Concurrency-with-Modern-Cpp学习笔记 std::atomic模板
std::atomic模板
std::atomic有各种变体。
直接使用模板类:std::atomic 和 std::atomic。
部分特化可用于指针类:std::atomic。
完全特化只能用于整型:std::atomic。
布尔原子类型和用户定义原子类型具有相同的接口,原子指针扩展了布尔原子类型,以及整数原子类型的接口。因其扩展了原子指针的接口,所以同样适用于整数原子类型。
不过,不保证std::atomic的各种变体都是无锁的。
std::atomic
std::atomic的功能比std::atomic_flag强大很多。并且,可以显式地将其设置为true或false。
原子类型不可为volatile
C#和Java中的volatile与C++中的volatile不同,这也是volatile和std::atomic之间的区别。
volatile:表示不允许对特定的对象进行读写优化。std::atomic:用来定义线程安全的原子变量。
volatile在Java和C#中,与std::atomic在C++中的含义相同。另外,在C++多线程语义中,没有volatile。
volatile多应用于嵌入式编程中,表示可以(独立于常规程序流)进行更改的对象,例如:表示外部设备的对象(内存映射I/O)。由于这些对象可以更改,并且会直接写入主存中,因此不会在缓存中进行优化存储。
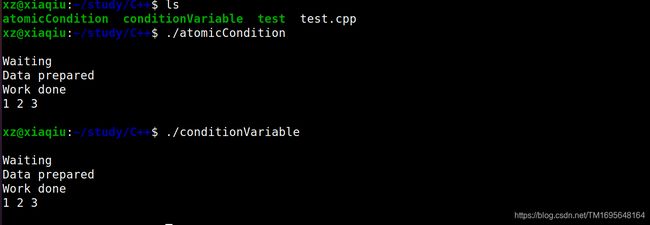
这对于同步两个线程已经足够了,可以用std::atomic实现条件变量。
// conditionVariable.cpp
#include 线程t1在(condVar.wait(lck, [] {return dataReady;});)等待线程t2的通知。两个线程使用相同的条件变量condVar,并在同一个互斥锁上进行同步。工作流如下所示:
线程t1
- 获取锁
lck时,等待数据准备好的通知condVar.wait(lck, []{ return dataReady; })。 - 得到通知后,执行
mySharedWork[1] = 2。
线程t2
- 准备数据
mySharedWork = {1, 0, 3} - 将非原子布尔类型的
dataReady置为true。 - 通过
condVar.notify_one发布通知。
线程t2将dataReady设置为true,线程t1使用Lambda表达式对dataReady进行检查。不过,条件变量可能会出现两种不好的情况:
- 伪唤醒:接受者在没有收到通知时被唤醒。
- 未唤醒:接收方在未处于等待状态时获得通知。
使用std::atomic进行实现:
// atomicCondition.cpp
#include 如何保证2在1之后执行?或者说,线程t1在线程t2执行mySharedWork ={1,0,3}后。
-
3
mySharedWork = {1, 0, 3}happens-before 4dataReady = true -
1
while (!dataReady.load())happens-before 2mySharedWork[1] = 2 -
4
dataReady = true与 1while (!dataReady.load())同步 -
因为同步建立了先行关系,并且先行关系可以传递,所以
mySharedWork = {1,0,3}先于mySharedWork[1] = 2执行。两段程序产生了相同的结果。
推拉原理
条件变量的同步与std::atomic之间有一个关键性的区别。条件变量会让线程等待通知(condVar.notify())。检查std::atomic的线程,只是为了确定发送方是否完成了其工作(dataRead = true)。
条件变量通知等待线程对应为"推原则(push principle)",而原子布尔值的重复轮询对应为"拉原则(pull principle)"。
std::atomic和std::atomic的其他全/偏特化都支持的原子操作:compare_exchange_strong和compare_exchange_strong。
compare_exchange_strong和compare_exchange_weak
compare_exchange_strong的声明为bool compare_exchange_strong(T& expected, T& desired)。此操作为比较和交换,因此也称为比较-交换(compare and swap,CAS)操作。这种操作在许多编程语言中都有用到,并且是非阻塞算法的基础。当然,C++中的行为可能会与其他语言不同。atomicValue.compare_exchange_strong(expected, desired)具有以下行为。
