【入门篇】ClickHouse最优秀的开源列式存储数据库
文章目录
- 一、什么是ClickHouse?
-
- OLAP场景的关键特征
- 列式数据库更适合OLAP场景的原因
-
- 输入/输出
- CPU
- 1.1 ClickHouse的定义与发展历程
- 1.2 ClickHouse的版本介绍
- 二、ClickHouse的主要特性
-
- 2.1 高性能的列式存储
- 2.2 实时的分析查询
- 2.3 高度可扩展性
- 2.4 数据压缩
- 2.5 SQL支持
- 2.6 数据复制和容错
- 三、ClickHouse与其他数据库的对比
-
- 3.1 与传统的关系型数据库对比
-
- 3.1.1 数据模型
- 3.1.2 性能
- 3.1.3 可扩展性
- 3.1.4 适用场景
- 3.1.5 SQL支持
- 3.1.6 数据压缩
- 3.2 与其他的列式数据库对比
- 四、ClickHouse的应用场景
-
- 4.1 大数据实时分析
- 4.2 日志分析系统
- 4.3 时序数据存储
一、什么是ClickHouse?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。

在传统的行式数据库系统中,数据按如下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
在列式数据库系统中,数据按如下的顺序存储:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
很容易可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
列式数据库更适合OLAP场景的原因
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解):
行式
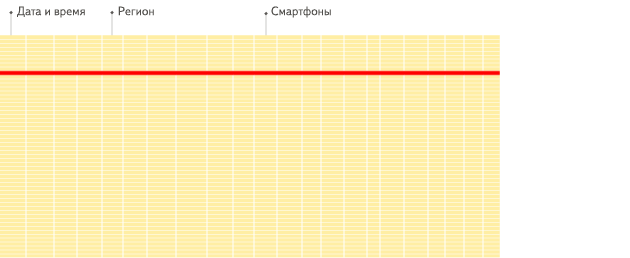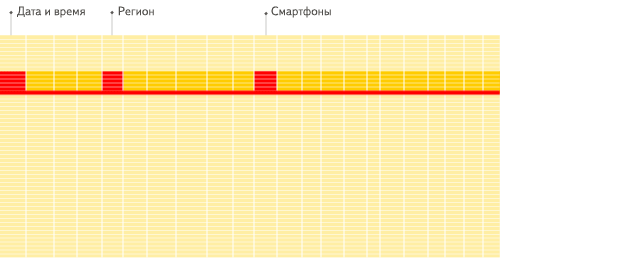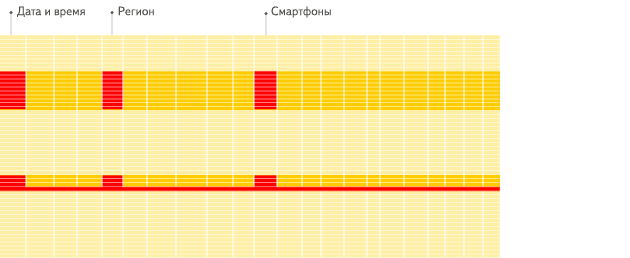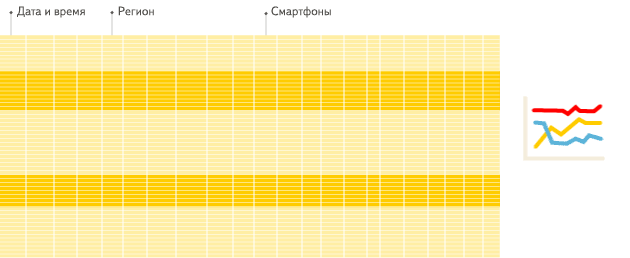
列式
看到差别了么?下面将详细介绍为什么会发生这种情况。
输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台ID»这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
- 代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
请注意,为了提高CPU效率,查询语言必须是声明型的(SQL或MDX), 或者至少一个向量(J,K)。 查询应该只包含隐式循环,允许进行优化。
1.1 ClickHouse的定义与发展历程
ClickHouse是一个开源的列式数据库管理系统(DBMS)用于在线分析处理(OLAP)。 它能够使用SQL查询实时生成分析数据报告。ClickHouse能够以极高的速度处理多达数十亿甚至数万亿行的数据。这是因为ClickHouse是一个列式数据库,它按列存储数据,使得数据查询变得非常高效。除了高效查询,ClickHouse还提供了高度的数据压缩,使得物理存储占用最小化。
ClickHouse由俄罗斯的互联网公司Yandex开发,Yandex是俄罗斯最大的搜索引擎和Web门户。ClickHouse最初是为了Yandex.Metrica项目开发的,这是全球第三大网页分析系统。ClickHouse于2016年被开源,并迅速在全球范围内获得了广泛的应用,被许多公司用于处理和分析大规模的数据。
1.2 ClickHouse的版本介绍
以下是ClickHouse的一些主要版本及其特性:
-
ClickHouse 1.1:这是首个公开发布的版本,主要特性包括列式存储、SQL查询、数据压缩等基础功能。
-
ClickHouse 1.2:增加了实时数据插入和查询的功能。
-
ClickHouse 1.3:优化了查询性能,可以更快地处理复杂查询。
-
ClickHouse 20.1:新增了数据复制和分布式查询的优化功能。
-
ClickHouse 20.3:提升了在大规模并行查询处理上的性能。
-
ClickHouse 21.1:优化了数据存储和查询性能,增加了对SQL标准的支持。
-
