C++多线程以及线程池
1 线程
1.1 简介
线程(英语:thread)是操作系统能够进行运算调度的最小单位。大部分情况下,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。一个进程可以有很多线程,每条线程并行执行不同的任务。在多核或多CPU,或支持Hyper-threading的CPU上使用多线程程序设计的好处是显而易见的,即提高了程序的执行吞吐率。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,从而提高了程序的执行效率。
1.2 线程的调度
线程作为CPU调度最基本的单位其状态和进程基本相同:
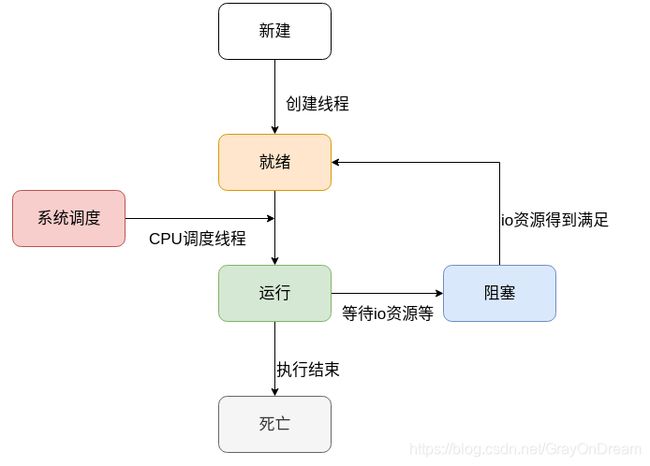
- 新建状态:当线程被创建到开始执行任务之间的状态,一般对应的是线程对象被创建到执行
start结构之间的过程; - 就绪状态:线程开始执行之后,只是表明线程准备好执行,需要CPU调度进行执行;
- 运行状态:线程被CPU翻牌子,开始执行任务;
- 阻塞状态:线程因为等待其他事件触发或者等待资源而发生阻塞,一般分为:
- 等待阻塞:线程执行了
wait; - 同步阻塞:因为同步锁获取失败,而进入阻塞;
- 其他阻塞:因等待获取IO资源而阻塞或者线程调用了
sleep;
- 等待阻塞:线程执行了
- 死亡状态:线程任务执行完成,可以被销毁。
线程调度算法其实是CPU调度算法,一般有:
- 先来先服务(FCFS)算法;
- 时间片轮转调度算法;
- 短作业优先算法;
- 最短剩余时间优先算法;
- 高响应比优先算法;
- 优先级调度算法;
- 多级反馈队列调度算法;
1.3 线程和进程的区别
- 线程是任务调度和执行的基本单位;进程是资源分配的基本单位;
- 单个进程可以包含多个线程,单个进程至少包含一个线程,不存在没有线程的进程,也没有不存在于进程的线程;
- 因为虚拟内存的关系不同的进程互相不知道对方的存在,相对独立,互相有独立的内存空间,地址空间;相同进程内的进程之间之间共享进程的内存空间,文件描述符表,部分寄存器等资源,但是每个线程都有自己独立的线程栈和部分寄存器,线程间访问资源需要考虑互斥问题;不同进程中的不同线程关系和不同进程关系相似,相对独立;
- 进程创建,销毁,切换代价大;线程创建,销毁,切换小。
进程和线程的优缺点:
- 进程有利于资源管理和保护,开销大;线程不利于资源管理和保护,需要使用锁保证线程的安全运行,开销小。
1.4 线程的通信方式
不同进程间的线程通信等同于进程通信,一般是五种通信方式:
- 消息队列;
- 共享内存;
- 有名管道/无名管道;
- 信号;
- scoket。
相同进程中的不同线程因为资源共享不存在通信问题,主要是资源的互斥访问,一般需要对资源进行加锁以防死锁。
1.5 内核线程和用户线程
线程的实现方式分为内核线程和用户线程。
内核级线程:由系统内核创建,撤销,调度的线程。
用户级线程:由用户进程自行调度的线程。
混合级线程:同时支持用户级线程和内核级线程。
内核级线程和用户级线程的区别:
- 内核线程需要操作系统支持,系统可知;用户级线程,系统调度资源分配是面向进程的,并不可知;
- 内核级线程创建、调度和撤销类似于进程;用户级线程创建和调度由用户进程控制,需要用户程序控制线程的调度工作;
- 内核级线程不同线程之间相对独立;用户线程中如果一个线程因其他原因而阻塞则导致整个进程阻塞,相同进程中的其他线程也被阻塞;
- 内核级线程资源竞争空间为全局;用户级线程资源竞争空间为当前进程。
内核级线程优缺点:
- 优点:
- 多核CPU友好,能够实现整整意义上的多线程;
- 如果单个进程中的一个线程被阻塞,进程中的其他线程仍然能够进程切换运行;
- 所有阻塞线程的调用都以系统调用实现,代价较小;
- 缺点:
- 由内核进行调度,用户的可定制性差;
- 线程在用户态运行,而线程的切换和调度相关操作在内核实现,进行线程切换时代价相对较高。
用户级线程的优缺点:
- 优点:
- 线程调度由用户控制,不需要内核参与,控制灵活,相对可控;
- 不需要内核支持,可以在不支持多线程的系统中实现;
- 线程创建、销毁、调度和切换等管理操作的代价比内核级线程小;
- 线程能够利用的表空间和堆栈空间比内核线程多;
- 缺点:
- 资源分配和调度按照进程进行,单个进程中同一时间只有一个线程运行,多处理机不友好;
- 当进程中的一个线程因缺页中断等原因阻塞时整个进程都会阻塞。
2 多线程
多线程(英语:multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-level multithreading)或同时多线程(Simultaneous multithreading)处理器。
多线程一般分为软件多线程和硬件多线程,分别通过软件实现和硬件支持。软件支持的多线程无法实现整整意义上的并发,硬件支持的多线程能够实现整整意义上的并发。
2.1 多线程模型
多线程模型分为:多对一,一对一,多对多。

多对一模型:
多个用户级线程映射到一个内核级线程。用户级线程对系统不可见,创建,调度,撤销的成本低效率高;当单个进程中的一个用户线程发生阻塞会导致进程阻塞。
一对一模型:
每一个用户线程映射到一个内核线程。并发能力强,不同线程之间相对独立;创建,调度,撤销需要调用系统调用,相对开销比较大。
多对多模型:
多个用户级线程映射到少许(<<用户线程数)内核线程。是对多对一和一对一模型的折中。
2.2 硬件层面的多线程支持
多线程的支持分为用户层,系统层(内核层),硬件层。其中只有硬件层的支持才能完全实现整整意义上的并发(同一时间多条指令运行),其他都只是感官上的多线程,实际上每个时刻只有一个线程在运行。
硬件层面的多线程实现分为:粗粒度交替多线程,细粒度交替多线程和同步多线程。
下图只是为了让读者更好的理解不同方式的区别,其中绿色和红色的框是随机画的并不完全准确。
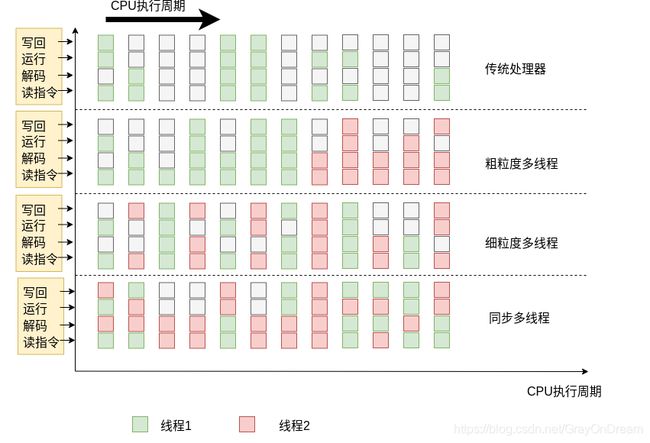
2.2.1 粗粒度交替多线程
粗粒度交替多线程中一个线程会一直运行到被一个外部事件导致无法继续运行为止才进行线程切换。该外部事件可以是:IO阻塞,程序分支,时间片结束等等高时延事件。
硬件成本:为了高效的线程切换,寄存器需要有两个实例。
许多微控制器与嵌入式处理器有多重的寄存器列,就能够在中断时快速环境切换。这样架构可以视为程序的线程与中断线程之间的块状多线程处理。
2.2.2 细粒度交替多线程
将CPU的周期轮转切换至不同的线程。更像是在时间片轮转的基础上再进行一次分割调度处理。
硬件成本:除了讨论块状多线程的硬件成本,交错式多线程也因每层管线需要追踪运行中指令的线程代码而增加硬件成本。而且,当越来越多的线程同时在管线中运行,像是缓存与 TLB 等共享资源也要加大来避免不同线程之间的冲突。
Intel Super-threading,Raza Microelectronics Inc XLR等处理器采用此方式。
2.2.3 同步多线程
同时多线程(Simultaneous multithreading,缩写SMT)也称同步多线程,是一种提高具有硬件多线程的超标量CPU整体效率的技术。同时多线程允许多个独立的执行线程更好地利用现代处理器架构提供的资源。
超标量(superscalar)CPU架构是指在一颗处理器内核中实行了指令级并发的一类并发运算。这种技术能够在相同的CPU主频下实现更高的CPU流量(throughput)。处理器的内核中一般有多个执行单元(或称功能单元),如算术逻辑单元、位移单元、乘法器等等。未实现超标量体系结构时,CPU在每个时钟周期仅执行单条指令,因此仅有一个执行单元在工作,其它执行单元空闲。超标量体系结构的CPU在一个时钟周期可以同时分派(dispatching)多条指令在不同的执行单元中被执行,这就实现了指令级的并行。超标量体系结构可以视作多指令流多数据流。
每个CPU周期,单个线程都会发布多个指令。
硬件成本:交错式多线程如果不计硬件成本,SMT在每个管线层次结构的追踪线程指令会有多余的花费。而且,像是缓存与TLB这类共享的资源可能会因为多出来的线程而变得更大。
Inter超线程,IBM Power5,AMD Bulldozer等都采用这种方式。
2.3 Thread API
2.3.1 C++11 API
2011年8月12日,国际标准化组织(ISO)发布了第三个C++标准,即ISO/IEC 14882:2011,简称ISO C++ 11标准。该标准第一次把线程的概念引入C++标准库。Windows平台运行的VS2012和Linux平台运行的g++4.7,都完美支持C++11线程。
标准库文档见:std::thread
//构造函数
thread() noexcept; //构造不表示线程的thread对象
thread( thread&& other ) noexcept; //移动拷贝构造函数,调用之后other不再是可执行线程
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args ); //构造可执行线程,f为需要线程执行的操作,args为可变参数,为f的参数
thread(const thread&) = delete; //禁用thread的拷贝构造
//析构函数
~thread() //析构前需要调用join()和detach()
//观察器
bool joinable() const noexcept; //检查 std::thread 对象是否标识活跃的执行线程,若 thread 对象标识活跃的执行线程则为 true ,否则为 false
std::thread::id get_id() const noexcept; //返回线程的 id
native_handle_type native_handle(); //返回底层实现定义的线程句柄
static unsigned int hardware_concurrency() noexcept;//返回支持的并发线程数。若该值非良定义或不可计算,则返回0,应该只把该值当做提示。
//操作
