C++ 杂记
Manipulator操纵符
//使用有参数的操纵符include 类型转换
static_cast
'static_cast’允许执行任意的隐式转换和相反转换动作。(即使它是不允许隐式的)
应用到类的指针上,意思是说它允许子类类型的指针转换为父类类型的指针(这是一个有效的隐式转换),同时,也能够执行相反动作:转换父类为它的子类。
double a = 1.999;
int b = static_cast(a); //相当于a = b
- 用于非多态类型的转换
- 没有运行时类型检查来保证转换的安全性(转换安全性不如 dynamic_cast)
- 通常用于转换数值数据类型(如 float -> int)
- 可以在整个类层次结构中移动指针,子类转化为父类安全(向上转换),父类转化为子类不安全(因为子类可能有不在父类的字段或方法)
char a = 'a';
int b = static_cast<char>(a);//将char型数据转换成int型数据
double *c = new double(33);
void *d = static_cast<void*>(c);//将double指针转换成void指针
int e = 10;
const int f = static_cast<const int>(e);//将int型数据转换成const int型数据
const int g = 20;
int *h = static_cast<int*>(&g);//error 编译错误,static_cast不能转换掉g的const属性
const_cast
用于删除 const、volatile 和 __unaligned 特性。将const type转换为type,将const type&转换为type&。(如将 const int 类型转换为 int 类型 )
class CTest{
public:
CTest(int i) { m_val = i; printf("construction [%d]\n", m_val); };
void SelfAdd() { m_val++; };
int m_val;
};
int main(){
const CTest test(1000);
CTest test2(1050);
printf("%d %d\n", test.m_val, test2.m_val);
const_cast<CTest &>(test) = test2;
//test.SelfAdd();//error,因为test是const
test2.SelfAdd();
printf("%d %d\n", test.m_val, test2.m_val);
return 0;
}
//1000 1050
//1050 1051
//简单示例
const int a = 5;
int *p = const_cast<int*>(&a);
(*p)++;
cout << a << " " << *p << endl;//但实际此时输出5 6,因为编译器自动进行了优化(一个类似宏替换将输出的a替换成5)
//这种就会正常
int b = 3;
const int a = b;//将一个变量的值赋给a,这样编译器不会自动优化,输出正常
int *p = const_cast<int*>(&a);
(*p)++;
cout << a << " " << *p << endl;// 4 4
dynamic_cast
- 用于多态类型的转换
- 执行行运行时类型检查
- 只适用于指针或引用
- 对不明确的指针的转换将失败(返回 nullptr),但不引发异常
- 可以在整个类层次结构中移动指针,包括向上转换、向下转换
在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的;
在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。
class B
{
public:
int Num;
virtual void foo();
};
class D:public B
{
public:
char* Name[100];
};
void func(B *pb) {
D *pd1 = static_cast<D *>(pb);
D *pd2 = dynamic_cast<D *>(pb);
}
在上面的代码段中,如果pb指向一个D类型的对象,pd1和pd2是一样的,并且对这两个指针执行D类型的任何操作都是安全的;
但是,如果pb指向的是一个B类型的对象,那么pd1将是一个指向该对象的指针,对它进行D类型的操作将是不安全的(如访问Name),而pd2将是一个空指针。
并且!B必须有虚函数,否则会编译出错(类中存在虚函数,就说明它有想要让基类指针或引用指向派生类对象的情况(向下转换),此时转换才有意义)
reinterpret_cast
允许将任何指针转换为任何其他指针类型。 也允许将任何整数类型转换为任何指针类型以及反向转换。
reinterpret_cast 是特意用于底层的强制转型,导致实现依赖(implementation-dependent)(就是说,不可移植)的结果,例如,将一个指针转型为一个整数。
int n=9; //9
double d=reinterpret_cast<double & > (n); //-9.25596e+61
这次, 结果有所不同. 在进行计算以后, d 包含无用值. 这是因为 reinterpret_cast 仅仅是复制 n 的比特位到 d, 没有进行必要的分析.
typeid、type_info
typeid返回名为type_info的标准库类型的对象的引用。
type_info 类描述编译器在程序中生成的类型信息。 此类的对象可以有效存储指向类型的名称的指针。 type_info 类还可存储适合比较两个类型是否相等或比较其排列顺序的编码值(before)。 类型的编码规则和排列顺序是未指定的,并且可能因程序而异。
class type_info
{
public:
const char* name() const;
bool operator == (const type_info & rhs) const;
bool operator != (const type_info & rhs) const;
int before(const type_info & rhs) const;
virtual ~type_info();
private:
...
