MySql超详细分析(InnoDb存储引擎,日志文件,调优,索引,主从复制简单操作等)
MySql分析
写在前面:本文主要是自己学习的一个记录,主要还处于理论阶段。如有错误之处,欢迎指出,如侵犯了你的权利,请联系修改或删除。
借鉴:
https://www.jianshu.com/p/38fa9dc1428d
https://www.cnblogs.com/wy123/p/8365234.html
https://blog.csdn.·gdj0001/article/details/83510447
一、简述
MySQL5.5 以后默认使用InnoDB存储引擎,提供事务安全表,MySql8.0废弃了MyISAM存储引擎。建议在任何时候都不用MyISAM存储引擎。
MyISAM存储引擎:
不支持事务,不支持行级锁(支持表锁,只支持并发插入的表锁,主要用于高负荷的select),支持三种存储格式:静态表、动态表、压缩表。
静态表:表中的字段都是非变长字段,优点:存储迅速,容易缓存,出现故障容易恢复;缺点:占用空间更多。
动态表:记录长度不固定,占用空间少,缺点:频繁的更新、删除数据容易产生碎片,需要定期对表进行优化、检查、修复。
压缩表:每个记录都是单独压缩的,访问开支小
MEMORY存储引擎:
使用存在于内存中的内容创建表。(不存储数据,只处理数据)
每个memory表只实际对应一个磁盘文件,格式是.frm,该文件只存储标的结构,而其数据文件,都是存储在内存中,有利于数据的快速处理,提高整个表的处理能力。
memory数据放在内存中,但是一旦服务关闭,表的数据就会丢失。
memory存储引擎默认使用哈希索引,其速度比B+(-)Tree更快
二、InnoDB存储引擎
1. MySQL存储引擎与InnoDB体系架构介绍
提供具有提交、回滚和崩溃恢复能力的事务安全,支持行级锁,使用了B+Tree索引、支持自动增长列、支持外键
对比MyISAM引擎,写的处理效率差一些,并且会占用更多磁盘空间保留数据和索引。
1.1 InnoDB 体系架构
内存管理子系统功能分布:

mysql线程分类:

不仅缓存索引数据,还缓存表的数据,完全按照数据文件中的数据块结构信息来缓存,和Oracle SGA中的database buffer cache类似。
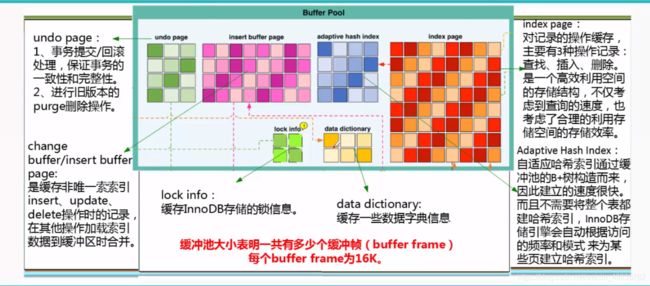
2.Additional Memory Pool
其参数innodb_additional_mem_pool_size是InnoDB用来保存数据字典信息和其他内部数据结构的内存池的大小,单位byte,默认值8M,数据库中表越多,参数值应该越大。如果InnoDB用完了内存池中的内存,就会从操作系统中分配内存,同时在error log中打入报警信息。这个参数以后会被弃用。
3.redo log buffer(mysql怎么写重做日志)
重做日志信息
redo log info --> redo log buffer --> 重做日志文件
innodb_log_buffer_size的大小:默认8M
将重做日志缓存中的内容刷新到外部磁盘的重做日志文件中的3种情况:
1.Master Tread每一秒将重做日志缓冲刷新到重做日志文件
2.每个事务提交时会将重做日志缓冲刷新重做日志文件
3.当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
和Oracle对比:每3秒,用户提交,大于1M空间的,剩余1/3空间。
二进制日志缓冲区(Binlog Buffer)
主要用来缓存由于各种数据变更操作所产生的Binary Log信息,为了提高系统的性能,MySQL并不是每次都是将二进制日志直接写入Log File,而是先将信息写入Binlog Buffer中,当满足某些特定条件之后再一次写入Log File文件中。
二进制日志和重做日志对比:
类别区分:
二进制日志:记录Mysql数据库相关的日志记录,包括InnoDB,MyISAM等其他存储引擎日志
重做日志:只记录InnoDB存储引擎本身的事务日志
内容区分:重做日志更安全
二进制日志记录:记录事务的具体操作内容,是逻辑日志
重做日志:记录每个页的更改的物理情况
时间区分:
二进制日志:只在事务提交完成后进行写入。只写磁盘一次,不论事务量有多大。存在效率问题
重做日志:在事务的进行中,就不断有重做日志条目(redo entry)写入重做日志文件
4. Double Write
是InnoDB表空间ibdata中一块连续的128page=2M的存储空间,他的作用是处理产生partial write时候的data recovery
比如:发生了极端情况,断电,InnoDB再次启动后,发现一个page数据损坏,就可以从doublewrite buffer中进行数据恢复
它的主要工作原理︰
dirty page刷新到数据文件之前,先刷到double write buffer里。
然后将page内容刷新到数据文件中。
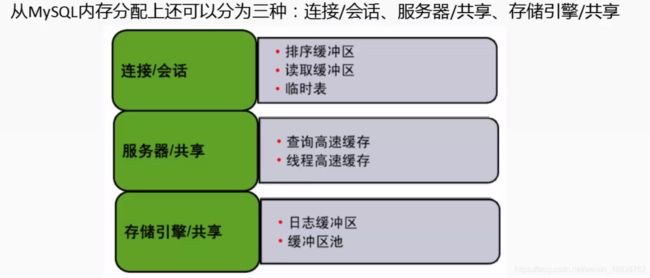
1.3 从MySQL内存分配上还可以分为三种
连接/会话、服务器/共享、存储引擎/共享
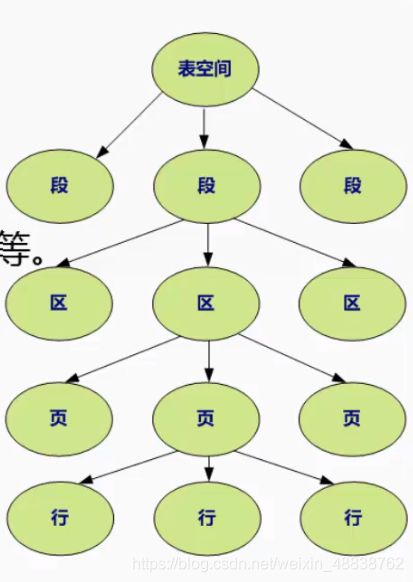
1.4 InnoDB存储引擎-逻辑存储结构
Oracle是表空间、段、区、块
MySQL是表空间、段、区、页
表空间∶所有的数据都放在表空间里面。
段︰表空间有若干各段组成,常见的有数据段/索引段/回滚段等。
区:每64个连续的页组成区,因此区大小正好为1M。
页∶页是InnoDB磁盘管理的最小单位,固定大小为16K。
行:InnoDB表中数据按行存储。
表空间︰
所有数据都是存放在表空间中的,启用了参数innodb_file_per_table(打开这个参数只是把数据独立出来了,其他信息放在共享表空间),则每张表内的数据可以单独放到一个表空间中,每张表空间内存放的只是数据,索引和插入缓冲,其他类的数据,如undo信息,系统事务信息,二次写缓冲等还是存放在原来你的共享表空间。
段(segment) :
常见的segment有数据段、索引段、回滚段。innodb是索引聚集表,所以数据就是索引,索引就是数据,那么数据段即是B+树的页节点(leaf node segment),索引段即为B+树的非索引节点(non-leaf node segment),而且段的管理是由引擎本身完成的。
区(extepd)
区是由64个连续的页组成,每个页大小为16K,即每个区的大小为(64*16K)=1MB,对于大的数据段,mysql每次最多可以申请4个区,以此保证数据的顺序性能。
页(page)
页是innodb磁盘管理最小的单位,innodb每个页的大小是16K,且不可更改。常见的类型有∶
数据页B-tree Node ;
undo页Undo Log Page ;
系统页System Page ;
事务数据页Transaction system Page ;
插入缓冲位图页lnsert Buffer Bitmap ;
插入缓冲空闲列表页Insert Buffer freeBitmap ;
未压缩的二进制大对象页Uncompressed BLOB Page ;压缩的二进制大对象页Compressed BLOB Page
行:
innodb存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存放。每个页最多可以存放16K/2 ~200行,也就是7992个行。
2. InnoDB存储引擎的常用参数配置(重点)
设置innodb存储引擎方法:在my.cnf加入:default_storage_engine=innodb
查看innodb存储引擎:show variables like 'default_storage_engine'
查看innodb的参数:show variables like '%innodb%'
1.innodb_buffer_pool_size
查看 innodb_buffer_pool_size大小:show variables like 'innodb_buffer_pool_size'
用于innodb数据和索引的缓存,默认128M,innodb最重要的性能参数。
建议值:不超过物理内存的80%(如果数据量小,可以是数据量+10%,数据量20G,物理内存是32G,这时候可以设置buffer pool为22G。将数据全部放入内存,访问更快,条件允许越大越好)
设置innodb_buffer_pool_size大小方法:在my.cnf加入:innodb_buffer_pool_size=512M (20G)重启mysql生效。
2.innodb_log_buffer_size (日志缓冲区)
查看 innodb_log_buffer_size大小show variables like 'innodb_log_buffer_size'
默认16M,已经非常够用了,大事务可以设置大一点
3.innodb_log_file_size(指定重做日志文件大小,日志文件功能数据库挂了之后的恢复操作)
show variables like 'innodb_log_file_size' ;
5.5版本最大可到4G;5.6以后最大512G
小业务256M够了,中型业务一般保持在2G左右,
设置方法:在my. cnf加入:innodb_log_file_size=256M重启mysql生效。
4.innodb_flush_log_at_trx_commit(控制事务的提交方式,控制日志刷新到硬盘的方式)
show variables like 'innodb_flush_log_at_trx_commit'
有3个值:0,1,2默认是1 通常来说,需要安全 1 不需要安全 0
0:每秒1次写入到log file中,同时会进行文件系统、磁盘的同步操作,每个事务的提交commit不会从log buffer到log file,不会触发文件系统到磁盘的同步,速度快,不安全,出现故障会丢失1秒的事务(游戏数据库建议设置为0)。
1:每个事务的提交commit会从log buffer到log file。同时触发文件系统到磁盘的同步操作。(最安全)
2:每个事务的提交commit会从log buffer到log file,不会触发文件系统到磁盘的同步。但是每秒会有一次文件系统到磁盘的同步.
5.innodb_flush_method
show variables like 'innodb_flush_method'
控制innodb数据文件及redo log的打开/刷写的模式
三个值:
fsync: the fsync option is used by default.
fsync: innodb uses the fsync() system call to flush both the data and LoG files. fsync is the default setting.
O_DSYNC: innodb uses O_DSYNC to open and flush the LOG files,and fsync() to flush the
data files.
innodb does not use o_DSYNC directly because there have been problems with it on many varieties of Unix.
O_DIRECT: innodb uses o_DIRECT (or directio() on Solaris) to open the data files,and usesfsync() to flush both the data and LOG files. This option is available on some GNU/Linux versions,FreeBSD,and Solaris.
设置方法:在my.cnf加入:innodb_flush_method=O_DIRECT重启mysql生效。
6.系统表空间与临时表空间路径
show variables like 'innodb%data%file%'
innodb_data_file_path=ibdata1:200M; ibdata2:200M;ibdata3:200M:autoextend:MAX:5G
(生产环境设置为5G/5G/5G,最大20G)数据库小可以1G
innodb_temp_data_file_path=ibtmp1:20OM: autoextend:MAX:20G
(生产环境设置为5G,最大20G)数据库小可以1G
7.重做日志与UNDO路径
show variables like 'innodb_log_group_home_dir'
show variables like 'innodb_undo_directory'
3.InnoDB buffer pool原理与配置
3.1 buffer pool原理
内存缓冲池(buffer pool)以页为单位,缓存最热的数据页(data page)与索引页(index page)
1. innodb_buffer_pool_size内存够的情况下越大越好
show variables like 'innodb_buffer_pool_instances '
-
innodb_buffer_pool_instances: win 1个,unix 8个,如果你的内存小于1G,默认就1个,将热点打散,提高并发性能。
-
buffer pool以页page单位,大小同innodb_page_size一样。
show variables like 'innodb_page_size'
读过程:读——>buffer_pool——>从磁盘读页
写过程:写——>buffer_pool——>刷新磁盘
-
buffer pool组成部分:(重要)
A.free list:启动时,有多个16K的空白页,这些页就存在free list中。
B.LuR list:当读取一个数据页的时候,就从free list中取出一个页,存放数据,并将这个页放入到LUR list。
C.flush list:当UR list中的页第一次被修改时,就将页的指针(page number)放到flush list(只要被修改过的,无论改了多少次)flush list中包含脏页,即数据改过未刷到磁盘的页。free list > LUR list > flush list >磁盘> free list
-
LUR list是如何管理的?(重要)
通过MID point算法管理
这个页第1次读取的时候,该页先放到 MID point的位置;当被读到的第2次,才将这个页放到new page里。
查看插入new page的位置:show variables like ‘innodb_old_blocks_pct’ 初始是放到37%的位置
图示:
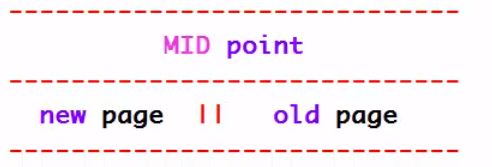
流程:new page->old page相当于是链表结构,old末端刷入磁盘MID point > new page 第二次读才从MID point到new page MID point > old page > new page 第一次读后未用,进入Old page,再次使用才到new page MID point > old page >刷回磁盘 第一次读后未用,进入Old page,到末端,刷入磁盘 MID point > new page > old page >刷回磁盘 第二次读进入 new page,再进入 old page,再写入磁盘同时有一个时间限制,一秒内无论读多少次,按一次计算。比如批量的来查询语句,会读很多次,1秒以后才会放入新的首部。
查看时间限制:show variables like 'innodb_old_blocks_time ’
查看脏页:
select pool_id, lru_position, SPACE, page_number, table_name, oldest_modification, newest_modification from information_schema.INNODB_BUFFER_PAGE_LRU where oldest_modification <> 0 and oldest_modification <> newest_modification
3.2 buffer pool 启动与卸载
- mysql 5.6之前每次启动buffer pool中页是空的,每次都需要大量的时间加载新的页到内存中,启动后有一段时间性能差。
- mysql 5.6之后每次停机会dump出buffer pool的数据(SPACE,page number),然后启动时load进buffer pool,预热。
- 查看bufferpool相关参数:show variables like ‘%innodb_buffer_pool%’
innodb_buffer_pool_dump_at_shutdown 停机时dump innodb_buffer_pool_load_at_startup 启动时加载 innodb_buffer_pool_dump_pct dump的百分比,是最近使用的一个实列的百分比 innodb_buffer_pool_load_now 手工dump相关,现在加载
3.3 buffer pool 的调整
mysql 5.7 <不能在线调整,需要重启才生效。
mysql 5.7 >可以在线调整,需要改my.cnf后重启永久生效。
什么时候需要调整(重要):
1)机器增加物理内存
2)性能原因或历史原因,需要调整。
增加时是以128M为单位增加块
注意:不要在业务繁忙时间调整,尽量在非业务时间。内部设计页的移动,用户请求可能阻塞
调整时,会按块的方式去调整和移动单位是chunk 128M,innodb_buffer_pool_chunk_size
调整innodb_buffer_pool大小的参数
show variables like 'innodb_buffer_pool_size' ;
show variables like 'innodb_buffer_pool_instances' ;实例最后根据cpu的核数来调整。
比如:设置96G
select 96*1024*1024*1024 from dual
innodb_buffer_pool_size=103079215104 --这个值需要在线计算调整设置,否则报错
innodb_buffer_pool_size=98304M --这个参数可以在my.cnf里面设置
实例:我的环境是4G,我现在先调整由512M到2G
第一步:临时全局生效
select 2 *1024 * 1024*1024 from dual
set global innodb_buffer_pool_size=2147483648 --在线设置或者my.cnf
show variables like 'innodb_buffer_pool_size'
第二步:永久生效
可以在my.cnf里面设置
innodb_buffer_pool_size=2147483648
or:
innodb_buffer_pool_size=2048M
or:
innodb_buffer_pool_size=2G
第三步:验证
show variables like 'innodb_buffer_pool_size'
show variables like 'innodb_buffer_pool_instances'
如果缩小呢?缩小需要特别注意,在线修改以后,再改my.cnf文件,再重启生效。去查看日志是否修改成功。不一定成功
select 1024*1024*1024 from dual;
set global innodb_buffer_pool_size=1073741824; -- 受innodb_buffer_pool_instances参数影响,在线不能低于1G
查看buffer pool状态01:show engine innodb status\G(linux查看)
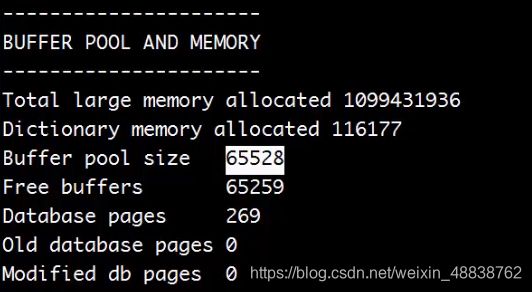
参数解释:
1.Buffer pool size 65528 一共有多少页,一个页为16k ** 单位是页 65528 16 /1024 /1024 G
2.Free buffers 有多少空白页 放在free list里
3.Database pages 存放于LUR list里,有多少页在使用
4.old database pages old page
5.Modified db pages 脏页
6.Total large memory allocated 1099431936 总分配的mysql内存 单位字节
7.Dictionary memory allocated 116177 数据字典内存
查看buffer_pool状态02:select from information_schema.INNODB_BUFFER_pool_stats(在线查看)

