '*':tokens[i].type = TK_DEF;break;
case '-':tokens[i].type = TK_MINUS;break;
default:break;
}
}
}
Result res = eval(0,nr_token-1);
*success = res.is_valid;
return res.data;
}
其中的函数eval定义如下,参数代表tokens数组所代表的子表达式的下标范围[p,q):
Result eval(uint32_t p, uint32_t q)
{
Result result;
Result val1;
Result val2;
int op=p;
if(p>q)
{
result.is_valid = false;
printf("Bad expression!!!\r\n");
return result;
}
else if(p == q)
{
/*Single token
*For now this token should be a number
*Return the value of the number
*/
if(tokens[p].type == TK_NUM){
result.data = strtol(tokens[p].str,NULL,10);
result.is_valid = true;
}
else if(tokens[p].type == TK_HEX){
result.data = strtol(tokens[p].str,NULL,16);
result.is_valid = true;
}
else if(tokens[p].type == TK_REG)
{
bool success = false;
result.data = isa_reg_str2val(tokens[p].str,&success);
result.is_valid = success;
if(success == false)
{
printf("Invalid register name\r\n");
}
}
return result;
}
else if(check_parentheses(p,q) == true)
{
/* The expression is surrounded by a matched pair of parentheses.
* If that is the case, just throw away the parentheses.
*/
return eval(p+1,q-1);
}
else
{
op = find_major_op(p,q);
if(check_order(op) == INT_MAX){
result.is_valid = false;
printf("Bad expression!!!\r\n");
return result;
}
if(tokens[op].type == TK_DEF)
{
Result def_res = eval(op+1,q);
result.is_valid = def_res.is_valid;
result.data = vaddr_read(def_res.data,4);
return result;
}
else if(tokens[op].type == TK_MINUS){
Result minus_res = eval(op+1,q);
result.is_valid = minus_res.is_valid;
result.data = -1 * minus_res.data;
return result;
}
else{
val1 = eval(p,op-1);
val2 = eval(op+1,q);
if(val1.is_valid && val2.is_valid)
result.is_valid=true;
else {
result.is_valid = false;
return result;
}
switch(tokens[op].type){
case '+': result.data = val1.data + val2.data;break;
case '-': result.data = val1.data - val2.data;break;
case '*': result.data = val1.data * val2.data;break;
case '/': result.data = val1.data / val2.data;break;
case TK_AND: result.data = val1.data && val2.data;break;
case TK_OR: result.data = val1.data || val2.data;break;
case TK_EQ: result.data = val1.data == val2.data;break;
case TK_NEQ: result.data = val1.data != val2.data;break;
case TK_M: result.data = val1.data > val2.data;break;
case TK_ME: result.data = val1.data >= val2.data;break;
case TK_L: result.data = val1.data < val2.data;break;
case TK_LE: result.data = val1.data <= val2.data;break;
default: Log("Invalid Operator\r\n");break;
}
return result;
}
}
}
single token 的情形也很容易理解,代表一个十进制整数。
check_parentheses() 函数用于判断表达式是否被一对匹配的括号包围着,同时检查表达式的左右括号是否匹配,实现如下:
static bool check_parentheses(int p, int q){
int cnt=0;
if(( (tokens[p].type=='(') && (tokens[q].type == ')') ))
{
for(int i=p;i<=q;i++)
{
if(tokens[i].type == '(')
cnt++;
else if(tokens[i].type == ')')
cnt--;
if(cnt == 0)
return i==q;
}
}
return false;
}
只有括号匹配才是返回true,否则返回false.
