iframe如何发送请求_如何实现高性能的在线 PDF 预览
本文首发于政采云前端团队博客:如何实现高性能的在线 PDF 预览
https://www.zoo.team/article/pdf-preview

引言
最近接到产品需求,用户需要在我们的站点上在线查看 PDF 文件,并且查看时,用户可以对 PDF 文件的进行旋转、缩放、跳转到指定页码等操作。
这个太简单了,随便找找就一堆轮子。目前常见的在线 PDF 查看方案:使用 iframe、embed、object 标签直接加载
采用此方案,只需要直接将 PDF 的在线地址设置为标签的 src 属性
- 使用第三方库 PDF.js 加载
这个方案麻烦一点,我们需要在项目中引入 PDF.js 这个库,然后再使用 iframe 来加载指定的 HTML 文件(下文代码中的 viewer.html ),并且将需要访问的 PDF 的在线地址作为参数传递进去。大概就像下面一样:
showPdf (selector, options) {
const { width, height, fileUrl } = options;
this.pdfFrame = document.createElement('iframe');
this.pdfFrame.width = width;
this.pdfFrame.height = height;
this.pdfFrame.src = `./assets/web/viewer.html?file=${encodeURIComponent(fileUrl)}`;
document.getElementById(selector).append(this.pdfFrame);
}
这里可能会遇到跨域的问题,不过不是本文重点,不展开讲,相信这种小事难不倒聪明的你。
于是乎,啪啪啪几行代码迅速搞定给产品演示。然后产品拿了个线上文件来尝试效果。。。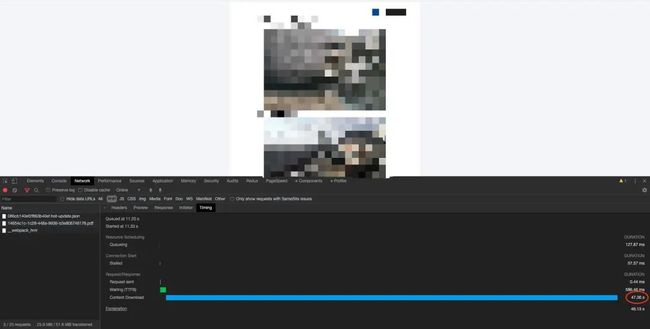 BEDC8D6B-827A-4883-8A27-52B6372517A5.png 两人对着白屏尴尬的沉默良久,产品终于忍不住了。“这怎么这么慢?不行,用户肯定不能接受。。。”“公司网络不好... 你这文件太大了... 你重启一下试试?“
BEDC8D6B-827A-4883-8A27-52B6372517A5.png 两人对着白屏尴尬的沉默良久,产品终于忍不住了。“这怎么这么慢?不行,用户肯定不能接受。。。”“公司网络不好... 你这文件太大了... 你重启一下试试?“
不存在的,作为一个优秀的前端开发者,怎么可以说这种话,当然是想办法解决啦。
重新整理一下产品的需求:
- 页面上查看服务器上的 pdf 文件
- 支持页码跳转、旋转、缩放
- 打开要快
方案思路 - PDF 内容分片加载
因为用户不可能一眼看到所有的 PDF 内容,每次只能看到屏幕显示范围内的几页。所以我们可以将可视范围内的PDF 页面内容优先下载并展示,可视范围外的我们根据用户浏览的实际位置按需下载和渲染。这样就可以减少第一次打开时用户的等待时间了。(类似与数据分页、图片懒加载的思想,目的是提高首屏性能。)
那么我们可以将一个大的 PDF 文件分成多个小文件,即分片。比如某个 PDF 有 200 页,我们按照 5 页一片,将它切分成 40 片,每次只下载用户看到的那一个分片。然后在用户进行滚动翻页的时候,异步的去下载对应包含对应页的分片。基本的思路有了,接下来就是想办法实现了。要实现分片加载我们需要做两件事情:1、服务器对 PDF 文件进行分片
由于这个是服务器做了,所以,交给后端就好了。本文不细讲,大家有兴趣的可以去了解 itextpdf (https://api.itextpdf.com/iText5/java/5.5.11/) 库,它提供了相关 API 对 PDF 进行切片。我们需要跟后端约定好 PDF 文件分片之后每一片的数据格式。假如分片的大小为 5(即每次请求 5 页内容),那么可以定义数据格式如下:{
"startPage": 1, // 分片的开始页码
"endPage": 5, // 分片结束页码