与上面linux查看可一一对应
查看LRU信息:select from information_schema .INNODB_BUFFER_page_lru*

注意:space,对应哪个表空间在使用
4.InnoDB数据字典
-
数据字典,数据库的元数据,(表名,数据库名,数据类型,结构,访问权限等除了数据都是元数据)
mysql 5.7 版本之前系统表空间+frm文件(各存在一份元数据),mysql 8.0 及之后全部放在系统表空间 -
获取元数据
information_schema / mysql数据库 所有的信息都在这两个数据库里面
1.sql语句
1. select C.COLUMN_NAME as'字段名', C.COLUMN__TYPE as'数据类型', C.IS_NULLABLE as 允许为空', C.EXTRA as 'PK', C.COLUMN_COMMENT as '字段说明" from columns c inner join tables T on C.TABLE_SCHEMA = T.TABLE_SCHEMA and C.TABLE_NAME = T.TABLE_NAME where T.TABLE_SCHEMA = 'itpux' and T.TABLE_NAME='dept'; 2. select TABLE_SCHEMA,TABLE_NAME, COLOMN_NAME,COLUAN_TYPE,COLUMN_CONMENT from information_schema. columns where TABLE_SCHEMA='mysql'2.navicat
3.mysql-utilities 需要安装:再执行命令 mysqlfrm --diagnostic dept.frm
5.InnoDB表空间管理
5.1 逻辑存储结构
mysql: 表空间 > 段 > 区 > 页 > 行 (逻辑结构,只能数据库看)
SPACE file > segment > extent > page > row
5.2 表空间的介绍(5.6.6以后默认独立表空间)
/mysql/data/3306/data/itpux
dept.ibd 表空间文件(数据和索引)
dept.frm 表结构
- mysql 5.7 有6种表空间:
1)system tablespace 系统表空间
2) file-per-table tablespace 独立表空间
3) temporary tablespace 临时表空间
4) undo tablespace undo表空间
5) general tablespace 一般表空间 与oracle有点类似
6) transportable tablespace 传输表空间
-
innodb包含两种表空间文件模式:
1) 默认的共享表空间
2) 每个表分离的独立表空间: innodb_file_per_table=1 在配置文件设置 my.cnf 在5.7都建议使用独立表空间
3)alter table table_name engine=innodb 把共享表迁移成独立表空间show variables like ‘innodb_file_per_table’;查看打开状态命令
-
共享表空间vs独立表空间
1)共享表空间:
官方默认的; 数据量大了后文件大小不好控制,性能也不好(索引和数据在同一个文件),数据量小没区别
show variables like ‘innodb_autoextend_increment’ ;满了之后可申请进行扩展,每次64M
2)独立表空间:
1000一个表1000个文件存储;分散I0,性能有提升,方便维护和迁移,文件过多也不方便管理和维护,总体来说优先考虑独立表空间
转换:
1.加参数
my.cnf:
innodb_file_per_table=1;
2.每个表转换
表少的情况,把现有的共享表迁移成独立表空间:
alter table table_name engine=innodb
如果表多,导出设置配置文件再导入即可
3.查看状态
show variables like ‘innodb_file_per_table’;
也可以动态设置:set global innodb_file_per_table=1; 可以动态设置。再加入配置文件永久生效
6.innodb system tablespace (系统表空间)
例:系统表空间存在哪些内容?
6.1 关于ibdata1数据文件
204800 -rw-r----- 1 mysql mysql 209715200 Apr 18 00:03 ibdata1
204800 -rw-r----- 1 mysql mysql 209715200 Jan 13 16:37 ibdata2
204800 -rw-r----- 1 mysql mysql 209715200 Jan 13 16:37 ibdata3
第一个用满用第二个
共享表空间下:用户的数据和索引放在ibdata文件中。
独立表空间下:用户的数据和索引放在非ibdata文件中。-- mysql 5.6.6+默认
同时还存储了以下数据:
1)数据字典
2)变更缓冲区
3)双写缓存区
4) undo日志 早期版本
6.2 变更缓冲区change buffer
提高辅助索引的性能,默认开启,能提升30%左右的性能。
mysql 5.5 之前: insert buffer
mysql 5.5 之后: change buffer 包含:insert,delete-marking,purge
查看参数:show variables like ‘%change_buffer%’ ;
innodb_change_buffering = all 参数可取: all,none,inserts,deletes, change, purge
linux查看change buffer:show engine innodb status\G
----------------
insert BUFFER and ADAPTIVE hash index
----------------
Ibuf: size 1,free list len 0,seg size 2,0 merges
merged operations: //合并,值应该很小,或者是0,否则影响性能
insert 0,delete mark 0,delete 0
discarded operations: //取消,值应该很小,或者是0,否则影响性能。
insert 0,delete mark 0,delete 0
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
hash table size 553193,node heap has 0 buffer(s)
0.00 hash searches/s,0.00 non-hash searches/s
Ibuf: size 1:默认一页,seg size 2:总共两页,还有一页是头部信息页
0 merges:合并总数,是0的话,内存是够的,全部放在内存中的
0.00 hash searches/s:每秒查询哈希索引的总数
0.00 non-hash searches/s:每秒查询非哈希索引的总数
6.2.1 什么是change buffer
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了更新操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。change buffer的目的是降低写操作的磁盘IO,提升数据库性能。如果该页在缓存池中,直接进行更新。、
6.2.2 change buffer适用条件
- 只限于普通索引
唯一索引在更新数据时,为了验证数据的唯一性约束,始终会将硬盘的数据读入内存。因此没必要change buffer。 - 适用于写多读少
每次读取数据时,会触发change buffer到磁盘的merge操作,反而影响性能。
6.2.3 change buffer触发merge条件
- 访问这个数据页时触发merge
- 后台线程定期merge
- 数据库正常关闭触发merger
6.3 双写缓存区 (主要解决部分写问题)

首先需要说一下为什么需要双写缓冲;由于InnoDB和操作系统的页大小不一致,InnoDB页大小一般为16k,操作系统页大小为4k,导致InnoDB回写dirty数据到操作系统中,一个页面需要写4次,写入过程出现问题无法保持原子性。写的过程如果崩溃或者断电,可能导致只有一部分写回到操作系统文件系统中,整个数据只是部分成功,其实数据是损坏的。
类似于raid 1模式,double write作用是为了保证数据的写入可靠性,避免部分写(partial write)的情况。
部分写(partial write) :一个页16K,只写了其中一部分(10K/8K),不完整的页是不能通过redo log恢复。
double write:double write是全局的,以段方式存在,大小2M,每个段2个区,每个区1M组成。
MySQL 的数据页在真正写入到表空间文件前,会先写到系统表空间文件的一段连续区域双写缓冲(Double-Write Buffer,默认大小为 2MB,128个页)并 fsync 落盘(这里只需要一两次落盘,每次1M),等双写缓冲写入成功后才会将数据页写到实际表空间的位置。
因为双写缓冲和数据页的写入时机不一致,如果在写入双写缓冲出错,可以直接丢弃该缓冲页,而如果是写入数据页时出错,则可以根据双写缓冲区数据恢复表空间文件。
**总结:**可以根据副本恢复
在脏页刷新到磁盘之前,先有一个地方记录这个脏页的副本:
1)将脏页copy到double write buffer对象中,默认2*1M大小;
2)将double write buffer中的对象写入到共享表空间ibdata1中的double write,循环2M覆盖;
3)根据共享表空间ibdata1中记录的表空间和页号(space id,page number)再写到用户表空间的ibd文件中
查看参数控制:show variables like ‘%doublewrite%’ ;
参数:innodb_doublewrite=on
注意:所谓双写,并不是写两次,比如一个写了128页,那么双写就是128+1次IO=129;性能影响大概是2M数据是顺序刷入磁盘,一次IO 2M,影响5%-25%;
特殊情况关闭:
不要数据安全,只要速度。innodb_doublewrite=0 my.cnf
6.4 系统表空间的扩容与缩小
6.4.1 设置自动扩展
查看参数:show variables like ‘innodb_data_file_path’ ;
文件修改:my.cnf
设置参数:innodb_data_file_path=ibdata1:200M; ibdata2:20OM; ibdata3:200M:autoextend:MAX:5G
自动扩展只能用于最后一个文件,前面的文件不能扩展
6.4.2 添加数据文件进行扩展
my. cnf文件
[mysqld]将原来的:
innodb_data_file_path=ibdata1:200M; ibdata2:200M;ibdata3:200M:autoextend:MAX:5G
修改为:
innodb_data_file_path=ibdata1:200M; ibdata2:200M;ibdata3:200M; ibdata4:200M: autoextend:MAX:5G
关于文件大小,扩容前最后一个文件精确到1M的倍数:
比如文件大小295.36M 写成 296M。
关于路径的问题:
查看命令:show variables like ‘%innodb%home%’ ;
6.4.3 缩小innodb system tablespace(重点)
场景:原来是共享表空间,转换独立表空间后,数据和索引迁移出ibdata,原来的又有500G文件不会自动缩小。
1)导出所有的数据:只针对innodb引擎
在新的文件夹执行命令,导入:
mysqldump --all-databases --flush-privileges --quick --routines --triggers -uroot -p >
all-db.sql
2)查询所有的innodb表-mysql 找到以后表名全部复制出来
select table_name from information_schema.tables where table_schema='mysql' and engine='innodb' ;
3)拷贝现在所有的目录(空间足够必须拷mysql数据文件目录,整个data目录下的mysql目录,命名为:.bak文件)

