数据库的学习
目录
前言
一、数据库简介
1.1 简介
1.2 常见数据库管理系统
1.3 数据库三大范式(规范)
1.4 MySQL安装和卸载
1.4.1 安装
1.4.2 卸载
二、SQL语言
2.1 概述
2.2 SQL语句分类
2.3 DDL操作数据库
2.3.1 创建数据库
2.3.2 查看数据库
2.3.3 修改数据库
2.3.4 删除数据库
2.3.5 其他语句
2.4 DDL操作表
2.4.1 创建新表
2.4.2 其他表操作
2.5 DML操作
2.5.1 INSERT 插入操作
2.5.2 修改(更新)操作 UPDATE
2.5.3 删除操作 DELETE
2.5.4 sql中的运算符
2.6 DCL操作
2.6.1 创建用户:
2.6.2 用户授权
2.6.3 用户权限查询
2.6.4 撤销用户权限
2.6.5 删除用户
三、DQL数据查询
3.1 简单查询
3.2 条件查询
3.3 模糊查询
3.4 字段控制查询
3.4.1 去除重复记录
3.4.2 加运算
3.4.3 给列名添加别名
3.5 排序
3.6 聚合函数
3.7 分组查询
3.7.1 分组查询
3.7.2 HAVING子句
3.8 LIMIT
前言
数据库的学习
一、数据库简介
1.1 简介
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合。
数据库管理系统(DataBase Management System,DBMS),指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
数据库软件应该为数据库管理系统,数据库是通过数据库管理系统创建和操作的。
数据库:存储、维护和管理数据的集合。
1.2 常见数据库管理系统
- Oracle:Oracle数据库被认为是业界目前比较成功的关系型数据库(一种数据库类型,数据与数据之间有一定关联性)管理系统。Oracle数据库可以运行在Unix、Windows等主流操作系统平台,完全支持所有的工业标准,并获得最高级别的ISO标准安全性认证。
- MySQL:MySQL是一个关系型数据库管理系统,目前属于Oracle旗下产品,MySQL是最流行的关系型数据库管理系统之一,在WEB应用方面,MySQL是最好的RDBMS(Relational Database Management System)应用软件。
- DB2:DB2是IBM公司的产品,DB2数据库系统采用多进程多线索体系结构,其功能足以满足大中公司的需要,并可灵活地服务于中小型电子商务解决方案。
- Microsoft SQL Server:SQL Server是Microsoft公司推出的关系型数据库管理系统,具有使用方便、可伸缩性好与相关软件集成程度高等优点。
1.3 数据库三大范式(规范)
第一范式(1NF):无重复的列
第二范式(2NF):属性完全依赖于主键【消除部分子函数依赖】,要求数据库表中的每个实例或行必须被唯一的区分;
第三范式(3NF):属性不依赖于其它非主属性【消除传递依赖】,要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
2NF和3NF的区分关键点:
2NF:非主键列是否完全依赖于主键,还是依赖于主键的一部分;
3NF:非主键列是直接依赖于主键,还是直接依赖于非主键列。
1.4 MySQL安装和卸载
1.4.1 安装
官网:https://dev.mysql.com/downloads/mysql/
1、下载压缩包


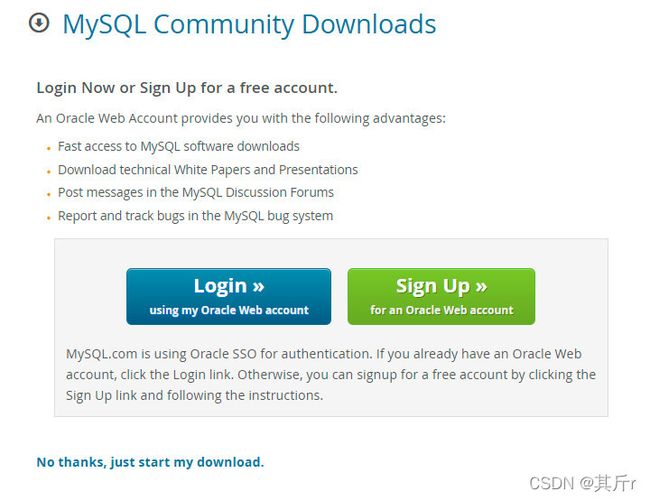
注意:没有账户的可以选择No thanks,just start 没有 download.
