【kafka】Kafka中的高水位和Leader Epoch
概述
在kakfa的安装章节https://blog.csdn.net/margu_168/article/details/132695162中,在后面查看topic详情的时候我们可以看到有Partition、Leader、Replicas、Isr几个字段。其中的isr(in sync replicas)表示目前的主从副本,数量是我们可以配置的,只有ISR中的副本才有可能成为leader副本。
我们可以通过一些参数的配置,例如ack的确认、生产者重试、isr数量,消费者手动提交等方式来尽可能的保障Kafka的消息可靠性。
Kafka在保证数据的可靠性上使用的是“数据冗余”的方式,即将一个分区下的数据保存到多个副本中,起到数据备份的作用。这样如果leader挂了,会重新选举follower作为leader继续工作,那么Kafka中leader副本是如何将数据同步到follower副本中的呢?今天想通过这篇文章总结记录一下。
副本中的高水位(High Watermark)
高水位概念
在Kafka中,高水位是一个位置标记,它是用消息位移来表示的,比如某个副本中HW=5,就是这个副本的高水位在offset=5那个位置上。
LEO(Log End Offset)是消息末端位移,它也是用消息位移来表示的,表示下一条插入消息的位移值。高水位和 LEO(Log End Offset) 是副本对象的两个重要属性。Kafka 所有副本都有对应的高水位和 LEO 值,而不仅仅是 Leader 副本,注意是所有。只不过 Leader 副本比较特殊,Kafka 使用 Leader 副本的高水位来定义所在分区的高水位。换句话说,分区的高水位就是其 Leader 副本的高水位(主分区比较重要)。
已提交消息(可消费消息):生产者提交到broker
高水位(HW)的作用
在Kafka中,高水位的作用主要有2个。
-
定义消息的可见性,即用来标识分区下的哪些消息是可以被消费的。如下图该分区的HW(Leader的HW)是8,那么这个分区只有小于8 这些位置上消息可以被消费。即高水位之前的消息才被认为是已提交的消息,才可以被消费。
-
帮助Kafka完成副本同步
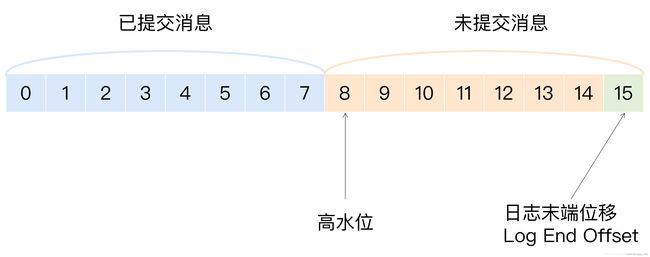
需要注意的是,位移值等于高水位的消息也属于未提交消息。也就是说,高水位上的消息就不能被消费者消费的。
上图中,HW是8,那么0-7属于已提交信息,可以被消费,LEO是15,即下一条新消息的位移是15,而中间的8-14这些位置上的消息属于未提交消息,不能被消费。同一个副本对象,其高水位值不会大于LEO值。
分区的高水位就是其leader副本的高水位。
Kafka 分区下有可能有很多个副本用于实现冗余,从而进一步实现高可用。副本根据角色的不同有以下3种:
- leader :相应 clients 端读写请求的副本;
- Follower :被动的备注 leader 副本的内容,不能相应 clients 端读写请求;
- ISR : 包含了 leader 副本和所有与 leader 副本保持同步的 Followerer 副本。
副本同步机制解析
首先我们先看一个例子

上面这张图,是follower向leader副本发送fetch(抓取)同步数据请求,此时他们的HW和LEO都是0。
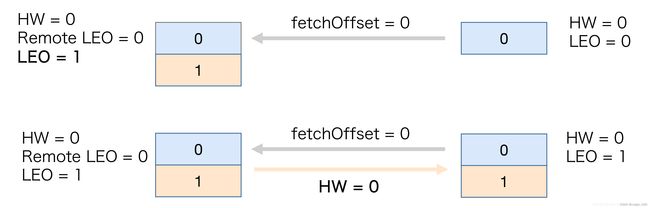
当生产者向leader发送一条消息,且提交成功后,leader的LEO更新为1,这个时候follower发现有消息可以拉取了,于是follower的LEO也更新为1,但是此时leader和follower的HW都为0,它们需要在下一次拉取中被更新。(LEO的更新早于HW)
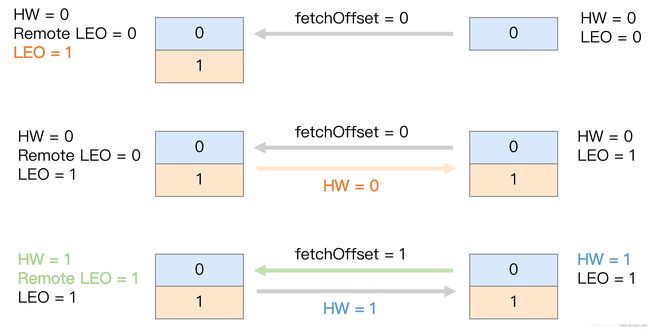
在下一次拉取请求中,因为之前位移值是0的消息已经拉取成功了,所以follower这次请求拉取的是位移值为1的消息。leader接收到这个请求后,将远程副本LEO更新为1,然后更新leader的HW=1,最后将HW=1发送给follower副本,follower收到后将自己的高水位值更新成1。至此,一次完整的消息同步周期就结束了。Kafka就是利用这样的机制,实现了leader和follower之前的同步。
通过高水位,Kafka既界定了消息的对外可见性,又实现了异步的副本同步机制。但是这里面还存在一些问题。刚才我们了解到的Kafka副本同步的过程中,follower副本的高水位更新需要下一次的拉取请求才能实现。如果有多个follower副本,就需要多轮拉取请求,对Leader的请求数量也会更多。也就是说,leader副本的高水位更新和follower副本高水位更新在时间上是存在一定延迟的,这样会导致数据丢失或者数据不一致。
消息数据丢失的场景

