Flink1.17学习笔记
- main快捷键设置
wordcount
- dataset API
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class wc {
public static void main(String[] args) throws Exception {
//创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//读取数据
DataSource<String> lineDS = env.readTextFile("input/word.txt");
//切分、转换(word, 1)
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//按照空格切分单词
String[] words = value.split(" ");
for (String word : words) {
//将单词转换为(word,1)
Tuple2<String, Integer> wordTuple2 = Tuple2.of(word, 1);
//使用collector向下游发送数据
out.collect(wordTuple2);
}
}
});
//按照word分组
UnsortedGrouping<Tuple2<String, Integer>> wordGroupby = wordAndOne.groupBy(0);
//分组内聚合
AggregateOperator<Tuple2<String, Integer>> wordsum = wordGroupby.sum(1);
//输出
wordsum.print();
}
}
- datastream读取文件做分词统计(有界流)
- (stream环境,分组用keyby, 需要开执行)
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class stemingwc {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取数据
final DataStreamSource<String> lineDS = env.readTextFile("input/word.txt");
//处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> wordandone = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
//分割
String[] words = value.split(" ");
for (String word : words) {
//转换
Tuple2<String, Integer> wordone = Tuple2.of(word, 1);
//采集器向下游发送数据
out.collect(wordone);
}
}
});
//分组
KeyedStream<Tuple2<String, Integer>, String> wordkeyby = wordandone.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
//聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> wordsum = wordkeyby.sum(1);
//输出数据
wordsum.print();
//执行
env.execute();
}
}
- 监听安装
sudo yum install -y netcat
nc -lk 7777
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeInfo;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class sockwc {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
socketDS.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
//转换
Tuple2<String, Integer> wordone = Tuple2.of(word, 1);
//采集器向下游发送数据
out.collect(wordone);
}
}
)
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1)
.print();
env.execute();
}
}
集群搭建
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
(1)进入conf路径,修改flink-conf.yaml文件,指定hadoop102节点服务器为JobManager
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
修改如下内容:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
(2)修改workers文件,指定hadoop102、hadoop103和hadoop104为TaskManager
[atguigu@hadoop102 conf]$ vim workers
修改如下内容:
hadoop102
hadoop103
hadoop104
(3)修改masters文件
[atguigu@hadoop102 conf]$ vim masters
修改如下内容:
hadoop102:8081
4)分发安装目录
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[atguigu@hadoop102 module]$ xsync flink-1.17.0/
(2)修改hadoop103的 taskmanager.host
[atguigu@hadoop103 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host
[atguigu@hadoop104 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
启动集群
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
关闭集群:(base) [link999@hadoop102 flink-1.17.0]$ bin/stop-cluster.sh
(2)查看进程情况:
[atguigu@hadoop102 flink-1.17.0]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4458 TaskManagerRunner
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
向集群提交作业
命令提交
(base) [link999@hadoop102 flink-1.17.0]$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.sockwc /opt/module/flink-1.17.0/testjar/F
linkTutorial-1.0-SNAPSHOT.jar
bin/flink run -m host:port -c copy_reference jarpath

3、copy reference


部署模式
- 会话模式(session Mode),适用于单个规模小、执行时间段的大量作业;
- 单作业模式(Per-Job Mode),为了更好地隔离资源,提交一个作业启动一个集群,作业完成后,集群关闭,资源释放;
- 应用模式(Application Mode),也是单个作业单个集群,但是由jobmanager进行解析,减少了网络带宽;
- 它们的主要区别在于:集群的生命周期和资源的分配方式;以及main方法到底在哪里执行–客户端还是jobmanager
运行模式
standalone(了解)
- 由Flink管理资源,不依赖外部条件,属于会话模式;
具体步骤如下:
(0)环境准备。在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(1)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
[atguigu@hadoop102 flink-1.17.0]$ mv FlinkTutorial-1.0-SNAPSHOT.jar lib/
(2)执行以下命令,启动JobManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh start --job-classname com.atguigu.wc.SocketStreamWordCount
这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
(3)同样是使用bin目录下的脚本,启动TaskManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh start
(4)在hadoop102上模拟发送单词数据。
[atguigu@hadoop102 ~]$ nc -lk 7777
hello
(5)在hadoop102:8081地址中观察输出数据
(6)如果希望停掉集群,同样可以使用脚本,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh stop
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh stop
YARN运行模式(重点)
sudo vim /etc/profile.d/my_env.sh
#FLINK_HOME
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
启动hadoop集群
一、会话模式
通过命令行提交作业
① 将FlinkTutorial-1.0-SNAPSHOT.jar任务上传至集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run
-c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定JobManager的地址,也可以通过-m或者-jobmanager参数指定JobManager的地址,JobManager的地址在YARN Session的启动页面中可以找到。
③ 任务提交成功后,可在YARN的Web UI界面查看运行情况。hadoop103:8088。
二、单作业模式
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -d -t yarn-per-job -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(3)可以使用命令行查看或取消作业,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
三、应用模式
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY
上传HDFS提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(1)上传flink的lib和plugins到HDFS上
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put lib/ /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put plugins/ /flink-dist
(2)上传自己的jar包到HDFS
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-jars
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars
(3)提交作业
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.atguigu.wc.SocketStreamWordCount hdfs://hadoop102:8020/flink-jars/FlinkTutorial-1.0-SNAPSHOT.jar
历史服务器
1)创建存储目录
hadoop fs -mkdir -p /logs/flink-job