void join(); //阻塞当前线程直至 *this 所标识的线程结束其执行
void detach(); //从 thread 对象分离执行线程,允许执行独立地持续。一旦该线程退出,则释放任何分配的资源。调用 detach 后 *this 不再占有任何线程
void swap( std::thread& other ) noexcept; //交换二个 thread 对象的底层柄
示例:
#include 输出:
$thread 140737336633088 10
#thread 140737328240384 10
140737336633088 joinable:1
140737328240384 joinable:1
140737336633088 native handle :140737336633088
140737328240384 native handle :140737328240384
#thread 140737328240384 11
#thread 140737328240384 12
#thread 140737328240384 13
#thread 140737328240384 14
$thread 140737336633088 11
$thread 140737336633088 12
$thread 140737336633088 13
$thread 140737336633088 14
thread::id of a non-executing thread joinable:0
thread::id of a non-executing thread joinable:0
final value is 15
2.3.2 C11 API
//#include 2.3.3 Win API
//#include 2.3.4 Posix API
详细内容见POSIX线程
//#include 3 锁
锁这一块儿,稍微了解下,感觉还没有完全吃透,还需要更多实践才行。
3.1 死锁
死锁:当两个以上的运算单元,双方都在等待对方停止运行,以获取系统资源,但是没有一方提前退出时,就称为死锁。在多任务操作系统中,操作系统为了协调不同行程,能否获取系统资源时,为了让系统运作,必须要解决这个问题。
死锁的基本条件:
- 禁止抢占(no preemption):系统资源不能被强制从一个进程中退出;
- 持有和等待(hold and wait):一个进程可以在等待时持有系统资源;
- 互斥(mutual exclusion):资源只能同时分配给一个进程或者线程,无法多个进程或者线程共享;
- 循环等待(circular waiting):一系列进程互相持有其他进程所需要的资源。
死锁的四个条件缺一不可,一般如果需要解决死锁,破坏其中一个即可。
死锁理论上可以通过银行家算法进行预测,但是实际上系统资源量,需求量往往并不是能够准确估计的,因此死锁无法准确预测,只能尝试避免。
3.2 Linux系统中的锁
锁是为了避免多个运行单位对临界区的竞争访问,资源依赖进行限制,防止出现不可预见的错误,死锁等状况。
可重入锁:当线程获取某个锁后,还可以继续获取它,可以递归调用,而不会发生死锁。
不可重入锁:与可重入相反,获取锁后不能重复获取,否则会死锁(自己锁自己)。
3.2.1 自旋锁
自旋锁是用于多线程同步的一种锁,线程反复检查锁变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。自旋锁最多只能被一个可执行线程持有。如果一个执行线程试图获得一个被已经持有(争用)的自旋锁,那么该线程就会一直进行忙循环-旋转-等待锁重新可用要是锁未被争用,请求锁的执行线程就可以立即得到它,继续执行。
//#include 3.2.2 互斥锁
互斥锁(Mutual exclusion,缩写 Mutex)是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。该目的通过将代码切片成一个一个的临界区域(critical section)达成。临界区域指的是一块对公共资源进行访问的代码,并非一种机制或是算法。一个程序、进程、线程可以拥有多个临界区域,但是并不一定会应用互斥锁。
pthread_mutex_t lock; // 互斥锁定义
pthread_mutex_init(&lock, NULL); // 动态初始化, 成功返回0,失败返回非0
pthread_mutex_t thread_mutex = PTHREAD_MUTEX_INITIALIZER; // 静态初始化
pthread_mutex_lock(&lock); // 阻塞的锁定互斥锁
pthread_mutex_trylock(&thread_mutex);// 非阻塞的锁定互斥锁,成功获得互斥锁返回0,如果未能获得互斥锁,立即返回一个错误码
pthread_mutex_unlock(&lock); // 解锁互斥锁
pthread_mutex_destroy(&lock) // 销毁互斥锁
3.2.3 读写锁