2、压缩包下载成功后直接解压,放在非C盘目录下,更改文件名为:mysql
3、配置环境变量:
电脑 => 右键 属性 => 高级系统设置 => 环境变量,打开mysql文件夹,找到bin目录,在环境变量中找到系统变量中的path,然后点击编辑,新建将bin目录地址写入。


4、添加配置文件:
在mysql文件夹下找到my.ini或者my-default.ini,如果没有.ini结尾的文件,直接创建该文件,
新建一个data文件夹。

.ini文件配置如下:
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装路径
basedir=D:\mysql
# 设置mysql数据库的数据存放目录
datadir=D:\mysql\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数,防止有人从该主机试图攻击数据库系统
max_connect_error=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务器端时默认使用的端口
port=3306default-character-set=utf8
5、cmd命令行安装mysql,打开bin文件夹,运行cmd
初始化数据库的指令:
mysqld --initialize --console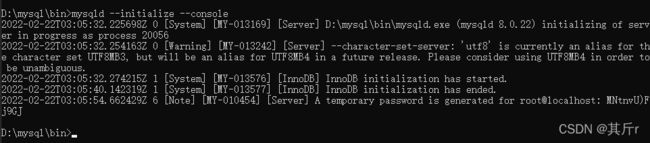
root用户初始化密码为:
![]()
安装过程中,出现如下问题:

后经百度找到原因:
未安装VC++2015版运行库,Microsoft Visual C++ 2015 Redistributable(点击下载)。
参考文档:安装MySQL时报错:找不到MSVCP140.dll_Hot Code的博客-CSDN博客
6、安装服务
在MySQL安装目录的bin目录下执行如下命令行:
mysqld --install [服务名]注:服务名默认是mysql,可以自定义

7、MySQL服务的启动和停止
启动服务:
net start mysql18停止服务:
net stop mysql188、链接数据库
mysql -u root -p
链接的时候会提示输入数据库密码
9、修改账户密码
alter user 'root'@'localhost' identified with mysql_native_password BY '新密码';注意:修改密码,尾部的分号一定要有
10、退出数据库
quit; 或 exit;1.4.2 卸载
1、使用管理员身份运行cmd,关闭mysql服务
2、删除mysql服务
sc delete xxxx
或
mysqld remove xxxx3、删除mysqlDB目录文件(安装mysql时my.ini指定的目录)
二、SQL语言
2.1 概述
2.2 SQL语句分类
-- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等。
-- DML(Data Manipulate Language):数据操作语言,用来定义数据库记录(数据)增删改。
-- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别。
-- DQL(Data Query Language):数据查询语言,用来查询记录(数据)查询。
注意:sql语句以分号";"结尾,关键字不区分大小写。
2.3 DDL操作数据库
2.3.1 创建数据库
CREATE DATABASE语句用于创建新的数据库:
编码方式:gb2312,utf-8,gbk,iso-8859-1
// create database 数据库名
CREATE DATABASE mydb1;
// create database 数据库名 character set 编码方式
CREATE DATABASE mydb2 character SET GBK;
// create database 数据库名 character set 编码方式 collate 排序规则
CREATE DATABASE mydb3 character SET GBK COLLATE gbk_chinese_ci;
2.3.2 查看数据库
查看当前数据库服务器中的所有数据库
show databases;
查看当前创建的mydb2数据库的定义信息
// show create database 数据库名
Show CREATE DATABASE mydb2;
2.3.3 修改数据库
alert databse 数据库名 character set 编码方式
查看服务器中的数据库,并把mydb2的字符集修改为utf8
ALERT DATABASE mydb2 character SET utf8;
2.3.4 删除数据库
drop database 数据库名
DROP DATABASE mydb3;
2.3.5 其他语句
查看当前使用的数据库
Select database();
切换数据库:use 数据库名
USE mydb2;
2.4 DDL操作表
2.4.1 创建新表