ClickHouse 21.3:最新稳定版本,优化了查询速度,增强了对高并发查询的处理能力。
以上版本中,每一次新版本的发布都包含了新功能的添加和对旧功能的优化,展现了ClickHouse快速发展和不断进步的历程。
二、ClickHouse的主要特性

2.1 高性能的列式存储
Clickhouse是一个列式数据库,这意味着它按列存储数据,而不是按行。例如,如果您有一个包含用户ID,用户名和密码的表,ClickHouse将分别存储用户ID,用户名和密码。当你查询特定的用户名时,只有用户名的列被加载和扫描,而不是整个表。这大大提高了查询性能,因为只有相关的数据被处理。
2.2 实时的分析查询
ClickHouse由于其优化的查询执行引擎和列式存储特性,使其能够在几秒钟内处理大量数据并生成报告。例如,如果你正在运行一个电子商务网站,并希望了解在过去的一小时内,哪些产品被查看次数最多,ClickHouse可以迅速返回结果。
2.3 高度可扩展性
如果你的业务正在快速增长,ClickHouse的高度可扩展性能够应对这种情况。例如,如果你最初在一台服务器上运行ClickHouse,但随着数据量的增加,你可以轻松地添加更多的服务器到你的ClickHouse集群,而不会影响到你现有的查询和报告。
2.4 数据压缩
ClickHouse在存储数据时会对数据进行压缩。例如,如果你的表有一列是日期,这列数据有很多重复的日期值,那么ClickHouse会使用数据压缩技术,如LZ4或ZSTD,将这些重复值压缩,从而节省存储空间,并提高查询性能。
2.5 SQL支持
尽管ClickHouse是一个列式数据库,但它支持SQL查询语言,包括SELECT,INSERT,UPDATE和DELETE语句。例如,你可以用如下SQL语句查询在过去一小时内被查看次数最多的产品:
SELECT product_id, COUNT(*) as view_count
FROM product_views
WHERE view_time > now() - INTERVAL 1 HOUR
GROUP BY product_id
ORDER BY view_count DESC
LIMIT 10;
2.6 数据复制和容错
ClickHouse支持数据复制和容错,这意味着你的数据会被复制到集群中的其他服务器,确保即使某些服务器发生故障,你的数据也不会丢失。例如,如果你有3台服务器,你的数据将被复制3次,任何一台服务器的故障都不会导致数据丢失。同时,数据复制也可以提高查询性能,因为查询可以在多个副本上并行执行。
三、ClickHouse与其他数据库的对比
3.1 与传统的关系型数据库对比
| 对比项 | 传统关系型数据库(如MySQL, PostgreSQL) | ClickHouse |
|---|---|---|
| 数据模型 | 行存储,适合OLTP工作负载 | 列存储,适合OLAP工作负载 |
| 性能 | 对大规模数据分析可能存在性能瓶颈 | 高性能,优化了查询执行引擎 |
| 可扩展性 | 通常运行在单个服务器上,需要手动进行分片和复制 | 分布式系统,自动进行分片和复制 |
| 适用场景 | 结构化的事务性数据处理,如银行交易、订单管理 | 大数据和实时分析场景,如日志数据分析、实时报告 |
| SQL支持 | 支持标准SQL,提供丰富的索引类型和事务支持 | 支持SQL,但不支持事务和一些复杂的SQL特性 |
| 数据压缩 | 通常不会进行数据压缩,占用存储空间大 | 会对数据进行压缩,节省存储空间和提高查询性能 |
3.1.1 数据模型
-
传统的关系型数据库如MySQL和PostgreSQL通常使用行存储数据。这种方式在处理事务性的OLTP(在线事务处理)工作负载时表现得很好,因为这些工作负载往往只涉及到表中的一小部分行。
-
ClickHouse则采用列存储方式,适用于OLAP(在线分析处理)工作负载,这种工作负载通常涉及到对大量行的聚合和分析。列存储的优势在于只需读取需要的列,可以大大降低I/O负载,提高查询性能。
3.1.2 性能
-
传统关系型数据库在处理大规模数据分析任务时可能会遇到性能瓶颈。例如,对数亿条记录进行分组和聚合的查询可能需要花费很长时间。
-
ClickHouse的查询执行引擎高度优化,能够利用现代多核和矢量处理硬件,查询性能非常高。它能够在几秒钟内处理和分析大量数据。
3.1.3 可扩展性
-
传统关系型数据库通常在单个服务器上运行,虽然有一些关系型数据库提供了分片和复制的功能,但这通常需要手动配置,而且在扩展性和复杂性之间需要进行权衡。