读写锁是计算机程序的并发控制的一种同步机制,也称“共享-互斥锁”、多读者-单写者锁。多读者锁,push lock用于解决读写问题(readers–writers problem)。读操作可并发重入,写操作是互斥的。读写锁通常用互斥锁、条件变量、信号量实现。
//#include 3.2.4 RCU锁
RCU锁是对读写锁的一种改进,在性能上相比更加高效。
RCU(Read-Copy Update),对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。RCU实际上是一种改进的rwlock,读者几乎没有什么同步开销,它不需要锁。(CPU发生了上下文切换称为经历一个quiescent state)
rcu_read_lock() //读者在读取由RCU保护的共享数据时使用该函数标记它进入读端临界区
rcu_read_unlock() //该函数与rcu_read_lock配对使用,用以标记读者退出读端临界区
synchronize_rcu() //该函数由RCU写端调用,它将阻塞写者,直到经过grace period后,即所有的读者已经完成读端临界区,写者才可以继续下一步操作
synchronize_kernel() //其他非RCU的内核代码使用该函数来等待所有CPU处在可抢占状态,目前功能等同于synchronize_rcu,但现在已经不建议使用,而使用synchronize_sched
synchronize_sched() //该函数用于等待所有CPU都处在可抢占状态,它能保证正在运行的中断处理函数处理完毕,但不能保证正在运行的softirq处理完毕
void fastcall call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
//函数 call_rcu 也由 RCU 写端调用,它不会使写者阻塞,因而可以在中断上下文或 softirq 使用,而 synchronize_rcu、synchronize_kernel 和synchronize_shced 只能在进程上下文使用。该函数将把函数 func 挂接到 RCU回调函数链上,然后立即返回。一旦所有的 CPU 都已经完成端临界区操作,该函数将被调用来释放删除的将绝不在被应用的数据
void fastcall call_rcu_bh(struct rcu_head *head, void (*func)(struct rcu_head *rcu))
//函数call_ruc_bh功能几乎与call_rcu完全相同,唯一差别就是它把softirq的完成也当作经历一个quiescent state,因此如果写端使用了该函数,在进程上下文的读端必须使用rcu_read_lock_bh
#define rcu_dereference(p) ({ \
typeof(p) _________p1 = p; \
smp_read_barrier_depends(); \
(_________p1); \
})
//该宏用于在RCU读端临界区获得一个RCU保护的指针,该指针可以在以后安全地引用,内存栅只在alpha架构上才使用
static inline void list_add_rcu(struct list_head *new, struct list_head *head)
//该函数把链表项new插入到RCU保护的链表head的开头
static inline void list_add_tail_rcu(struct list_head *new,struct list_head *head)
//该函数类似于list_add_rcu,它将把新的链表项new添加到被RCU保护的链表的末尾
static inline void list_del_rcu(struct list_head *entry)
//该函数从RCU保护的链表中移走指定的链表项entry,并且把entry的prev指针设置为LIST_POISON2,但是并没有把entry的next指针设置为LIST_POISON1,因为该指针可能仍然在被读者用于便利该链表
static inline void list_replace_rcu(struct list_head *old, struct list_head *new)
//该函数是RCU新添加的函数,并不存在非RCU版本。它使用新的链表项new取代旧的链表项old,内存栅保证在引用新的链表项之前,它的链接指针的修正对所有读者可见
list_for_each_rcu(pos, head)//该宏用于遍历由RCU保护的链表head,只要在读端临界区使用该函数,它就可以安全地和其它_rcu链表操作函数
list_for_each_safe_rcu(pos, n, head)
//该宏类似于list_for_each_rcu,但不同之处在于它允许安全地删除当前链表项pos
list_for_each_entry_rcu(pos, head, member)