4)停止mysql 进入data目录停止
service mysql stop
5)删除所有的表空间文件(.ibd),包括ibdata,ib_log, undo*, mysql目录下面的*.ibd文件,以及mysql中的innodb表的.frm文件。 data文件夹
1: find . -name "*.ibd"-exec rm -rf {} \;批量删除.idb文件
2: 进入data/mysql文件,将刚拷贝的表名的.frm删除 如:
rm -f slave_master_info.frm
rm -f slave_relay_log_info.frm
rm -f slave_worker_info.frm
rm -f time_zone.frm
rm -f time_zone_leap_second . frm
rm -f time_zone_name .frm
rm -f time_zone_transition. frm
3: rm -f ib* 删除ib开头的文件
4: rm -f undo00* 删除undo文件
6) 如果你的my.cnf里面的ibdata1是200M,那你手工改成180M,设置新的ibd文件大小
vi /mysql/data/3306/my.cnf
将大小改小
innodb_data_file_path=ibdata1:180M;ibdata2:180M;ibdata3:180M:autoextend:MAX:5G
7) 开启mysql服务
service mysql start
- 恢复数据数据库
mysql -uroot -p < all-db.sql
- 重启测试
6.4.4 分离innodb ibdata文件(重点)
场景2∶原来是共享表空间,转换独立表空间后,数据和索引迁移出ibdata,原来的又有500G文件不会自动缩小,同时还在分离成独立表空间
方法同6.4.3 只需要在第6步加入:innodb_file_per_table=1
7.临时表空间
mysql 5.7之前临时表都放在ibdata里面,mysql 5.7 之后临时表放在临时表空间
临时表空间作用:主要用于临时排序/非压缩的临时表M,默认12M
7.1 大小、位置修改
查看参数:show variables like ‘innodb_temp_data_file_path’;
设置参数:innodb_temp_data_file_path=ibtmp1:200M: autoextend:MAX:20G (生产环境别设置太小,5G/10G都行)
位置:/mysql/data/3306/data
正常来讲,这个是不能改路径的。
修改路径的另类方法:
ln -s /dev/shm/ lmysql/data/3306/data/temp
chown -R mysql :mysql /mysql/data/3306/data/temp
vi my.cnf
innodb_temp_data_file_path=temp/ibtmp1:500M: autoextend:MAX:30G
重启mysql生效
8.临时表
临时表类型:
全局临时表( memory引擎)
会话级临时表( create temporary table)
事务级临时表(mysql目前没有这种临时表)
检索级临时表
mysql创建临时表的情况:
1) union查询
2) order by
3) group by
4) from子查询,链接,大的结果集
mysql 5.7.5 以后默认定义磁盘临时表为innodb:
查看命令:show variables like 'internal_tmp_disk_storage_engine ’ ;
internal_tmp_disk_storage_engine=innodb
会话级临时表默认存储引擎:
mysql 5.6.3 之前 create temporary table临时表为memory引擎
mysql 5.6.3 之后 create temporary table临时表为innodb引擎
show variables like ‘default_tmp_storage_engine’ ;
显示创建非压缩临时表与测试 创建的临时表定义(.frm)放在tmpdir环境变量下默认tmp目录下
create temporary table itpuxtmp1(id int,tmp_desc varchar(60));
select*from information_schema .innodb_temp_table_info;
**显示创建压缩的临时表,定义和数据文件(.frm和.idb)默认tmp目录下,compressed最大支持在16K的页下面,同时innodb_file_format格式为barracuda:**show variables like 'innodb_file_format ';
create temporary table itpuxtmp2(id int, tmp_desc varchar(60))row_format=compressed;
select * from information_schema.innodb_temp_table_info;
关于#sql78ff_3_0
select CONV('3',16,10); = select CONNECTION_IDO;
9.general tablespace一般表空间
mysql 5.7.6 >开始支持general tablespace,类似oracle的表空间管理创建表空间可以指定数据文件名,但只能是一个,.ibd为后缀
创建表空间语法:
create tablespace tablespace_name
add datafile 'file_name' --文件名,路径默认在mysql下
[FILE_BLOCK_SIZE = value] --只能在压缩表的时候才可以使用
[engine [=] engine_name]
例:
--创建一个表空间1
create tablespace itpuxts1 add datafile 'itpuxts101.ibd' engine=innodb;
--创建一个表空间2
create tablespace itpuxts2 add datafile '、itpuxts201.ibd' FILE_BLOCK_SIZE = 8k;
--创建一个压缩表
create table itpuxz01(c1 int) tablespace itpuxts1 row_format=compressed;--error
create table itpuxz01(c1 int) tablespace itpuxts2 row_format=compressed;-- OK
--删除表空间(要先删除里面的表)
drop table itpuxz01;
drop tablespace itpuxts2;
--表在表空间之间的迁移
create tablespace itpuxts1 add datafile 'itpuxts101.ibd'engine=innodb;
create table itpuxt01(a int);
迁移到itpuxts1表空间
alter table itpuxt01 tablespace=itpuxts1;
迁移到系统表空间
alter table itpuxt01 tablespace=innodb_system;
迁移到独立表空间
alter table itpuxto1 tablespace=innodb_file_per_table;
--创建表空间的另类方法(不建议使用)
mkdir /var/lib/mysql/data02
chown mysql:mysql /var/lib/mysql/data02
create table itpuxt02(a int) data directory='/var/lib/mysql/data02';
10.Undo表空间
mysql 5.7 >从系统表空间独立出来的undo回滚表空间
show variables like '%undo%';
默认值:
innodb_max_undo_log_size 1073741824 --生产环境可设置5G
innodb_undo_directory ./ -- 默认路径
innodb_undo_log_truncate OFF -- 会滚段是否开启自动清理 可改变为NO
innodb_undo_logs 128 -- 日志段为128个段
innodb_undo_tablespaces 0 --回滚段表空间的个数最大95个,一般3
11.transportable tablespace(略)
可传输表空间,方便迁移。
12.加密表空间(略)
mysql 5.7 以后 keyring_file插件
13.深入分析InnoDB的存储结构
13.1 工具innochecksum查看ibdata1的页使用情况
必须停掉mysql服务
[root@itpuxdb data]# innochecksum --page-type-summary ibdata1
结果:
File::ibdata1
================PAGE TYPE SUMMARY==============
#PAGE_COUNT PAGE_TYPE
===============================================
94 Index page --索引页
52 Undo log page --会滚段页
8 Inode page --节点页
0 Insert buffer free list page --插入缓冲区空闲列表页
489 Freshly allocated page --新的页
4 Insert buffer bitmap
106 System page --系统页
1 Transaction system page --事务系统页
5 File Space Header --空间头页
0 Extent descriptor page
9 BLOB page --大字段页
0 Compressed BLOB page --压缩字段页
0 Other type of page
===============================================
Additional information:
Undo page type: 37 insert, 15 update, 0 other
Undo page state: 0 active, 52 cached, 0 to_free, 0 to_purge, 0 prepared, 0 other
13.2 通过ruby (innodb_space)深入分析innodb内部结构
13.2.1 工具安装
innodb格式分析工具,可以解析innodb内部存储与数据结构。别去生产环境使用,有风险。
安装(略)
innodb_space --help
innodb_space -s ibdata1 [-T tname [-I iname]] [options] <mode>
Use ibdata1 as the system tablespace and load the tname table (and the
iname index for modes that require it) from data located in the system
tablespace data dictionary. This will automatically generate a record
describer for any indexes.
innodb_space -f tname.ibd [-r ./desc.rb -d DescClass] [options] <mode>
Use the tname.ibd table (and the DescClass describer where required).
The following options are supported:
--help, -?
Print this usage text.
--trace, -t
Enable tracing of all data read. Specify twice to enable even more
tracing (including reads during opening of the tablespace) which can
be quite noisy.
--system-space-file, -s <arg>
Load the system tablespace file or files <arg>: Either a single file e.g.
"ibdata1", a comma-delimited list of files e.g. "ibdata1,ibdata1", or a
directory name. If a directory name is provided, it will be scanned for all
files named "ibdata?" which will then be sorted alphabetically and used to
load the system tablespace.
--table-name, -T <name>
Use the table name <name>.
--index-name, -I <name>
Use the index name <name>.
--space-file, -f <file>
Load the tablespace file <file>.
--page, -p <page>
Operate on the page <page>.
--level, -l <level>
Operate on the level <level>.
--list, -L <list>
Operate on the list <list>.
--fseg-id, -F <fseg_id>
Operate on the file segment (fseg) <fseg_id>.
--require, -r <file>
Use Ruby's "require" to load the file . This is useful for loading
classes with record describers.
--describer, -d
Use the named record describer to parse records in index pages.
The following modes are supported:
system-spaces
Print a summary of all spaces in the system.
data-dictionary-tables
Print all records in the SYS_TABLES data dictionary table.
data-dictionary-columns
Print all records in the SYS_COLUMNS data dictionary table.
data-dictionary-indexes
Print all records in the SYS_INDEXES data dictionary table.
data-dictionary-fields
Print all records in the SYS_FIELDS data dictionary table.
space-summary
Summarize all pages within a tablespace. A starting page number can be
provided with the --page/-p argument.
space-index-pages-summary
Summarize all "INDEX" pages within a tablespace. This is useful to analyze
page fill rates and record counts per page. In addition to "INDEX" pages,
"ALLOCATED" pages are also printed and assumed to be completely empty.
A starting page number can be provided with the --page/-p argument.
space-index-fseg-pages-summary
The same as space-index-pages-summary but only iterate one fseg, provided
with the --fseg-id/-F argument.
space-index-pages-free-plot
Use Ruby' s gnuplot module to produce a scatterplot of page free space for
all "INDEX" and "ALLOCATED" pages in a tablespace. More aesthetically
pleasing plots can be produced with space-index-pages-summary output,
but this is a quick and easy way to produce a passable plot. A starting
page number can be provided with the --page/-p argument.
space-page-type-regions
Summarize all contiguous regions of the same page type. This is useful to
provide an overall view of the space and allocations within it. A starting
page number can be provided with the --page/-p argument.
space-page-type-summary
Summarize all pages by type. A starting page number can be provided with
the --page/-p argument.
space-indexes
Summarize all indexes (actually each segment of the indexes) to show
the number of pages used and allocated, and the segment fill factor.
space-lists
Print a summary of all lists in a space.
space-list-iterate
Iterate through the contents of a space list.
space-extents
Iterate through all extents, printing the extent descriptor bitmap.
space-extents-illustrate
Iterate through all extents, illustrating the extent usage using ANSI
color and Unicode box drawing characters to show page usage throughout
the space.
space-extents-illustrate-svg
Iterate through all extents, illustrating the extent usage in SVG format
printed to stdout to show page usage throughout the space.
space-lsn-age-illustrate
Iterate through all pages, producing a heat map colored by the page LSN
using ANSI color and Unicode box drawing characters, allowing the user to
get an overview of page modification recency.
space-lsn-age-illustrate-svg
Iterate through all pages, producing a heat map colored by the page LSN
producing SVG format output, allowing the user to get an overview of page
modification recency.
space-inodes-fseg-id
Iterate through all inodes, printing only the FSEG ID.
space-inodes-summary
Iterate through all inodes, printing a short summary of each FSEG.
space-inodes-detail
Iterate through all inodes, printing a detailed report of each FSEG.
index-recurse
Recurse an index, starting at the root (which must be provided in the first
--page/-p argument), printing the node pages, node pointers (links), leaf
pages. A record describer must be provided with the --describer/-d argument
to recurse indexes (in order to parse node pages).
index-record-offsets
Recurse an index as index-recurse does, but print the offsets of each
record within the page.
index-digraph
Recurse an index as index-recurse does, but print a dot-compatible digraph
instead of a human-readable summary.
index-level-summary
Print a summary of all pages at a given level (provided with the --level/-l
argument) in an index.
index-fseg-internal-lists
index-fseg-leaf-lists
Print a summary of all lists in an index file segment. Index root page must
be provided with --page/-p.
index-fseg-internal-list-iterate
index-fseg-leaf-list-iterate
Iterate the file segment list (whose name is provided in the first --list/-L
argument) for internal or leaf pages for a given index (whose root page
is provided in the first --page/-p argument). The lists used for each
index are "full", "not_full", and "free".
index-fseg-internal-frag-pages
index-fseg-leaf-frag-pages
Print a summary of all fragment pages in an index file segment. Index root
page must be provided with --page/-p.
page-dump
Dump the contents of a page, using the Ruby pp ("pretty-print") module.
page-account
Account for a page's usage in FSEGs.
page-validate
Validate the contents of a page.
page-directory-summary
Summarize the record contents of the page directory in a page. If a record
describer is available, the key of each record will be printed.
page-records
Summarize all records within a page.
page-illustrate
Produce an illustration of the contents of a page.
record-dump
Dump a detailed description of a record and the data it contains. A record
offset must be provided with -R/--record.
record-history
Summarize the history (undo logs) for a record. A record offset must be
provided with -R/--record.
undo-history-summary
Summarize all records in the history list (undo logs).
undo-record-dump
Dump a detailed description of an undo record and the data it contains.
A record offset must be provided with -R/--record.
1.3.2.2 配合innodb_space参数学习innodb内部结构
innodb_space --help |more
Invocation examples:
innodb_space -s ibdata1 [-T tname [-I iname]] [options] <mode>
Use ibdata1 as the system tablespace and load the tname table (and the
iname index for modes that require it) from data located in the system
tablespace data dictionary. This will automatically generate a record
describer for any indexes.
innodb_space -f tname.ibd [-r ./desc.rb -d DescClass] [options] <mode>
Use the tname.ibd table (and the DescClass describer where required).
常用的几个选项:
-s系统表空间名
-T表名
-工索引
-f表空间文件
- 示例:
innodb_space -f itpuxt02.ibd space-summary |more