其中check_parentheses()函数用于判断表达式是否被一对匹配的括号包围着, 同时检查表达式的左右括号是否匹配, 如果不匹配, 这个表达式肯定是不符合语法的, 也就不需要继续进行求值了. 我们举一些例子来说明check_parentheses()函数的功能:
“(2 - 1)” // true
“(4 + 3 * (2 - 1))” // true
“4 + 3 * (2 - 1)” // false, the whole expression is not surrounded by a matched
// pair of parentheses
“(4 + 3)) * ((2 - 1)” // false, bad expression
“(4 + 3) * (2 - 1)” // false, the leftmost ‘(’ and the rightmost ‘)’ are not matched
上面的框架已经考虑了BNF中算术表达式的开头两种定义, 接下来我们来考虑剩下的情况(即上述伪代码中最后一个else中的内容). 一个问题是, 给出一个最左边和最右边不同时是括号的长表达式, 我们要怎么正确地将它分裂成两个子表达式? 我们定义"主运算符"为表达式人工求值时, 最后一步进行运行的运算符, 它指示了表达式的类型(例如当一个表达式的最后一步是减法运算时, 它本质上是一个减法表达式). 要正确地对一个长表达式进行分裂, 就是要找到它的主运算符. 我们继续使用上面的例子来探讨这个问题:
“4 + 3 * ( 2 - 1 )”
/*********************/
case 1:
“+”
/ \
“4” “3 * ( 2 - 1 )”
case 2:
“*”
/ \
“4 + 3” “( 2 - 1 )”
case 3:
“-”
/ \
“4 + 3 * ( 2” “1 )”
上面列出了3种可能的分裂, 注意到我们不可能在非运算符的token处进行分裂, 否则分裂得到的结果均不是合法的表达式. 根据主运算符的定义, 我们很容易发现, 只有第一种分裂才是正确的. 这其实也符合我们人工求值的过程: 先算4和3 * ( 2 - 1 ), 最后把它们的结果相加. 第二种分裂违反了算术运算的优先级, 它会导致加法比乘法更早进行. 第三种分裂破坏了括号的平衡, 分裂得到的结果均不是合法的表达式.
通过上面这个简单的例子, 我们就可以总结出如何在一个token表达式中寻找主运算符了:
非运算符的token不是主运算符.
出现在一对括号中的token不是主运算符. 注意到这里不会出现有括号包围整个表达式的情况, 因为这种情况已经在check_parentheses()相应的if块中被处理了.
主运算符的优先级在表达式中是最低的. 这是因为主运算符是最后一步才进行的运算符.
当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符. 一个例子是1 + 2 + 3, 它的主运算符应该是右边的+.
要找出主运算符, 只需要将token表达式全部扫描一遍, 就可以按照上述方法唯一确定主运算符.
注意这里对优先级的考虑,另外当有多个运算符的优先级相同时,根据结合性,最后被结合的运算符才是主运算符。
另外,我们约定所有运算都是无符号运算,即类型 uint32_t。
目前对除 0 行为直接报错。
尚未实现带有负数的算术表达式的求值。
与编译原理的对应:
- 表达式token的识别:词法分析
- 表达式结构的分析:语法分析
- 表达式最后的求值:代码生成
调试: 一
调试公理:
- The machine is always right. (机器永远是对的)
- Corollary: If the program does not produce the desired output, it is the programmer’s fault.
- Every line of untested code is always wrong. (未测试代码永远是错的)
- Corollary: Mistakes are likely to appear in the “must-be-correct” code.