2)在 flink-config.yaml中添加如下配置
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
3)启动历史服务器
bin/historyserver.sh start
4)停止历史服务器
bin/historyserver.sh stop
5)在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
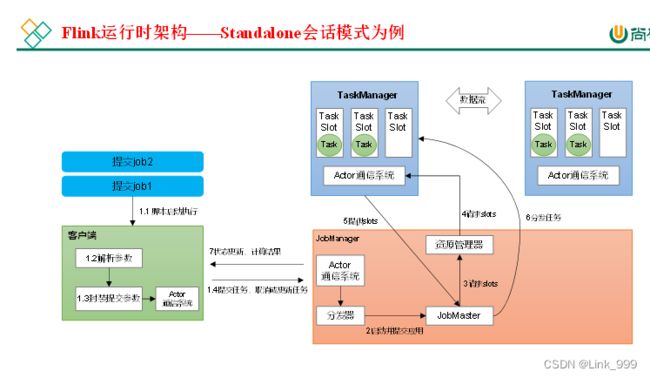
运行时架构
并行度
设置本地运行也可以看到webUI
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(2);
算子也可以设置并行度
优先级:
算子>env>提交>配置文件
算子链
1、算子之间的传输关系:
- 一对一
- 重分区
2、算子串在一起的条件:
- 一对一
- 并行度相同
3、关于算子链的API:
- 全局禁用算子链:env.disableOperatorChaining();
- 某个算子不参与链化:算子A…disableOperatorChaining();
- 从某个算子开启新链条:算子A.startNewChain();
任务槽(task slot)
- 表示taskmanager拥有计算资源的一个固定大小的子集,这些资源就是用来独立执行一个子任务的。
- slot的特点:
– 均分隔离内存,不隔离CPU
– 可以共享:同一个job中,不同算子的子任务才可以共享同一个slot,同一个共享组默认都是default - 设置共享组:算子A.slotSharingGroup(“name”)
- slot 数量与并行度的关系
–slot是一种静态的概念,表示最大的并发上限;并行度是一种动态的概念,表示实际运行占用了几个。
– slot数量>=job并行度(算子最大并行度),job才能运行。如果是yarn模式,会动态申请。
–申请的数量=job并行度/每个tm的slot数,向上取整
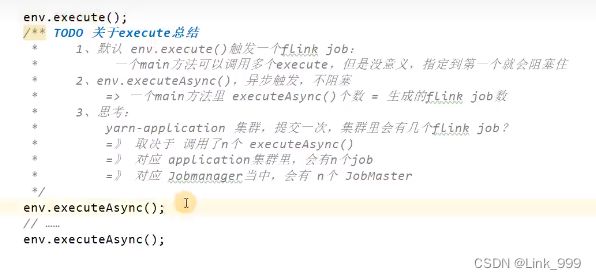
env
DataStream API执行模式包括:流执行模式、批执行模式和自动模式。
流执行模式(Streaming)
这是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。
批执行模式(Batch)
专门用于批处理的执行模式。
自动模式(AutoMatic)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
批执行模式的使用。主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加execution.runtime-mode参数,指定值为BATCH。
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
- 测试数据准备

package com.atguigu.wc.bean;
import java.util.Objects;
public class WaterSensor {
public String id;
public Long ts;
public Integer vc;
// shift+insert
public WaterSensor() {
}
public WaterSensor(String id, Long ts, Integer vc) {
this.id = id;
this.ts = ts;
this.vc = vc;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTs() {
return ts;
}
public void setTs(Long ts) {
this.ts = ts;
}
public Integer getVc() {
return vc;
}
public void setVc(Integer vc) {
this.vc = vc;
}
@Override
public String toString() {
return "WaterSensor{" +
"id='" + id + '\'' +
", ts=" + ts +
", vc=" + vc +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WaterSensor that = (WaterSensor) o;
return Objects.equals(id, that.id) &&
Objects.equals(ts, that.ts) &&
Objects.equals(vc, that.vc);
}
@Override
public int hashCode() {
return Objects.hash(id, ts, vc);
}
}
source
从集合中读取数据
env.fromElements(1,2,3).print();
从文件中读取
读取文件,需要添加文件连接器依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
package com.atguigu.wc.sourcedemo;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class sourcefiledemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
FileSource<String> filesouce = FileSource.forRecordStreamFormat(
new TextLineInputFormat(),
new Path("input/word.txt"))
.build();
env.fromSource(filesouce, WatermarkStrategy.noWatermarks(), "filesource").print();
env.execute();
}
}
从Socket读取数据
DataStream<String> stream = env.socketTextStream("localhost", 7777);
从Kafka读取数据
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
package com.atguigu.wc.sourcedemo;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class sourcekafkademo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
KafkaSource<String> kafkasouce = KafkaSource.<String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setGroupId("atguigu")
.setTopics("topic_1")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.build();
env
.fromSource(kafkasouce, WatermarkStrategy.noWatermarks(),"kafkasource")
.print();
env.execute();
}
}
kafka发送数据
kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic topic_1

- kafka启动时,遇到时间加载超时
Error while executing topic command : Timed out waiting for a node assignment. Call: createTopics
[2023-06-12 20:46:07,145] ERROR org.apache.kafka.common.errors.TimeoutException: Timed out waiting for a node assignment. Call: creat
eTopics
解决:分别在3个节点的kafka/config/server.properties修改配置文件的监听映射
例:修改其中103 的节点
listeners=PLAINTEXT://hadoop103:9092
从数据生成器读取数据
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>${flink.version}</version>
</dependency>
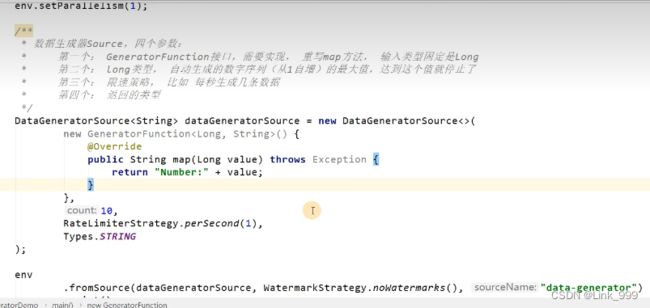
package com.atguigu.wc.sourcedemo;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class sourcegeneratordemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long aLong) throws Exception {
return "number:" + aLong;
}
},
// 10,
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(5),
Types.STRING
);
env
.fromSource(stringDataGeneratorSource, WatermarkStrategy.noWatermarks(), "outDataGeneratorSource")
.print();
env.execute();
}
}
transform
map
package com.atguigu.wc.transfrom;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class mapdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> sourceDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
);
// 匿名实现类
// SingleOutputStreamOperator map = sourceDS.map(new MapFunction() {
// @Override
// public String map(WaterSensor value) throws Exception {
// return value.getId();
// }
// });
// lambda表达式
// SingleOutputStreamOperator map = sourceDS.map(Sensor -> Sensor.getId());
// 定义一个类实现
SingleOutputStreamOperator<String> map = sourceDS.map(new MyMapFunction());
map.print();
env.execute();
}
public static class MyMapFunction implements MapFunction<WaterSensor, String>{
@Override
public String map(WaterSensor value) throws Exception {
return value.getId();
}
}
}
filter
package com.atguigu.wc.transfrom;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class filterdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> sourceDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
);
SingleOutputStreamOperator<WaterSensor> filter = sourceDS.filter(new FilterFunction<WaterSensor>() {
@Override
public boolean filter(WaterSensor value) throws Exception {
return value.getVc() > 1;
}
});
filter.print();
env.execute();
}
}
flagmap