};
//e.g.
const type_info& t2 = typeid(int);
type_info.name()的返回类型是一个const char* 静态字符串
比较对象type_info.name()是否相等仅支持2种比较符==和!=。如 t1.name()!=t2.name()
class Shape{
public: virtual void fun() {};
};
class Rect :public Shape{
public:
void fun() {};
void prin() { cout << "我是方形" << endl; }
};
class Circle :public Shape{
public:
void fun() {};
void prin() { cout << "我是圆形" << endl; }
};
void fun(Shape *p)
{
if (typeid(*p) == typeid(Rect)){//typeid用于返回指针或引用所指对象的实际类型
Rect *r = dynamic_cast<Rect *>(p);
r->prin();
}
if (typeid(*p) == typeid(Circle)){
Circle *c = dynamic_cast<Circle *>(p);
c->prin();
}
}
int main(){
Rect r;
cout << "第一次执行fun函数:";
fun(&r);
Circle c;
cout << "第二次执行fun函数:";
fun(&c);
return 0;
}
处理string
string s(10,'1') //等于"1111111111"
ifstream i; i.open(s.c_str()) // .c_str()返回指向const的null结尾的char类型数组指针
string s.erase(4, 7) //删除子串
string s.swap(s1) //交换
string s.find(s1, ind=0) // 如果s1在s中位置>=ind则返回大于等于ind的索引值,不在s里则返回无穷大。返回从左到右第一个
string s.rfind(s1, ind=0) // 如果s1在s中位置<=ind则返回小于等于ind的索引值,不在s里则返回无穷大。返回从右到左第一个
string s.find_first_of(s1) // 返回s1集合中的字符在s中第一次出现的索引
string s.find_first_not_of(s1) //...不出现..
find_first_of 函数最容易出错的地方是和find函数搞混。它最大的区别就是如果在一个字符串str1中查找另一个字符串str2,如果str1中含有str2中的任何字符,则就会查找成功,而find则不同;
others
//注意内联和宏定义的影响
x=15
#define SQUARE(X) X*X -> SQUARE(x++) ->x=17
inline double square(double x) { return x * x; } -> square(x++) -> x=16
//try catch throw
void gg(int i){
throw i;
}
int main(){
try {
gg(3);
} catch(int i){
cerr << i << endl;
}
return 0;
}
out: 3
//exception
out_of_bounds //数组越界等
bad_alloc //new申请空间失败
try {
//分配内存
for(int i = 1; i < 123456789876; i++)
int* a = new int[99999993];
} catch (std::bad_alloc e) {
cerr << e.what() << endl;
}
//无名命名空间....只有同一文件内的函数才能调用。。似乎避免与其他文件的namespace冲突
namespace{
void gg(){int a = 5;}
}
//无名联合...成员可当作普通变量使用...似乎也没用
//https://blog.csdn.net/lincyang/article/details/6176642
union{
int i; int b;
}
ios::sync_with_stdio() //同步io
///禁用传值方式 传递或返回对象
class c{
private:
c(c&);//将拷贝构造函数设为私有,防止对象被按值传递
}
//抑制内置类型隐式转换(针对转型构造函数)//见 https://www.cnblogs.com/yongpan/p/7463636.html
explicit gg(string a) {
cout << a << endl;
}
//初始化const数据成员
class C{
public:
C() : c(0) { x = -1; } // 把c赋值为0
//这种也可行 C() : c(0), x(-1) {}
private:
int x;
const int c;
}
//new对象
C c; //不加括号调用默认构造函数或唯一的构造函数
C c();//加括号调用没有参数的构造函数
//C++在new时的初始化的规律为:对于有构造函数的类,不论有没有括号,都用构造函数进行初始化;如果没有构造函数,则不加括号的new只分配内存空间,不进行内存的初始化,而加了括号的new会在分配内存的同时初始化为0。
static和const区别
//const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间
继承
//using 想让这些继承而来的数据成员作为public或者protected成员,可以用using来重新声明。
//改变基类成员在派生类的访问权限(注意当基类的类成员为private,那么子类也无法访问/改变权限)
class A {
