go语言---锁
什么是锁呢?就是某个协程(线程)在访问某个资源时先锁住,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。这和我们生活中加锁使用公共资源相似,例如:公共卫生间。
死锁
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,
死锁: 不是锁的一种!!!是一种错误使用锁导致的现象。
1. 单go程自己死锁
channel 应该在 至少 2 个以上的 go程中进行通信。否则死锁!!!
2. go程间channel访问顺序导致死锁
使用channel一端读(写), 要保证另一端写(读)操作,同时有机会执行。否则死锁。
3. 多go程,多channel 交叉死锁
Ago程,掌握M的同时,尝试拿N; Bgo程,掌握N的同时尝试拿M。
4. 在go语言中,尽量不要将 互斥锁、读写锁 与 channel 混用。 —— 隐性死锁。
//单go程自己死锁
ch := make(chan int) //channel
ch <- 789 //写 这里写入就会阻塞
num := <-ch //读
fmt.Println(num)
//go程间channel访问顺序导致死锁
ch := make(chan int)
num := <-ch //顺序不对,阻塞了,那么go就不执行了
fmt.Println(num)
go func() {
ch <- 789
}()
//多go程,多channel 交叉死锁
ch1 := make(chan int)
ch2 := make(chan int)
go func() { // 子
for {
select {
case num := <-ch1:
ch2 <- num
}
}
}()
for {
select {
case num := <- ch2:
ch1 <- num
}
}
4. 在go语言中,尽量不要将 互斥锁、读写锁 与 channel 混用。 —— 隐性死锁。
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var rwMutex sync.RWMutex //锁只有一把,两个属性
// 左写右读
// <-chan int 读
func readGo(in <-chan int, index int) {
for {
rwMutex.RLock() //以读模式加锁
num := <-in
fmt.Printf("----%dth 读 go程,读出:%d\n", index, num)
time.Sleep(time.Second)
rwMutex.RUnlock() //以读模式写锁
}
}
// chan<- int 写
func writeGo(out chan<- int, index int) {
for {
//生成随机数
num := rand.Intn(1000)
rwMutex.Lock() //以写模式加锁
out <- num //写进去
fmt.Printf("%dth 写go程,写入:%d\n", index, num)
time.Sleep(time.Millisecond * 300) // 放大实验现象
rwMutex.Unlock() //解锁
}
}
func main() {
// 播种随机数种子
rand.Seed(time.Now().UnixNano())
ch := make(chan int)
for i := 0; i < 5; i++ {
go readGo(ch, i+1)
}
for i := 0; i < 5; i++ {
go writeGo(ch, i+1)
}
for true {
}
}
互斥锁
每个资源都对应于一个可称为 “互斥锁” 的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待。
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁。
在使用互斥锁时,一定要注意:对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。如下所示:
var mutex sync.Mutex // 定义互斥锁变量 mutex
func write(){
mutex.Lock( )
defer mutex.Unlock( )
}
互斥锁:(互斥量)
A 、B go程 共同访问共享数据。 由于cpu调度随机,需要对 共享数据访问顺序加以限定(同步)。
创建 mutex(互斥锁),访问共享数据之前,加锁,访问结束,解锁。 在Ago程加锁期间,B go程加锁会失败——阻塞。
直至 A go程 解说mutex,B 从阻塞处。恢复执行。
package main
import (
"fmt"
"time"
"sync"
)
// 使用channel 完成同步
/*var ch = make(chan int)
func printer(str string) {
for _, ch := range str {
fmt.Printf("%c", ch)
time.Sleep(time.Millisecond * 300)
}
}
func person1() { // 先
printer("hello")
ch <- 98
}
func person2() { // 后
<- ch
printer("world")
}
func main() {
go person1()
go person2()
for {
;
}
}
*/
// 使用 “锁” 完成同步 —— 互斥锁
var mutex sync.Mutex // 创建一个互斥量, 新建的互斥锁状态为 0. 未加锁。 锁只有一把。
func printer(str string) {
mutex.Lock() // 访问共享数据之前,加锁
for _, ch := range str {
fmt.Printf("%c", ch)
time.Sleep(time.Millisecond * 300)
}
mutex.Unlock() // 共享数据访问结束,解锁
}
func person1() { // 先
printer("hello")
}
func person2() { // 后
printer("world")
}
func main() {
go person1()
go person2()
for {
;
}
}
读写锁
互斥锁的本质是当一个goroutine访问的时候,其他goroutine都不能访问。这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行执行变成了串行执行。
其实,当我们对一个不会变化的数据只做“读”操作的话,是不存在资源竞争的问题的。因为数据是不变的,不管怎么读取,多少goroutine同时读取,都是可以的。
所以问题不是出在“读”上,主要是修改,也就是“写”。修改的数据要同步,这样其他goroutine才可以感知到。所以真正的互斥应该是读取和修改、修改和修改之间,读和读是没有互斥操作的必要的。
因此,衍生出另外一种锁,叫做读写锁。
读写锁可以让多个读操作并发,同时读取,但是对于写操作是完全互斥的。也就是说,当一个goroutine进行写操作的时候,其他goroutine既不能进行读操作,也不能进行写操作。
GO中的读写锁由结构体类型sync.RWMutex表示。此类型的方法集合中包含两对方法:
一组是对写操作的锁定和解锁,简称“写锁定”和“写解锁”:
func (*RWMutex)Lock()
func (*RWMutex)Unlock()
另一组表示对读操作的锁定和解锁,简称为“读锁定”与“读解锁”:
func (*RWMutex)RLock()
func (*RWMutex)RUlock()
读写锁:
读时共享,写时独占。写锁优先级比读锁高。
读写锁—数据同步
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var rwMutex sync.RWMutex //锁只有一把,两个属性
var value int //定义全局变量,模拟共享数据
// 左写右读
// <-chan int 读
func readGo(index int) {
for {
rwMutex.RLock() //以读模式加锁 channel和读锁不能同时存在
num := value
fmt.Printf("----%dth 读 go程,读出:%d\n", index, num)
//time.Sleep(time.Second)
rwMutex.RUnlock() //以读模式写锁
}
}
// chan<- int 写
func writeGo(index int) {
for {
//生成随机数
num := rand.Intn(1000)
rwMutex.Lock() //以写模式加锁
value = num //写进去
fmt.Printf("%dth 写go程,写入:%d\n", index, num)
//time.Sleep(time.Millisecond * 300) // 放大实验现象
rwMutex.Unlock() //解锁
}
}
func main() {
// 播种随机数种子
rand.Seed(time.Now().UnixNano())
for i := 0; i < 5; i++ {
go readGo(i + 1)
}
for i := 0; i < 5; i++ {
go writeGo(i + 1)
}
for true {
}
}
读写锁—对应channel
package main
import (
"fmt"
"math/rand"
"time"
)
var value int //定义全局变量,模拟共享数据
// 左写右读
// <-chan int 读
func readGo(ch <-chan int, index int) {
for {
num := <-ch //从channel中读取数据
fmt.Printf("----%dth 读 go程,读出:%d\n", index, num)
time.Sleep(time.Second)
}
}
// chan<- int 写
func writeGo(ch chan<- int, index int) {
for {
//生成随机数
num := rand.Intn(1000)
ch <- num //写进去
fmt.Printf("%dth 写go程,写入:%d\n", index, num)
time.Sleep(time.Millisecond * 300) // 放大实验现象
}
}
func main() {
// 播种随机数种子
rand.Seed(time.Now().UnixNano())
ch := make(chan int)
for i := 0; i < 5; i++ {
go readGo(ch, i+1)
}
for i := 0; i < 5; i++ {
go writeGo(ch, i+1)
}
for true {
}
}
生产者消费者模型回顾
package main
import (
"fmt"
"math/rand"
"time"
)
// 左写
func producer(out chan<- int, index int) {
for i := 0; i < 50; i++ {
num := rand.Intn(800)
fmt.Printf("生产者%dth,生成:%d\n", index, num)
out <- num
}
close(out)
}
// 右读
func consumer(in <-chan int, index int) {
for i := range in {
fmt.Printf("-------消费者%dth,消费:%d\n", index, i)
//time.Sleep(time.Millisecond * 300)
}
}
func main() {
product := make(chan int)
rand.Seed(time.Now().UnixNano())
for i := 0; i < 5; i++ {
go producer(product, i+1)
}
for i := 0; i < 5; i++ {
go consumer(product, i+1)
}
for {
}
}
在上面的代码中,加了一个消费者,同时在consumer方法中,将数据取出来后,又进行了一组运算。这时可能会出现一个协程从管道中取出数据,参与加法运算,但是还没有算完另外一个协程又从管道中取出一个数据赋值给了num变量。所以这样累加计算,很有可能出现问题。当然,按照前面的知识,解决这个问题的方法很简单,就是通过加锁的方式来解决。增加生产者也是一样的道理。
另外一个问题,如果消费者比生产者多,仓库中就会出现没有数据的情况。我们需要不断的通过循环来判断仓库队列中是否有数据,这样会造成cpu的浪费。反之,如果生产者比较多,仓库很容易满,满了就不能继续添加数据,也需要循环判断仓库满这一事件,同样也会造成CPU的浪费。
条件变量
条件变量的作用并不保证在同一时刻仅有一个协程(线程)访问某个共享的数据资源,而是在对应的共享数据的状态发生变化时,通知阻塞在某个条件上的协程(线程)。条件变量不是锁,在并发中不能达到同步的目的,因此条件变量总是与锁一块使用。
例如,我们上面说的,如果仓库队列满了,我们可以使用条件变量让生产者对应的goroutine暂停(阻塞),但是当消费者消费了某个产品后,仓库就不再满了,应该唤醒(发送通知给)阻塞的生产者goroutine继续生产产品。
GO标准库中的sys.Cond类型代表了条件变量。条件变量要与锁(互斥锁,或者读写锁)一起使用。成员变量L代表与条件变量搭配使用的锁。
type Cond struct {
noCopy noCopy
// L is held while observing or changing the condition
L Locker
notify notifyList
checker copyChecker
}
对应的有3个常用方法,Wait,Signal,Broadcast。
1)func (c *Cond) Wait()
该函数的作用可归纳为如下三点:
a)阻塞等待条件变量满足
b)释放已掌握的互斥锁相当于cond.L.Unlock()。 注意:两步为一个原子操作。
c)当被唤醒,Wait()函数返回时,解除阻塞并重新获取互斥锁。相当于cond.L.Lock()
2)func (c *Cond) Signal()
单发通知,给一个正等待(阻塞)在该条件变量上的goroutine(线程)发送通知。
3)func (c *Cond) Broadcast()
广播通知,给正在等待(阻塞)在该条件变量上的所有goroutine(线程)发送通知。
条件变量:
本身不是锁!!! 但经常与锁结合使用!!