-
ClickHouse设计为分布式系统,提供了自动分片和复制的功能。它可以轻松地通过添加更多的服务器来扩展处理能力和存储容量。
3.1.4 适用场景
-
传统关系型数据库适合处理结构化的事务性数据,例如银行交易、订单管理等应用。
-
ClickHouse则更适合大数据和实时分析场景,例如日志数据分析、实时报告、时间序列数据分析等。
3.1.5 SQL支持
-
传统关系型数据库通常支持标准SQL,并提供了丰富的索引类型和事务支持。但在大规模数据分析任务中,可能需要使用复杂的SQL和索引优化来提高性能。
-
ClickHouse也支持SQL,但不支持事务和一些复杂的SQL特性。然而,它可以执行复杂的分析查询,如多维度聚合、窗口函数等,而无需索引优化。
3.1.6 数据压缩
-
传统关系型数据库通常不会对数据进行压缩,占用的存储空间较大。
-
ClickHouse会对数据进行压缩,以节省存储空间,同时也能提高查询性能。
3.2 与其他的列式数据库对比
这些列式数据库具有不同的特点和适用场景。ClickHouse在大规模数据处理和实时分析方面表现出色,而Apache Cassandra适用于分布式数据存储和高吞吐量写入。Apache Druid专注于实时OLAP查询,而Vertica则提供高性能的大规模数据处理和复杂查询。选择适合的列式数据库取决于具体的需求和应用场景。
| 特性 | ClickHouse | Apache Cassandra | Apache Druid | Vertica |
|---|---|---|---|---|
| 存储模型 | 列式存储 | 列式存储 | 列式存储 | 列式存储 |
| 查询性能 | 高性能,适用于大规模数据和复杂查询 | 高性能,适用于大规模数据和分布式查询 | 高性能,适用于实时OLAP查询 | 高性能,适用于大规模数据和复杂查询 |
| 压缩率 | 高压缩率,节省存储空间 | 较低压缩率 | 可选的压缩算法,节省存储空间 | 中等压缩率 |
| 可扩展性 | 高度可扩展,支持水平扩展和分布式架构 | 高度可扩展,支持分布式架构 | 高度可扩展,支持分布式架构 | 高度可扩展,支持分布式架构 |
| 数据复制和容错 | 支持数据复制和故障转移,提供高可用性 | 支持数据复制和故障转移,提供高可用性 | 支持数据复制和故障转移,提供高可用性 | 支持数据复制和故障转移,提供高可用性 |
| 查询语言 | 完全支持标准SQL语法,包括高级功能 | CQL (Cassandra Query Language) | SQL-like语法 | 完全支持标准SQL语法 |
| 数据类型 | 支持各种数据类型,包括时间序列和数组 | 支持常见的数据类型 | 支持常见的数据类型 | 支持常见的数据类型 |
| 实时分析 | 支持实时分析查询,低延迟响应 | 不适合实时分析,更适合高吞吐量的写入 | 适合实时OLAP查询,低延迟响应 | 支持实时分析查询,低延迟响应 |
| 数据一致性 | 强一致性,数据更新即时可见 | 最终一致性,需要时间同步 | 最终一致性,需要时间同步 | 强一致性,数据更新即时可见 |
| 开源项目 | 是 | 是 | 是 | 否 |
四、ClickHouse的应用场景
4.1 大数据实时分析
ClickHouse是一个高性能的列式数据库,它的列式存储结构使得它非常适合大数据实时分析。在此应用场景中,大量的结构化数据(例如,用户行为数据、交易数据等)被实时地写入到ClickHouse中,然后使用SQL语句快速地进行分析查询。比如,电商公司可能需要实时分析用户的购买行为,以便于动态调整它们的销售策略。
4.2 日志分析系统
日志分析是ClickHouse的一个重要应用场景。许多公司都有大量的系统日志和应用日志需要处理。 ClickHouse可以接收和存储这些日志数据,并提供SQL接口进行查询分析,如分析系统故障的原因、用户的访问行为等。例如,一个网络安全公司可能使用ClickHouse来收集和分析他们的防火墙日志,以便于快速发现并应对网络攻击。
4.3 时序数据存储
时序数据是指随时间变化而变化的数据,例如股票价格、温度读数等。ClickHouse的列式存储结构使得它非常适合存储和查询时序数据。在此应用场景中,ClickHouse不仅可以用于存储大量的时序数据,还可以提供高效的数据查询和分析。比如,一个金融公司可能使用ClickHouse来存储和分析他们的股票交易数据,以便于快速发现市场趋势和交易机会。