-
如果
atomicValue的值与期望值(expected)的比较返回true,则将atomicValue设置为所需值(desired)。 -
如果比较返回false,则将expected值设置为
atomicValue的值。
compare_exchange_strong称为strong的原因显而易见。当然,还有一个compare_exchange_weak,weak版本可能会伪失败。这意味着,虽然*atomicValue == expected成立,但atomicValue没有被设置成desired,函数返回false,因此必须在循环中进行检查:while (!atomicValue.compare_exchange_weak(expected, desired))。弱形式的存在原因是,因为一些处理器(硬件)不支持原子比较交换指令。循环调用时,也应该首选弱形式。在某些平台上,弱形式运行得更快。
CAS操作对于ABA问题,解决方式是开放的。先描述一下这个问题:读取一个值两次,每次都返回相同的值A;因此得出结论,在这两者之间没有变化。但是,两次读取过程中数值可能已经更改为B了。
弱版本允许伪失败,也就是说,即使它们是相等的,结果也和*this !=expected一样。当比较-交换操作处于循环中时,弱版本可能在某些平台上具有更好的性能。
除了布尔值之外,还有指针、整型和用户定义类型的原子操作。所有std::atomic的变种类型都支持CAS操作。
用户定义类型的原子操作std::atomic
因为std::atomic是模板类,所以可以使用自定义的原子类型。使用自定义类型用于原子类型std::atomic时,有很多限制。
原子类型std::atomicstd::atomic具有相同的接口。
以下是自定义类型成为原子类型的限制:
- 自定义类型对所有基类和有非静态成员的复制赋值操作必须非常简单。这意味着不能定义复制赋值操作符,但是可以使用default让编译器来完成这个操作符的定义。
- 自定义的类型不能有虚方法或虚基类。
- 自定义的类型必须可按位比较,这样才能使用C函数memcpy或memcmp。
主流平台都可以对std::atomic进行原子操作,前提是用户定义类型的大小不大于int。
编译时的类型属性
可以使用以下函数在编译时,检查自定义类型的类型属性:std::is_trivially_copy_constructible, std:: is_polymorphic和std::is_trivial。这些函数都是类型特征库(type-traits library)的一部分。
std::atomic
std::atomic是std::atomic类模板的偏特化类型。原子指针std::atomic支持与std::atomic 或std::atomic相同的成员函数。它的行为就像一个普通的指针T*。std::atomic支持指针运算和前后递增或前后递减操作。
看个简单的例子。
int intArray[5];
std::atomic<int*> p(intArray);
p++;
assert(p.load() == &intArray[1]);
p+=1;
assert(p.load() == &intArray[2]);
--p;
assert(p.load() == &intArray[1]);
在C++11中,有原子整型。std::atomic
对于每个整数类型,都有相应的全特化std::atomic版本。
对于哪些整型存做了全特化?让我们来看一下:
• 字符类型: char 、 char16_t 、 char32_t 和 wchar_t
• 标准有符号整数类型:signed char、short、int、long 和 long long
• 标准无符号整数类型: unsigned char 、 unsigned short 、 unsigned int 、 unsigned
long 和 unsigned long long
• 额外的整数类型,在头文件 ²⁰ 中定义:
- int8_t , int16_t , int32_t 和 int64_t (8, 16, 32 和 64位的有符号整型)
- uint8_t , uint16_t , uint32_t 和 uint64_t (8, 16, 32 和 64位的无符号整型)
- int_fast8_t , int_fast16_t , int_fast32_t 和 int_fast64_t (8, 16, 32 和 64位的高速有符号整型)
- uint_fast8_t , uint_fast16_t , uint_fast32_t 和 uint_fast64_t (8, 16, 32 和 64 位的高速无符号整型)
- int_least8_t , int_least16_t , int_least32_t 和 int_least64_t (8, 16, 32 和 64 位的最小有符号整型)