查询总共的页数,计算.idb的文件大小

98304=6x1024x16
- 表空间数据文件的结构(space file)(重点)
SPACE id=表空间标识
ibdata1, ibdata2均属于系统表空间,相同的表空间space id相同
每个表空间对应一个space id,而表空间又对应一个ibd文件。
每次读取page时,通过space id + page number进行读取,space id是全局自增长的,不会回收。
select * from information_schema .innodb_sys_tables;

每一种表空间,space id是一样的,single,每一个表就是一个表空间
参数:
1)system-spaces
列出所有物理对象的数量
innodb_space -s ibdata1 system-spaces

2) space-indexes列出索引统计信息
空间索引列出索引统计信息
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-indexes

3)space-page-type-regions 列出索引树有多少节点
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-page-type-regions

4) space-page-type-summary按类型统计
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-page-type-summary

5) space-extents-illustrate所有页的饱和度情况(数据太少,图片颜色看不出来)
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-extents-illustrate

6)space-lsn-age-illustrate 所有页在空间的时间标识、新旧程度(数据太少,图片颜色看不出来)
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-lsn-age-illustrate
7) space-index-pages-summary |more
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-index-pages-summary |more

13.3页的结构(重点)

页的大小16K,所有的记录都放在数据库页中:
页的结构:
1)文件头:file header
| 名称 | 长度 | 含义 |
|---|---|---|
| FIL_PAGE_SPACE | 4 | SPACE id |
| FIL_PAGE_OFFSET | 4 | 页号(表空间中页的偏移值。如某独立表空间a.ibd的大小为1GB,如果页的大小为16KB,那么总共有65536个页。FIL_PAGE_OFFSET表示该页在所有页中的位置。若此表空间的ID为10,那么搜索页(10,1)就表示查找表a中的第二个页) |
| FIL_PAGE_PREV | 4 | 当前页的上一个页,B+ Trec特性决定了叶子节点必须是双向列表 |
| FIL_PAGE__NEXT | 4 | 当前页的下一个页,B+ Tree特性决定了叶子节点必须是双向列表 |
| FIL_PAGE_LSN | 8 | 日志序列号,该值代表该页最后被修改的日志序列位置LSN (Log Sequence Number) |
| FIL_PAGE_TYPE | 2 | 页类型 |
| FIL_PAGE_FILE_FLUSH_LSN | 8 | 文件的日志序列号,仅文件的第一页的此字段有效 |
| FIL_PAGE_ARCH_LOG_NO | 4 | 归档日志文件号 |
2)页头:page header
| 名称 | 长度 | 含义 |
|---|---|---|
| PAGE_N_DIR_SLOTS | 2 | 记录页目录中槽的数量,初始值为2,因为页至少具有最小虚记录与最大虚记录 |
| PAGE_HEAP_TOP | 2 | 指向堆中的第一条记录 |
| PAGE_N_HEAP | 2 | 堆记录的数量,初始值为2 |
| PAGE_N_FREE | 2 | 指向第一个空闲记录 |
| PAGE_GARBAGE | 2 | 被删除记录的总字节数 |
| PAGE_LAST_INSERT | 2 | 指向最后一个插入的记录 |
| PAGE_DIRECTION | 2 | 记录顺序 |
| PAGE_N_DIRECTION | 2 | 连续同方向插入的数量 |
| PAGE_N_RECS | 2 | 用户记录的数量 |
| PAGE_MAX_TRX_ID | 8 | 更改此页的最高事务ID(仅仅对二级索引有效) |
| PAGE_LEVEL | 2 | 该页在索引中的层次(页节点是0) |
| PAGE_INDEX_ID | 8 | 所属的索引ID |
| PAGE_BTR_SEG_LEAF | 10 | 索引页节点段 |
| PAGE_BTR_SEG_TOP | 10 | 索引内节点段 |
3)最小虚记录和最大虚记录: infimum+isupermum recoreds
4)用户记录:user records
5)空间空间:free SPACE
6)页目录槽: page directory
7)文件尾: file trailer
其中:
1)和7)与文件管理有关
2)和6)与页管理有关
3)4)5)是与记录相关的
8)查看第三页的统计信息
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-account

具体页详细信息:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-dump |more

第三页记录数:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-records |more

查看具体页的字典信息(根据索引,只能查到页字典信息,根据page directory才能找到具体记录)
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-directory-summary

页存储分布图:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-illustrate

具体页内存的统计信息:(重点)

13.4 索引的结构(Index)
- 主键索引的记录(通过id查询,可查询记录行)
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -I PRIMARY index-recurse |more

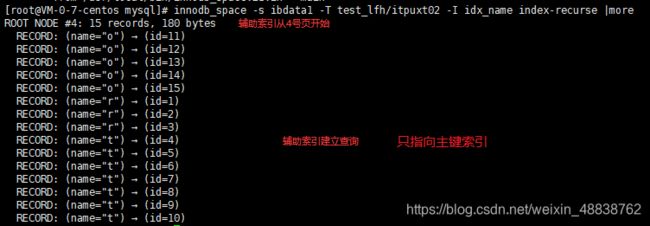
2)辅助索引(idx_name为创建的索引名,只指向主键索引,再由主键索引指向数据)
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -I idx_name index-recurse |more
3)0号级别的索引
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -I PRIMARY -l 0 index-recurse |more
13.5数据记录结构
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 -R 2 record-dump
heap number:表示页中每个记录插入的顺序序号
例如:插入的数据是a,b,c,d e f ,则对应的heap number为2,3,4,5,6
0,1被Infimum(对应最小的heap number)与supremum(对应最大的heap number)所使用
heap number是物理的,存储的row的record_header字段中。
行插入结构:(重点:数据是怎么记录的)
heap_number 行数 插入数据
----------------
2 第1行 a
3 第2行 b
4 第3行 c
5 第4行 e
6 第5行 f
mysql> show engine innodb status\G
查看数据库状态,heap number,事务id,锁信息,所在页等信息。
--05.数据记录的历史(history)了解
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 4 -R 111 record-history
innodb_space -s ibdata1 undo-history-summary
innodb_space -s ibdata1 -p 400 -R 100 undo-record-dump
13.6通过innodb_space详细分析索引结构和分配情况
查看索引分配情况:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-indexes

查看索引数据使用页的情况:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 space-page-type-regions

查看第三页的数据情况:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-records
统计主键占用页的数量:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 3 page-records |wc -l
查看辅助索引记录数量:-i idnexname
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 36 page-recqrds -I idx_name |wc -l
查看辅助索引的记录:
innodb_space -s ibdata1 -T test_lfh/itpuxt02 -p 4 page-records -I idx_name |more
辅助索引并不是记录行的数据,而是一个指针指向主键,索引辅助索引一个页可以存很多这样的指针信息,而主键索引存的是每一行的信息。所以一个页存的记录很少。
14.innodb 存储格式介绍
文件格式有两种:
mysql 5.7 之前 Antelope
支持两个行格式:
compact: mysql 5.6默认的格式,针对char类型null值,不存储。varchar类型,不存储NULL值
redundant : mysql 4.1之前的格式,为了兼容老的innodb,针对char类型null值,存储。varchar类型,不存储NULL值
mysql 5.7 之后 Barracuda
支持两个行格式:
dynamic: mysql 5.7默认的格式
compressed :大对象记录优化,支持压缩
需要开启innodb_file_per_table=1,支持独立表空间,才支持这两种格式
查看文件格式:
show variables like '%innodb%format%';
区别:
Antelope:针对text/blob每一个页上会存768个前缀字节
Barracuda:针对text/blob每一个页上只存20个字节的指针,可以存储更多数据
barracuda文件格式大字段存储格式:

查看文件格式:
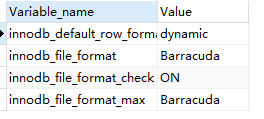
在mysql 8.0,这两个参数官方不再建议使用了:
innodb_file_format
innodb_file_format_max
compact行记录格式:5.7之前行格式
————————————————————————————————————————————————————————————————————————————
|变长字段长度列表 | NULL标记位 | 记录头信息 | 列1 | 列2 | 列3 | 列4
————————————————————————————————————————————————————————————————————————————
|variable length | null flag | record header | 列1 | 列2 | 列3 | 列4
————————————————————————————————————————————————————————————————————————————
记录头信息:record header
(row id B+树索引键值,trx id事务ID 6个字节,roll pointer回滚指针7个字节)
redundant行记录格式: 5.7之后行格式 没有null标记位
————————————————————————————————————————————————————————————————————————————
|变长字段长度列表 | 记录头信息 | 列1 | 列2 | 列3 | 列4
————————————————————————————————————————————————————————————————————————————
|variable length | record header | 列1 | 列2 | 列3 | 列4
————————————————————————————————————————————————————————————————————————————
记录头信息:record header
(row id B+树索引键值,trx id事务ID 6个字节,roll pointer回滚指针7个字节)
查看当前的行格式:
show table status like 'yg';
动态表和静态表:
动态表,如果一份数据最后一个页用了8K,动态表就只用了8K,后面的数据可以接着用这页。静态表相当于占用了16K,后面的数据从下一页开始写。
静态表(memory): row_format=fixed 变成动态表:导致char类型变成varchar
动态表(innodb): row_format=dynamic 变成静态表:导致varchar类型变成char
修改行格式:
alter table table_name row_format=dynamic;
alter table table_name row_format=default;
alter table table_name row_format=compressed
修改存取格式:
alter table yg row_format=compressed;
alter table yg row_format=dynamic;
15.InnoDB存储引擎表的压缩
(压缩页与buffer pool 有关。buffer pool设置够大采用压缩,开启压缩以后,空间不会去释放,buffer pool空间越来越大)
场景:日志数据归档,采用压缩表。
15.1 设置innodb表的压缩
- mysql版本建议是5.7+
2)(my.cnf)innodb_file_format=Barracuda
3)(my.cnf)innodb_file_per_table=on - create table /alter table 指定row_format=compressed key_block_size=8
建表语句:
create table itpuxz01(id int ,name varchar(10)) engine=innodb row_format=compressed key_block_size=8;
show table status like 'itpuxz01';
row_format=compressed 是针对页压缩,而不是针对记录压缩,读取页的时候会自动解压,写页的时候会自动压缩
15.2 查看状态
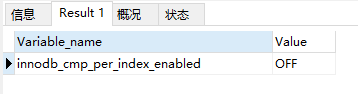
可以看压缩是否有异常:
select * from information_schema .innodb_cmp;
查看压缩参数:
show variables like '%innodb%compress%';

select * from information_schema .innodb_cmp_per_index;
show variables like '%innodb%cmp%';
15.3 innodb表压缩算法
压缩借助于zlib库,采用了1777压缩算法
create table itpuxz04(id int ,name varchar(10)) compression="zlib";
create table itpuxz03(id int ,name varchar(10)) compression="lz4";
更改压缩算法:
alter table itpuxz03compression="zlib";
optimize table itpuxz03;
show create table itpuxz03;
15.4 buffer pool与压缩页
查换buffer pool中的压缩页:
desc information_schema.`INNODB_BUFFER_PAGE_LRU`;
查看那些页压缩:
select* from information_schema.`INNODB_BUFFER_PAGE_LRU` where compressed='YES';
根据空间id查找表信息:
select * from information_schema.`INNODB_SYS_TABLES` where SPACE=8;
16.InnoDB状态的监控管理
一些信息输出到错误日志
16.1 innodb monitor类型
standard monitor
lock monitor
tablespace monitor
table monitor
standard monitor:
show variables like '%innodb_status%';
进行一般的监控的参数:
innodb_status_output=on
innodb_status_output_locks=off
设置监控:
set global innodb_status_output=on
linux查看:
show engine innodb status\G
lock monitor:
show variables like '%innodb_status%';
监控参数;
innodb_status_output=on
innodb_status_output_locks=on
设置监控:长期生效放入my.conf的配置文件
set global innodb_status_output=on
set global innodb_status_output_locks=on
tablespace monitor 表空间状态
select* from information_schema.`TABLESPACES`;
select*from information_schema .innodb_sys_tablespaces;
table monitor 表状态
select* from information_schema.tables;
select * from information_schema. `INNODB_SYS_TABLES`
select* from information_schema.`INNODB_SYS_TABLESTATS`
16.2详细分析innodb status(监控信息)
可以分页来看:
pager less
show engine innodb status\G
系统时间及取样时间长度:

IO与OS相关,并发量高,数值大,几万和十几万时应该关注

生成一个锁观察事务的锁效果:应该有具体哪个表锁住,锁类型的具体信息,目前没找到
mysql> use test_lfh;
mysql> lock table itpuxz03 write;
IO:
LOG&LSN:

buffer内存情况:

总体信息:这段时间主要在做什么内容(insert/update/delete/read)

16.3常用空间信息查询语句
查看各数据库大小:
select table_schema "Database Name",SUM(data_length + index_length ) / 1024/ 1024 "Database Size in NB" from information_schema.TABLES group by table_schema;
查看全部数据库总共大小:
select SUM(data_length + index_length ) / 1024/ 1024 "Database Size in NB" from information_schema.TABLES;
查看索引 单位是MB
select CONCAT(ROUND(SUM(data_length)/(1024*1024),2),'MB' )as 'Total data Size'from INFORMATION_SCHEMA.TABLES where engine='innodb';
查看test_lfh数据库的 单位是MB
select CONCAT(ROUND(SUM(index_length)/(1024*1024),2),'MB')as 'Total Index Size' from information_schema.TABLES where table_schema like 'test_lfh';
查看数据库的表空间大小 MB
select CONCAT(ROUND(SUM(data_length)/(1024*1024),2),'MB') as 'Total Data Size'from information_schema.TABLES where table_schema like 'test_lfh';
查看test_lfh数据库中所有表和索引的空间信息
select CONCAT(table_schema,'.',table_name) as 'Table Name',CONCAT(ROUND(table_rows,2))as 'Number of Rows',CONCAT(ROUND(data_length/(1024*1024),2),'MB') as 'Data Size ', CONCAT(ROUND(index_length/(1024*1024),2),'MB') as 'Index_Size' from information_schema.TABLES where table_schema like 'test_lfh';
查看数据库表空间信息:
select CONCAT(TRUNCATE(SUM(data_length)/1024/1024,2),'MB') as 'data_size',
CONCAT(TRUNCATE(SUM(max_data_length)/1024/1024,2),'MB') as 'max_data_size',
CONCAT(TRUNCATE(SUM(data_free)/1024/1024,2), 'MB') as 'data_free',
CONCAT(TRUNCATE(SUM(index_length)/1024/1024,2), 'MB') as 'index_size'
from information_schema.tables where TABLE_SCHEMA ='test_lfh';
查看数据库itpuxz01表的大小:
select table_name as "Tables",ROUND(((data_length + index_length)/1024/1024),2) "Size in MB"from information_schema.TABLES where table_schema = "test_lfh" and table_name ='itpuxz01';
查看数据库各表大小:
select table_name as "Tables",ROUND(((data_length + index_length)/1024/1024),2) "Size in MB"from information_schema.TABLES where table_schema = "test_lfh" order by (data_length + index_length) desc;
找出前10的表大小:
select CONCAT(table_schema,'.',table_name),
CONCAT(ROUND(table_rows/1000,2),'K') rows,
CONCAT(ROUND(data_length/(1024*1024 ),2),'MB') data,
CONCAT(ROUND(index_length/(1024*1024 ),2),'MB') idx,
CONCAT(ROUND((data_length+index_length)/ (1024*1024),2),'MB') total_size,
ROUND(index_length/data_length,2) idxfrac
from information_schema.TABLES order by data_length + index_length desc limit 10;
17.InnoDB的Memcached插件的使用(NoSQL)
mysql+memcached
使用这个插件,如果数据量大,性能提高显著。
17.1安装memcached插件
数据库客户端查找插件位置,确认memcached是否存在
select @@plugin_dir;
linux系统在mysql环境导入指定文件目录下的脚本sql:
mysql> source /usr/share/mysql/innodb_memcached_config.sql
安装插件
mysql> install plugin daemon_memcached soname "libmemcached.so";
卸载插件
mysql> uninstall plugin daemon_memcached;
装好之后查看一些信息
show variables like "%memcached%";
安装nc命令:
yum install -y nc
测试是否安装好:
echo "stats" |nc localhost 11211
使用:
1.使用提供的test数据库创建表:后面三个字段得建立上,且字段类型和给出的demotest表一致。
create table itpux_member(
id int unsigned not null primary key auto_increment,
username varchar(15) not null,
password varchar(32) not null,
email varchar(50) not null,
flags int(10) UNSIGNED default '0',
cas_column BIGINT(20) UNSIGNED default '0',
expire_time_column int(10) UNSIGNED DEFAULT '0',
unique key username (`username`)
)engine=innodb;
2.添加数据:
insert into itpux_member(username,password,email) values('itpux1','itpuxpass1','itpux10qq.com');
insert into itpux_member(username,password,email) values('itpux2','itpuxpass2','[email protected]');
COMMIT;
3.在containers配置itpux_member表
insert into innodb_memcache.containers(
name,db_schema,db_table,key_columns,value_columns,flags,cas_column,expire_time_column,unique_idx_name_on_key)values(
'itpux_member','test','itpux_member','username','password|email|','flags','cas_column','expire_time_column','username');
COMMIT;
SELECT * FROM innodb_memcache.containers;
测试: itpux_member:containers中的name字段;itpux1:containers中的name字段对应table_name字段表的主键字段得值
[root@VM-0-7-centos mysql]# echo "get @@itpux_member.itpux1" |nc localhost 11211

18.三种日志(redo log/undo log/bin log)
18.1 redo log
**作用:**确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。(只能恢复最后一次提交的位置)
**内容:**物理格式的日志(恢复时基于物理格式的日志效率要高于逻辑日志),记录的是物理数据页面的修改的信息,其redo log是顺序写入redo log file的物理文件中去的,是事务层面的日志。对应的物理文件:默认情况下,对应的物理文件位于数据库的data目录下的ib_logfile1&ib_logfile2,是以块进行存储的,以页记录。为innodb引擎所有。
关于文件的大小和数量,由以下两个参数配置:
- innodb_log_file_size 重做日志文件的大小。
- innodb_mirrored_log_groups 指定了日志镜像文件组的数量,默认1
产生时机:事务开始之后就产生redo log,redo log的落盘并不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo log文件中
释放时机:当对应事务的脏页写入到磁盘之后,redo log的使命也就完成了,重做日志占用的空间就可以重用(redo日志大小是固定的)。
刷盘时机:重做日志有一个缓存区Innodb_log_buffer,Innodb_log_buffer的默认大小为8M,Innodb存储引擎先将重做日志写入innodb_log_buffer中。
然后会通过以下几种方式将innodb日志缓冲区的日志刷新到磁盘:innodb_flush_log_at_trx_commit参数默认为1时刷盘规则
- Master Thread 每秒一次执行刷新Innodb_log_buffer到重做日志文件。
- 每个事务提交时会将重做日志刷新到重做日志文件。
- 当重做日志缓存可用空间 少于一半时,重做日志缓存被刷新到重做日志文件
- checkpoint时
因为redo log时持续刷盘的,所以再大的事务的提交(commit)的时间也是很短暂的
innodb_flush_log_at_trx_commit参数:事务commit时是否需要刷盘控制参数
- 为0时,事务的提交不刷写log buffer。log buffer每秒写入OS cache的file,并flush到磁盘file中。
- 为1时,默认状态;每次事务的提交都会写log buffer,并将log buffer写入OS cache中且flush到磁盘的file中。
- 为2时,每次事务提交会把log buffer写入OS cache的log file中,每秒执行一次flush到磁盘的file操作。
对比:参数值为1时最安全,最慢。在mysqld崩溃或者服务器主机宕机时,bin log最多丢失一个语句或者一个服务。参数值为0时,速度最快,在mysqld崩溃或者服务器主机宕机时会丢失1s的数据。参数为2时,速度比0慢不了多少,比0安全,服务器主机宕机时上一秒数据可能丢失。
commit的刷盘频率:由innodb_flush_log_at_timeout控制,默认1s,此参数与commit时是否刷盘无关。
18.2 undo log
**作用:**保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
**内容:**逻辑格式的日志,记录的是sql语句。在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。采用段记录。MySQL5.6之前,undo表空间位于共享表空间的回滚段中,共享表空间的默认的名称是ibdata,位于数据文件目录中。MySQL5.6之后,undo表空间可以配置成独立的文件,但是提前需要在配置文件中配置,完成数据库初始化后生效且不可改变undo log文件的个数。
关于MySQL5.7之后的独立undo 表空间配置参数如下:
- innodb_undo_directory = /data/undospace/ –undo独立表空间的存放目录
- innodb_undo_logs = 128 –回滚段为128KB
- innodb_undo_tablespaces = 4 –指定有4个undo log文件
**产生时机:**事务开始之前,将当前是的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性
默认情况下undo文件是保持在共享表空间的,也即ibdatafile文件中,当数据库中发生一些大的事务性操作的时候,要生成大量的undo信息,全部保存在共享表空间中的。因此共享表空间可能会变的很大,默认情况下,也就是undo 日志使用共享表空间的时候,被“撑大”的共享表空间是不会也不能自动收缩的。因此,mysql5.7之后的“独立undo 表空间”的配置就显得很有必要了。
18.3 bin log
作用:用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。用于数据库的基于时间点的还原。
内容:为mysql server层所有,可追加写入sql语句
逻辑格式的日志,可以简单认为就是执行过的事务中的sql语句。
但又不完全是sql语句这么简单,而是包括了执行的sql语句(增删改)反向的信息,也就意味着delete对应着delete本身和其反向的insert;update对应着update执行前后的版本的信息;insert对应着delete和insert本身的信息。
因此可以基于binlog做到类似于oracle的闪回功能,其实都是依赖于binlog中的日志记录。
产生时机:
事务提交的时候,一次性将事务中的sql语句(一个事物可能对应多个sql语句)按照一定的格式记录到binlog中。
这里与redo log很明显的差异就是redo log并不一定是在事务提交的时候刷新到磁盘,redo log是在事务开始之后就开始逐步写入磁盘。
因此对于事务的提交,即便是较大的事务,提交(commit)都是很快的,但是在开启了bin_log的情况下,对于较大事务的提交,可能会变得比较慢一些。
这是因为binlog是在事务提交的时候一次性写入的造成的。
释放时机:
binlog的默认是保持时间由参数expire_logs_days配置,也就是说对于非活动的日志文件,在生成时间超过expire_logs_days配置的天数之后,会被自动删除。
物理文件:
配置文件的路径为log_bin_basename,binlog日志文件按照指定大小,当日志文件达到指定的最大的大小之后,进行滚动更新,生成新的日志文件。
对于每个binlog日志文件,通过一个统一的index文件来组织。
18.4 redo log 与bin log 对比
- redo log保护事务的持久性,是事务方面,binlog作为还原功能是数据库层面。保护数据的层次不一样。
- redo log是物理日志,bin log是逻辑日志。两者产生实际,释放时间,可释放情况下的清理机制不同,恢复时基于物理日志的redo log效率高于基于逻辑日志的bin log。
- 关于事务提交时,为了保证主从复制时候的主从一致,MySQL通过两阶段提交过程来完成事务的一致性的,也即redo log和binlog的一致性的,理论上是先写redo log,再写binlog,两个日志都提交成功(刷入磁盘),事务才算真正的完成。
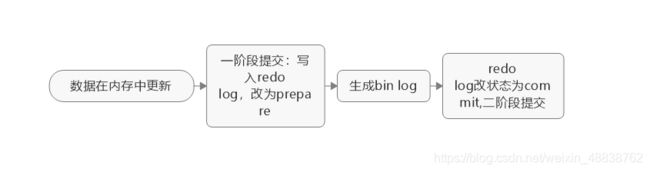
19.Update/delete/LSN
19.1 update 执行流程
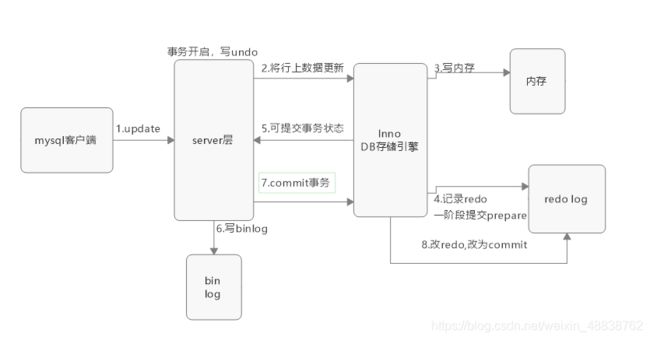
-
客户端发出update请求,并向mysql服务建立连接
-
mysql连接器负责和客户端建立连接获取权限,维护连接
-
查询缓存,是否之前执行过(此项默认不开启,且8.0以上已废弃)
1.命中缓存,返回key-value
2.未命中,执行真正的sql
-
分析器做词法分析,识别关键字update,表名等;之后做语法分析,是否符合sql语法
-
优化器选择索引(多表还会选择表的连接顺序)
-
mysql服务端的执行器调用引擎的接口执行sql
-
事务开始(任何一个操作都是事务),写undo log,记录上个版本的数据,并更新记录的回滚指针和事务id
-
执行器先调用引擎获取where条件这一行数据(索引)
1.如果这行所在的页本来就在内存中,直接返回给执行器更新
2.不在内存中,判断索引是否为唯一索引
1).唯一索引:InnoDb读取数据页到内存(需要进行是否违反唯一性约束判断),不写入change buffer
2).非唯一索引:InnoDb将更新操作缓存于change buffer,当发生merger操作时,才读入内存进行更新
-
执行器拿到引擎给的数据,修改这行数据,再调用引擎写入新数据
-
引擎将数据写入内存,同时更新操作到redo log,这时redo log进入prepare状态,相当于告诉执行器,执行完成,可以commit
-
执行器收到通知,生成这个操作的bin log(有自己的刷盘策略,事务提交时产生,并刷入磁盘)
-
执行器调用引擎的提交事务接口,并将redo log 改为commit状态(redo log也有相应的刷盘策略)
-
更新完成
19.2 select查询过程