public:
int a;
};
class B : public A {
private:
using A::a;
};
//名字隐藏(遮蔽、重定义): 如果子类隐藏了父类的方法,则正确调用方法如下
class A {
public:
int a() { return 1; };
};
class B : public A {
public:
int a() { return 2; };
};
B b;
b.a();//2
b.A::a();//1
多态
dynamic_cast
//运行期类型识别,和static_cast语法相同。但dynamic_cast只能用于多态性的类型,目的类型必须是指针或引用
//一般含有继承关系的向上转型会成功
//下例:如果转型成功则返回指向A的指针,否则返回Null。可以避免运行期的意外错误。
class A {
public:
virtual void gg() { ; }
};
class B : public A{
public:
void m() { ; }
};
int main() {
B* b = dynamic_cast<B*>(new A);
if (b)
b->m;
else
cerr ....;
}
typeid()
可用来确定某个表达式/变量的类型
float x;
typeid(x) == typeid(float) // true
typeid(x) == typeid(double) //false
typeid(long double) == typeid(9.211231E-9L) //true
class A {
};
class B : public A{
public:
virtual void m() { ; }
};
class C : public A {
public:
void g() {};
};
A b = new B;
A c = new C;
typeid(*b) == typeid(B) //true
typeid(*c) == typeid(C) //false
//因为B具有多态性,系统再确定*b的typeid时会进行 运行期 类型检查。而C没有,所以是 编译期 类型检查
关于重载、覆盖、隐藏、多态 https://www.cnblogs.com/DannyShi/p/4593735.html
STL
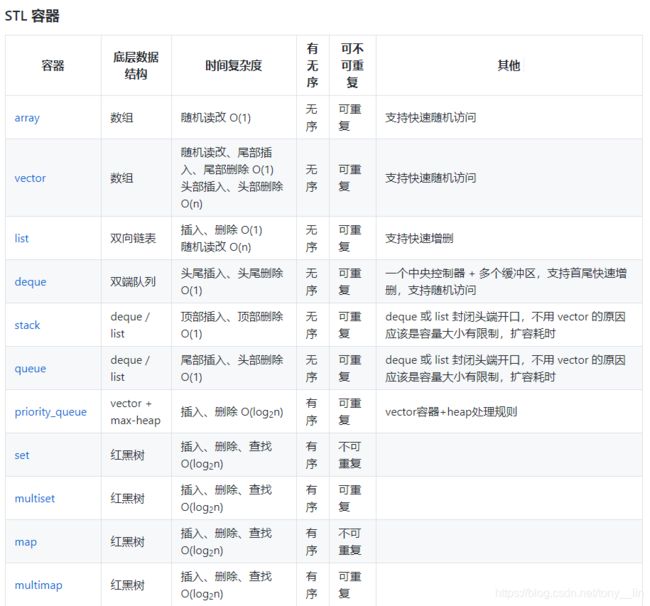
https://blog.csdn.net/u014465639/article/details/70241850
vector<int> v;
generate(v.begin(), v.end(), rand); //填充数,第三个参数为一个函数。
replace_if(v.begin(), b.end(), odd, 1) // 替代其中奇数项,改为1
char hh[] = "asdfghjkl";
int len = strlen(hh);
random_shuffle(hh, hh+len); //将元素随机打乱
nth_element(hh, hh+len/2, hh+len); //将0到len-1的中值元素放到len/2处(第二个参数可变)
copy(hh, hh+len, ostream_iterator< char > a(cout, " ") );//输出:a s d f g h j k l
// copy最后一个参数为输出型迭代器。迭代器第一个参数为输出流,第二个参数为各项之间分隔符。迭代器名为a
迭代输出2
void dump(int i){ cout << i << " "; }
for_each(v.begin(), v.end(), dump);
迭代输出3(函数对象)
template< class T >
struct dump {
void operator ()(T t) { cout << t << endl; }
};
for_each(v.begin(), v.end(), dump<int>());
关于指针
int n = 3;
//指针引用
int *p = &n;
func1(p);
void func1(int* &p){
p = new int;
*p = 5;
}
//二级指针
func2(&p);
void func2(int **p){
*p = new int;
**p = 5;
}
二级指针
在传递一级指针时(仅传值,如果是传引用,则既可以改变指针指向的内容,又可以修改指针的指向(指针的值)),只有对指针所指向的内存变量做操作才是有效的;
在传递二级指针时,只有对指针的指向做改变才是有效的;
应用在链表:
在初始化链表函数中,传入头指针,并在函数中为该指针分配空间,此时就应该使用二级指针,如void initLinklist(Node **head)。
而在添加删除结点的过程中,我们并没有改变函数参数指针的指向,而是通过传入的指针如Node *head,找到要删除结点的位置,并未对该指针做改变,因此退出函数后,该指针无影响。
关于++i和i++
i++的过程:先拷贝一份原始值至另外的内存地址中,然后这份被拷贝的原始值应用于后续的计算过程中,然后自身加1;
++i的过程:先自增,然后把自增后的值拷贝一份到另外的内存地址中,这份被拷贝的值应用于后续计算。
#pragma pack(n)
设定结构体、联合以及类成员变量以 n 字节方式对齐
#pragma pack(push) // 保存对齐状态
#pragma pack(2) // 设定为默认为 8 字节对齐,现在改为2字节对齐
struct test {
int b;//4 0-4
char m2;//1 5
char m1;//1 6
int c;//4 7-10
};
sizeof(test) == 10
#pragma pack(pop) // 恢复对齐状态,
struct test1{
int b;
char m2;
char m1;
int c;
};
sizeof(test1) == 12