//该宏类似于list_for_each_rcu,不同之处在于它用于遍历指定类型的数据结构链表,当前链表项pos为一包含struct list_head结构的特定的数据结构
list_for_each_continue_rcu(pos, head)
//该宏用于在退出点之后继续遍历由RCU保护的链表head
static inline void hlist_del_rcu(struct hlist_node *n)
//它从由RCU保护的哈希链表中移走链表项n,并设置n的ppre指针为LIST_POISON2,但并没有设置next为LIST_POISON1,因为该指针可能被读者使用用于遍利链表
static inline void hlist_add_head_rcu(struct hlist_node *n,struct hlist_head *h)
//该函数用于把链表项n插入到被RCU保护的哈希链表的开头,但同时允许读者对该哈希链表的遍历。内存栅确保在引用新链表项之前,它的指针修正对所有读者可见
hlist_for_each_rcu(pos, head)//该宏用于遍历由RCU保护的哈希链表head,只要在读端临界区使用该函数,它就可以安全地和其它_rcu哈希链表操作函数(如hlist_add_rcu)并发运行
hlist_for_each_entry_rcu(tpos, pos, head, member)
//类似于hlist_for_each_rcu,不同之处在于它用于遍历指定类型的数据结构哈希链表,当前链表项pos为一包含struct list_head结构的特定的数据结构
3.2.5 条件变量
条件变量是用来等待线程而不是上锁的,通常和互斥锁一起使用。互斥锁的一个明显的特点就是某些业务场景中无法借助系统来唤醒,仍然需要业务代码使用while来判断,这样效率本质上比较低。而条件变量通过允许线程阻塞和等待另一个线程发送信号来弥补互斥锁的不足,所以互斥锁和条件变量通常一起使用,来让条件变量异步唤醒阻塞的线程。
int pthread_cond_init(pthread_cond_t *cond,pthread_condattr_t *cond_attr);
int pthread_cond_wait(pthread_cond_t *cond,pthread_mutex_t *mutex);
int pthread_cond_timewait(pthread_cond_t *cond,pthread_mutex *mutex,const timespec *abstime);
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond); //解除所有线程的阻塞
4 线程池
4.1 简介
线程池(thread pool)是一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。 例如,线程数一般取cpu数量+2比较合适,线程数过多会导致额外的线程切换开销。
任务调度以执行线程的常见方法是使用同步队列,称作任务队列。池中的线程等待队列中的任务,并把执行完的任务放入完成队列中。
4.2 线程池模式
线程池模式分为:HS/HA半同步/半异步模式、L/F领导者与跟随者模式。
- 半同步/半异步模式又称为生产者消费者模式,是比较常见的实现方式,比较简单。分为同步层、队列层、异步层三层。同步层的主线程处理工作任务并存入工作队列,工作线程从工作队列取出任务进行处理,如果工作队列为空,则取不到任务的工作线程进入挂起状态。由于线程间有数据通信,因此不适于大数据量交换的场合;
- 领导者跟随者模式,在线程池中的线程可处在3种状态之一:领导者leader、追随者follower或工作者processor。任何时刻线程池只有一个领导者线程。事件到达时,领导者线程负责消息分离,并从处于追随者线程中选出一个来当继任领导者,然后将自身设置为工作者状态去处置该事件。处理完毕后工作者线程将自身的状态置为追随者。这一模式实现复杂,但避免了线程间交换任务数据,提高了CPU cache相似性。在ACE(Adaptive Communication Environment)中,提供了领导者跟随者模式实现。
4.3 线程池的优点
- 提高资源利用率。可以重复使用已经创建了的线程资源;
- 提高响应速度。当线程池中的线程没有超过线程池的最大上限时,有的线程处于等待分配任务状态,当任务到来时,无需创建线程就能被执行;
- 高度可控,可管理。线程池会根据当前系统特点对池内的线程进行优化处理,减少创建和销毁线程带来的系统开销。
线程池的伸缩性对性能有较大的影响:
- 创建太多线程,将会浪费一定的资源,有些线程未被充分使用;
- 销毁太多线程,将导致之后浪费时间再次创建它们;
- 创建线程太慢,将会导致长时间的等待,性能变差;
- 销毁线程太慢,导致其它线程资源饥饿。
4.4 简单的线程池实现
#include 输出:
thread 140737336633088 begin to work!
thread 140737328240384 begin to work!
