Python爬虫实战案例——第三例
文章中所有内容仅供学习交流使用,不用于其他任何目的!严禁将文中内容用于任何商业与非法用途,由此产生的一切后果与作者无关。若有侵权,请联系删除。
起点中文网月票榜加密字体处理
字体加密的原理:就是将一种特定的字体库来代替浏览器本身的字体库显示的过程。
基本流程:
- 请求页面
- 获取加密的字体库
- 解析字体库,获取字体间的映射关系
- 获取加密的字体,获取字体间的映射关系,一一对应
地址:aHR0cHM6Ly93d3cucWlkaWFuLmNvbS9yYW5rL3l1ZXBpYW8v

请求模板:
class SendRequest:
def __init__(self):
self.url = 'aHR0cHM6Ly93d3cucWlkaWFuLmNvbS9yYW5rL3l1ZXBpYW8v'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'referer': ''
}
self.session = requests.session()
def URequest(self):
response = self.session.get(self.url, headers=self.headers)
return response
首先是对该页面进行抓包分析
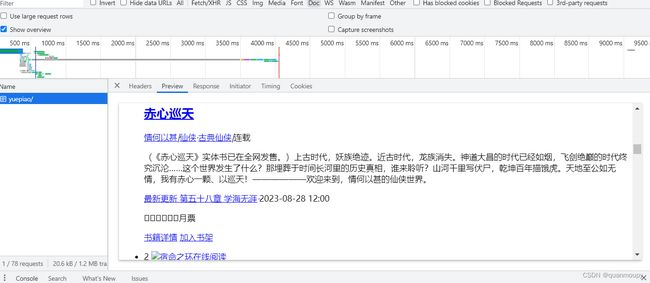
可以看到目标数据是在HTML页面中的静态数据,但是月票数据却是加密内容,其源码中内容如下

所以接下来我们需要做的就是将这段加密的内容还原成准确的文字,这里由于适合字体显示有关,所以我们可以先看一下这部分标签对于字体的相关设置
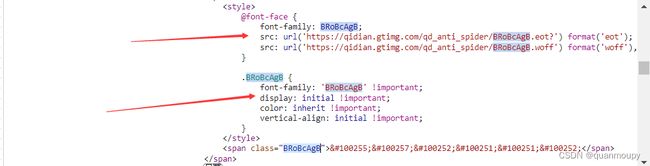
刚好就说在这个标签上可以看到对于这些字体的配置,同时我们可以看到span标签的字体是由woff文件渲染的,所以我们可以先将这个字体文件下载到本地,然后找一下是否有关于字体相关的映射关系。下载完成后在Python中通过fonttools模块(pip install fonttools)来对字体文件进行初步处理。
from fontTools.ttLib import TTFont
# 使用TTfont打开一个本地存在的字体文件
font_file = TTFont('BRoBcAgB.woff')
# 转换成XML文档
font_file.saveXML('BRoBcAgB.xml')
通过fonttools保存为xml文件之后从里面可以看到相关的映射关系。
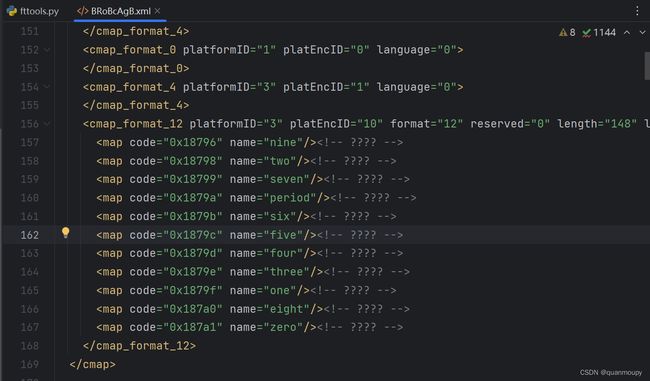
然后我们可以将code后面的内容转换成十进制观察。

现在我们来将这些数字简单的和网页中看到的数字对比一下看看是否得出正确的映射关系。如第一部小说的月票数据内容
𘞟𘞡𘞜𘞛𘞛𘞜
从页面中看到的月票量为105665,那么就是说100255映射的值为1,100257映射的值为0,我们来验证一下是否如此呢。从XML中找到1相关的映射

刚好,那继续验证一下后面的数字呢,如0

也对应上了,后续继续验证也是对应的,所以就是说我们能够从xml文件中的cmap标签中获取到对应的映射关系,然后将html源码中的加密内容与其进行映射就可以获取到明文内容了。
完整代码如下:
import requests
import re
from lxml import etree
from fontTools.ttLib import TTFont
class SendRequest:
def __init__(self):
self.url = 'https://www.qidian.com/rank/yuepiao/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
'referer': ''
}
self.session = requests.session()
def URequest(self):
response = self.session.get(self.url, headers=self.headers)
return response
class QiDian(SendRequest):
def getIndex(self):
response = self.URequest()
text_html = response.content.decode()
with open('qidian.html', 'w', encoding='utf-8')as f:
f.write(text_html)
woff_url = re.findall("format\('eot'\); src: url\('(.*?)'\) format\('woff'\)", text_html)[0]
self.url = woff_url
novel_titles = etree.HTML(text_html).xpath('//*[@id="book-img-text"]/ul/li/div[2]/h2/a/text()')
print(novel_titles)
tickets = re.findall('(.*?);月票', text_html)
print(tickets)
woff_res = self.URequest()
with open('qidian.woff', 'wb')as f:
f.write(woff_res.content)
font_file = TTFont('qidian.woff')
font_file.saveXML('qidian.xml')
best_map = font_file.getBestCmap()
return novel_titles, tickets, best_map
def dealFont(self):
novel_titles, tickets, best_map = self.getIndex()
zh_en = {
'zero': 0, 'one': 1, 'two': 2, 'three': 3,
'four': 4, 'five': 5, 'six': 6, 'seven': 7,
'eight': 8, 'nine': 9
}
result = {} # 用于存放最终的数据,键为书名,值为月票
for i, j in zip(novel_titles, tickets):
t_num = j.replace('&#', '').split(';') # 消除&#后以分号进行分割
print(t_num)
res_ticket = '' # 用于记录每一本书字体解密之后的内容
for l in t_num:
res_ticket += str(zh_en[best_map[int(l)]]) # 根据网站中提取出来的加密数据映射字体文件中
# 的目标值,然后由于目标值是英文所以需要映射成阿拉伯数字,最后进行连接称为该本书最终的月票信息
result[i] = res_ticket
print(result)
if __name__ == '__main__':
q = QiDian()
q.dealFont()
执行结果:

