全流程调度-Airflow介绍和使用
文章目录
-
- Airflow基本概念
-
- 概述
- 名词
- Airflow安装
-
- 安装Python环境
-
- 安装Miniconda
- 创建Python3.8环境
- 安装Airflow
- 修改数据库为MySQL
- 修改执行器
- 部署使用
- Dag任务操作
-
- 删除Dag任务
- 查看当前所有dag任务
- 配置邮件服务器
Airflow基本概念
概述
Airflow是一个以编程方式编写,安排和监视工作流的平台。
使用Airflow将工作流编写任务的有向无环图(DAG)。Airflow计划程序在遵循指定的依赖项,同时在一组工作线程上执行任务。丰富的命令实用程序使在DAG上执行复杂的调度变的轻而易举。丰富的用户界面使查看生产中正在运行的管道,监视进度以及需要时对问题进行故障排除变的容易。
名词
(1)Dynamic:Airflow配置需要实用Python,允许动态生产管道。这允许编写可动态。这允许编写可动态实例化管道的代码。
(2)Extensible:轻松定义自己的运算符,执行程序并扩展库,使其适合于您的环境。
(3)Elegant:Airlfow是精简的,使用功能强大的Jinja模板引擎,将脚本参数化内置于Airflow的核心中。
(4)Scalable:Airflow具有模板块架构,并使用消息队列来安排任意数量的工作任务。
Airflow安装
https://airflow.apache.org
安装Python环境
Superset是由Python语言编写的Web应用,要求Python3.8的环境。
安装Miniconda
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。
此处,我们不需要如此多的工具包,故选择MiniConda。
(1)下载Miniconda(Python3版本)
下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
(2)安装Miniconda
执行以下命令进行安装,并按照提示操作,直到安装完成。
[atguigu@hadoop102 lib]$ bash Miniconda3-latest-Linux-x86_64.sh
在安装过程中,出现以下提示时,可以指定安装路径:
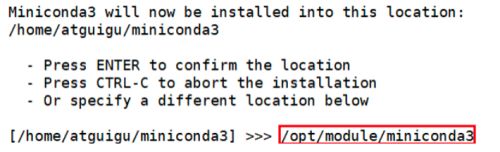
(3)加载环境变量配置文件,使之生效
[atguigu@hadoop102 lib]$ source ~/.bashrc
(4)取消激活base环境
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
[atguigu@hadoop102 lib]$ conda config --set auto_activate_base false
创建Python3.8环境
(1)配置conda国内镜像
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(base) [atguigu@hadoop102 ~]$ conda config --set show_channel_urls yes
(2)创建python3.8环境
(base) [atguigu@hadoop102 ~]$ conda create --name airflow python=3.8
说明:conda环境管理常用命令:
- 创建环境:conda create -n env_name
- 查看所有环境:conda info --envs
- 删除一个环境:conda remove -n env_name --all
(3)激活airflow环境
(base) [atguigu@hadoop102 ~]$ conda activate airflow
说明:退出当前环境。
(superset) [atguigu@hadoop102 ~]$ conda deactivate
(4)执行python -V命令查看python版本
(airflow) [atguigu@hadoop102 software]$ python -V
Python 3.8.13
安装Airflow
(1)更改pip的源
[atguigu@hadoop102 software]$ conda activate airflow
(airflow) [atguigu@hadoop102 software]$ pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
(airflow) [atguigu@hadoop102 software]$ sudo mkdir ~/.pip
(airflow) [atguigu@hadoop102 software]$ sudo vim ~/.pip/pip.conf
#添加以下内容
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
(2)安装airflow
(airflow) [atguigu@hadoop102 software]$ pip install "apache-airflow==2.4.3"
(3)初始化airflow
(airflow) [atguigu@hadoop102 software]$ airflow db init
(4)查看版本
(airflow) [atguigu@hadoop102 software]$ airflow version
2.4.3
(5)airflow安装好存放路径
(airflow) [atguigu@hadoop102 airflow]$ pwd
/home/atguigu/airflow
(6)启动airflow web服务,启动后浏览器访问http://hadoop102:8080
(airflow) [atguigu@hadoop102 airflow]$ airflow webserver -p 8080 -D

