Airflow环境搭建
1 Airflow简介

1.1 简介
Apache Airflow是⼀个提供基于DAG(有向⽆环图)来编排⼯作流的、可视化的分布式任务调度平台(也可单机),与Oozie、Azkaban等调度平台类似。Airflow在2014年由Airbnb发起,2016年3⽉进⼊Apache基⾦会,在2019年1⽉成为顶级项⽬。Airflow采⽤Python语⾔编写,并提供可编程⽅式定义DAG⼯作流(编写Python代码)。当⼯作流通过代码来定义时,它们变得更加可维护、可版本化、可测试和协作。
Airflow的可视化界⾯提供了⼯作流节点的运⾏监控,可以查看每个节点的运⾏状态、运⾏耗时、执⾏⽇志等。也可以在界⾯上对节点的状态进⾏操作,如:标记为成功、标记为失败以及重新运⾏等。在Airflow中⼯作流上每个task都是原⼦可重试的,⼀个⼯作流某个环节的task失败可⾃动
或⼿动进⾏重试,不必从头开始跑。
Airflow通常⽤在数据处理领域,也属于⼤数据⽣态圈的⼀份⼦。当然Airflow也可以⽤于调度⾮数据处理的任务,只不过数据处理任务之间通常都会存在依赖关系。⽽且这个关系可能还⽐较复杂,⽤crontab等基础⼯具⽆法满⾜,因此更需要被调度平台编排和管理。
例如:
时间依赖:任务需要等待某⼀个时间点触发
外部系统依赖:任务依赖外部系统需要调⽤接⼝去访问
任务间依赖:任务 A 需要在任务 B 完成后启动,两个任务互相间会产⽣影响
资源环境依赖:任务消耗资源⾮常多, 或者只能在特定的机器上执⾏
Airflow拥有和 Hive、Presto、MySQL、HDFS、Postgres 和 S3 交互的能力,并且拥有很好地扩展性。除了一个命令行界面,该工具还提供了一个基于 Web 的用户界面让您可以可视化管道的依赖关系、监控进度、触发任务等。
传统 Workflow 通常使用 TextFiles (json,xml/etc ) 来定义 DAG ,然后 Scheduler 解析这些 DAG 文件形成具体的 TaskObjec t执行; Airflow 没这么干,它直接用 Python 写 DAG definition ,一下子突破了文本文件表达能力的局限,定义 DAG 变得简单。
1.2 设计原则
动态:Airflow配置为代码(Python),允许动态生成pipeline。 这允许编写动态实例化的pipelines代码。
自定义:轻松定义自己的opertators,执行程序并扩展库,使其符合适合您环境的抽象级别。
优雅:Airflow精益而明确。 使用强大的Jinja模板引擎将参数化脚本内置于Airflow的核心。
可扩展:Airflow具有模块化体系结构,并使用消息队列来协调任意数量的工作者。 Airflow已准备好扩展到无限远。
特点
Python脚本实现DAG,非常容易扩展
可实现复杂的依赖规则
外部依赖较少,搭建容易,仅依赖DB和rabbitmq
工作流依赖可视化。有一套完整的UI,可视化展现所有任务的状态及历史信息
完全支持crontab定时任务格式,可以通过crontab格式指定任务何时进行
业务代码和调度系统解耦,每个业务的流程代码以独立的Python脚本描述,里面定义了流程化的节点来执行业务逻辑,支持任务的热加载
1.3 功能简介