thread 140737319847680 begin to work!
thread 140737311454976 begin to work!
thread 140737303062272 begin to work!
thread 140737219917568 begin to work!
thread 140737211524864 begin to work!
thread 140737203132160 begin to work!
thread 140737194739456 begin to work!
thread 140737186346752 begin to work!
#thread working in func2 in thread 140737336633088;n is 0
#thread working in func2 in thread 140737328240384;n is 1
#thread working in func2 in thread 140737319847680;n is 2
#thread working in func2 in thread 140737311454976;n is 3
#thread working in func2 in thread 140737303062272;n is 4
#thread working in func2 in thread 140737219917568;n is 5
#thread working in func2 in thread 140737211524864;n is 6
#thread working in func2 in thread 140737203132160;n is 7
#thread working in func2 in thread 140737194739456;n is 8
#thread working in func2 in thread 140737186346752;n is 9
#thread working in func2 in thread 140737336633088;n is 10
#thread working in func2 in thread 140737328240384;n is 11
#thread working in func2 in thread 140737319847680;n is 12
#thread working in func2 in thread 140737311454976;n is 13
#thread working in func2 in thread 140737303062272;n is 14
#thread working in func2 in thread 140737219917568;n is 15
#thread working in func2 in thread 140737211524864;n is 16
#thread working in func2 in thread 140737203132160;n is 17
#thread working in func2 in thread 140737194739456;n is 18
#thread working in func2 in thread 140737186346752;n is 19
thread 140737336633088 going to die!
thread 140737328240384 going to die!
thread 140737319847680 going to die!
thread 140737303062272 going to die!
thread 140737311454976 going to die!
thread 140737211524864 going to die!
thread 140737203132160 going to die!
thread 140737194739456 going to die!
thread 140737219917568 going to die!
thread 140737186346752 going to die!
5 参考
- 用户级线程和内核级线程的区别
- 线程的3种实现方式–内核级线程, 用户级线程和混合型线程
- 用户级线程和内核级线程的区别
- Linux系统编程——用户级线程和内核级线程区别
- 进程间通信的几种方式
- 维基-单线程
- 维基-多线程
- 维基-线程池
- CMP读书笔记三:提高吞吐量
- 维基-同时多线程
- 超标量
- 指令流水线
- POSIX线程
- linux中读写锁的rwlock介绍-nk_ysg-ChinaUnix博客
- 维基-读写锁
- 维基-互斥锁
- 维基-自旋锁
- Linux中的各种锁及其基本原理
- Linux内核同步方法——自旋锁(spin lock)
- Linux C 互斥锁的使用
- Linux 2.6内核中新的锁机制–RCU