(7)启动airflow调度
(airflow) [atguigu@hadoop102 airflow]$ airflow scheduler -D
(8)创建账号
(airflow) [atguigu@hadoop102 airflow]$ airflow users create \
> --username admin \
> --firstname atguigu \
> --lastname atguigu \
> --role Admin \
> --email [email protected]
(9)启动停止脚本
[atguigu@hadoop102 bin]$ vim af.sh
#!/bin/bash
case $1 in
"start"){
echo " --------启动 airflow-------"
ssh hadoop102 "conda activate airflow;airflow webserver -p 8080 -D;airflow scheduler -D; conda deactivate"
};;
"stop"){
echo " --------关闭 airflow-------"
ps -ef|egrep 'scheduler|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -15
};;
esac
修改数据库为MySQL
(1)在MySQL中建库
mysql> CREATE DATABASE airflow_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
(2)如果报错Linux error:1425F102:SSL routines:ssl_choose_client_version:unsupported protocol,可以关闭MySQL的SSL证书
查看SSL是否开启 YES为开启
mysql> SHOW VARIABLES LIKE '%ssl%';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| have_openssl | YES |
| have_ssl | YES |
| ssl_ca | ca.pem |
| ssl_capath | |
| ssl_cert | server-cert.pem |
| ssl_cipher | |
| ssl_crl | |
| ssl_crlpath | |
| ssl_key | server-key.pem |
+---------------+-----------------+
(3)修改配置文件my.cnf,加入以下内容:
# disable_ssl
skip_ssl
(4)添加python连接的依赖:
官网介绍的方法有两种,这里我们选择下面的连接器。
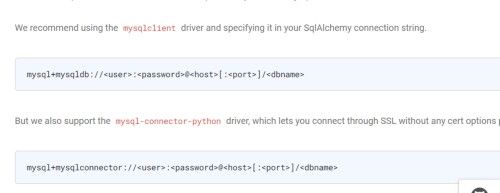
(airflow) [atguigu@hadoop102 airflow]$ pip install mysql-connector-python
(5)修改airflow的配置文件:
[database]
# The SqlAlchemy connection string to the metadata database.
# SqlAlchemy supports many different database engines.
# More information here:
# http://airflow.apache.org/docs/apache-airflow/stable/howto/set-up-database.html#database-uri
#sql_alchemy_conn = sqlite:home/atguigu/airflow/airflow.db
sql_alchemy_conn = mysql+mysqlconnector://root:123456@hadoop102:3306/airflow_db
(6)关闭airflow,初始化后重启:
(airflow) [atguigu@hadoop102 ~]$ af.sh stop
(airflow) [atguigu@hadoop102 airflow]$ airflow db init
(airflow) [atguigu@hadoop102 ~]$ af.sh start
(7)初始化报错1067 - Invalid default value for ‘update_at’:
原因:字段 ‘update_at’ 为 timestamp类型,取值范围是:1970-01-01 00:00:00 到 2037-12-31 23:59:59(UTC +8 北京时间从1970-01-01 08:00:00 开始),而这里默认给了空值,所以导致失败。
推荐修改mysql存储时间戳格式:
mysql> set GLOBAL sql_mode ='STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
重启MySQL会造成参数失效,推荐将参数写入到配置文件my.cnf中。
sql_mode = STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
(8)重新创建账号登录:
(airflow) [atguigu@hadoop102 airflow]$ airflow users create \
--username admin \
--firstname atguigu \
--lastname atguigu \
--role Admin \
--email [email protected]
修改执行器
官网不推荐在开发中使用顺序执行器,会造成任务调度阻塞。
修改airflow的配置文件:
[core]