CREATE TABLE 语句用于创建新表。
语法:
CREATE TABLE 表名(
列名1 数据类型 [约束],
列名2 数据类型 [约束],
列名3 数据类型 [约束]
);
说明:
1、表名、列名是自定义项,多列之间用逗号隔开,最后一列不能写逗号,[约束] 表示可有可无。
2、数据类型:
int:整型;
double:浮点型,例如double(5,2)表示最多5位,其中必须有2位小数,即最大值为999.99;默认支持四舍五入;
char:固定长度字符串类型; char(10) --- 'aaa ' 占10位;
varchar:可变长度字符串类型;varchar(10) --- 'aaa' 占3位;
text:字符串类型,比如小说信息;
blob:字节类型,保存文件信息(视频、音频、图片);
date:日期类型,格式为:yyyy-MM-dd;
time:时间类型,格式为:hh:mm:ss;
timestamp:时间戳类型 yyyy-MM-dd hh:mm:ss 会自动赋值;
datetime:日期时间类型,格式为:yyyy-MM-dd hh:mm:ss;
2.4.2 其他表操作
删除当前表的结构,以及被依赖的约束(constrain)、触发器(trigger)、索引(index)
drop table 表名;
DROP TABLE table_name;
当前数据库中的所有表;
SHOW TABLES;
查看表的字段信息
desc 表名;
DESC employee;
增加列:在上面员工表的基础上增加一个image列;
alter table 表名 add 新列名 新的数据类型
ALTER TABLE employee ADD image blob;
修改列:
alter table 表名 change 旧列名 新列名 新的数据类型
ALTER TABLE employee CHANGE name username varchar(60);
ALTER TABLE employee MODIFY job varchar(60);
删除列:
alter table 表名 drop 列名
ALTER TABLE employee DROP image;
修改表名:
alter table 旧表名 rename 新表名;
ALTER TABLE user RENAME users;
查看表格的创建细节:
show create table 表名;
SHOW CREATE TABLE user;
修改表的字符集为gbk
alter table 表名 character set 编码方式
ALTER TABLE user CHARACTER SET gbk;
2.5 DML操作
对表中的数据进行增、删、改的操作。
2.5.1 INSERT 插入操作
insert into 表名(列名) values(数据值);
同时添加多行:
insert into student(stuname,stuage,stusex,birthday) values('张三1',18,'a','2000-1-1');
insert into student(stuname,stuage,stusex,birthday) values
('张三3',18,'a','2000-1-1'),
('张三4',18,'a','2000-1-1'),
('张三5',18,'a','2000-1-1'),
('张三6',18,'a','2000-1-1'),
('张三7',18,'a','2000-1-1'),
('张三8',18,'a','2000-1-1');
注意:1、多列和多个列值之间使用逗号隔开;
2、列名要和列值一一对应;
3、非数值的列值两侧需要加单引号;
4、当给所有列添加数据的时候可以将列名省略;
5、此时列值的顺序按照数据表中列的顺序执行;
2.5.2 修改(更新)操作 UPDATE
语法:update 表名 set 列名1=列值1,列名2=列值2... where 列名=值;
2.5.3 删除操作 DELETE
语法:delete from 表名 【where 列名=值】;
注意:delete删除表中的数据,表结构还在,删除后的数据可以找回;
truncate 删除是把表直接drop掉,然后在创建一个同样的新表,删除的数据不能找回,执行速度比delete快。
2.5.4 sql中的运算符
1、算术运算符: + ,- ,* ,/ (除法),%(求余)
2、赋值运算符:=
注意:赋值方向:从右往左赋值
3、逻辑运算符:and(并且)、or(或者)、not(取非)
作用:用于链接多个条件时使用
4、关系运算符:>,<,>=,<=,!=(不等于),=(等于),<>(不等于)
补充:查询所有 用*号,select * from 表名
获取当前系统时间:now(); select now();
2.6 DCL操作
2.6.1 创建用户:
create user 用户名@指定ip identified by 密码;
create user test123@localhost IDENTIFIED by 'test123';
create user [email protected] IDENTIFIED by 'test456';