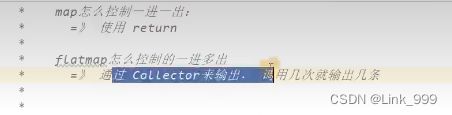
package com.atguigu.wc.transfrom;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class flagmapdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> sourceDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
);
SingleOutputStreamOperator<String> flagmap = sourceDS.flatMap(new FlatMapFunction<WaterSensor, String>() {
@Override
public void flatMap(WaterSensor value, Collector<String> out) throws Exception {
out.collect(value.getId());
if ("s1".equals(value.getId())) {
out.collect("karry on");
}
}
});
flagmap.print();
env.execute();
}
}
keyby

package com.atguigu.wc.aggregate;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class keybydemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> sourceDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
);
KeyedStream<WaterSensor, String> kb = sourceDS.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor value) throws Exception {
return value.getId();
}
});
kb.print();
env.execute();
}
}
简单聚合算子
- keyby之后才能调用
- 对同一个key进行聚合
- 位置索引适用于tuple类型,pojo要用字段名
kb.max("vc").print();
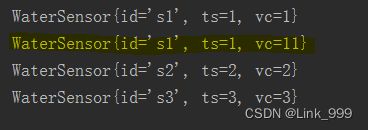
kb.maxBy("vc").print();
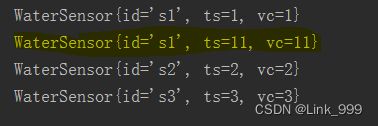
- max、maxBy的区别:
– max:只会比较字段的最大值,非比较字段保留第一次的值;
– maxBy:去比较字段的最大值,同时非比较字段取最大值这条数据
reduce
package com.atguigu.wc.aggregate;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class reducedemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<WaterSensor> sourceDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
);
KeyedStream<WaterSensor, String> kb = sourceDS.keyBy(new KeySelector<WaterSensor, String>() {
@Override
public String getKey(WaterSensor value) throws Exception {
return value.getId();
}
});
SingleOutputStreamOperator<WaterSensor> reduce = kb.reduce(new ReduceFunction<WaterSensor>() {
@Override
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
return new WaterSensor(value1.id, value2.ts, value1.vc + value2.vc);
}
});
reduce.print();
env.execute();
}
}
- keyby之后调用
- 输入类型等于输出类型,类型不能变
- 每个key的第一条数据来的时候,不会执行reduce方法,存起来,直接输出;
- reduce方法中的两个参数:
– value1:之前的计算结果,存状态
– value2:现在的数据
自定义函数
普通自定义函数
- 先自定义号函数后,new function调用
package com.atguigu.wc.function;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.FilterFunction;
public class filterfunfiondemo implements FilterFunction<WaterSensor>{
public String id;
// alt + insert
public filterfunfiondemo(String id) {
this.id = id;
}
@Override
public boolean filter(WaterSensor value) throws Exception {
return this.id.equals(value.getId());
}
}

富函数 richfunction
- 多了生命周期管理方法
– open():每个子任务,在启动时,调用一次;
– close():每个子任务,在结束时,调用一次;如果Flink程序异常挂掉,不会调用close;如果用cancel停止,会调用close; - 多了一个 运行时上下文
– 可以获取一些运行时的环境信息,比如子任务编号、名称等等
package com.atguigu.wc.transfrom;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class richfunctiondemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> source = env.fromElements(1, 2, 3, 4, 5);
SingleOutputStreamOperator<Integer> map = source.map(new RichMapFunction<Integer, Integer>() {
// ctrl+o
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.print(getRuntimeContext().getIndexOfThisSubtask()+"open方法调用");
}
@Override
public void close() throws Exception {
super.close();
System.out.print(getRuntimeContext().getIndexOfThisSubtask()+"close方法调用");
}
@Override
public Integer map(Integer value) throws Exception {
return value + 1;
}
});
map.print();
env.execute();
}
}
分区器和分区算子
package com.atguigu.wc.partition;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class partitiondemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 7777);
// 随机分区
stream.shuffle().print();
// 轮询分区
stream.rebalance().print();
// 重缩放分区,局部组队,比rebalance更高效
stream.rescale().print();
// 广播分区,发送给下游所有子任务
stream.broadcast().print();
// 全局分区,全部发往第一个子任务
stream.global().print();
// keyby,按指定key去发送,相同key发到同一个子任务
// one to one
// 自定义分区
env.execute();
}
}
自定义分区
package com.atguigu.wc.partition;
import org.apache.flink.api.common.functions.Partitioner;
public class mypartitiondemo implements Partitioner<String>{
@Override
public int partition(String key, int numPartitions) {
return Integer.parseInt(key) % numPartitions;
}
}
package com.atguigu.wc.partition;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class partitioncustomdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 7777);
stream.partitionCustom(new mypartitiondemo(), r -> r).print();
env.execute();
}
}
分流
filter过滤
package com.atguigu.wc.spilt;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class filterspiltdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> stream = env.socketTextStream("hadoop102", 7777);
stream.filter(value -> Integer.parseInt(value) % 2 == 0).print("偶数流");
stream.filter(value -> Integer.parseInt(value) % 2 == 1).print("奇数流");
env.execute();
}
}
侧输出流
WaterSensorMapfunction
package com.atguigu.wc.function;
import com.atguigu.wc.bean.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
public class WaterSensorMapfunction implements MapFunction<String, WaterSensor>{
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0], Long.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
}
sideoutputdemo
package com.atguigu.wc.spilt;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.SideOutputDataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.operators.Output;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class sideoutputdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
/*
* 使用侧输出流,分出watersencor的S1,S2的数据
* 步骤:
* 使用process算子
* new OutputTag
* 上下文调用
* 主流和侧流输出
* */
// 侧输出流标签,测输出流类型
OutputTag<WaterSensor> s1Tab = new OutputTag<>("s1", Types.POJO(WaterSensor.class));