# The executor class that airflow should use. Choices include
# ``SequentialExecutor``, ``LocalExecutor``, ``CeleryExecutor``, ``DaskExecutor``,
# ``KubernetesExecutor``, ``CeleryKubernetesExecutor`` or the
# full import path to the class when using a custom executor.
executor = LocalExecutor
可以使用官方推荐的几种执行器,也可以自定义。这里我们选择本地执行器即可。
部署使用
(1)测试环境启动
本次测试使用的是spark的官方案例,所有需要启动hadoop和spark的历史服务器。
[atguigu@hadoop102 bin]$ myhadoop.sh start
[atguigu@hadoop102 bin]$ cd /opt/module/spark-yarn/sbin/start-history-server.sh
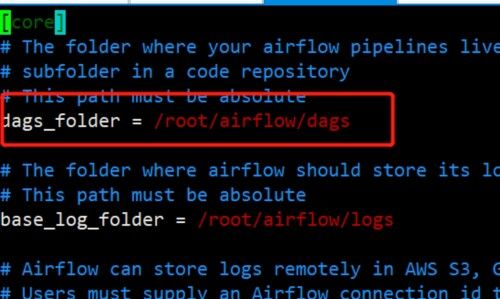
(2)查看Airflow配置文件
(python3) [root@airflow work-py]# vim ~/airflow/airflow.cfg
(3)编写.py脚本,创建work-py目录用于存放python调度脚本
(airflow) [atguigu@hadoop102 airflow]$ mkdir ~/airflow/dags
(airflow) [atguigu@hadoop102 airflow]$ cd dags/
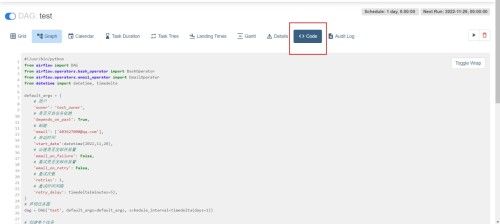
(airflow) [atguigu@hadoop102 dags]$ vim test.py
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
# 用户
'owner': 'test_owner',
# 是否开启任务依赖
'depends_on_past': True,
# 邮箱
'email': ['[email protected]'],
# 启动时间
'start_date':datetime(2022,11,28),
# 出错是否发邮件报警
'email_on_failure': False,
# 重试是否发邮件报警
'email_on_retry': False,
# 重试次数
'retries': 1,
# 重试时间间隔
'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))
# 创建单个任务
t1 = BashOperator(
# 任务id
task_id='dwd',
# 任务命令
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
# 重试次数
retries=3,
# 把任务添加进图中
dag=dag)
t2 = BashOperator(
task_id='dws',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
t3 = BashOperator(
task_id='ads',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
# 设置任务依赖
t2.set_upstream(t1)
t3.set_upstream(t2)
-
必须导包
from airflow import DAG from airflow.operators.bash_operator import BashOperator -
default_args 设置默认参数。