- uint_least8_t , uint_least16_t , uint_least32_t 和 uint_least64_t (8, 16, 32 和 64 位的最小无符号整型)
- intmax_t 和 uintmax_t (最大有符号整数和无符号整数)
- intptr_t 和 uintptr_t (用于存放有符号整数和无符号整数指针)
std::atomic支持复合赋值运算符+=、-=、&=、|=和^=,以及相应操作的方法:fetch_add、fetch_sub、fetch_and、fetch_or和fetch_xor。复合赋值运算符返回新值,而fetch操作返回旧值。此外,复合赋值运算符还支持前增量和后增量,以及前减量和后减量(++x, x++,–x和x–)。
更深入的研究前需要了解一些前提:原子操作没有原子乘法、原子除法,也没有移位操作。这不是重要的限制,因为这些操作很少需要,并且很容易实现。下面就是是实现原子fetch_mult的例子。
// fetch_mult.cpp
#include 值得一提的一点是,while (!shared.compare_exchange_strong(oldValue, oldValue * mult));中的乘法仅在关系 oldValue == shared 成立时才会发生。 我将乘法放在 while 循环中以确保乘法总是发生,因为有两条指令用于读取T oldValue = shared.load();中的 oldValue 并在while (!shared.compare_exchange_strong(oldValue, oldValue * mult));中使用它。这是原子乘法的结果。

fetch_mult无锁
算法T fetch_mult(std::atomic std::atomic 乘以 T mult。 关键是在读取旧值 T oldValue = shared Load和与while (!shared.compare_exchange_strong(oldValue, oldValue * mult));中的新值进行比较之间有一个小的时间窗口。因此另一个线程总是可以介入并更改 oldValue 。 如果您考虑错误的线程交错,您会发现没有每个线程的保证。
该算法是无锁的,但不是无等待的。
类型别名
对于所有 std::atomic 和所有 std::atomic,如果整数类型可用,C++ 标准提供类型别名。
所有原子操作
这是关于所有原子操作的列表。
| 成员函数 | 描述 |
|---|---|
| test_and_set | (原子性地)将标记设置为true,并返回旧值 |
| clear | (原子性地)将标记设置为false |
| is_lock_free | 检查原子是否无锁 |
| load | (原子性地)返回原子变量的值 |
| store | (原子性地)将原子变量的值替换为非原子值 |
| exchange | (原子性地)用新值替换值,返回旧值 |
| compare_exchange_strong | (原子性地)比较并交换值 |
| compare_exchange_weak | (原子性地)比较并交换值 |
| fetch_add , += | (原子性地)加法 |
| fetch_sub , -= | (原子性地)减法 |
| fetch_or , |= | (原子性地)逻辑或 |
| fetch_and , &= | (原子性地)逻辑与 |
| fetch_xor , ^= | (原子性地)逻辑异或 |
| ++ , – | (原子性地)自加和自减 |
原子类型没有复制构造函数或复制赋值操作符,但支持从内置类型进行赋值和隐式转换。复合赋值运算符返回新值,fetch操作返回旧值。复合赋值运算符返回值,而不是所赋值对象的引用。
隐式转换为基础类型
std::atomic<long long> atomOb(2011j;
atomObj = 2014;
long long nonAtomObj = atomObj;
每个方法都支持内存序参数。默认的内存序是std::memory_order_seq_cst,也可以使用std::memory_order_relaxed, std::memory_order_consume, std::memory_order_acquire, std::memory_order_release或std::memory_order_acq_rel。compare_exchange_strong和 compare_exchange_weak可以传入两个内存序,一个是在比较成功的情况下所使用的内存序,另一个是在比较失败的情况下使用的。
如果只显式地提供一个内存序,那么成功和失败的情况都会使用该内存序.