我们使用随机测试。
首先我们需要来思考如何随机生成一个合法的表达式,在 nemu/tools/gen-expr/gen-expr.c 中,我们定义了 gen_rand_expr 函数:
static void gen_rand_expr(int depth) {
if (strlen(buf) > 65536 - 10000 || depth > 15){
gen('(');
gen_rand_blank();
gen_num();
gen_rand_blank();
gen(')');
return ;
}
switch (choose(3)) {
case 0:
gen_num();
gen_rand_blank();
break;
case 1:
gen('(');
gen_rand_blank();
gen_rand_expr(depth + 1);
gen_rand_blank();
gen(')');
break;
default: {
gen_rand_expr(depth + 1);
gen_rand_blank();
gen_rand_op();
gen_rand_blank();
gen_rand_expr(depth + 1);
break;
}
}
}
这里 buf 代表生成的字符串,而 buf_index 代表目前的下标(框架代码中并没有)。
对 buf_index 进行判断是为了防止生成的表达式太长(注意将 gen_rand_expr 换成了 gen_num,防止生成的表达式不合法)。
前面的一部分是为了随机插入空格。
choose 函数接受一个参数 n,返回 1 ~ n - 1 中的一个整数。
gen_num 则使用 sprintf 生成一个非 0 的无符号整数(本来这样做是为了避免除 0 行为,然而发现还是避免不了 )。
编译得到的 gen-expr 接受一个循环次数的参数(生成表达式的个数)。
通过元编程的方式,在代码模板中嵌入随机生成的表达式,然后使用 system 和 popen 函数,执行并得到表达式求值的结果。
这样的结果通常是正确的,然而对于下面的情形:
1 / (1 / 3)
会出现除 0 行为。然而最终还是会被打印出来,就像这样:
2370368656 134767682/(( ( (1999988489)))( ((((632216280)))(636492772/1060985738)))/963486453)
总结来说,这种计算的特征是:
- 进行的都是无符号运算
- 数据宽度都是 32 bits
- 溢出后不处理
这样就可以用来生成表达式求值的测试用例了:
./gen-expr 10000 > input
将会生成 10000 个测试用例到 input 文件中,其中每行为一个测试用例,其格式为:
结果 表达式
再稍微改造一下 NEMU 的 main() 函数,让其读入 input 文件中的测试表达式后,直接调用 expr(),并与结果进行比较:
这里的 rl_gets 照搬了 nemu/src/monitor/sdb/sdb.c 中的 rl_gets。
思考编译时是如何定位到 nemu/src/monitor/sdb/expr.c 中的 expr 函数。
后来将 rl_gets 和 test_expr 转移到 nemu/src/monitor/sdb/expr.c 中。注意在 main() 函数添加 #include “monitor/sdb/sdb.h”,在 nemu/src/monitor/sdb/sdb.h 添加函数声明 void test_expr();。
监视点
扩展表达式求值
扩展功能:
- ==、!=、&&
- 十六进制常数
- 获取寄存器的值
- 指针解引用
注意有个寄存器叫 $0,并且 TK_HEX 规则在 TK_DEC 规则的前面。
功能一很容易扩展,只需要注意运算符优先级即可:
其中难点就是一个指针解引用和负号的区分。
if (!make_token(e)) {
*success = false;
return 0;
}
/* TODO: Implement code to evaluate the expression. */
for (i = 0; i < nr_token; i ++) {
if (tokens[i].type == '*' && (i == 0 || tokens[i - 1].type == certain type) ) {
tokens[i].type = DEREF;
}
}
return eval(?, ?);
其中的certain type不难思考,只有*前面不为),前面不为十进制整数,十六进制整数,不为寄存器就是解引用。
for(int i=0;i<nr_token;i++){
if( i==0 || !(tokens[i-1].type==TK_NUM
|| tokens[i-1].type == ')'
|| tokens[i-1].type == TK_HEX
|| tokens[i-1].type == TK_REG)
)
{
switch (tokens[i].type)
{
case '*':tokens[i].type = TK_DEF;break;
case '-':tokens[i].type = TK_MINUS;break;
default:break;
}
}
}
若 * 为第一个 token 或者 * 前一个 token 的类型为二元运算符(或者就是解引用,或者是左括号),那么这个 * 就是指针解引用。
上述框架也处理了负数问题
最后,别忘了在 nemu/src/monitor/sdb/sdb.c 中加入 cmd_p 函数,这样的话我们曾经编写的 test_expr 函数就光荣退役了 :
实现监视点
我们使用链表将监视点的信息组织起来。框架代码中已经定义好了监视点的结构体,在 nemu/src/monitor/sdb/watchpoint.c 中:
typedef struct watchpoint {
int NO;
struct watchpoint *next;
/* TODO: Add more members if necessary */
uint32_t val; //the watchpoint's value
char str[32]; //the watchpoint expression
} WP;
static WP wp_pool[NR_WP] = {};
static WP *head = NULL, *free_ = NULL;
void init_wp_pool() {
int i;
for (i = 0; i < NR_WP; i ++) {
