NLP(5)--自编码器
目录
一、自编码器
1、自编码器概述
2、降噪自编码器
二、特征分离
三、自编码器的其他应用
1、文本生成
2、图像压缩
3、异常检测
四、VAE
1、极大似然估计
2、GSM
3、GMM
4、VAE的引出
5、VAE
一、自编码器
1、自编码器概述
自编码器(Auto-Encoder)作为无监督学习的一种算法,自编码器中包含Encoder和Decoder紧紧相连的两个部分。首先将自编码器的输入的高维向量通过编码转变为低维度的隐变量,这一部分是编码器网络,然后将编码过的隐变量解码为高维度的输出向量,这一部分为解码器网络。
自编码器中没有标签信息,也不需要外界提供标签信息,而是通过最小化重构误差来学习数据的特征表示,Encoder的输出隐变量可以用来用于数据压缩、降维、特征提取的任务,也可以用于作为有监督学习任务的输入特征。
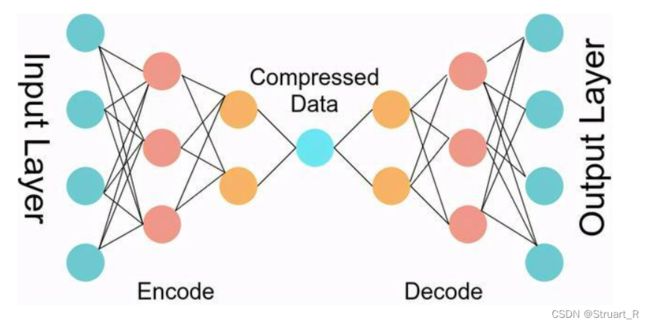
通俗的讲,输入向量经过Encoder变为难以理解的低位向量(特征)再经过Decoder转变为高维向量,自编码器输出的高维向量与输入的高维向量相比较,如果相似度越高,则证明模型效果更好。
另外Encoder和Decoder如果蕴含着深层次的神经网络结构,那么该编码器就是深度自编码器,可以用来提取更加深层次的非线性特征值。
下图是一个2006年的自编码器雏形,很好笑的points,一个是当时的深层网络要一层一层的去train,另一个是Encoder和Decoder都必须对称使用,在现在来看这些早就被突破了。

2、降噪自编码器
降噪自编码器(Denoising Auto-Encoder,DAE)通过对输入数据添加噪声,模型需强制根据带有噪声的输入向量找到数据中隐藏的真实信息(特征),这样防止模型对于输入数据过分依赖,避免了自编码器过去常常出现的过拟合现象。
相较于一般自编码器,降噪自编码器可以提高数据的抗干扰性,使得模型更具有鲁棒性,不依赖于数据本身,而注重数据特征,并且改善梯度消失的问题。
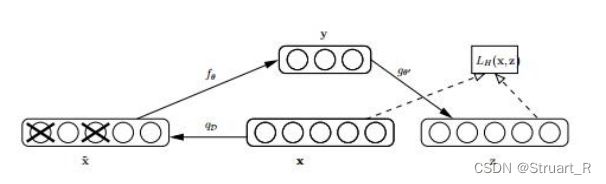
下图为降噪自编码器的图示,x为原始向量,![]() 是添加噪声的向量(输入向量),y为隐藏层(Encoder输出向量),z为降噪自编码器输出向量,计算x与z的相似度,越相似说明效果越好。
是添加噪声的向量(输入向量),y为隐藏层(Encoder输出向量),z为降噪自编码器输出向量,计算x与z的相似度,越相似说明效果越好。
二、特征分离
特征分离(Feature Distangle)有点类似于特征可解释化,旨在将隐变量的不同维度提取出来,让其可解释化。在深度学习中,通过设计一定的模型或算法,将输入数据中的不同特征分离解耦出来,从而在模型训练和应用中利用这些特征,提高泛化能力。
特征分离在图像分类中对于图像的颜色、纹理、形状的特征提取和音频迁移中对于声音音色、文本的提取有极大的价值。

下面的图就是通过特征分离形成的语音风格迁移。

三、自编码器的其他应用
1、文本生成
自编码器也可以用在文本生成模型,可以生成与输入文本相似的新文本,也可以用来生成各种烈性的文本。模型的隐藏层其实类似于对文章做了一个summary,Decoder再通过summary来生成一个相似的新文本,做到了无监督学习。
但这样的做法,有可能出现输入文本和自编码器输出文本可以不依靠文本特征,而是通过某些特定的数据,进行“对暗号”,有一点过拟合的感觉,所以,可以通过引入Discriminator来对summary进行评断。下图就是这样的解释。