-
depends_on_past 是否开启任务依赖。
-
schedule_interval 调度频率。
-
retries 重试次数 。
-
start_date 开始时间。
-
BashOperator 具体执行任务,如果为true前置任务必须成功完成才会走下一个依赖任务,如果为false则忽略是否成功完成。
-
task_id 任务唯一标识(必填)。
-
bash_command 具体任务执行命令。
-
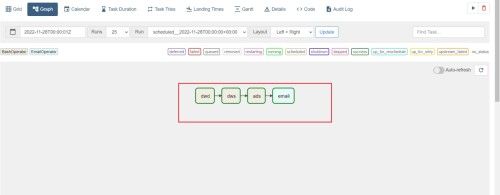
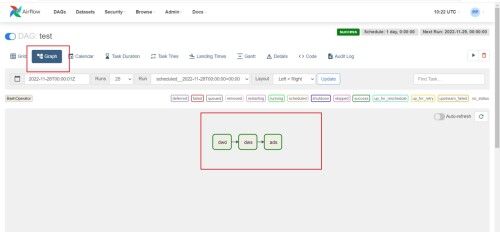
set_upstream 设置依赖 如上图所示ads任务依赖dws任务依赖dwd任务。
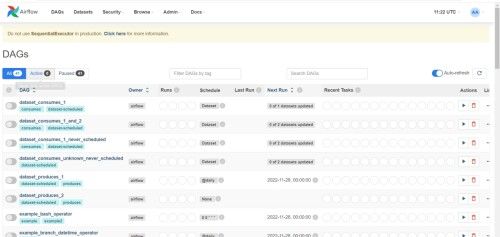
(4)等待一段时间,刷新任务列表
(airflow) [atguigu@hadoop102 airflow]$ airflow dags list
-------------------------------------------------------------------
DAGS
-------------------------------------------------------------------
example_bash_operator
example_branch_dop_operator_v3
example_branch_operator
example_complex
example_external_task_marker_child
example_external_task_marker_parent
example_http_operator
example_kubernetes_executor_config
example_nested_branch_dag
example_passing_params_via_test_command
example_pig_operator
example_python_operator
example_short_circuit_operator
example_skip_dag
example_subdag_operator
example_subdag_operator.section-1
example_subdag_operator.section-2
example_trigger_controller_dag
example_trigger_target_dag
example_xcom
latest_only
latest_only_with_trigger
test
test_utils
tutorial
(5)已出现test任务,刷新页面
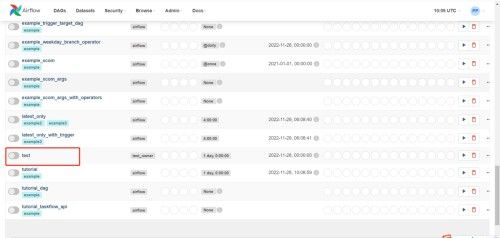
(6)点击运行
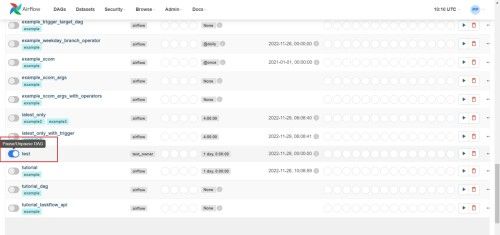
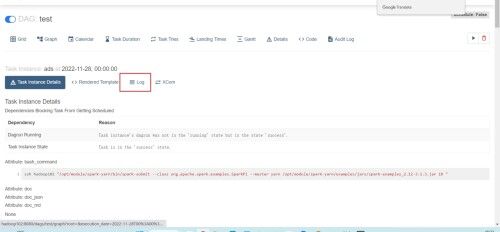
(7)点击成功任务,查看日志
![]()

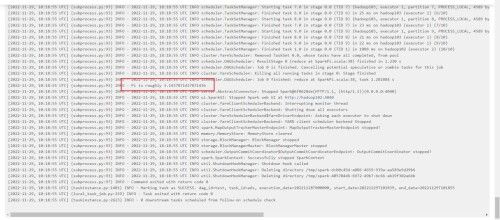
(8)查看dag图、甘特图
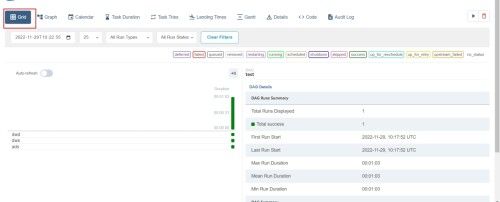
(9)查看脚本代码
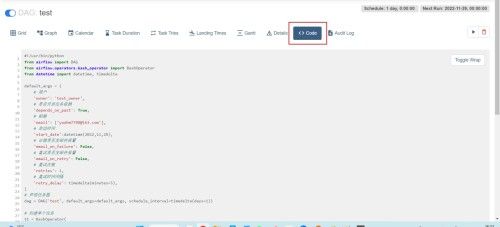
Dag任务操作
删除Dag任务
主要删除DAG任务不会删除底层文件,过一会还会自动加载回来。
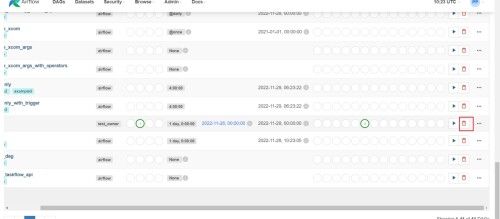
查看当前所有dag任务
# 查看所有任务
(airflow) [atguigu@hadoop102 airflow]$ airflow list_dags