上图中副本A是leader,副本B是follower,现在情况是A的LEO和HW都是2,副本B中的LEO也更新成了2,但是HW还是1,它需要下一次请求来更新自己的HW,但是此时因为某些原因,B重启了,重启完后,B会执行日志截断功能,将LEO调整到它的高水位位置,即副本B的LEO变为了1,就是说副本B中位置为1的消息被删除了,现在只有一条消息了。
执行完截断操作后,副本B开始从A拉取消息,执行正常的消息同步。如果A正常,B其实会正常拉取A中位移为1的信息。但如果在这个时候,副本A所在的Broker宕机了,那么kafka只能选B成为新的leader了,当A重启回来后,需要执行相同的日志截断工作,将高水位调整为B的高水位值,因为规定follower的HW值不能超过leader中的HW值。A中的位移1位置的消息也被删除了,这样这条消息就丢失了。
消息数据不一致的场景
上图中副本A和B,其中副本A中有两条消息,LEO是2、HW是2,B的LEO和HW都是1,假设在同一时刻,A和B都宕机了,然后B先醒过来,那么B成了新的leader,然后他收到生产者发来的m3消息,然后B的LEO和HW都更新成了2。
当A醒过来后,会先根据HW判断是否需要进行日记截断,这里HW和LEO相等,发现不需要进行日志截断,然后跟B进行同步,这个时候A和B的LEO都是2,这样A中的消息是
Leader Epoch
Leader Epoch(时代,时期) 可以认为是leader的版本号,它由两部分数据组成。(版本号+首条位移值)
- Epoch,一个单调增加的版本号。每当副本Leader发生变更后,都会增加该版本号。小版本号的leader被认定是过期leader。
- 起始位移,leader副本在该Epoch值上写入的首条消息的位移。
假设现在有两个 Leader Epoch\(0, 0) 和 (1, 120),那么,第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 120 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 120。
Kafka Broker 会在内存中为每个分区都缓存 Leader Epoch 数据,同时它还会定期地将这些信息持久化到一个 checkpoint 文件中。当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存。如果该 Leader 是首次写入消息,那么 Broker 会向缓存中增加一个 Leader Epoch 条目,否则就不做更新。这样,每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,以避免数据丢失和不一致的情况。
Leader Epoch用途
Leader Epoch主要用于解决消息丢失和消息不一致的问题的(避免数据的丢失,不用依赖自己的高水位hw进行判断,而是去检查leader的LEO值)
消息数据丢失的问题

还是刚才上面的场景,现在有了Leader Epoch机制的介入,当副本B重启回来后,会向A发送一个请求去获取leader中的LEO,发现A的LEO=2,不比它自己的LEO(自己的LEO也是2)值小,而且缓存中没有保存任何起始位移值 > 2的Epoch条目,这样B就不需要执行日志截断操作了(也就是不需要阶段位置1的消息)。
然后副本A宕机了,B成为了leader,B的Leader Epoch由原来的<0, 0> 更新成了 <1, 2>,意思说是B成为了新的leader,版本号+1,这个leader的起始消息位移值为2。
A重启回来后会向B发送请求获取B的LEO,发现等于2,和自己相同,并且缓存中的Leader Epoch的起始位移值是2,也不需要进行日志截断。这样就不会出现消息丢失的问题了。
消息不一致
有了Leader Epoch机制的加入,当B变为leader后,Leader Epoch会更新为<1,1>,producer发送m3消息到B中,数据保存到磁盘上,然后当A重启后,会先发送请求知道B的LEO值为2和自己一样,然后通过缓存的Leader Epoch值,得知下一条要写入的消息是1的位置,然后就会进行日志截断,将原先的m2删除,并同步B的数据将m3写入。由此解决了消息不一致的问题。
以上都是一些极端情况,在实际使用中,应尽量避免这些场景发生。
更多关于kafka的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出