2、图像压缩
利用自编码器进行图像压缩可以实现,可能由于高维转低维再转高维、模型容量限制、误差重构、数据分布缺乏多样性,导致出现失真的效果,如下图。
为了避免图像压缩中出现的失真效果,可以利用变分自编码器(VAE),生成对抗网络(GNN)来提供更好的图像生成和重构能力,或者利用更复杂的压缩算法技术来进行压缩。

3、异常检测
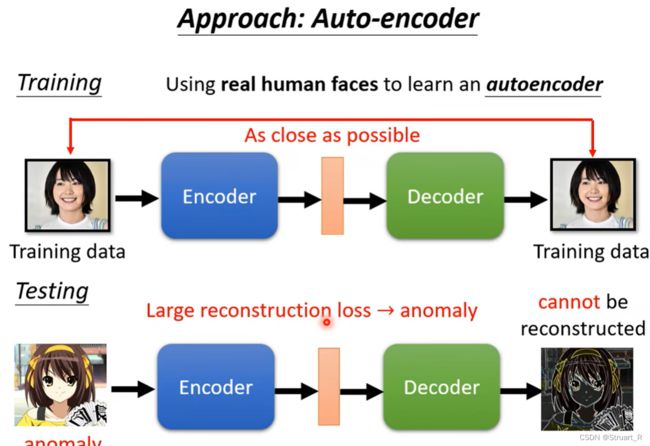
异常检测是一个很大的领域,可以识别出数据集中的异常事件和异常对象,但是可以使用自编码器做出一些应用,比如图像异常检测。
通过训练真人图像数据集的自编码器模型,测试中输入二次元图像与输出图像做相似度匹配,若相似度低则为异常值,做到了图像异常检测。
四、VAE
1、极大似然估计
极大似然估计是参数估计的一种方式,通过抽样一部分来估计整体的参数情况(比如方差、平均数)
极大似然估计的算法步骤如下:(来自百度)
PS:其他的建议看概率论详解

2、GSM
GSM(单高斯混合模型) ,其实就是正态分布模型。
一维概率密度分布如下:
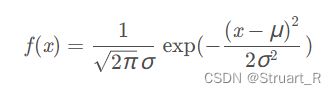
二维概率密度分布在图中表示集中于一个椭圆形,三维概率密度分布集中于一个椭球型。
3、GMM
GMM(混合高斯模型),其实就是多个高斯模型通过一定的权重后的融合,为了更为贴近拟合真实情况下的数据多样性。
混合高斯模型概率密度分布如下:

混合高斯模型由K个高斯模型组成,也就是K个类,其中 ![]() 表示第k个高斯模型概率密度函数,可以看成选定第k个模型后,产生x的概率。
表示第k个高斯模型概率密度函数,可以看成选定第k个模型后,产生x的概率。![]() 是第k个高斯模型权重,称作第k个模型的先验概率,满足
是第k个高斯模型权重,称作第k个模型的先验概率,满足![]() 。
。
详细介绍请参考:详解EM算法与混合高斯模型(Gaussian mixture model, GMM)_林立民爱洗澡的博客-CSDN博客
4、VAE的引出
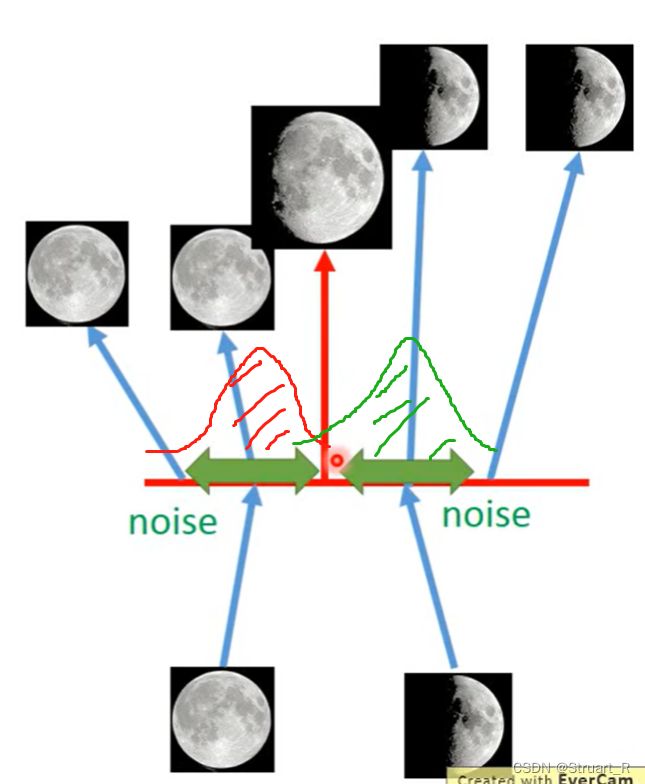
首先利用自编码器训练满月和弦月两个图像类,那么如果介于满月和弦月的隐变量的向量传给Decoder输出,是否可以有可能产生介于满月和弦月之间的月相图呢,答案是否定的,只会输出一个乱码一般的图像,因为编码离散性,所以最后的输出图像只能是离散的图像。