wp_pool[i].NO = i;
wp_pool[i].next = (i == NR_WP - 1 ? NULL : &wp_pool[i + 1]);
}
head = NULL;
free_ = wp_pool;
}
代码中定义了监视点结构的池 wp_pool,还有两个链表 head 和 free_,其中 head 用于组织使用中的监视点结构,free_ 用于组织空闲的监视点结构,init_wp_pool() 函数会对两个链表进行初始化(在 nemu/src/monitor/sdb/sdb.c 中的 init_sdb 调用了 init_wp_pool)。
注意这里的 static 关键词,由此我们不需要显式地进行 malloc 和 free 了,所用的空间都在 wp_pool 中。
为了使用监视点池,需要编写以下两个函数:涉及的主要就是链表操作
void new_wp(char *args){
if(free_ == NULL)
{
panic("The number of watchpoints has been Max = %d\r\n",NR_WP);
}
WP* new_wp = free_;
free_ = free_->next;
new_wp->next = NULL;
//new_wp->str = args;
strcpy(new_wp->str, args);
bool success = false;
uint32_t val = expr(new_wp->str,&success);
if(success){
new_wp->val = val;
printf("Watchpoint %d: %s initial value is Decimal: %u Hexadecimal: 0x%x\r\n",new_wp->NO,new_wp->str,new_wp->val,new_wp->val);
if(head == NULL){
head = new_wp;
}
else{
new_wp->next = head; //头插
head = new_wp;
}
}
else{
printf("You set the watpoint's expression is invalid\r\n");
//free_wp(new_wp->NO);
}
}
void free_wp(int n){
if(head == NULL){
printf("Current don't have watchpoint can delete\r\n");
return;
}
WP *free_wp = NULL;
if(head->NO == n){
free_wp = head;
head = head->next;
free_wp->next = NULL;
}
else{
WP * itr = head;
while (itr->next != NULL)
{
if(itr->next->NO == n){
free_wp = itr->next;
itr->next = itr->next->next;
free_wp->next = NULL;
break;
}
itr = itr->next;
}
printf("No match the %d watchpoint\n",n);
return;
}
free_wp->next = free_;
free_ = free_wp; //头插
}
大概思路是 new_wp 函数接受一个表达式,从 free_ 链表的开头得到一个 watchpoint,并加入到 head 链表的最后;而 free_wp 函数接受一个序号,在 head 链表中查找相同序号的 watchpoint,删除后再加入到 free_ 链表中。
实现了监视点池的管理之后,我们就可以考虑如何实现监视点的相关功能了:
- 设置监视点
- 删除监视点
- 打印监视点信息
首先是打印监视点信息,我们添加一个新的函数 display_watchpoint:
void display_watchpoint(void){
WP *wp = head;
if(wp==NULL){
printf("Current don't have watchpoints\n");
}
while(wp != NULL){
printf("%d watchpoint expression: %s now value is: %u 0x%x\n",wp->NO,wp->str,wp->val,wp->val);
wp = wp->next;
}
}
在 cmd_info 相应的地方调用 display_watchpoint即可。
对于设置和删除监视点,分别调用 new_wp 函数和 free_wp 函数即可。
最后,我们需要在 trace_and_difftest() 函数 (在 nemu/src/cpu/cpu-exec.c 中定义) 的最后扫描所有的监视点,每当 cpu_exec() 的循环执行完一条指令,都会调用一次 trace_and_difftest() 函数。在扫描监视点的过程中,你需要对监视点的相应表达式进行求值 (这就是实现表达式求值的意义!),并比较它们的值有没有发生变化,若发生了变化,程序就因触发了监视点而暂停下来,你需要将 nemu_state.state 变量设置为 NEMU_STOP 来达到暂停的效果:
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {
#ifdef CONFIG_ITRACE_COND
if (ITRACE_COND) log_write("%s\n", _this->logbuf);
#endif
if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); }
IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
#ifdef CONFIG_WATCHPOINT
diff_check_wp();
#endif
}
注意此处对 NEMU_ABORT 和 NEMU_END 的特判,否则若键入 w $pc,当 trap 指令修改了 nemu_state.state 后,check_wp 返回 true 又会将 nemu_state.state 设为 NEMU_STOP,从而导致程序无法正常退出,就像下面那样:
(nemu) si
invalid opcode(PC = 0x80000010):
1c e3 d3 27 da 28 64 6c ...