# 查看单个任务
(airflow) [atguigu@hadoop102 airflow]$ airflow tasks list test --tree
配置邮件服务器
(1)保证邮箱已开SMTP服务

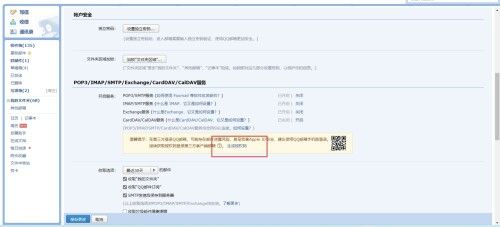
(2)修改airflow配置文件,用stmps服务对应587端口
(airflow) [atguigu@hadoop102 airflow]$ vim ~/airflow/airflow.cfg
smtp_host = smtp.qq.com
smtp_starttls = True
smtp_ssl = False
smtp_user = 403627000@qq.com
# smtp_user =
smtp_password = qluxdbuhgrhgbigi
# smtp_password =
smtp_port = 587
smtp_mail_from = 403627000@qq.com
(3)重启airflow
[atguigu@hadoop102 bin]$ af.sh stop
[atguigu@hadoop102 bin]$ af.sh start
(4)编辑test.py脚本,并且替换
[root@airflow ~]# cd /opt/module/work-py/
[root@airflow work-py]# vim test.py
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.email_operator import EmailOperator
from datetime import datetime, timedelta
default_args = {
# 用户
'owner': 'test_owner',
# 是否开启任务依赖
'depends_on_past': True,
# 邮箱
'email': ['[email protected]'],
# 启动时间
'start_date':datetime(2022,11,28),
# 出错是否发邮件报警
'email_on_failure': False,
# 重试是否发邮件报警
'email_on_retry': False,
# 重试次数
'retries': 1,
# 重试时间间隔
'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))
# 创建单个任务
t1 = BashOperator(
# 任务id
task_id='dwd',
# 任务命令
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
# 重试次数
retries=3,
# 把任务添加进图中
dag=dag)
t2 = BashOperator(
task_id='dws',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
t3 = BashOperator(
task_id='ads',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
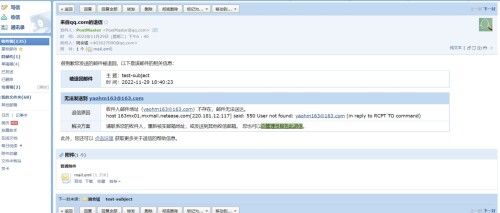
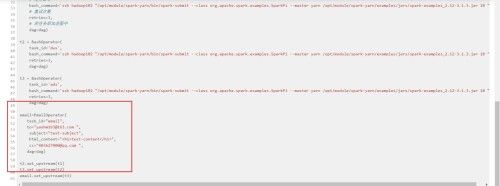
email=EmailOperator(
task_id="email",
to="[email protected] ",
subject="test-subject",
html_content="test-content
",
cc="[email protected] ",
dag=dag)
t2.set_upstream(t1)
t3.set_upstream(t2)
email.set_upstream(t3)
(5)查看页面是否生效
(6)运行测试