OutputTag<WaterSensor> s2Tab = new OutputTag<>("s2", Types.POJO(WaterSensor.class));
SingleOutputStreamOperator<WaterSensor> process =
stream.process(new ProcessFunction<WaterSensor, WaterSensor>() {
@Override
public void processElement(WaterSensor waterSensor, Context context, Collector<WaterSensor> collector) throws Exception {
String id = waterSensor.getId();
if ("s1".equals(id)) {
/**
* 上下文调用output,将数据放入侧输出流;
* 第一个参数,tab对象;
* 第二个参数,数据
*/
context.output(s1Tab, waterSensor);
} else if ("s2".equals(id)) {
context.output(s2Tab, waterSensor);
} else {
// 非S1,S2的数据放到主流
collector.collect(waterSensor);
}
}
}
);
// 打印侧输出流
SideOutputDataStream<WaterSensor> s1 = process.getSideOutput(s1Tab);
SideOutputDataStream<WaterSensor> s2 = process.getSideOutput(s2Tab);
s1.printToErr("s1");
s2.printToErr("s2");
// 打印主流
process.print("主流");
env.execute();
}
}
合流
union
package com.atguigu.wc.combine;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class uniondemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> source2 = env.fromElements(11, 22, 33);
DataStreamSource<String> source3 = env.fromElements("a", "b", "c");
DataStreamSource<String> source4 = env.fromElements("111", "222", "333");
source1.union(source2).union(source4.map(r -> Integer.valueOf(r))).print();
source1.union(source2, source4.map(r -> Integer.valueOf(r))).print();
env.execute();
}
}
connect
- 一次只能连接2条流
- 流的数据类型可以不一样
- 连接后可以调用map、flatmap、process来处理,但是流内各处理各的
package com.atguigu.wc.combine;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class connectdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> source2 = env.fromElements(11, 22, 33);
DataStreamSource<String> source3 = env.fromElements("a", "b", "c");
DataStreamSource<String> source4 = env.fromElements("111", "222", "333");
ConnectedStreams<Integer, String> connect = source1.connect(source3);
SingleOutputStreamOperator<String> result =
connect.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer integer) throws Exception {
return integer.toString();
}
@Override
public String map2(String s) throws Exception {
return s;
}
});
result.print();
env.execute();
}
}
CoProcessFunction
package com.atguigu.wc.combine;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class connectkeybydemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(
Tuple2.of(1, "a1"),
Tuple2.of(1, "a2"),
Tuple2.of(2, "b"),
Tuple2.of(3, "c")
);
DataStreamSource<Tuple3<Integer, String, Integer>> source2 = env.fromElements(
Tuple3.of(1, "aa1", 1),
Tuple3.of(1, "aa2", 2),
Tuple3.of(2, "bb", 1),
Tuple3.of(3, "cc", 1)
);
// 合流
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect =
source1.connect(source2);
// 多并行度要先进行keyby
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> keyby =
connect.keyBy(r1 -> r1.f0, r2 -> r2.f0);
/**
* 实现互相匹配的效果:两条流,不一定谁的数据先来
* 1、每条数据,有数据来,存到一个变量中
* hash
* key = id
* value = list
* 2、每条流有数据来的时候,除了存变量中,不知道对方是否有匹配的数据,要去另一条流的变量中,查找是否有匹配上的
*/
SingleOutputStreamOperator<String> process = keyby.process(new CoProcessFunction<Tuple2<Integer,
String>, Tuple3<Integer, String, Integer>, String>() {
/**
* 每条流都定义一个hashmap
*/
Map<Integer, List<Tuple2<Integer, String>>> s1cache = new HashMap<>();
Map<Integer, List<Tuple3<Integer, String, Integer>>> s2cache = new HashMap<>();
/**
* 第一条流的逻辑
* @param value 第一条流的数据
* @param context 上下文
* @param out 采集器
* @throws Exception
*/
@Override
public void processElement1(Tuple2<Integer, String> value,
Context context, Collector<String> out) throws Exception {
Integer id = value.f0;
// 1、S1的数据来了,就存到变量中
if (!s1cache.containsKey(id)) {
// 如果key不存在,说明是该key的第一条数据,初始化,put进map中
List<Tuple2<Integer, String>> s1Values = new ArrayList<>();
s1Values.add(value);
s1cache.put(id, s1Values);
} else {
// 如果key存在,直接添加到value的list中
s1cache.get(id).add(value);
}
// 2、去s2cache中查找是否有id能匹配上的,匹配上就输出,没有就不输出
// if (s1cache.containsKey(id)) {
// for (Tuple3 s2Element : s2cache.get(id)) {
// out.collect("s1:" + value + "<--------->s2:" + s2Element);
// }
// }
}
/**
* 第二条流的数据
* @param integerStringIntegerTuple3 第二条的数据
* @param context 上下文
* @param out 采集器
* @throws Exception
*/
@Override
public void processElement2(Tuple3<Integer, String, Integer>
integerStringIntegerTuple3,
Context context,
Collector<String> out) throws Exception {
Integer id = integerStringIntegerTuple3.f0;
// 1、S1的数据来了,就存到变量中
if (!s2cache.containsKey(id)) {
// 如果key不存在,说明是该key的第一条数据,初始化,put进map中
List<Tuple3<Integer, String, Integer>> s2Values = new ArrayList<>();
s2Values.add(integerStringIntegerTuple3);
s2cache.put(id, s2Values);
} else {
// 如果key存在,直接添加到value的list中
s2cache.get(id).add(integerStringIntegerTuple3);
}
// 2、去s1cache中查找是否有id能匹配上的,匹配上就输出,没有就不输出
if (s1cache.containsKey(id)) {
for (Tuple2<Integer, String> s1element : s1cache.get(id)) {
out.collect("s1" + s1element + "<=========>" + "s2" + integerStringIntegerTuple3);
}
}
}
});
process.print();
env.execute();
}
}
sink
输出到文件系统
package com.atguigu.wc.sink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
import java.time.ZoneId;
public class sinkfiledemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 开启检查机制
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 数据生成器
DataGeneratorSource<String> stringDataGeneratorSource = new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long aLong) throws Exception {
return "number:" + aLong;
}
},
// 10,
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(5),
Types.STRING
);
DataStreamSource<String> datagen = env.fromSource(stringDataGeneratorSource,
WatermarkStrategy.noWatermarks(), "outDataGeneratorSource");
// 输出到文件系统
FileSink<String> filesink = FileSink.<String>forRowFormat(new Path("F:\\尚硅谷大数据\\Flink\\FlinkTutorial\\src\\main\\java\\com\\atguigu\\wc\\sink"),