使用流程:
1. 创建 条件变量: var cond sync.Cond
2. 指定条件变量用的 锁: cond.L = new(sync.Mutex)
3. cond.L.Lock() 给公共区加锁(互斥量)
4. 判断是否到达 阻塞条件(缓冲区满/空) —— for 循环判断
for len(ch) == cap(ch) { cond.Wait() —— 1) 阻塞 2) 解锁 3) 加锁
5. 访问公共区 —— 读、写数据、打印
6. 解锁条件变量用的 锁 cond.L.Unlock()
7. 唤醒阻塞在条件变量上的 对端。 signal() Broadcast()
条件变量使用原理分析
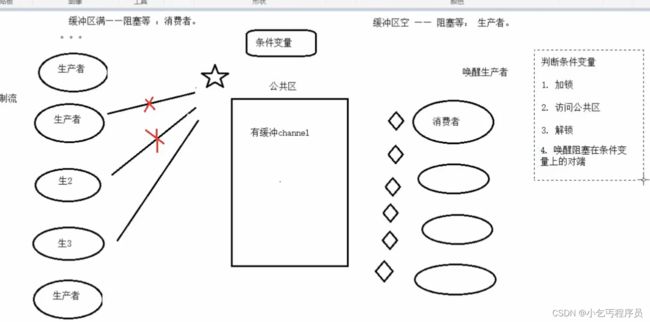
条件变量生产者消费者–主要是串行
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cond sync.Cond //定义全部条件变量
// 左写
func producer(out chan<- int, index int) {
for {
//先加锁
cond.L.Lock()
//判断缓冲区是否满
if len(out) == 5 {
cond.Wait() //1 阻塞,释放刚才的锁,唤醒以后重新加锁
}
num := rand.Intn(800)
out <- num
fmt.Printf("生产者%dth,生成:%d\n", index, num)
//返回公共区结束,并且打印结束,解锁
cond.L.Unlock()
//唤醒阻塞在条件变量上的消费者
cond.Signal()
time.Sleep(time.Millisecond * 200)
}
}
// 右读
func consumer(in <-chan int, index int) {
for {
//先加锁
cond.L.Lock()
//判断缓冲器是否为空
if len(in) == 0 {
cond.Wait()
}
num := <-in
fmt.Printf("-------消费者%dth,消费:%d\n", index, num)
//访问公共区结束后,解锁
cond.L.Unlock()
//唤醒 阻塞在条件变量上的生产者
cond.Signal()
time.Sleep(time.Millisecond * 200)
}
}
func main() {
product := make(chan int, 6)
rand.Seed(time.Now().UnixNano())
//指定条件变量使用的锁
cond.L = new(sync.Mutex) //互斥锁,初值0 未加锁状态
for i := 0; i < 5; i++ {
go producer(product, i+1)
}
for i := 0; i < 5; i++ {
go consumer(product, i+1)
}
for {
}
}
判断wait使用for的原因分析—主要是并行
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cond sync.Cond //定义全部条件变量
// 左写
func producer(out chan<- int, index int) {
for {
//先加锁
cond.L.Lock()
//判断缓冲区是否满
for len(out) == 5 { //如果有多个并行就要使用for
cond.Wait() //1 阻塞,释放刚才的锁,唤醒以后重新加锁
}
num := rand.Intn(800)
out <- num
fmt.Printf("生产者%dth,生成:%d\n", index, num)
//返回公共区结束,并且打印结束,解锁
cond.L.Unlock()
//唤醒阻塞在条件变量上的消费者
cond.Signal()
time.Sleep(time.Millisecond * 200)
}
}
// 右读
func consumer(in <-chan int, index int) {
for {
//先加锁
cond.L.Lock()
//判断缓冲器是否为空
for len(in) == 0 {
cond.Wait()
}
num := <-in
fmt.Printf("-------消费者%dth,消费:%d\n", index, num)
//访问公共区结束后,解锁
cond.L.Unlock()
//唤醒 阻塞在条件变量上的生产者
cond.Signal()
time.Sleep(time.Millisecond * 200)
}
}
func main() {
product := make(chan int, 6)
rand.Seed(time.Now().UnixNano())
//指定条件变量使用的锁
cond.L = new(sync.Mutex) //互斥锁,初值0 未加锁状态
for i := 0; i < 5; i++ {
go producer(product, i+1)
}
for i := 0; i < 5; i++ {
go consumer(product, i+1)
}
for {
}
}