深度学习:循环神经网络RNN及LSTM
深度学习:循环神经网络RNN及LSTM
- 循环神经网络RNN
-
- 原理
- 代码
- 长短期记忆网络LSTM
-
- 原理
-
- 遗忘门
- 记忆门
- 输出门
- 代码
循环神经网络RNN
原理
对于传统的神经网络,它的信号流从输入层到输出层依次流过,同一层级的神经元之间,信号是不会相互传递的。这样就会导致一个问题:输出信号只与输入信号有关,而与输入信号的先后顺序无关;并且神经元本身也不具有存储信息的能力,整个网络也就没有“记忆”能力。当输入信号是一个跟时间相关的信号时,如果我们想要通过这段信号的“上下文”信息来理解一段时间序列的意思,传统的神经网络结构就显得无力了。与我们人类的理解过程类似,我们听到一句话时往往需要通过这句话中词语出现的顺序以及我们之前所学的关于这些词语的意思来理解整段话的意思,而不是简单的通过其中的几个词语来理解。
因此,我们需要构建具有“记忆”能力的神经网络模型,用来处理需要理解上下文意思的信号,也就是时间序列数据。循环神经网络(RNN)被设计用来处理这类时间序列数据,它存储每一步时间信息,利用历史时刻隐藏状态的特征和当前时刻的输入来预测未来的输出。其网络结构示意图如下:

传统的循环神经网络结构较为简单,仅通过tanh函数实现历史时刻状态和当前时刻输入到当前时刻的输出。示意图如下:
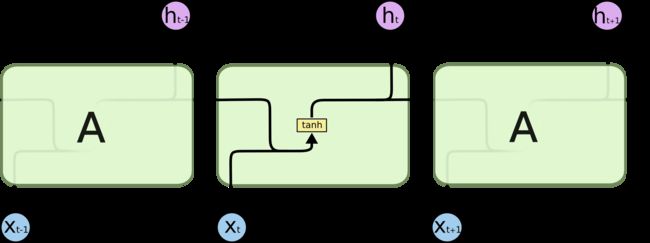
代码
利用pytorch实现循环神经网络RNN:
# -*- coding:UTF-8 -*-
import torch
from torch import nn
# Define Recurrent Neural Networks
class myRNN(nn.Module):
"""
Parameters:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size=1, output_size=1, num_layers=1):
super().__init__()
rnn = nn.RNN(input_size, hidden_size, num_layers)
self.ffn = nn.Linear(hidden_size, output_size)
def forward(self, _x):
x, _ = self.rnn(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s*b, h)
x = self.ffn(x)
x = x.view(s, b, -1)
return x
长短期记忆网络LSTM
原理
虽然循环神经网络在语音识别、自然语言处理、视频图像处理等领域已经取得了一定的成果,但其实际使用较少,因为它存在一定的局限性,例如当时间步数较大时,循环神经网络容易发生梯度爆炸。其次循环神经网络虽然在理论上可以保留所有历史时刻的信息,但在实际使用时,信息的传递往往会因为时间间隔太长而逐渐衰减,传递一段时刻以后其信息的作用效果就大大降低了。因此,普通的RNN对于信息的长期依赖问题没有很好的处理办法。而使用门控循环神经网络(Gated RNN)可以解决此问题,例如长短期记忆网络(Long Short Term Memory Network,LSTM)。
LSTM主要包括三个不同的门结构:遗忘门、记忆门和输出门。这三个门用来控制LSTM的输入信号 X t X_t Xt的保留和传递,最终反映到细胞状态(中间状态) C t C_t Ct和输出信号 h t h_t ht。其网络结构示意图如下图所示:

LSTM 的关键是细胞状态 C t C_{t} Ct,实现对当前LSTM的状态信息的更新并传递到下一时刻的LSTM中。

遗忘门
遗忘门的作用就是用来舍弃信息的。通过一个Sigmoid函数输出0~1的信号来决定哪些信息需要遗忘。
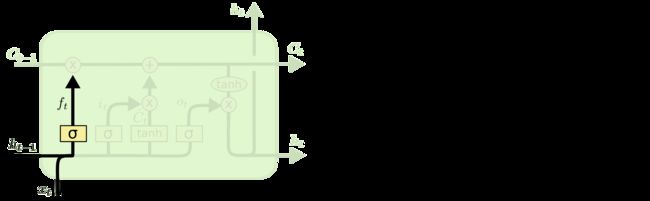
记忆门
记忆门的作用就是用来保留信息的,它利用一个Sigmoid函数和tanh函数来决定新输入的信息 x t x_t xt和 h t − 1 h_{t-1} ht−1中哪些信息需要保留。
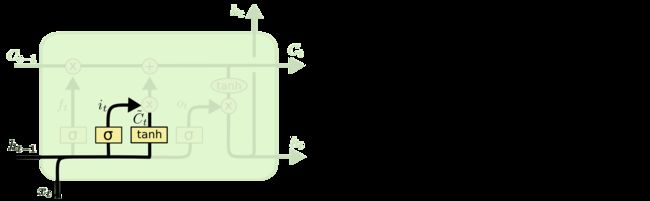
更新细胞状态 C t C_{t} Ct

输出门
在经过了前面遗忘门与记忆门选择后的细胞状态 C t − 1 C_{t-1} Ct−1,与 t − 1 t-1 t−1时刻的输出信号 h t − 1 h_{t-1} ht−1和 t t t时刻的输入信号 x t x_t xt整合到一起作为当前时刻的输出信号 h t h_t ht。
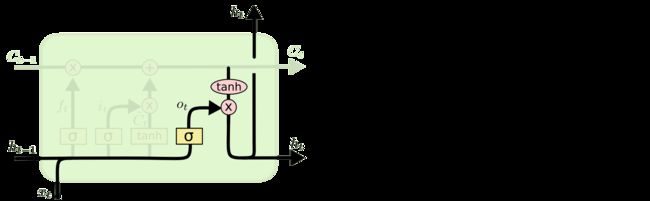
代码
利用pytorch实现长短期记忆网络LSTM:
# -*- coding:UTF-8 -*-
import torch
from torch import nn
# Define LSTM Neural Networks
class myLSTM(nn.Module):
"""
Parameters:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size=1, output_size=1, num_layers=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # utilize the LSTM model in torch.nn
self.ffn = nn.Linear(hidden_size, output_size)
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s*b, h)
x = self.ffn(x)
x = x.view(s, b, -1)
return x