new SimpleStringEncoder<>("UTF-8"))
// 输出文件的配置 前缀 后缀
.withOutputFileConfig(OutputFileConfig.builder()
.withPartPrefix("karryon-")
.withPartSuffix(".log")
.build())
// 文件分桶
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH",
ZoneId.systemDefault()))
// 文件的滚动策略
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withInactivityInterval(Duration.ofMinutes(10)) // 按时间
.withMaxPartSize(new MemorySize(1024)) // 按大小
.build()
).build();
datagen.sinkTo(filesink);
env.execute();
}
}
输出到kafka
socket --> fink --> kafka(消费者)
package com.atguigu.wc.sink;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;
public class kafkasinkdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 必须要开启checkpoint,否则在精准一次无法写入kafka
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SingleOutputStreamOperator<String> sensorDS = env.socketTextStream("hadoop102", 7777);
KafkaSink<String> kafkasink = KafkaSink.<String>builder()
// 指定kafka的地址和端口
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
// 指定序列化器,指定topic名称、具体的序列化
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("ws")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// 写到kafka的一致性级别:精准一次,至少一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 如果是精准一次,必须设置事务前缀
.setTransactionalIdPrefix("karry-")
// 如果是精准一次,必须设置 事务超时时间:大于checkpoint,小于max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
sensorDS.sinkTo(kafkasink);
env.execute();
}
}
开启socket
nc -lk 7777
开启kafka消费
(base) [link999@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop104:9092 --topic ws
自定义序列化器
package com.atguigu.wc.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.nio.charset.StandardCharsets;
public class kafkasinkwithkeydemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 必须要开启checkpoint,否则在精准一次无法写入kafka
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SingleOutputStreamOperator<String> sensorDS = env.socketTextStream("hadoop102", 7777);
/**
* 如果要指定写入kafka的key,可以自定义反序列器
* 实现一个接口,重写序列化方法
* 指定key,转成字节数组
* 指定value,转成字段组
* 返回一个producerRecord对象,把key、value放进去
*/
KafkaSink<String> kafkasink = KafkaSink.<String>builder()
// 指定kafka的地址和端口
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
// 指定序列化器,指定topic名称、具体的序列化
.setRecordSerializer(
new KafkaRecordSerializationSchema<String>() {
@Nullable
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {
String[] datas = element.split(",");
byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);
byte[] value = element.getBytes(StandardCharsets.UTF_8);
return new ProducerRecord<>("ws1", key, value);
}
}
)
// 写到kafka的一致性级别:精准一次,至少一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 如果是精准一次,必须设置事务前缀
.setTransactionalIdPrefix("karry-")
// 如果是精准一次,必须设置 事务超时时间:大于checkpoint,小于max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
sensorDS.sinkTo(kafkasink);
env.execute();
}
}
输出到JDBC
写入数据的MySQL的测试步骤如下。
(1)添加依赖
添加MySQL驱动:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
官方还未提供flink-connector-jdbc的1.17.0的正式依赖,暂时从apache snapshot仓库下载,pom文件中指定仓库路径:
<repositories>
<repository>
<id>apache-snapshots</id>
<name>apache snapshots</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
</repositories>
添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.17-SNAPSHOT</version>
</dependency>
如果不生效,还需要修改本地maven的配置文件,mirrorOf中添加如下标红内容:
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*,!apache-snapshots</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
(2)启动MySQL,在test库下建表ws
mysql>
CREATE TABLE `ws` (
`id` varchar(100) NOT NULL,
`ts` bigint(20) DEFAULT NULL,
`vc` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
package com.atguigu.wc.sink;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class mysqlsinkdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
/**
* TODO 写入mysql
* 1、只能用老的sink写法: addsink
* 2、JDBCSink的4个参数:
* 第一个参数: 执行的sql,一般就是 insert into
* 第二个参数: 预编译sql, 对占位符填充值
* 第三个参数: 执行选项 ---》 攒批、重试
* 第四个参数: 连接选项 ---》 url、用户名、密码
*/
SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink(
"insert into ws values(?,?,?)",
new JdbcStatementBuilder<WaterSensor>() {
@Override
public void accept(PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException {
//每收到一条WaterSensor,如何去填充占位符
preparedStatement.setString(1, waterSensor.getId());
preparedStatement.setLong(2, waterSensor.getTs());
preparedStatement.setInt(3, waterSensor.getVc());
}
},
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 重试次数
.withBatchSize(100) // 批次的大小:条数
.withBatchIntervalMs(3000) // 批次的时间
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://hadoop102:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("000000")
.withConnectionCheckTimeoutSeconds(60) // 重试的超时时间
.build()
);
sensorDS.addSink(jdbcSink);
env.execute();
}
}
自定义sink输出
stream.addSink(new MySinkFunction<String>());
窗口
- 动态创建
- 按驱动类分:时间窗口、计数窗口
- 按窗口分配数据的规则分:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window)、全局窗口(Global Window)
滚动窗口
- 有固定的大小,均匀切片。窗口之间没有重叠,也不会有间隔,首尾相连。
- 适用于每个时间段做统计的场景
滑动窗口
- 大小固定,可以错开
- 两个参数:窗口大小、滑动步长
- 当滑动步长小于窗口大小,滑动窗口就会出现重叠
- 适用于更新频率高的场景
会话窗口
- 只能基于时间来定义
- 如果两个数据来的时间间隔Gap小于指定的大小size,说明保持会话,属于同一个窗口
全局窗口
- 全局有效,会把相同的key发往同一个窗口中
窗口分配器与窗口函数
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.api.windowing.windows.Window;
public class windowapidemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = sensorDS.keyBy(word -> word.getId());
// 1、窗口分配器:指定用哪一种窗口 --- 时间 or 计数 ? 滚动、滑动、会话、全局
// 1.1 没有keyby的窗口:窗口内所有数据进入同一个子任务,并行度只能为1
sensorDS.windowAll();
// 1.2 有keyby的窗口:每个key上都定义了一组窗口,各自独立地进行统计计算
// 基于时间的
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(10))); //滚定窗口,窗口长度10S
sensorkb.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(2))); // 滑动窗口,窗口长度10s,滑动步长2s