27d3e31c 6c6428da...
There are two cases which will trigger this unexpected exception:
1. The instruction at PC = 0x80000010 is not implemented.
2. Something is implemented incorrectly.
Find this PC(0x80000010) in the disassembling result to distinguish which case it is.
If it is the first case, see
_ __ __ _
(_) | \/ | | |
_ __ _ ___ ___ ________ __ | \ / | __ _ _ __ _ _ __ _| |
| '__| / __|/ __|______\ \ / / | |\/| |/ _` | '_ \| | | |/ _` | |
| | | \__ \ (__ \ V / | | | | (_| | | | | |_| | (_| | |
|_| |_|___/\___| \_/ |_| |_|\__,_|_| |_|\__,_|\__,_|_|
for more details.
If it is the second case, remember:
* The machine is always right!
* Every line of untested code is always wrong!
所以应该需要判断,不只是diff_check_wp,应该修改为
if(diff_check_wp()&&nemu_state.state!=NEMU_ABORT&&nemu_state.state!=NEMU_END)
nemu_state.state=NEMU_STOP;
若在同一时刻触发两个及以上的监视点,我们会全部显示出来(为了更新监视点的值)。
另外,我们可以很容易地用监视点来模拟断点的功能:
w $pc == ADDR
其中 ADDR 为设置断点的地址。这样程序执行到 ADDR 的位置时就会暂停下来。
然而 gdb 设置断点的工作方式和上述通过监视点来模拟断点的方法大相径庭,可以阅读这篇文章。
如果把断点设置在指令的非首字节,上述通过监视点来模拟断点的方法就会失效(直接跳过),而在 gdb 中会提示下面的信息:
(gdb) continue
Continuing.
Warning:
Cannot insert breakpoint 1.
Cannot access memory at address 0x1169
Command aborted.
模拟器 (Emulator) 和调试器 (Debugger) 有什么不同?更具体地,和 NEMU 相比,GDB 到底是如何调试程序的?
调试二
在实现监视点的过程中,你很有可能会碰到段错误(目前尚未发现 )。
例如编写了 if (p = NULL) 这样的代码。但执行到这行代码的时候,也只是 p 被赋值成 NULL,程序还会往下执行。然而等到将来对 p 进行了解引用的时候,就会触发段错误。
从上面的这个例子中抽象出一些软件工程相关的概念:
- Fault: 实现错误的代码,例如 if (p = NULL)
- Error: 程序执行时不符合预期的状态,例如 p 被错误地赋值成 NULL
- Failure: 能直接观测到的错误,例如程序触发了段错误
调试其实就是从观测到的 failure 一步一步回溯寻找 fault 的过程。
调试之所以不容易,是因为:
-
fault 不一定马上触发 error
-
触发了 error 也不一定马上转变成可观测的 failure
-
error 会像滚雪球一般越积越多,当我们观测到 failure 的时候,其实已经距离 fault 非常遥远了
理解了这些原因之后,我们就可以制定相应的策略了: -
尽可能把 fault 转变成 error,方法是提高测试的覆盖度(如简化表达式求值中的随机测试)
-
尽早观测到 error 的存在,可以使用一些工具:
- -Wall, -Werror
- assert()
- printf, Log
- GDB
- sanitizer
如何阅读手册
- 学会使用目录
- 逐步细化搜索范围
下面是针对 gcc 和 riscv32 的一些练习:
- riscv32 有哪几种指令格式?