union 联合
联合(union)是一种节省空间的特殊的类,一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。联合有如下特点:
- 从低地址开始存,所以可以测试主机字节序
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
#include:: 范围解析运算符
- 全局作用域符(::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间
- 类作用域符(class::name):用于表示指定类型的作用域范围是具体某个类的
- 命名空间作用域符(namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
explicit
explicit 修饰的构造函数可用来防止隐式转换
class Test1
{
public:
Test1(int n) // 普通构造函数
{
num=n;
}
private:
int num;
};
class Test2
{
public:
explicit Test2(int n) // explicit(显式)构造函数
{
num=n;
}
private:
int num;
};
int main()
{
Test1 t1=12; // 隐式调用其构造函数,成功
Test2 t2=12; // 编译错误,不能隐式调用其构造函数
Test2 t3(12); // 显式调用成功
return 0;
}
enum 枚举
enum用来定义一系列宏定义常量,相当于一系列的#define xx xx,或定义新的数据类型
enum class
强类型枚举使用enum class语法来声明,如
enum class Enum:unsigned int{
VAL1 = 33,
VAL2 = 99,
VAL3 //此时VAL3的值是100
};
强类型枚举是安全的,枚举值不会被隐式转换为整数,无法和整数数值比较
比如
Enum::VAL1==10 //会触发编译错误
//而如下操作正确
e = (Enum)33;
printf("%d", Enum::VAL1==e);//1
限定变量的范围
比如我们的应用程序中要处理有关月份的东西,显然月份只能取1-12中的某个数字
enum Month {Jan=1,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,dec};
enum Month a = Oct;
decltype
编译时类型推导
decltype的类型推导并不是像auto一样是从变量声明的初始化表达式获得变量的类型,而是总是以一个普通表达式作为参数,返回该表达式的类型,而且decltype并不会对表达式进行求值。
decltype实际上有点像auto的反函数,auto可以让你声明一个变量,而decltype则可以从一个变量或表达式中得到类型。如果需要去初始化某种类型的变量,auto是最简单的选择,但是如果所需的类型不是一个变量,例如返回值这时我们可也试一下decltype。
int i = 4;
decltype(i) a; //推导结果为int。a的类型为int
vector<int> vec;
typedef decltype(vec.begin()) vectype;
for (vectype i = vec.begin; i != vec.end(); i++){//和auto一样
//...
}
decltype和auto都可以用来推断类型,但是二者有几处明显的差异:
- auto忽略顶层const,decltype保留顶层const;
- 对引用操作,auto推断出原有类型,decltype推断出引用;
- 对解引用操作,auto推断出原有类型,decltype推断出引用;
- auto推断时会实际执行,decltype不会执行,只做分析。总之在使用中过程中和const、引用和指针结合时需要特别小心。
拷贝构造函数
对于浅拷贝:
如果在类中没有显式地声明一个拷贝构造函数,系统会创建默认的拷贝构造函数。若类的数据成员中有指针成员,则会使得新的对象的指针所指向的地址与被拷贝对象的指针所指向的地址相同,delete该指针时则会导致两次重复delete而出错。
反之如果一个类拥有资源,当这个类的对象发生复制过程的时候,资源重新分配,就是深拷贝。
类的对象需要拷贝时,拷贝构造函数将会被调用。以下情况都会调用拷贝构造函数:
(1)一个对象以值传递的方式传入函数体
(2)一个对象以值传递的方式从函数返回
(3)一个对象需要通过另外一个对象进行初始化。
class Person {
public:
Person(Person & p);
private:
char* m_pName;
};
// 系统会自动创建的默认复制构造函数,只做位模式拷贝
Person(Person & p){
//使两个字符串指针指向同一地址位置
m_pName = p.m_pName;
}
// 实现深拷贝,即不让指针指向同一地址,而是重新申请一块内存给新的对象的指针数据成员
Person(Person & chs){
// 用运算符new为新对象的指针数据成员分配空间
m_pName=new char[strlen(p.m_pName)+ 1];
if(m_pName){
// 复制内容
strcpy(m_pName ,chs.m_pName);
}
// 则新创建的对象的m_pName与原对象chs的m_pName不再指向同一地址了
}
成员初始化列表
以下场合必须要用初始化列表:
- const常量成员,因为常量只能初始化不能赋值,所以必须放在初始化列表里面
- 引用类型,引用必须在定义的时候初始化,并且不能重新赋值,所以也要写在初始化列表里面
- 没有默认构造函数的类类型,因为使用初始化列表可以不必调用默认构造函数来初始化,而是直接调用拷贝构造函数初始化。
为什么成员初始化列表效率更高?