"totalPage": 100, // pdf 总页数
"url": "http://test.com/asset/fhdf82372837283.pdf" // 分片内容下载地址
}
2、客户端根据用户交互行为获取并渲染指定的分片
显然,获取并渲染是两个操作。为了保证用户操作(滚动)的流畅性,这两个操作我们都异步进行。至此,我们需要解决的关键问题变成两个:- 如何下载 PDF 分片
- 如何渲染 PDF 分片
知识准备 - PDF.js 接口介绍
由于我们无法在已有标签上做修改,所以我们考虑基于 PDF.js 库进行深度定制。那么我们先了解一下 PDF.js 可以为我们提供哪些能力。参考 官方文档 (https://mozilla.github.io/pdf.js),下面列举了我们需要用到的几个 API ,由于官方文档中内容比较粗,这里贴上了源码中的注释。另附 源码地址 (https://github.com/mozilla/pdf.js/blob/12aba0f91a5cd3e36fa81cb799540f8073990831/src/display/api.js#L431)。获取远程的 pdf 文档
/**
* This is the main entry point for loading a PDF and interacting with it.
* NOTE: If a URL is used to fetch the PDF data a standard XMLHttpRequest(XHR)
* is used, which means it must follow the same origin rules that any XHR does
* e.g. No cross domain requests without CORS.
*
* @param {string|TypedArray|DocumentInitParameters|PDFDataRangeTransport} src
* Can be a url to where a PDF is located, a typed array (Uint8Array)
* already populated with data or parameter object.
* @returns {PDFDocumentLoadingTask}
*/简单的说就是,getDocument 接口可以获取 src 指定的远程 PDF 文件,并返回一个 PDFDocumentLoadingTask 对象。后续所有对 PDF 内容的操作都可以通过改对象实现。
PDFDocumentLoadingTask
/**
* The loading task controls the operations required to load a PDF document
* (such as network requests) and provides a way to listen for completion,
* after which individual pages can be rendered.
*/PDFDocumentLoadingTask 是一个下载远程 PDF 文件的任务。它提供了一些监听方法,可以监听 PDF 文件的下载状态。通过 promise 可以获取到下载完成的 PDF 对象,它会生成并最终返回一个 PDFDocumentProxy 对象。
PDFDocumentProxy
/**
* Proxy to a PDFDocument in the worker thread. Also, contains commonly used
* properties that can be read synchronously.
*/PDFDocumentProxy 是 PDF 文档代理类,我们可以通过它的 numPages 获取到文档的页面数量,通过 getPage 方法获取到指定页码的页面 PDFPageProxy 实例。
PDFPageProxy
/**
* Proxy to a PDFPage in the worker thread.