sensorkb.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5))); // 会话窗口,超时间隔5s
// 基于计数的
sensorkb.countWindow(5); // 滚动窗口,窗口长度=5个元素
sensorkb.countWindow(5,2); // 滑动窗口,窗口长度=5个元素,滑动步长=2个元素,每经过一个步长,都有一个窗口输出
sensorkb.window(GlobalWindows.create()); // 全局窗口,计数窗口的底层就是用的这个,需要自定义的时候才会用
// 2、窗口函数:窗口内数据的计算逻辑
WindowedStream<WaterSensor, String, TimeWindow> sensoraws =
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
// 增量聚合:来一条数据,计算一条数据,窗口触发的时候输出计算结果
sensoraws.aggregate()
sensoraws.reduce()
// 全窗口函数:数据来了不计算,存起来,窗口触发的时候,计算并输出结果
sensoraws.process()
env.execute();
}
}
归约函数 reduce
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class reducedemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = stream.keyBy(key -> key.getId());
WindowedStream<WaterSensor, String, TimeWindow> sensorws =
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));
SingleOutputStreamOperator<WaterSensor> reduce = sensorws.reduce(new ReduceFunction<WaterSensor>() {
@Override
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
System.out.print("调用reduce方法,value1=" + value1 + ", value2=" + value2);
return new WaterSensor(value1.getId(), value1.getTs(), value1.getVc() + value2.getVc());
}
});
reduce.print();
env.execute();
}
}
聚合函数 aggregate
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class aggregatedemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = stream.keyBy(key -> key.getId());
// 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorws =
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));
// 窗口函数
/**
* 增量聚合 aggregate
* 1 属于本窗口的第一条数据来,创建窗口,创建累加器
* 2 增量聚合 来一条,调用一次add方法
* 3 窗口输出时调用一次getresult方法
* 4 输入 累加器 输出 数据类型可以不一样
*/
SingleOutputStreamOperator<String> aggregate = sensorws.aggregate(new AggregateFunction<WaterSensor, Integer, String>() {
/**
* 第一个类型:输入类型
* 第二个类型:累加器的类型,存储中间计算结果的类型
* 第三个类型:输出类型
*/
// 初始化累加器
@Override
public Integer createAccumulator() {
System.out.print("创建累加器\n");
return 0;
}
// 聚合逻辑
@Override
public Integer add(WaterSensor value, Integer accumulator) {
System.out.print("调用add方法, value=" + value);
return accumulator + value.getVc();
}
// 获取最终结果,窗口触发时输出
@Override
public String getResult(Integer accumulator) {
System.out.print("\n调用getReault方法");
return accumulator.toString();
}
@Override
public Integer merge(Integer a, Integer b) {
// 只有会话窗口才会用到
System.out.print("调用merge方法");
return null;
}
});
aggregate.print();
env.execute();
}
}
全窗口函数 full window functions
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class processdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = stream.keyBy(key -> key.getId());
// 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorws =
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));
SingleOutputStreamOperator<String> process = sensorws.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
// 上下文可以拿到window对象,还有其他
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
});
process.print();
env.execute();
}
}
增量聚合+全窗口函数
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class aggregateprocessdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = stream.keyBy(key -> key.getId());
// 窗口分配器
WindowedStream<WaterSensor, String, TimeWindow> sensorws =
sensorkb.window(TumblingProcessingTimeWindows.of(Time.seconds(20)));
// 窗口函数
/**
* 增量聚合aggregate+全窗口process
* 增量聚合,来一条处理一条,占用空间少
* 窗口触发时,增量聚合的结果(只有一条)传递给全窗口函数,可以通过上下文实现其他功能
* 经过全窗口函数处理包装后输出
*/
SingleOutputStreamOperator<String> aggregateprocess = sensorws.aggregate
(new MyAgg(), new MyProcess());
aggregateprocess.print();
env.execute();
}
public static class MyAgg implements AggregateFunction<WaterSensor, Integer, String>{
/**
* 第一个类型:输入类型
* 第二个类型:累加器的类型,存储中间计算结果的类型
* 第三个类型:输出类型
*/
// 初始化累加器
@Override
public Integer createAccumulator() {
System.out.print("创建累加器\n");
return 0;
}
// 聚合逻辑
@Override
public Integer add(WaterSensor value, Integer accumulator) {
System.out.print("调用add方法, value=" + value);
return accumulator + value.getVc();
}
// 获取最终结果,窗口触发时输出
@Override
public String getResult(Integer accumulator) {
System.out.print("\n调用getReault方法");
return accumulator.toString();
}
@Override
public Integer merge(Integer a, Integer b) {
// 只有会话窗口才会用到
System.out.print("调用merge方法");
return null;
}
}
public static class MyProcess extends ProcessWindowFunction<String, String, String, TimeWindow>{
@Override
public void process(String s, Context context, Iterable<String> elements, Collector<String> out) throws Exception {
// 上下文可以拿到window对象,还有其他
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}
}
动态获取会话间隔时间
package com.atguigu.wc.window;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SessionWindowTimeGapExtractor;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class timewindowprocessdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
KeyedStream<WaterSensor, String> sensorkb = stream.keyBy(key -> key.getId());
// 窗口分配器
// 会话窗口,动态间隔,每条来的数据都会更新动态间隔时间
WindowedStream<WaterSensor, String, TimeWindow> windowwithDynamicGap =
sensorkb.window(ProcessingTimeSessionWindows.withDynamicGap(
new SessionWindowTimeGapExtractor<WaterSensor>() {
@Override
public long extract(WaterSensor element) {
// 从数据中提取间隔,单位ms
return element.getTs() * 1000L;
}
}
));
SingleOutputStreamOperator<String> process = windowwithDynamicGap.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
// 上下文可以拿到window对象,还有其他
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
});
process.print();
env.execute();
}
}
其他API
-
触发器、移出器
以时间类型的滚动窗口为例,分析原理: -
窗口是什么时候触发输出?
– 时间进展 >= 窗口 的最大时间戳(end - 1ms) -
窗口是怎么划分的?
– start 向下取整,去窗口长度的整数倍
– end start+窗口长度
– 窗口左闭右开,属于本窗口的最大时间戳=end-1ms -
窗口的生命周期?