因为对于非内置类型,少了一次调用默认构造函数的过程。非内置类型在构造函数中初始化首先调用默认的构造函数,然后调用指定的构造函数。
如果使用类初始化列表,直接调用对应的构造函数(拷贝构造函数)即完成初始化
class A
{
private:
int i;
public:
A():i(3){};
};
class Test
{
private:
int &a; //声明引用
public:
Test(int a):a(a){} //初始化
}
抽象类、接口类、聚合类
抽象类:含有纯虚函数的类
接口类:仅含有纯虚函数的抽象类
聚合类:用户可以直接访问其成员,并且具有特殊的初始化语法形式。
如struct C { int a; double b; };满足如下特点:
- 所有成员都是 public
- 没有定义任何构造函数
- 没有类内初始化
- 没有基类,也没有 virtual 函数
delete this; 合法吗?
合法,但:
- 必须保证 this 对象是通过 new(不是 new[]、不是 placement new、不是栈上、不是全局、不是其他对象成员)分配的
- 必须保证调用 delete this 的成员函数是最后一个调用 this 的成员函数
- 必须保证成员函数的 delete this 后面没有调用 this 了
- 必须保证 delete this 后没有人使用了
类占用内存大小
http://blog.jobbole.com/108148/
C++程序的内存分区
1)、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其
操作方式类似于数据结构中的栈。 用于函数调用时保存现场。
2)、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回
收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3)、全局区/静态区(Global Static Area): 全局变量和静态变量存放区,程序一经编译好,该区域便存在。在C++中,由于全局变量和静态变量编译器会给这些变量自动初始化赋值,所以没有区分了初始化变量和未初始化变量了(c中区分了),程序结束后由系统释放。
4)常量区: 这是一块比较特殊的存储区,专门存储不能修改的常量(一般是const修饰的变量,或是一些常量字符串),程序结束后由系统释放。
5)、程序代码区—存放函数体的二进制代码。
自由存储区(Free Storage):由程序员用malloc/calloc/realloc分配,free释放。如果程序员忘记free了,则会造成内存泄露,程序结束时该片内存会由OS回收。
堆是操作系统维护的一块内存,而自由存储是C++中通过new与delete动态分配和释放对象的抽象概念。堆与自由存储区并不等价。堆是操作系统维护的一块内存,是一个物理概念,而自由存储是是一个逻辑概念。
栈区与堆区的区别:
1)堆和栈中的存储内容:栈存局部变量、函数参数等。堆存储使用new、malloc申请的变量等;
2)申请方式:栈内存由系统分配,堆内存由自己申请;
3)申请后系统的响应:
栈——只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆——首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序;
4)申请大小的限制:Windows下栈的大小一般是2M,堆的容量较大;
5)申请效率的比较:栈由系统自动分配,速度较快。堆使用new、malloc等分配,较慢;
总结:栈区优势在处理效率,堆区优势在于灵活;
内存分配方式有三种:
1.从静态存储区域分配。内存在程序编译时候就已经分配好,这块内存在程序整个运行期间都存在。例如全局变量,static变量。
2.在栈上创建。在执行函数时,函数内局部变量存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器指令集中,效率很高,但是分配内存容量有限。
3.从堆上分配,亦称动态内存分配。程序在运行时候用malloc或new申请任意多少内存,程序员自己负责在何时用free或delete释放内存。动态内存生存期由我们决定,使用非常灵活,但问题也最多。
进程线程内存空间和切换
进程的上下文由PCB(进程控制块)表示,它包括进程状态,CPU寄存器的值,中断位置,堆栈上的内容等,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
PCB保存在内存中,一般存储在内核栈的开始位置,便于阻止用户访问,保护PCB不被修改。
在多线程环境下,每个线程拥有一个栈和一个程序计数器和局部变量。栈和程序计数器用来保存线程的执行历史和线程的执行状态,是线程私有的资源(还有寄存器)。其他的资源(比如堆、地址空间、全局变量)是由同一个进程内的多个线程共享。
切换
进程上下文切换保存的内容有:
- 页表 – 对应虚拟内存资源
- 文件描述符表/打开文件表 – 对应打开的文件资源
- 寄存器 – 对应运行时数据
- 信号控制信息/进程运行信息
线程的上下文切换保存
- 线程的id
- 寄存器中的值
- 栈数据
执行析构函数时抛出异常是什么情况?