VAE做了哪些事呢,他在隐变量部分,加上了一部分噪声(而这个噪声就可以是混合高斯模型的) ,当训练满月和弦月模型时,也使用这各自(绿色箭头区域)的多个向量进行Decoder,这样训练出的Decoder就可以在中间失真点处生成3/4月相(红色箭头)。
5、VAE
变分自编码器(VAE)是一种基于概率的生成模型,相比于AE的离散空间分布,VAE引入了一个潜在变量来生成新的样本。
VAE的优点:
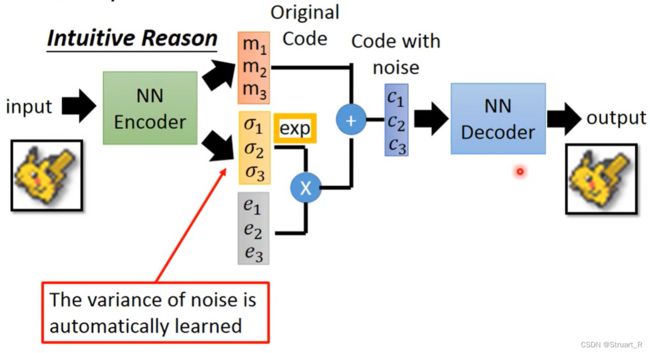
(1)相较于传统的自编码器通常将隐藏层的离散编码映射为离散图像pixel,所以图像离散化,而VAE引入了潜在变量,并假设变量服从高斯分布,也就是noise,经过noise处理的隐变量通过解码后就会得到连续的图像pixel,生成连续图像。
(2)VAE可以通过采样隐变量,生成多样性的样本,实现样本的多样性。
(3)VAE也可以对隐变量进行插值操作,获得合理的逐步过渡的图像。
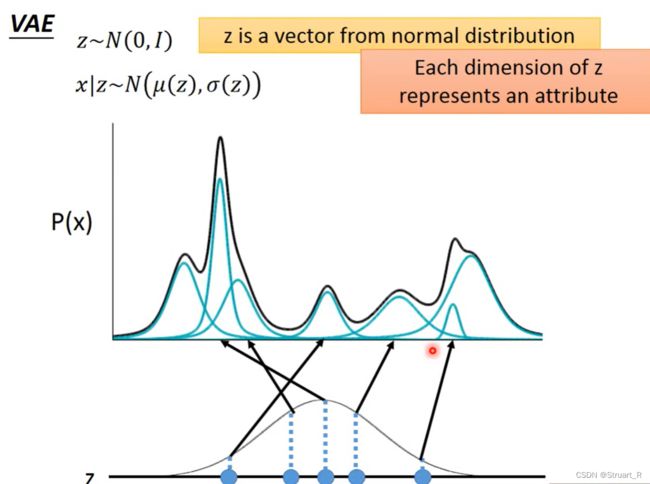
VAE分布映射中,VAE使用混合高斯模型 拟合生成噪声,可以看做是N个高斯噪声的混合。对应的一维向量就是连续变化的z,而根据z我们经过神经网络就可以求出μ(z)和σ(z)。
拟合生成噪声,可以看做是N个高斯噪声的混合。对应的一维向量就是连续变化的z,而根据z我们经过神经网络就可以求出μ(z)和σ(z)。
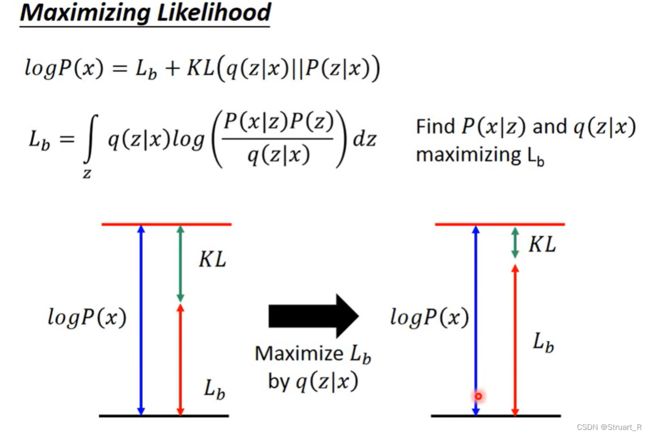
而如何估计 μ(z)和σ(z)的值呢就需要用到极大似然估计的知识。下面这一大段,博主已经迷糊了,下次再看吧。

下面是一个VAE论文中的数据流形可视化。

参考视频:第八节 2021 - 自编码器 (Auto-encoder) (上) – 基本概念_哔哩哔哩_bilibili