– 创建:属于本窗口的第一条数据来的时候,现new的,放入一个singleton单例的集合中
– 销毁(关闭):事件进展 >= 窗口的最大时间戳(end - 1ms)+ 允许迟到的时间(默认0)
时间语义
- 事件时间:数据产生的时间(timestamp)
- 处理时间:数据真正被处理的时刻
水位线
- 用来衡量时间事件进展的标志,称作 水位线
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以设置延迟,来确保正确处理乱序数据
- 一个水位线watermark(t),表示当前流中事件时间已经达到了时间戳t,这代表t之前的所有数据都到齐了,之后流中不会出现时间t’ <= t的数据
有序
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class watermarkmonodemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy<WaterSensor> myWatermarkStrategy = WatermarkStrategy
// 升序的watermark,没有等待时间
.<WaterSensor>forMonotonousTimestamps()
// 指定时间戳分配器,从事件中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId())
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}).print();
env.execute();
}
}
乱序
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class watermarkoutoforderdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy<WaterSensor> myWatermarkStrategy = WatermarkStrategy
// 乱序的watermark,等待3秒
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// 指定时间戳分配器,从事件中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId())
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}).print();
env.execute();
}
}
- 内置watermark的生成原理
- 1、都是周期性生成的:默认200S
- 2、有序流:watermark = 当前最大的事件时间 - 1ms
- 3、乱序流:watermark = 当前最大的事件时间 - 延迟时间 - 1ms
周期性水位线生成器
watermarkgeneratedemo
package com.atguigu.wc.watermark;
import org.apache.flink.api.common.eventtime.Watermark;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkOutput;
public class watermarkgeneratedemo<T> implements WatermarkGenerator<T>{
private long delayTs;
private long maxTs;
public watermarkgeneratedemo(long delayTs) {
// 乱序等待时间
this.delayTs = delayTs;
// 用来保存当前为止最大的乱序时间
this.maxTs = Long.MIN_VALUE + this.delayTs + 1;
}
/**
* 每条数据来都会调用一次,用来提取最大的事件时间,保存下来
* @param event
* @param eventTimestamp 数据的事件时间
* @param output
*/
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTs = Math.max(maxTs, eventTimestamp);
System.out.println(maxTs);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
/**
* 周期调用,发射watermark
*/
output.emitWatermark(new Watermark(maxTs - delayTs -1));
System.out.println(maxTs - delayTs -1);
}
}
watermarkcustomdemo
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class watermarkcustomdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 默认周期 200ms
env.getConfig().setAutoWatermarkInterval(200);
SingleOutputStreamOperator<WaterSensor> stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy<WaterSensor> myWatermarkStrategy = WatermarkStrategy
// 乱序的watermark,等待3秒
.<WaterSensor>forGenerator(ctx -> new watermarkgeneratedemo<>(3000L))
// 指定时间戳分配器,从事件中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator<WaterSensor> waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId())
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}).print();
env.execute();
}
}
断点式水位线生成器
watermarkPunctuatedgeneratedemo
package com.atguigu.wc.watermark;
import org.apache.flink.api.common.eventtime.Watermark;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkOutput;
public class watermarkPunctuatedgeneratedemo<T> implements WatermarkGenerator<T>{
private long delayTs;
private long maxTs;
public watermarkPunctuatedgeneratedemo(long delayTs) {
// 乱序等待时间
this.delayTs = delayTs;
// 用来保存当前为止最大的乱序时间
this.maxTs = Long.MIN_VALUE + this.delayTs + 1;
}
/**
* 每条数据来都会调用一次,用来提取最大的事件时间,保存下来, 并发射watermark
* @param event
* @param eventTimestamp 数据的事件时间
* @param output
*/
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTs = Math.max(maxTs, eventTimestamp);
System.out.println(maxTs);
output.emitWatermark(new Watermark(maxTs - delayTs -1));
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
/**
* 周期调用,发射watermark
*/
}
}
// 周期性水位线生成
// .forGenerator(ctx -> new watermarkgeneratedemo<>(3000L))
// 断点式水位线生成
.<WaterSensor>forGenerator(ctx -> new watermarkPunctuatedgeneratedemo<>(3000))
多并行度下的watermark传递
- 接收到上游多个取最小
- 往下游多个发送,广播
空闲等待
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import com.atguigu.wc.partition.mypartitiondemo;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class watermarklenessdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
SingleOutputStreamOperator sockDS = env
.socketTextStream("hadoop102", 7777)
.partitionCustom(new mypartitiondemo(), r -> r)
.map(r -> Integer.parseInt(r))
.assignTimestampsAndWatermarks(WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((r, ts) -> r * 1000)
.withIdleness(Duration.ofSeconds(5)) // 空闲等待时间
);
sockDS
// 分奇偶数组,当一直输入奇数时,偶数一直在等待,此时需要设置等待时间
.keyBy(r -> r % 2)
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessWindowFunction() {
@Override
public void process(Integer integer, Context context, Iterable elements, Collector out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + integer + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}).print();
env.execute();
}
}
推迟关窗
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class watermarkallowedLatenessdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy myWatermarkStrategy = WatermarkStrategy
// 乱序的watermark,等待3秒
.forBoundedOutOfOrderness(Duration.ofSeconds(3))
// 指定时间戳分配器,从事件中提取
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId())
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 推迟关窗
.allowedLateness(Time.seconds(2))
.process(new ProcessWindowFunction() {
/**
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable elements, Collector out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
}).print();
env.execute();
}
}
迟到后关窗的数据放入侧输出流
package com.atguigu.wc.watermark;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class watermarksideOutputLateDatademo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy myWatermarkStrategy = WatermarkStrategy
// 乱序的watermark,等待3秒
.forBoundedOutOfOrderness(Duration.ofSeconds(3))
// 指定时间戳分配器,从事件中提取
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
// 定义侧输出流标签
OutputTag late_data = new OutputTag<>("late_data", Types.POJO(WaterSensor.class));
SingleOutputStreamOperator process = waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId())
// 使用事件语义的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 推迟关窗
.allowedLateness(Time.seconds(2))
.sideOutputLateData(late_data)
.process(new ProcessWindowFunction() {
/**
* @param s 分组的key
* @param context 上下文
* @param elements 存储的数据
* @param out 采集器
* @throws Exception
*/
@Override
public void process(String s, Context context, Iterable elements, Collector out) throws Exception {
long start = context.window().getStart();
long end = context.window().getEnd();
String startformat = DateFormatUtils.format(start, "yyyy-MM-dd HH:mm:ss.SSS");
String endformat = DateFormatUtils.format(end, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口" + startformat + ","
+ endformat + "包含" + count + "条数====》" + elements.toString());
}
});
process.print(); // 主流
process.getSideOutput(late_data).printToErr(); // 侧输出流
env.execute();
}
}
总结
- 乱序与迟到的区别
– 乱序:数据的顺序乱了,出现时间小的比时间大的晚来
– 迟到:数据的时间戳 < 当前的watermark - 乱序、迟到数据的处理
– watermark中指定乱序的等待时间
– 如果开窗,设置窗口允许迟到
– 关窗后迟到的数据放入侧输出流
基于时间的合流
窗口联结(Window Join)
- 落在同一个时间窗口范围内才能匹配
- 根据keyby的key,来进行匹配关联
- 只能拿到匹配上的数据,类似inner join
package com.atguigu.wc.watermark;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class windowjoindemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator> ws1 =
env.
fromElements(Tuple2.of("a", 1),
Tuple2.of("a", 2),
Tuple2.of("b", 3),
Tuple2.of("c", 4))
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
SingleOutputStreamOperator> ws2 =
env.