原子函数
为了与C语言兼容,这些函数使用的是指针而不是引用。所以,std::atomic_flag和类模板std::atomic的功能也可以与原子函数一起使用。
std::atomic_flag的原子函数有:
std::atomic_flag_clear()、std::atomic_flag_clear_explicit、std::atomic_flag_test_and_set()和std::atomic_flag_test_set_explicit()。
所有函数的第一个参数都是指向std::atomic_flag的指针。另外,以_explicit为后缀的函数需要传入内存序。
对于每个std::atomic类型,都有相应的原子函数。原子函数遵循一个简单的命名约定:只在前面添加前缀atomic_。例如,std::atomic上的方法调用at.store()变成std::atomic_store(), std::atomic_store_explicit()。std::shared_ptr算是个例外,其原子函数只能在原子类型上使用
std::shared_ptr
std::shared_ptr 是唯一可以应用原子操作的非原子数据类型。
C++ 委员会认为智能指针的实例应该提供最少的多线程程序中的原子性保证。,所以做出了这样的设计。先来解释“最小原子性保证”,也就是std::shared_ptr的控制块是线程安全的,这意味着增加和减少引用计数器的是原子操作,也就能保证资源只被销毁一次了。
shared_ptr实例可以被多个线程同时“读”(仅const方式访问)。- 不同的
shared_ptr实例可以被多个线程同时“写”(通过操作符=或reset等操作访问)(即使这些实例是副本,但在底层共享引用计数)。
为了使这两个表述更清楚,举一个简单的例子。当在一个线程中复制std::shared_ptr时,一切正常。
std::shared_ptr 的线程安全copy
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++)
{
std::thread([ptr]{
std::shared_ptr<int> localPtr(ptr);
localPtr = std::make_shared<int>(2014);
}).detach();
}
通过对std::shared_ptr localPtr使用复制构造,只使用控制块,这是线程安全的。为localPtr设置了一个新的std::shared_ptr。从多线程的角度来看,这不是问题:Lambda函数通过复制绑定ptr。因此,对localPtr的修改在副本上进行。
如果通过引用获得std::shared_ptr
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++)
{
std::thread([&ptr]{
ptr = std::make_shared<int>(2014);
}).detach();
}
Lambda函数通过引用,绑定了std::thread([&ptr]中的std::shared_ptr ptr。这意味着,赋值ptr = std::make_shared可能触发底层的并发读写,所以该段程序具有未定义行为(数据竞争)。
最后一个例子并不容易实现,但在多线程环境下使用std::shared_ptr也需要特别注意。同样需要注意的是,std::shared_ptr是C++中唯一存在原子操作的非原子数据类型。
std::shared_ptr的原子操作
std::shared_ptr的原子操作load、store、compare_and_exchange有专用的方法,甚至可以指定内存序。下面是std::shared_ptr的原子函数。
std::shared_ptr的原子函数列表
`std::atomic_is_lock_free(std::shared_ptr)` `std::atomic_load(std::shared_ptr)` `std::atomic_load_explicit(std::shared_ptr)` `std::atomic_store(std::shared_ptr)` `std::atomic_store_explicit(std::shared_ptr)` `std::atomic_exchange(std::shared_ptr)` `std::atomic_exchange_explicit(std::shared_ptr)` `std::atomic_compare_exchange_weak(std::shared_ptr)` `std::atomic_compare_exchange_strong(std::shared_ptr)` `std::atomic_compare_exchange_weak_explicit(std::shared_ptr)` `std::atomic_compare_exchange_strong_explicit(std::shared_ptr)`
std::shared_ptr数据竞争的解决
std::shared_ptr<int> ptr = std::make_shared<int>(2011);
for (auto i = 0; i < 10; i++)
{
std::thread([&ptr]{
auto localPtr = std::make_shared<int>(2014);
std::atomic_store(&ptr, localPtr);
}).detach();
}