论文总结《Adversarial Sampling and Training for Semi-Supervised Information Retrieval(AdvIR)》
原文链接
AdvIR
这篇文章是信息检索系统的鲁棒性,其中利用了从对抗训练的模型中挑选负样本,其实也是一篇去噪的文章。
Motivation
- non-labled的样本远远多于labled的样本(这里labled可以指推荐系统中用户点击了某一商品),即信息检索系统中数据的稀疏性,仅仅用均匀负采样(例如一个正例,从数据集中均匀采样100个负例)不能很好的解释现实世界,因为负样本不一定是用户不喜欢/不需要的,可能是用户并没有看到(即实际意义可能是正例)。
- 因为ad-hoc retrieval models的一定的线性性质(如Relu中非饱和部分的线性行),导致了模型对于对抗样本的脆弱性。
contributions
- 利用对抗采样负样本,来对抗训练ad-hoc retrieval models
- 提出了虚拟对抗训练,即利用虚拟的对抗样本训练模型(即利用KL散度非监督的生成对抗样本)
鲁棒 Ad-hoc Retrieval Models 的对抗训练
对抗训练
对抗训练的阐述还可以看APR[2]的论文
对抗训练的目标函数可以定义为如下形式:
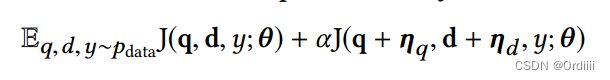
其中 p,d均为特征向量, η q , η d \eta_q,\eta_d ηq,ηd表示扰动
其中扰动由以下公式给出:

该公式意义是在 ϵ \epsilon ϵ的范围内(保证扰动不会改变样本的语义),尽可能的使得损失函数最大。
如果 η q , η d \eta_q,\eta_d ηq,ηd足够小,上述公式可以近似认为:
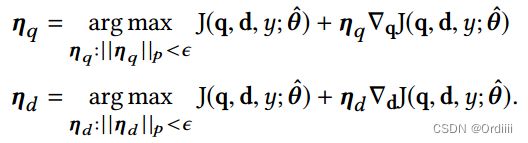
因此对于 η q , η d \eta_q,\eta_d ηq,ηd的解我们可以参考FGSM[1]或者APR[2]中对于扰动的近似解法:

虚拟对抗样本
文章认为,利用标签来生成对抗样本不一定理想,例如如果我们从unlabled的样本中生成负对抗样本,因为其假设unlabeld的样本为负例本身的不确定性(可能不喜欢也可能没看到),导致生成的负对抗样本也不一定合理。
因此文章利用KL散度来衡量未扰动和扰动过后的分布相似性,最小化该相似性来生成对抗样本,从而无监督的生成了对抗样本:
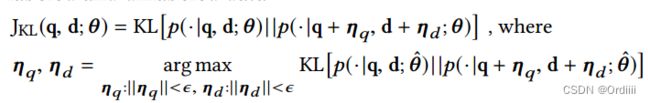 求解:
求解:

对于离散输入的扰动
一般来说,如果直接对离散的输入进行扰动会改变其语义,例如userID + ϵ \epsilon ϵ 会改变userID,那么语义就发生了改变。APR[2]的工作是在userID映射到隐空间,在latent vector上进行扰动,但因为是在模型参数上的改变,模型可以学习调整映射到隐空间的隐射函数,使得其扰动作用减小。
文章的解决方法是将离散的转换为one-hot vector,然后加上扰动,即 x ′ = x + η x' = x + \eta x′=x+η,其中 x 为one-hot向量,然后映射到隐空间:
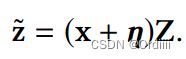
一般没有加 η \eta η的情况下,则是在Z中选取 x 对应的latent vector,加上 η \eta η后表示在映射的过程中混合了其它的latent vector,从而达到一定程度的扰动。
利用对抗采样的样本进行对抗训练
总结来说,文章利用对抗样本进行对抗训练的意义实际上是在数据集上选取正例,然而在上一次对抗训练的模型参数上选取负例,正负例再进行对抗训练更新模型参数:
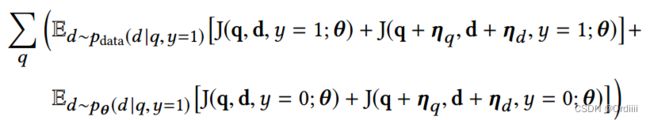 这个公式可以理解为一个去噪的过程,其不再是简单的在数据集中均匀采样负样本,而是根据上一次对抗训练的模型参数 θ \theta θ采样负样本,可以这样理解,均匀的从unlabled样本中采样负样本无法判断unlabled的样本就是用户不喜欢的item,可能是没有看到的item,那么利用模型推理得出的负样本可以一定程度上的筛选出了更具有信息,即采样用户不喜欢的item置信度高的样本作为负样本,因此这个负样本信息密度更高。对抗采样为动态采样
这个公式可以理解为一个去噪的过程,其不再是简单的在数据集中均匀采样负样本,而是根据上一次对抗训练的模型参数 θ \theta θ采样负样本,可以这样理解,均匀的从unlabled样本中采样负样本无法判断unlabled的样本就是用户不喜欢的item,可能是没有看到的item,那么利用模型推理得出的负样本可以一定程度上的筛选出了更具有信息,即采样用户不喜欢的item置信度高的样本作为负样本,因此这个负样本信息密度更高。对抗采样为动态采样
其中 p θ p_\theta pθ分布为:
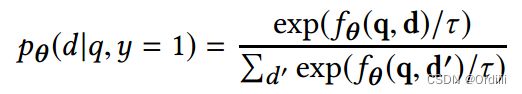
τ \tau τ为温度,可以参考C&W[3]对于蒸馏模型的介绍。
利用虚拟对抗样本进行对抗训练
参考上一节介绍的虚拟对抗样本,这里仅仅将对抗损失换成了KL散度的虚拟对抗损失:
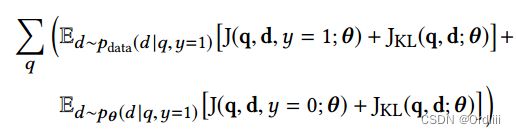
EXPERIMENTS
数据集
Movielens(100k),这里对4和5-star的数据作为labeled的数据,其它数据为unlabeled数据
结果
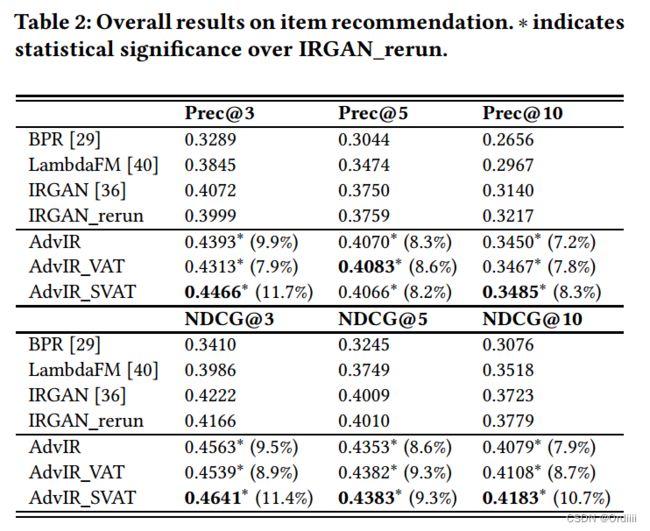
其中LambdaFM,IRGAN以及本文方法均是动态采样,而BPR则仅仅均匀采样负例。实验结果也显示动态负采样远好于均匀负采样。这里AdvIR_VAT和AdvIR_SVAT分别表示对负例进行虚拟对抗样本生成,AdvIR_SVAT则表示在对抗采样的基础上进行虚拟对抗样本生成。可以看到,对于item recommendation来说,由于unlabled样本的不确定性,利用VAT进行无监督对抗样本的生成要好于有监督的生成对抗样本。
总结与思考
这篇文章介绍了在对抗训练后的模型上进行动态负采样,连同正例和采样出来的负样本进行对抗训练。在item recommendation上与APR[2]类似,但也有以下不同点
- APR是在latent vector上进行扰动,而AdvIR则在input上进行扰动,即混合不同的embedding来达到扰动的效果
- 其次APR仅仅利用均匀负采样负例,而AdvIR则在对抗训练的模型上动态负采样负例
这篇文章可以发现动态的负采样往往要比简单的均匀负采样要好,其次利用KL散度来无监督的学习对抗样本对于unlabeled语义不清的情况下解决对抗样本生成的问题也很有启发。
参考文献
[1] Goodfellow, I. J., et al. (2014). “Explaining and harnessing adversarial examples.” arXiv preprint arXiv:1412.6572.
[2] He, X., et al. (2018). Adversarial personalized ranking for recommendation. The 41st International ACM SIGIR conference on research & development in information retrieval.
[3] Carlini, N. and D. Wagner (2017). Towards evaluating the robustness of neural networks. 2017 ieee symposium on security and privacy (sp), Ieee.