SQL查询的执行过程:
1.客户端发送一条查询给服务器;
2.服务器通过权限检查之后,先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
3.服务器端进行SQL解析、预处理,再由优化器根据该SQL所涉及到的数据表的统计信息进行计算,生成对应的执行计划;
4.MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
5.将结果返回给客户端。
注意:
查询优化器:写的任何sql,到底是怎么样真正执行的,按照什么条件查询,最后执行的顺序,可能都会有多个执行方案
查询优化器根据对数据表的统计信息(比如索引有多少条数据)在真正执行一条sql之前,会根据自己内部的数据,进行综合的查询,根据mysql自身的统计信息,从多种执行方案当中,选择一个它认为是最优的执行方案,来去执行。得出执行方案,才会给执行引擎。
关键点:1.先写内存,再写日志文件,2.先写redo log 再写bin log 3.刷盘是先刷日志,再刷数据
19.3 InnoDb在修改语句中的LSN流程
- 修改内存中的数据页,在数据页中记录LSN
- 在修改页的几乎同时,在redo_log_buffer写入redo_log记录LSN
- redo log 触发写盘规则,磁盘的redo log记录LSN
- checkpoint点,检查点会触发数据页和日志页刷盘 ,在本次checkpoint脏页刷盘结束时,磁盘上redo log和数据页中记录checkpoint的LSN位置
- 中途刷入的每个数据页都会记下当前页所在的LSN。
19.4delete/update操作内部机制
delete:不会直接删除,而是将delete的对象打上delete flag,标记删除,最终的删除操作是purge线程完成的
update:1.不是主键列,undo log记录反向update和update直接执行
2. 是主键列:先删除该行,再插入目标行
三、索引/视图/存储过程
1.索引
1.一般来说,索引本身也很大,索引往往以文件的形式存储到磁盘上
2.索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录.所以索引也是要占磁盘空间的
3.虽然索引提高了查询速度,但是会降低更新表的速度,
因为更新表时,MYSQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,
4.会调整因为更新所带来的键值变化后索引的信息
1.1 hash索引
检索效率高,索引的检索可以一次定位,但功能有限,支持也有限。适用于定值查找:“=”,“IN”,"<=>"。
原理:
对于每一行数据,存储引擎都会对所有索引列计算一个哈希码,哈希码是一个较小的值,不同键值的行计算出的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时保存指向每个数据行的指针。 如果多个列的哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中去。哈希表中哈希码是顺序的,导致对应的数据行是乱序的。
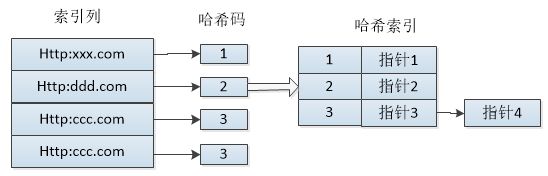
哈希索引限制:
-
哈希索引只保存哈希码和指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过访问内存中的行速度非常快(因为是MEMORY引擎),所以对性能影响并不大
-
哈希索引数据并不是按照索引值顺序存储的,所以无法用于排序
-
哈希索引不支持部分索引列查找,因为哈希索引始终是使用索引列的全部内容来计算哈希码。如,在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法使用该哈希索引
-
哈希索引只支持等值比较查询,包括=、IN()、<=>,不支持范围查询,如where price > 100
-
哈希冲突(不同索引列会用相同的哈希码)会影响查询速度,此时需遍历索引中的行指针,逐行进行比较。
-
如果哈希冲突很多,一些索引维护操作的代价会很高。如果从表中删除一行,需要遍历链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。

总结:哈希索引限制多,只适用于一定的场合。而一旦适合哈希索引,它带来的性能提升将非常显著。
1.2.B-Tree、B+Tree索引
扩展:数据结构
B-Tree:每一个节点都会去磁盘找数据
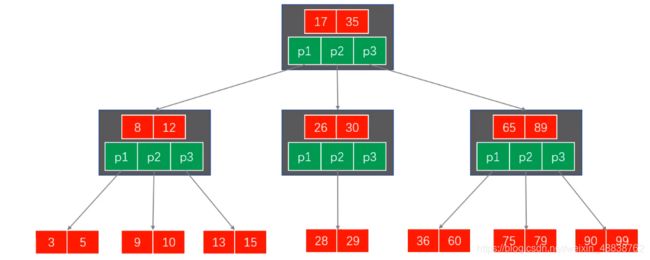
B+Tree:直接到叶子节点采取磁盘找数据

需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问。适用于范围查找。
采用B+Tree做为主流索引数据结构的原因:
1.更适合用来做存储索引
2.B+树的磁盘读写代价更低
内部的结构并没有指向关键字的具体指针
不存放数据,只存放索引信息
内部节点相对B树更小
3.B+树的查询效率更加稳定
内部节点并不是最终指向文件内容的节点,只是叶子节点中关键字的索引,所以它任何关键字的查找,必须走一条从根节点到叶子节点的路
所有关键字查询的长度相同,导致每一个数据查询的效率也几乎是相同
4.B+树更有利于对数据库的扫描。
B树在提高IO性能同时,并没有解决元素遍历效率底下问题
B+树只需要遍历叶子节点,就可以解决对全部关键字信息的扫描对数据库中,频繁使用的范围查询,性能更高(B+TREE叶子节点是通过链接关键的,不用返回上一个节点查询)
1.3 自定义哈希索引
在InnoDB中,某些索引值被使用的非常频繁的时候,它会在内存中基于B+Tree的基础上再创建一个哈希索引,使其不必要在从根节点就行查找。完全自动的内部行为,用户无法配置或更改。
使用场景:为超长的键创建哈希索引。列值太长,导致索引体积过大,查询速度也会受到影响。
创建思路: 增加一个额外哈希列,将列值映射成哈希值,对哈希列进行再进行索引。在where条件处手动指定使用哈希函数。
例子1:列B还是利用B+Tree索引进行查找,只不过我们是利用哈希值而不是列键本身进行索引。
select * from table where 列B=hash('xxxxx')and 列A='xxxxx';
例子2:使用mysql自带的CRC32函数对url做哈希处理,就可以使用下面的函数查询,需要手动维护CRC32( )列;
select * from url_hash where url_crc=CRC32('https://blog.csdn.net/qq' ) and url='https://blog.csdn.net/qq'
注意:
1、where语句中必须包含url,避免哈希冲突。
2、mysql同时提供了SHA1()、MD5()两个加密函数,不要使用这两个函数做哈希函数,他们是强加密函数,设计目标是最大限度消除冲突,但计算的哈希值很长,浪费空间且有时更慢。哈希冲突只要在一个可接受的范围内对性能影响并不大。
1.4创建索引的情况
1.主键自动建立唯一索引:primary
2频繁作为查询条件的字段应该创建索引 :比如银行系统银行帐号,电信系统的手机号
3.查询中与其它表关联的字段,外键关系建立索引
4.查询中排序的字段,排序的字段若通过索引去访问将大提升排序速度。
5.查询中统计或分组的字段
6.频繁更新的字段不适合建立索引
7.where条件里用不到的字段不建立索引
8.记录比较少不适合建立索引
9.经常增改的表不适合建立索引
10.数据重复的表字段不适合建立索引
2.视图
视图就是虚表,视图的创建来自select语句,比如多表的连表查询sql语句复杂可以建立一个视图。视图只能查询,不能插入数据。
allemp本身没有数据,数据来自于后面的查询语句
create view allemp as select ... (后面是连表查询语句)
查看视图:
select *from `information_schema`.`views`;
3.存储过程
3.1 存储过程变量
创建一个简单的存储过程:
mysql> use test_lfh;
mysql> delimiter $$
mysql> create procedure testa()
-> begin
-> select * from itpuxt02;
-> select * from itpuxz04;
-> end;
-> $$
mysql> delimiter ;
mysql> call testa();
也可通过客户端,函数去创建存储过程;
CREATE DEFINER=`root`@`%` PROCEDURE `text_xxx`()
BEGIN
DECLARE my_name VARCHAR(32) DEFAULT ''; --声明变量
SET my_name ='lfh';
SELECT name INTO my_name FROM itpuxt02 WHERE id =1;
SELECT my_name;
END;
1.变量的声明使用declare,一句declare只声明一个变量,变量必须先声明后使用
2.变量具有数据类型和长度,与mysql的sQL数据类型保持一致,因此甚至还能指定默认值、字符集和排序规则等
3.变量可以通过set来赋值,也可以通过select into的方式赋值
4.变量需要返回,可以使用select语句,如: select变量名
调用存储过程:
call text_xxx;
一个存储过程可以套用格式如:
CREATE DEFINER=`root`@`%` PROCEDURE `text_xxx`()
BEGIN
...定义在外层的变量为全局变量,每个begin/end块都可以用。
BEGIN
...定义在每个begin/end中的是局部变量,只在当前begin/end有效
DECLARE my_name VARCHAR(32) DEFAULT ''; --声明变量
SET my_name ='lfh';
SELECT name INTO my_name FROM itpuxt02 WHERE id =1;
SELECT my_name;
END;
BEGIN
...
END;
END;
1.变量是有作用域的,作用范围在begin与end块之间,end结束变量的作用范围即结束。
2.需要在多个代码块中传递值,可使用全局变量,即放在所有代码块之前。
3.传参变量是全局的,可以在多个块间起作用
3.2存储过程传入的参数
IN参数:用于传入
可以通过传入参数作为条件进行存储过程的查询;如:
IN test_id int
1.传入参数︰类型为IN,表示该参数的值必须在调用存储过程时指定,如果不显式指定为IN,那么默认就是IN类型。
2.IN类型参数一般只用于传入,在调用存储过程中一般不作修改和返回
3.如果调用存储过程中需要修改和返回值,可以使用OUT类型参数
OUT参数:用于传出
IN test_id int,OUT test_name varchar(32)
参数可以一次定义多个,中间用“,”隔开
创建传入参数的过程:
CREATE DEFINER=`root`@`%` PROCEDURE `testa`(IN test_id int,OUT test_name VARCHAR(32))
begin
select name into test_name from itpuxt02 WHERE id =test_id;
SELECT test_name;
end
调用:
call testa(2,@y)
1.传出参数:在调用存储过程中,可以改变其值,并可返回
2.OUT是传出参数,不能用于传入参数值
3.调用存储过程时,OUT参数也需要指定,但必须是变量,不能是常量
4.如果既需要传入,同时又需要传出,则可以使用INOUT类型参数
INOUT:用于传入和传出 存储过程可变的参数
创建INOUT存储过程:
CREATE DEFINER=`root`@`%` PROCEDURE `testa`(INOUT test_id int,INOUT test_name VARCHAR(32))
begin
set test_id =1;
select id,name into test_id,test_name from itpuxt02 WHERE id =test_id;
end
调用:
call testa(@id,@name)
SELECT @id as id ,@name as name;
1.可变变量INOUT∶调用时可传入值,在调用过程中,可修改其值,同时也可返回值。2.INOUT参数集合了IN和OUT类型的参数功能
3.INOUT调用时传入的是变量,而不是常量
3.3 存储过程条件语句
CREATE DEFINER=`root`@`%` PROCEDURE `testIf`(IN my_id int)
BEGIN
DECLARE my_name VARCHAR(32) DEFAULT '';
if(my_id%3=0)
then
SELECT name into my_name FROM itpuxt02 WHERE id = my_id;
SELECT my_name;
elseif(my_id%3=0)
then
SELECT my_id;
else
SELECT my_id;
end if;
END
call testIf(2);
1.条件语句基本结构:
if()
then
....
else
....
endif;
2.多条件判断结构︰
if()
then
....
elseif()
then
....
else
....
end if
3.4存储过程循环语句
while语句最基本的结构:
while() do
...
end while;
while判断返回逻辑真或者假,表达式可以是任意返回真或者假的表达式
repeat语包最基本的结构:repeat
...
until ...
end repeat;
until半断返回逻辑真或者假,表达式可以是任意返回真或者假的表达式只有当until语句为真时,循环结束。
3.5 存储过程游标
CREATE DEFINER=`root`@`%` PROCEDURE `testCursor`()
BEGIN
DECLARE stopflag INT DEFAULT 0;
DECLARE my_name VARCHAR(32) DEFAULT '';
DECLARE uname_cur CURSOR FOR SELECT name from itpuxt02 WHERE id%2=0;
DECLARE CONTINUE HANDLER FOR NOT found set stopflag =1;
OPEN uname_cur;
FETCH uname_cur INTO my_name;
WHILE(stopflag=0) DO
BEGIN
UPDATE itpuxt02 SET name =CONCAT(my_name,'_cur') WHERE name = my_name;
FETCH uname_cur INTO my_name;
END;
END WHILE;
CLOSE uname_cur;
END
四、性能调优
1.优化分析
1.1分析
1.查询语句写的不好:各种连接,各种子查询导致用不上索引或者没有建立索引
2.建立的索引失效:建立了索引,在真正执行时,没有用上建立的索引
3.关联查询太多join
4.服务器调优及和个配置参数导致:如果设置的不合理比例不恰当,也会导致性能下降,sqI变慢
1.2三大范式与表设计准则
三大范式:
1.是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值:第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库
2.要求数据库表中的每个实例或行必须可以被惟一地区分:设置主键
3.要求一个数据库表中不包含已在其它表中已包含的非主关键字信息:两张表不要重复的字段,通常都是设置外键
注意:有些时候会违法第三范式,将其他表一些常用的信息直接拿过来。
表设计准则:
大表拆小表,有大数据的列单独拆成小表:
在一个数据库中,一般不会设计属性过多的表;
在一个数据库中,一般不会有超过500/1000万数据的表拆表
有大数据的列单独拆成小表(富文本编辑器,CKeditor);
1.3 优化的实质
根据以上章节做的sql语句查询流程分析:做优化,就是想让查询优化器按照我们的想法,帮我们选择最优的执行方案,让优化器选择符合程序员计划的执行语句,来减少查询过程中产生的IO。
1.4 MYSQL常见瓶颈
1.CPU饱和
2.磁盘I/0读取数据大小(主要考虑的方向)
3.服务器硬件比较低
2.Explain
2.1简介&作用
查询执行计划:
使用explain关键字,可以模拟优化器执行的SQL语句
从而知道MYSQL是如何处理sql语句的
通过Explain可以分析查询语句或表结构的性能瓶颈
作用:
查看表的读取顺序
数据读取操作的操作类型
查看哪些索引可以使用
查看哪些索引被实际使用
查看表之间的引用
查看每张表有多少行被优化器执行
2.2使用
- sql语句前加上EXPLAIN
EXPLAIN SELECT * FROM itpuxt02;

字段解释:
2.2.1 id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
值的三种情况:
1.id相同,执行顺序由上到下
EXPLAIN SELECT * FROM itpuxt02 i1 LEFT JOIN itpuxz01 i2 on i1.id=i2.id;

2.id不同(包含子查询的情况),执行顺序是从大到小的执行,id值越大,优先级越高
3.id相同不同,同时存在(子查询+连表查询情况)
2.2.2 select_type
查询类型,主要用于区别普通查询,联合查询,子查询等复杂查询
- SIMPLE :简单select查询,查询中不包含子查询或者UNION
PRIMARY: 查询中若包含任何复杂的子查询,最外层查询则被标记为primary
SUBQUERY :查询中的子查询标记
DERIVED :在from列表中包含的子查询被标记为derived(衍生),将结果放在临时表
UNION:从union表获取结果select
UNION RESULT :从union表获取结果select,两个UNION合并的结果集的临时表类型
2.2.3 table
当前查询数据是关于哪张表的
2.2.4 partitions
如果真询是基于分区表的话,会显示查询访问的分区
2.2.5 type(重点)(做到range最好ref)
- system:表中有一行记录(系统表)这是const类型的特例,平时不会出现
- const:表示通过索引一次就找到了,const用于比较primary 或者unique索引.直接查询主键或者唯一索引因为只匹配一行数据,所以很快(唯一索引,给的条件值是一个常量)
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配常见于主键或唯一索引扫描(两个表的唯一索引扫描匹配,查询的结果一一对应)
EXPLAIN SELECT * FROM itpuxt02 i1,itpuxz01 i2 WHERE i1.id=i2.id;
- **ref:**非唯一性索引扫描,返回匹配某个单独值的所有行本质上也是一种索引访问,它返回所有匹配某个单独值的行,可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体(where条件不是唯一索引,存在一对多的情况)
EXPLAIN SELECT * FROM itpuxt02 i1,itpuxz01 i2 WHERE i1.id=i2.t_id;
- **range:**范围查找
EXPLAIN SELECT id FROM itpuxt02 i1 WHERE i1.id>2;
-
index:通过索引进行扫描(查询的列直接是一个索引)
-
ALL:进行的是全表的扫描,此时应当去做一个sql优化
2.2. 6possible_keys(与key共同判断索引是否失效)
可能用到的索引、可以使用哪些索引(可能是select *导致)
2.2.7 key
实际使用的索引,possible_keys与key关系理论应该用到哪些索引实际用到了哪些索引覆盖索引查询的字段和建立的字段刚好吻合,这种我们称为覆盖索引。
2.2.8 key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引长度.(使用复合索引的情况,判断索引是否失效或者用到复合索引的哪些索引)
2.2.9 ref
索引是否被引入到到底引用到了哪几个索引(索引引用的是哪个表的哪个字段)
也可能是const,(where条件)引用的直接是一个常量,固定值。
2.2.10 rows(越少越好)
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
查询指定数据时,每张表有多少行被优化器查询过
没有建立索引和建立了索引后可进行对比,看出效率情况。
2.2.11 filtered
满足查询的记录数量的比例,注意是百分比,不是具体记录数,值越大越好,filtered列的值依赖统计信息,并不十分准确。(100%表示所查询的数据,全部使用的索引,扫描时命中率不一样)
2.2.12 Extra
-
Using filesort(这种情况需要立马优化)
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行
Mysql中无法利用索引完成排序操作称为"文件排序”, -
Using temporary(这种情况需要立马优化)
使用了临时表保存中间结果,Mysql在对查询结果排序时,使用了临时表,常见于排序orderby 和分组查询group by
-
use index
使用了索引
-
using where
使用了条件
-
using join buffer
使用了连接缓存
-
impossible where(这种情况需要立马优化)
where子句的值总是false 不能用来获取任何元组
3.索引原则(尽量不用*)
1.全词匹配(最好)
建立的复合索引,全部都用上了
CREATE INDEX idx_3 on itpuxt02(age,name,yx);
#全词匹配
EXPLAIN SELECT * FROM itpuxt02 WHERE age =1 and name='r_cur01' and yx='gt';
2.最佳左前缀法则
如果索引的多列(复合索引),要遵守最左前缀法则,指的就是从索引的最左列开始并且不跳过索引中的列,跳过第一个,索引失效,跳过前两个,索引失效,跳过中间一个,只有第一个生效,顺序可以乱。
3.不在索引列做任何操作
计算,函数,类型转换,会导致索引失效而转向全表扫描
错误示例:
EXPLAIN SELECT * FROM itpuxt02 WHERE trim(name)='r_cur01';
4.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
5.is not null无法使用索引
where条件使用is not null索引失效
6.用or连接时,会导致索引失效
7.like以通配符开头(%qw)索引失效变成全表扫描
like使用不恰当会导致索引失效
8.自动类型转换会导致索引失效
错误示例:(字符串不加单引号)
EXPLAIN SELECT * FROM itpuxt02 WHERE name=200;
9.尽量使用覆盖索引(使用覆盖索引解决以上问题)
覆盖索引查询的字段和建立索引的字段刚好吻合,这种我们称为覆盖索引
这种方式可以一定程度以上描述的索引失效问题,比如又想使用模糊查询,又想使用索引,可以尝试覆盖索引。
正确示例:用name,age字段建立索引。模糊查询索引字段解决索引失效问题
EXPLAIN SELECT name,age FROM itpuxt02 WHERE name like '%o_cur%';
4.排序优化
4.1. 在使用order by时,经常出现Using filesort
索引仅做为排序条件时,作为排序的索引用不上;
使用order by排序时,排序的条件如果没有按照组合索引的顺序,会出现Using filesort
错误示例:Using filesort
EXPLAIN SELECT age,name,yx FROM `itpuxt02` WHERE age >3 ORDER BY name;
当使用*时order by即使使用了全部索引,也会filesort
当索引字段为常量时可以当作是存在索引的
正确示例:age常量,组合索引顺序写
EXPLAIN SELECT age,name,yx FROM `itpuxt02` WHERE age =3 ORDER BY name,yx;
使用排序一升一降会造成filesorte
错误示例:一升一降,即使顺序正确也造成filesorte
EXPLAIN SELECT age,name,yx FROM `itpuxt02` WHERE age =3 ORDER BY name,yx;
4.2使用group by时,使用不当,会出现Using temporary
(规则和上面基本一样因为分组前必排序)
假设建立复合索引(a,b,c),请说出以下条件是否使用到了索引及使用情况:
where a=4 使用到了索引a
where a = 4 and b= 6;使用到了索引a,b
where a = 4 and c = 5 and b = 6; 。使用到了a,b,c
where b = 4 or b=5;没有使用到索引
where a = 4 and c = 6;·使用到了索引a
where a = 4 and b > 5 and c=6;使用到索引a,b
where a = 4 and b like 'test%' and c=4;使用到了a,b kk%相当于范围
where a = 4 order by b,c 使用到了a,不会有filesort
where b = 5 order by a 没用到索引会有filesort
where b = 5 order by c 没有索引,会有filesort
where a = 5 group by c,b 使用到了索引a,造成Using temporary;换成b,c就不会造成Using temporary
5.分页查询优化(构建大量数据)
5.1带来问题
SELECT * from `itpuxt02` LIMIT 990000 ,10;
如上:当查询的开始条数越大时,查询时长明细增加,他会将前面的记录数全查出来,再去查990000开始的10条数据
5.2分页查询优化-使用子查询
- 尽量使查询走索引,select后面写索引列,比如查出id,避免*
- 使用查出来的id,子查询缩小查询范围,让最耗时的部分走索引,然后查询出需要的全部数据;示例:
SELECT * from itpuxt02 t INNER JOIN
(SELECT id from itpuxt02 t LIMIT 990000 ,10) tmp on t.id = tmp.id;
SELECT *from itpuxt02
where id >(SELECT id from itpuxt02 t LIMIT 990000 ,1)LIMIT 10;
5.3使用id限定优化(要求查询时传入id,且建表时id自增的)
记录上—页最大的id号,使用范围查询
限制是只能使用于明确知道id的情况,不过一般建立表的时候,都会添加基本的id字段,这为分页查询带来很多便利
select * from itpuxt02 where id between 1000000 and 1000100 limit 100;
select * from itpuxt02 where id >= 1000001 limit 100;
6.最大值max优化
主要影响参数row;错误示例:age不是索引,查询时间长,正确做法:为age创建索引
EXPLAIN SELECT max (age) from itpuxt02;
7.统计count使用注意点
count(*),统计所有列,包含null
count(name),统计索引列,不包含*;或者:
select count(name or name is null) from itpuxt02;
8.小表驱动大表
8.1.实质
数据库操作最耗时的就是链接操作,小表驱动大表就是减少链接
SELECT * from itpuxt02 where id in (SELECT id from itpuxt03);
8.2 in与exists的选择(可互换)
SELECT * from itpuxt02 where id in(SELECT id from itpuxt03) ;
(小表驱动大表)
伪代码:
for SELECT id from itpuxt03 d
for SELECT * from itpuxt02 e where e.id = d.id;
SELECT * from itpuxt02 e where EXISTS (SELECT 3 from itpuxt03 d where e.id = d.id );(大表驱动小表)
伪代码:
for SELECT * from itpuxt02 e
for SELECT *from itpuxt03 d where e.id = d.id
当A表中数据多于B表中的数据时,这时我们使用IN优于EXISTS
当B表中数据多于A表中的数据时,这时我们使用EXISTS 优于IN
因此是使用IN还是使用EXISTS就需要根据我们的需求决定了。但是如果两张表中的数据显差不多时那么是使用N还是使用EXSTS差别不大
EXISTS子查询只返回TRUE或FALSE,因此子查询中的SELECT *可以是SELECT 1或者其他
9.锁相关
9.1锁分类
按操作:
-
读锁(共享锁)
-
写锁(排它锁)
按粒度分:
-
表锁
-
行锁
-
页锁
9.2表锁(一般用在读数据多时)
1.偏向MYISAM存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发最底
2.整张表就只能一个人使用
3.查看表加锁情况:(In_use参数)
show open tables;
4.加锁
lock table tableName read;
lock tabletableName write;
5.解锁
unlock tables;
6.读写锁对操作和性能产生哪些影响
1.对表加上读锁后:lock table tableName read;
当前链接:可以查看该表,不可以更改该表,没有释放锁之前也无法查看其他表
其他链接:可以查看该表,修改该表会处于阻塞状态,等待锁释放。可以读取其他表
2.对表加上写锁后:lock tabletableName write;
当前链接:可以读取该表,可以更改该表,不可以读取别的表。
其他链接:不可以读取该表,会阻塞。不可以更改该表,也会阻塞。可以读取其他表。
9.3行锁
1.偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁;锁定粒度最小,发生锁冲突的概率最底,并发度也最高
lnnoDB与MylSAM的最大不同点:一是支持事务,二是采用了行级锁
lnnoDB默认开启行锁。
2.行锁操作和性能产生哪些影响
当前连接:未提交事务之前,当前连接可以查看修改的内容,
其他链接:未提交事务之前,只能查看到修改前的内容,
一个链接更新一行数据未提交事务时,另一个连接的更新同一条数据会被阻塞。两个链接更新不同数据不影响。
3.索引失效,行锁会变成表锁
正常使用索引,两个链接修改不同行,不会变成表锁,但是索引失效之后,两个链接修改不同行会使用主索引,造成阻塞。、
9.4间隙锁
一个链接修改id为3到7之前的数据:未提交事务
update employee set name='000' where id>3 and id <7;
另一个链接再修改id为3-7之前的某行,会造成阻塞。
9.5如何在查询时值锁定一行
默认情况,在查询一行数据的时候,事务未提交,另一个连接可以对该行进行修改。
set autocommit =0;
select * from employee where id=1 for update;
#这样做就锁定的一行,事务未提交,其他链接不能对这行进行更新,会阻塞
commit;
9.6行锁等待时间查看(如果此项非常大,证明该检查sql语句)
show status like 'innodb_row_lock%';
9.7悲观锁与乐观锁
1.悲观锁:就是很悲观,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。悲观锁一般都是依靠关系数据库提供的锁机制,事实上关系数据库中的行锁,表锁不论是读写锁都是悲观锁
2.乐观锁:顾名思义,就是很乐观,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现,不会发生并发抢占资源,只有在提交操作的时候检查是否违反数据完整性
3.为什么要使用乐观锁呢:
对于读操作远多于写操作的时候,大多数都是读取,这时候一个更新操作加锁会阻塞所有读取,降低了吞吐量。最后还要释放锁,锁是需要一些开销的,我们只要想办法解决极少量的更新操作的同步问题。
换句话说,如果是读写比例差距不是非常大或者你的系统没有响应不及时,吞吐量瓶颈问题,那就不要去使用乐观锁,它增加了复杂度,也带来风险。
4.乐观锁的实现方式:
- 版本号
- 时间戳
原理都是一致的,通过在表中增加一个字段,每次修改该行之前,取出该字段的值,更改的时候,对该字段值进行判断。如果字段值在取出之后没有改变过,就对该行进行更新,同时对该字段的值进行更新。如果更改时发现该字段的值变更过,就放弃修改。
五、主从复制、日志
1.主从复制
1.1 传统数据库存在的问题
1.传统数据库设计时,如果服务器宕机,将不能为用户提供服务导致整个系统崩溃.
2.如果数据库突然宕机.会导致数据丢失.
3.为了防止数据丢失,要进行实时备份
冷备份:通过数据库工具进行人为的导出sq.但是手动导出数据可能在中间节点宕机时也会造成数据库的丢失
1.2主从复制概念
主从复制:是用来建立一个和主数据库完全一样的数据库环境,称为从数据库
1.3主从复制的作用
1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失
⒉架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能
3读写分离,使数据库能支撑更大的并发。
1.4主从复制的原理
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作
- i/o线程去请求主库的binlog,并将得到的binlog日志写到relay log(中继日志)文件中;
- 主库会生成一个 log dump线程,用来给从库i/o线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;