应当阅读的手册(也许)是 Unprivileged ISA,并且是 RV32I,也就是第二章。
阅读 §2.2 和 §2.3 可知,riscv32 有四种指令格式 (R/I/S/U)。若考虑立即数,S 类型衍生出 B 类型,U 类型衍生出 J 类型。
-
LUI 指令的行为是什么?
同样是阅读 Unprivileged ISA 的第二章。LUI 指令为 U 类型,将高 20 位编码的立即数左移 12 位后,装入目的寄存器。 -
mstatus 寄存器的结构是怎么样的?
阅读 Privileged ISA 的 §3.1.6,可知 mstatus 寄存器为机器状态寄存器,具体的结构 RTFM。 -
打开 nemu/scripts/build.mk 文件,你会在 CFLAGS 变量中看到 gcc 的一些编译选项。请解释 gcc 中的 -Wall 和 -Werror 有什么作用?为什么要使用 -Wall 和 -Werror?
CFLAGS := -O2 -MMD -Wall -Werror $(INCLUDES) $(CFLAGS)
man gcc可知:
-Wall
This enables all the warnings about constructions that some users consider questionable, and that are easy to avoid (or modify to prevent the warning), even in conjunction with macros. This also enables some language-specific warnings described in C++ Dialect Options and Objective-C and Objective-C++ Dialect Options.
-Wall 会开启一堆选项,以第一个 -Waddress 为例:
-Waddress
Warn about suspicious uses of memory addresses.
可以检测类似下面的错误:
- “void func(void); if (func)”
- “if (x == “abc”)”
如果想要一些额外的选项,可以使用 -Wextra。
而对于 -Werror,则直接将所有的警告都报错处理。
-Werror
Make all warnings into errors.
也可以使用 -Werror=* 的格式将特定的警告报错处理。当然也有 -Wno-error=*。
统计代码行数
- 完成 PA1 的内容之后,nemu/ 目录下的所有 .c 和 .h 和文件总共有多少行代码,除去空行呢?
先不去除空行:
find -name "*[.h|.c]" -type f | xargs cat | wc -l
“*[.h|.c]” 为正则表达式,-type f 指定目标类型为文件,xargs 则捕获 find 的输出并传递给 wc(find 本身并不支持管道命令)。
若去除空行:
find -name "*[.h|.c]" -type f | xargs cat | grep -v ^$ | wc -l
-v 表示选取不匹配的行。而 ^ 匹配开头,$ 匹配结尾,所以 ^$ 匹配一个空行。
- 和框架代码相比,你在 PA1 中编写了多少行代码?
可以把这条命令写入 Makefile 中,随着实验进度的推进,你可以很方便地统计工程的代码行数,例如敲入 make count 就会自动运行统计代码行数的命令。
总结
- PA1主要负责完善相关实验的基础设施,因为使用gdb调试客户程序时,想在客户程序s设置断点等,不是很方便。
基础设施相当于实现了一个简易的gdb调试器。 - NEMU是一个用来执行客户程序的程序,内存是被定义成一个大数组,CPU是一个结构体,模拟CPU的执行过程:取值、译码、执行、更新PC
- 表达式求值:词法分析、语法分析(分析表达式的结构)、递归求值
- PA1相当于是设置一个最简单的计算机——图灵机,只有最简单的硬件,NEMU是模拟一个最简单计算机的硬件:CPU、内存、寄存器、PC、加法器
- NEMU包括4部分:CPU、Memory、Monitor(调试器和加载客户程序)、设备