其实析构函数不能抛出异常。
- [正常情况下调用析构函数抛出异常会导致资源泄露]
如果析构函数抛出异常,则异常点之后的程序不会执行,如果析构函数在异常点之后执行了某些必要的动作比如释放某些资源,则这些动作不会执行,会造成诸如资源泄漏的问题。 - [在发生异常的情况下调用析构函数还抛出异常,会导致程序崩溃]
通常异常发生时,c++的机制会调用已经构造对象的析构函数来释放资源,此时若析构函数本身也抛出异常,则前一个异常尚未处理,又有新的异常,会造成程序崩溃的问题。
解决方案:
- 如果某个操作可能会抛出异常,class应提供一个普通函数(而非析构函数),来执行该操作。目的是给客户一个处理错误的机会。
- 如果析构函数中异常非抛不可,那就用try catch来将异常吞下,必须要把这种可能发生的异常完全封装在析构函数内部,不能让它抛出函数之外。
C++中typename和class的区别
-
模板中无区别
template与template 一般情况下这两个通用 -
嵌套依赖类型有区别
template<class T> void MyMethod(T myarr) { typedef typename T::LengthType LengthType; LengthType length = myarr.GetLength; }这里的 typename 告诉编译器,T::LengthType是一个类,程序要声明一个 T::LengthType类的对象,而不是声明 T 的静态成员,而 typename 如果换成 class 则语法错误。
手写String类的实现
class CMyString {
private:
char* buf;
public:
CMyString() {
buf = nullptr;
}
CMyString(const char* str) {
buf = new char[strlen(str) + 1];
strcpy(buf, str);
}
//拷贝构造函数,深拷
CMyString(const CMyString& cstr) {
buf = new char[strlen(cstr.buf) + 1];
strcpy(buf, cstr.buf);
}
//赋值构造函数,局部变量防止内存泄漏
CMyString& operator=(const CMyString& cstr) {
if (&cstr != this) {
CMyString tmp(cstr);
char* p = tmp.buf;
tmp.buf = buf;
buf = p;
}
return *this;
}
~CMyString() {
delete[] buf;
buf = nullptr;
}
//以下加分项
//移动构造函数
CMyString(CMyString&& cstr) {
buf = cstr.buf;
cstr.buf = nullptr;
}
//移动赋值函数
CMyString& operator=(CMyString&& cstr) {
if (this != &cstr) {
buf = cstr.buf;
cstr.buf = nullptr;
}
return *this;
}
};
手撕CAS
struct ListNode {
ListNode* next;
int value;
ListNode(int val) : value(val), next(NULL) { }
};
//实现了__sync_bool_compare_and_swap同样的效果
template <typename T>
bool compare_and_swap(T* reg, T oldval, T newval) {
if (*reg == oldval) {
*reg = newval;
return true;
}
return false;
}
class CASQueue {
private:
ListNode* head;
ListNode* tail;
public:
CASQueue() {
head = new ListNode(0);
tail = head;
}
void push(int value) {
ListNode* node = new ListNode(value);
ListNode* p = tail;
do {
while (p->next != NULL) {
p = p->next;
}
} while (!compare_and_swap(&p->next, (ListNode*)NULL, node));
compare_and_swap(&tail, p, node);
}
int pop() {
ListNode* node = head;
ListNode* p;
do {
p = head;
} while (!compare_and_swap(&head, p, p->next));
int val = p->value;
delete p;
p = NULL;
return val;
}
};
//c++11 atomic
void c11CAS()
{
std::atomic<int> head = 1;
int a = 10;
int b = 2;
head.compare_exchange_weak(a, b);
cout << "head=" << head << ",a=" << a << ", b=" << b << endl;//1,1,2
}