create user test7@'%' IDENTIFIED by 'test7';
2.6.2 用户授权
grant select,insert,update,delete,create on chaoshi.* to 'test456'@'127.0.0.1';
grant all on *.* to 'test456'@'127.0.0.1';
2.6.3 用户权限查询
show grants for 'root'@'%';
2.6.4 撤销用户权限
REVOKE SELECT ON *.* FROM 'root'@'%' ;
2.6.5 删除用户
drop user test123@localhost;
三、DQL数据查询
SELECT 要查询的列名称FROM 表名称WHERE 限定条件 /* 行条件 */GROUP BY grouping_columns /* 对结果分组 */HAVING condition /* 分组后的行条件 */ORDER BY sorting_columns /* 对结果分组 */LIMIT offset_start, row_count /* 结果限定 */
3.1 简单查询
SELECT * FROM stu;
SELECT sid,sname,age FROM stu;
3.2 条件查询
条件查询就是在查询时给出where句子,在where句子中可以使用运算符及关键字:
=、!=、<>、<、>、<=、>=;BETWEEN...AND; IN(set);IS NULL;AND;OR;NOT;
列名 in(列值1,列值2)
3.3 模糊查询
关键字:LIKE
语法:列名 like '表达式' // 表达式必须是字符串
通配符:
_(下划线):任意一个字符
%:任意0~n个字符
3.4 字段控制查询
3.4.1 去除重复记录
两行或两行以上记录中系列的上的数据都相同,去除重复记录,需要使用DISTINCT:
SELECT DISTINCT sal FROM emp;
3.4.2 加运算
两列的类型都是数值类型,可以做加运算,其中有一个不是数值类型都会出错:
SELECT *,sal+comm FROM emp;
任何东西与NULL相加结果仍为NULL,把NULL转换成数值0的函数为IFNULL:
SELECT *,sal+IFNULL(comm,0) FROM emp;
3.4.3 给列名添加别名
给列名起别名时使用关键字AS:
SELECT *,sal+IFNULL(comm,0) AS total FROM emp;
也可以省略关键字:
SELECT *,sal+IFNULL(comm,0) total FROM emp;
3.5 排序
语法:order by 列名 asc/desc
- asc 升序,默认值
- desc 降序
3.6 聚合函数
聚合函数是用来做纵向运算的函数:
COUNT(列名):统计指定列不为NULL的记录行数;
MAX(列名):计算指定列的最大值,如果指定列为字符串类型,则按字符串排序运算;
MIN(列名):计算指定列的最小值,如果指定列为字符串类型,则按字符串排序运算;
SUM(列名):计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG(列名):计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
3.7 分组查询
关键字:GROUP BY
注意:如果查询语句中有分组操作,则select后面添加的只能是聚合函数和被分组的列名
3.7.1 分组查询
例:查询每个部门的部门编号和每个部门的工资和
SELECT deptno,SUM(sal) FROM emp GROUP BY deptno;
3.7.2 HAVING子句
例:查询工资总和大于9000的部门编号以及工资和
SELECT deptno, SUM(sal)FROM empGROUP BY deptnoHAVING SUM(sal) > 9000;
注:having与where的区别:
1.having是在分组后对数据进行过滤,where是在分组前对数据进行过滤;
2.having后面可以使用分组函数(统计函数) ,where后面不可以使用分组函数;
3.WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
多列分组:
例:统计出stu表中每个班级的男女生各多少人
select gradename,gender ,count(*) from stu group by gradename,gender;
3.8 LIMIT
LIMIT用来限定查询结构的起始行以及总行数。
语法:
LIMIT 开始下标,显示条数;
LIMIT 显示条数; // 表示默认从0开始获取数据
注意:
查询语句的书写顺序:
SELECT - FROM - WHERE - GROUP BY - HAVING- ORDER BY - LIMIT
查询语句的执行顺序:
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY - LIMIT