* @alias PDFPageProxy
*/实现细节
下载 PDF 分片
首先我们使用 PDF.js 提供的接口获取第一个分片的 url,然后再下载该分片的 PDF 文件。/*
代码中使用 loadStatus 来记录特定页的内容是否一件下载
*/渲染 PDF 分片
PDF 分片内容下载完成之后,我们就可以将其渲染到页面上。渲染之前,我们需要知道 PDF 页面的大小。调用 PDF.js 提供的方法,我们能够根据当前 PDF 的缩放比例、选择角度来获取页面的实际大小。// 获取单页高度然后我们需要创建一个内容渲染的区域,需要计算出内容的总高度(总高度 = 单页高度 * 总页数)。
// 为了不让内容太拥挤,我们可以加一些页面间距 PAGE_INTVERVAL之后我们就可以根据 pdf 的页码来将其内容渲染到指定区域。
// 我们可以通过 scale 和 rotaion 的值来控制 pdf 文档缩放、旋转滚动加载内容
上面我们已经将第一个分片进行了展示,但是当用户进行滚动时,我们需要更新内容的显示。首先根据滚动的位置,计算出当前需要展示的页面,然后下载包含该页面的分片。// 监听容器的滚动事件,触发 scrollPdf 方法做一些优化
PDF 文件可能会很大,比如一个 1000 页的 PDF 文件。随着用户的滚动浏览,它会一直渲染,如果最终同时将 1000 个页面的 dom 全部放到页面上。那么内存占用将会非常多,导致页面卡顿。因此,为了减少内存占用,我们可以将当前可视范围之外的页面元素清除。// 首先我们获取到需要渲染的范围总结 & 遇到的坑
我们在程序设计中,遇到请求数据较大、任务执行时间过长等场景时很容易想到通过数据切分、任务分片等方式来提升程序在系统中的执行&响应效果。本文介绍的问题便是将大的 PDF 文件拆分,然后根据用户的交互行为按需加载,从而达到提升用户在线阅读体验的目的。当然上述方案还存在很多优化空间,比如我们可以通过 IntersectionObserver API 结合容器 margin 的调整来实现 PDF 内容的滚动及页面元素的复用。具体的实现大家有兴趣可以自己尝试。实际使用场景中,我们也遇到了一些坑。上述方案在进行页面渲染时,会预先初始化整个容器( contentView)的大小。并且我们是根据第一次获取的 PDF 页面的大小进行计算容器高度的(页面高度 * 总页数)。这里有一个前提,就是我们假定所有的 PDF 页面大小是一样的,但在实际场景中,很可能出现同一个 PDF 文档中,页面大小不一样的情况。这时就会出现加载页面位置不准确或者内容展示被遮挡的情况。针对上述问题,目前我们思考了两种方案:将大小不一样的页面进行缩放。当我们发现页面大小和保存的 pageSize 不一致时,可以将当前页进行缩放,这样就将所有页面的大小转化成了一样。但是这样做用户体验会有所影响,因为用户看到的页面内容大小可能和他实际上传的不一样。
可以在服务器上提前计算好每一页的页面大小,返回给前端。前端在渲染指定页时,根据服务器返回的数据进行来计算页面位置。但是这样需要在前端做大量的计算。渲染性能上会受到一些影响。
看完两件事
如果你觉得这篇内容对你挺有启发,我想邀请你帮我两件小事1.点个「 在看」,让更多人也能看到这篇内容(点了 「 在看 」,bug -1 )2.关注公众号「 政采云前端团队」,持续为你推送精选好文招贤纳士
政采云前端团队(ZooTeam),一个年轻富有激情和创造力的前端团队,隶属于政采云产品研发部,Base 在风景如画的杭州。团队现有 50 余个前端小伙伴,平均年龄 27 岁,近 3 成是全栈工程师,妥妥的青年风暴团。成员构成既有来自于阿里、网易的“老”兵,也有浙大、中科大、杭电等校的应届新人。团队在日常的业务对接之外,还在物料体系、工程平台、搭建平台、性能体验、云端应用、数据分析及可视化等方向进行技术探索和实战,推动并落地了一系列的内部技术产品,持续探索前端技术体系的新边界。如果你想改变一直被事折腾,希望开始能折腾事;如果你想改变一直被告诫需要多些想法,却无从破局;如果你想改变你有能力去做成那个结果,却不需要你;如果你想改变你想做成的事需要一个团队去支撑,但没你带人的位置;如果你想改变既定的节奏,将会是“5 年工作时间 3 年工作经验”;如果你想改变本来悟性不错,但总是有那一层窗户纸的模糊… 如果你相信相信的力量,相信平凡人能成就非凡事,相信能遇到更好的自己。如果你希望参与到随着业务腾飞的过程,亲手推动一个有着深入的业务理解、完善的技术体系、技术创造价值、影响力外溢的前端团队的成长历程,我觉得我们该聊聊。任何时间,等着你写点什么,发给 [email protected]