fromElements(Tuple3.of("a", 1, 1),
Tuple3.of("a", 12, 12),
Tuple3.of("b", 11, 11),
Tuple3.of("c", 15, 15))
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
// window join
DataStream apply = ws1
.join(ws2)
.where(r1 -> r1.f0)
.equalTo(r2 -> r2.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction, Tuple3, String>() {
/**
* 关联上的数据调用join
* @param first ws1 的数据
* @param second ws2 的数据
* @return
* @throws Exception
*/
@Override
public String join(Tuple2 first, Tuple3 second) throws Exception {
return first + "-------" + second;
}
});
apply.print();
env.execute();
}
}
间隔联结(Interval Join)
有界流
package com.atguigu.wc.watermark;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class Intervaljoindemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator> ws1 =
env.
fromElements(Tuple2.of("a", 1),
Tuple2.of("a", 2),
Tuple2.of("b", 3),
Tuple2.of("c", 4))
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
SingleOutputStreamOperator> ws2 =
env.
fromElements(Tuple3.of("a", 1, 1),
Tuple3.of("a", 12, 12),
Tuple3.of("b", 11, 11),
Tuple3.of("c", 15, 15))
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
// Interval join
// 分别做keyby,key其实就是关联条件
KeyedStream, String> kb1 = ws1.keyBy(r1 -> r1.f0);
KeyedStream, String> kb2 = ws2.keyBy(r2 -> r2.f0);
// 调用interval join
kb1.intervalJoin(kb2)
.between(Time.seconds(-2), Time.seconds(2))
.process(new ProcessJoinFunction, Tuple3, String>() {
/**
*
* @param left kb1的数据
* @param right kb2的数据
* @param ctx 上下文
* @param out 采集器
* @throws Exception
*/
@Override
public void processElement(Tuple2 left, Tuple3 right, Context ctx, Collector out) throws Exception {
out.collect(left + "----" + right);
}
})
.print();
env.execute();
}
}
无界流
- 迟到的数据用侧输出流输出
package com.atguigu.wc.watermark;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class Intervalsockjoindemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator> ws1 =
env.
socketTextStream("hadoop102", 7777)
.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
String[] datas = value.split(",");
return Tuple2.of(datas[0], Integer.valueOf(datas[1]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
SingleOutputStreamOperator> ws2 =
env.
socketTextStream("hadoop102", 8888)
.map(new MapFunction>() {
@Override
public Tuple3 map(String value) throws Exception {
String[] datas = value.split(",");
return Tuple3.of(datas[0], Integer.valueOf(datas[1]), Integer.valueOf(datas[2]));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
.>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner((value, ts) -> value.f1 * 1000L));
/**
* Interval join
* 1、只支持事件时间
* 2、指定上界、下界的偏移,负号代表时间往前,正号代表时间往后
* 3、process中,只能处理 join上的数据
* 4、两条流关联后的watermark,以两条流中最小的为准
* 5、如果 当前数据的事件时间 < 当前的watermark,就是迟到数据, 主流的process不处理
* => between后,可以指定将 左流 或 右流 的迟到数据 放入侧输出流
*/
// 分别做keyby,key其实就是关联条件
KeyedStream, String> kb1 = ws1.keyBy(r1 -> r1.f0);
KeyedStream, String> kb2 = ws2.keyBy(r2 -> r2.f0);
// 标签
OutputTag> left = new OutputTag<>("left", Types.TUPLE(Types.STRING, Types.INT));
OutputTag> right = new OutputTag<>("right", Types.TUPLE(Types.STRING, Types.INT, Types.INT));
// 调用interval join
SingleOutputStreamOperator process = kb1.intervalJoin(kb2)
.between(Time.seconds(-2), Time.seconds(2))
.sideOutputLeftLateData(left) // 将 ks1的迟到数据,放入侧输出流
.sideOutputRightLateData(right) // 将 ks2的迟到数据,放入侧输出流
.process(new ProcessJoinFunction, Tuple3, String>() {
/**
*
* @param left kb1的数据
* @param right kb2的数据
* @param ctx 上下文
* @param out 采集器
* @throws Exception
*/
@Override
public void processElement(Tuple2 left, Tuple3 right, Context ctx, Collector out) throws Exception {
out.collect(left + "----" + right);
}
});
process.print();
process.getSideOutput(left).printToErr();
process.getSideOutput(right).printToErr();
env.execute();
}
}
处理函数
KeyedProcessFunction 定时器案例
package com.atguigu.wc.process;
import com.atguigu.wc.bean.WaterSensor;
import com.atguigu.wc.function.WaterSensorMapfunction;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class keyprocessdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator stream = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapfunction());
// 定义watermark策略
WatermarkStrategy myWatermarkStrategy = WatermarkStrategy
.forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
System.out.println(element + " " + recordTimestamp);
return element.getTs() * 1000L;
}
});
SingleOutputStreamOperator waterSensorSingleOutputStreamOperator = stream.assignTimestampsAndWatermarks(myWatermarkStrategy);
KeyedStream wsstream = waterSensorSingleOutputStreamOperator
.keyBy(key -> key.getId());
SingleOutputStreamOperator process = wsstream.process(new KeyedProcessFunction() {
@Override
public void processElement(WaterSensor value, Context ctx, Collector out) throws Exception {
// 提取数据的事件时间
Long ts = ctx.timestamp();
// 定时器
TimerService timerService = ctx.timerService();
// 注册定时器
// 事件时间
timerService.registerEventTimeTimer(5000L);
System.out.print("当前时间是" + ts + "注册了一个5秒的定时器");
// 处理时间
// String currentKey = ctx.getCurrentKey();
// timerService.registerProcessingTimeTimer(ts + 5000L);
// System.out.print(currentKey + "----" + "当前时间是" + ts + "注册了一个5秒的定时器");
// 删除定时器
// 事件时间
// timerService.deleteEventTimeTimer()
// 处理时间
// timerService.deleteProcessingTimeTimer();
// 获取当前处理时间,就是系统时间
// long currentts = timerService.currentProcessingTime();
// 获取当前的watermark
// long wm = timerService.currentWatermark();
}
// ctrl + o
// 定时器触发
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
super.onTimer(timestamp, ctx, out);
String currentKey = ctx.getCurrentKey();
System.out.print(currentKey+"--"+timestamp + "定时器触发了");
}
});
process.print();
env.execute();
}
}
- 定时器
- 事件时间定时器,通过watermark来触发
– watermark >= 注册时间 - 在process中获取当前watermark,显示的是上一次的watermark,因为process还没接受到这条数据对应生成的新watermark
状态管理
待补充
容错机制
待补充