1.5主从复制服务器配置
-
主机配置
1.首先修改mysql的配置文件,使其支持二进制日志功能。
打开主服务器的mysql配置文件: my.conf(window保存时,使用使用ANTIS格式,否则Mysql启动不起来)
加入如下代码:前两项必选,[mysqld] server-id=1 #必须主服务器ID唯一 log-bin=mysql-bin #启用二进制日志文件 read-only=0 #主机读写都可以 binlog-ignore-db=mysql #设置不要复制的数据库 binlog-do-db=设置需要复制的主数据库名字 #设置需要复制的数据库 log-err=/var/log/mysql/mysqlerr #启用错误日志(配置选) basedir=/usr #根目录(可选) temdir=/tmp#临时目录(可选) datadir=/var/lib/mysql #数据库目录(可选)2.重启服务:
systemctl stop mysqld.service systemctl start mysqld.servic3.在主服务器上为从服务器分配一个账号,就像一把钥匙,从服务器拿着这个钥匙,才能到主服务器上来共享主服务器的日志文件
//ip填写从服务器ip,backup是创建的mysql用户名 grant all on *.* to backup@'192.168.18.101'identified by '123456'; 或者: grant replication slave on *.* to backup@'192.168.18.101'identified by '123456';
FLUSH PRIVILEGES #backup用户名,从机要用
```shell
#mysql -u backup -p -h 192.168.18.88(输入密码123456,可以访问说明设置正确)
4.查看主服务器BIN日志的信息,当前在什么位置
show master status;
执行完之后记录下这两值,然后在配置完从服务器之前不要对主服务器进行任何操作,
因为每次操作数据库时这两值会发生改变
2.主从复制从机配置
- 进入从机修改配置文件
获取root最高权限(su 密码)
vim /etc/my.cnf
log-bin=mysql-bin
server-id=2
保存修改重启服务
systemctl stop mysqld.service
systemctl start mysqld.service
-
在从机mysq中执行以下语句
CHANGE MASTER TO MASTER_HOST='192.168.18.102',MASTER_USER='backup', MASTER PASSWORD='123456, MASTER LOG_FILE='读取值', MASTER LOG POS=读取值; #MASTER_HOST:主机ip #LOG_FILE:show master status 读取值 #POS:show master status 读取值 #配置关联master,3306可以默认不写,master_log_file参考之前记录的信息 -
先在从服务器配置完成,启动从服务器:
start slave; -
查看是否配置成功:
show slave status; 看到以下内容证明成功: Slave_IO_Running:Yes IO读取线程 Slave_SQL_Running: Yes 中继日志的SQL线程 -
停止服务复制
stop slave;
2.慢查询日志分析(分析执行耗时的sql语句)
2.1慢查询日志
- 概述:
1.MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句
2.具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
ong_query_time的默认值为10,意思是运行10S以上的语句。就会被认作是慢查询
3.默认情况下,Mysq数据库并不启动慢查询日志,需要我们手动来设置这个参数,
4.如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
5.慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
- 相关参数
查询慢查询日志是否开启:
show variables like '%slow_query_log%';
临时生效:
set global slow_query_log=1;
永久生效:my.cnf
slow query log =1
slow_query _log_file=地址
查看设置记录慢日志的时长:断开连接后才能失效
show variables like 'long_query_time';
set global long_query_time=4;
show global variables like 'long_query_time';
(查询睡眠)
select sleep(4)
show global status like '%slow_queries%';
2.2mysqldumpslow分析工具(当慢日志很多时使用工具找出最值得优化的sql)
返回慢日志中记录最多的10个sql:
mysqldumpslow -s r -t 10/var/lib/mysql/localhost_slow.log(慢日志文件路径)
2.3Show Profile(查看cpu,io消耗等)
1.Show Profile是mysq提供的可以用来分析当前会话中sq悟句执行的资源消耗情况的工具,可用于sql调优的测量。
2.默认情况下处于关闭状态,并保存最近15次的运行结果。
3.把一条sql在mysql当中每一个环节耗费的时候都记录下来
4.默认该功能是关闭的,使用前需开启。默认保存最近15次运行的结果
使用:
查看开启状态:
Show variables like 'profiling';
打开Show Profile:
set profiling = on;
执行sql后查看运行结果:
SELECT * FROM `itpuxt02`;
Show Profiles;
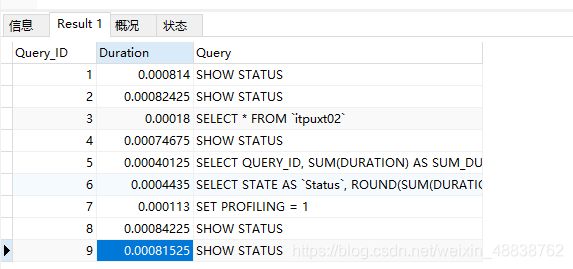
找到自己执行语句对应的Query_ID之后执行:查看该sql每一步的时间
show profile cpu, block io for query 3;
当以上参数出现这些时需要进行优化:
1.converting HEAP to MylsAM,查询结果太大,内存都不够用了,往确磁盘上存了
2.Creating tmp table创建临时表
- copy数据到临时表
- 用完再进行删除
3.Copying to tmp table on disk
1.把内存中临时表复制到磁盘,危险操作
4.Locked:被锁定
2.4 全局日志查询
1.只允许在测试环境用,不能在生产环境使用
2.在测试是,可以把所有执行的sql抓取出来查看
3.设置启用
set global general_log =1;
set global log_output = 'TABLE'; 结果输出到表中
此后所编写的sql语句将会记录到mysql库里的general_log表中
select *from mysql.general_log;(在linux命令行查看)
mysql -u root -p***** --default-character-set=utf8
补充:
1.解决脏读
修改时加排他锁,直到事务提交后才释放,读取时加共享锁,读取完释放,事务1读取数据时加上共享锁后(这 样在事务1读取数据的过程中,其他事务就不会修改该数据),不允许任何事物操作该数据,只能读取,之后1如果有更新操作,那么会转换为排他锁,其他事务更无权参与进来读写,这样就防止了脏读问题。
2.解决不可重复度
不可重复读:在同一事务中,两次读取同一数据,得到内容不同
mysql中,默认的事务隔离级别是可重复读(repeatable-read),为了解决不可重复读,innodb采用了mvcc(多版本并发控制)来解决这一问题。mvcc是利用在每条数据后面加了隐藏的两列(创建版本号和删除版本号),每个事务在开始的时候都会有一个递增的版本号
查询操作为了避免查询到旧数据或已经被其他事务更改过的数据,需要满足如下条件:
1、查询时当前事务的版本号需要大于或等于创建版本号
2、查询时当前事务的版本号需要小于删除的版本号
即:create_version <= current_version < delete_version
这样就可以避免查询到其他事务修改的数据
3.解决幻读
幻读:同一事务中,用同样的操作读取两次,得到的记录数不相同
- 在快照读读情况下,mysql通过mvcc来避免幻读。 undo log + MVCC
- 在当前读读情况下,mysql通过next-key来避免幻读:当前读是通过 next-key 锁(行记录锁+间隙锁)
普通读(也称快照读,英文名:Consistent Read),就是单纯的 SELECT 语句,不包括下面这两类语句:
SELECT … FOR UPDATE
SELECT … LOCK IN SHARE MODE
当前读,读取的是最新版本,并且需要先获取对应记录的锁,如以下这些 SQL 类型:
select … lock in share mode 、
select … for update、
update 、delete 、insert
获取什么类型的锁取决于当前事务的隔离级别、语句的执行计划、查询条件等因素。例如,要 update 一条记录,在事务执行过程中,如果不加锁,那么另一个事务可以 delete 这条数据并且能成功 commit ,就会产生冲突了。所以 update 的时候肯定要是当前读,得到最新的信息并且锁定相应的记录。