2 Airflow架构详解
2.1 Airflow服务架构

如上图所示,airflow主要包含以下服务
DAGs:
开发者自定义的DAG调度脚本,存放路径由airflow.cfg中的dags_folder参数决定
Airflow.cfg:
该文件非常重要,默认在$AIRFLOW_HOME的路径下,主要配置了我们需要用到的所有组件信息以及一些配置参数。
Scheduler:
负责处理触发计划的工作流,并将任务提交给executor运行
Worker(s):
负责执行调度任务的节点,当任务很大时,可以合理增加Worker节点来水平扩展集群,并将这些新的节点指向同一个元数据库,从而分发处理过程。
Executor:
executor负责运行tasks,Airflow安装时每次只有一个executor,executor被定义为Airflowconfig文件(airflow.cfg)的核心部分。
executor分两种,localexecutor和remote executor。local包括DebugExecutor,LocalExecutor和SequentialExecutor。remote executor包括CeleryExecutor和KubernetesExecutor。local用于在本地执行任务,在scheduler线程内部。remote executor在远程执行任务,比如在Kubernets cluster的一个pod中,且常通过一系列workers/worker pool实现。
Web Server:
提供一个方便的用户界面来检查、触发和调试DAG 和任务的平台
Metadata DB
Airflow的元数据库信息,用于保存executor、scheduler和web server的相关数据。默认使用SQLite,Airflow可使用任何SQLAlchemy支持的数据库,比如Mysql,Postgre等,一般情况用于常选择PostgreSQL。
2.2 WebServer
Airflow 提供了一个可视化的 Web 界面。启动 WebServer 后,就可以在 Web 界面上查看定义好的 DAG 并监控及改变运行状况。也可以在 Web 界面中对一些变量进行配置。

1.左侧 On/Off 按钮控制DAG 的运行状态,Off 为暂停状态,On 为运行状态。注意:所有 DAG 脚本初次部署完成时均为 Off 状态。
2.若 DAG 名称处于不可点击状态,可能为 DAG 被删除或未载入。若 DAG 未载入,可点击右侧刷新按钮进行刷新。注意:由于可以部署若干 WebServer,所以单次刷新可能无法刷新所有 WebServer 缓存,可以尝试多次刷新。
3.Recent Tasks 会显示最近一次 DAG Run(可以理解为 DAG 的执行记录)中 Task Instances(可以理解为作业的执行记录)的运行状态,如果 DAG Run 的状态为 running,此时显示最近完成的一次以及正在运行的 DAG Run 中所有 Task Instances 的状态。
4.Last Run 显示最近一次的 execution date。注意:execution date 并不是真实执行时间,具体细节在下文 DAG 配置中详述。将鼠标移至 execution date 右侧 info 标记上,会显示 start date,start date 为真实运行时间。start date 一般为 execution date 所对应的下次执行时间。
5.点击指定的DAG就能看到整个DAG的相关task,根据设定的依赖关系以树状方式呈现

2.3 Task操作

在 DAG 的树状图和 DAG 图中都可以点击对应的 Task Instance 以弹出 Task Instance 模态框,以进行 Task Instance 的相关操作。注意:选择的 Task Instance 为对应 DAG Run 中的 Task Instance。
Task InstanceDetails 显示该 Task Instance 的详情,可以从中得知该 Task Instance 的当前状态,以及处于当前状态的原因。例如,若该 TaskInstance 为 no status 状态,迟迟不进入queued 及 running 状态,此时就可通过 TaskInstance Details 中的 Dependency 及 Reason 得知原因。
Rendered 显示该 Task Instance 被渲染后的命令。
Run 指令可以直接执行当前作业。
Clear 指令为清除当前 Task Instance 状态,清除任意一个 Task Instance 都会使当前 DAG Run 的状态变更为 running。注意:如果被清除的 Task Instance 的状态为 running,则会尝试 kill 该 Task Instance 所执行指令,并进入 shutdown 状态,并在 kill 完成后将此次执行标记为 failed(如果 retry 次数没有用完,将标记为 up_for_retry)。Clear 有额外的5个选项,均为多选,这些选项从左到右依次为:
Past: 同时清除所有过去的 DAG Run 中此 Task Instance 所对应的 Task Instance。
Future: 同时清除所有未来的 DAG Run 中此 Task Instance 所对应的 Task Instance。注意:仅清除已生成的 DAG Run 中的 Task Instance。
Upstream: 同时清除该 DAG Run 中所有此 Task Instance 上游的 Task Instance。
Downstream: 同时清除该 DAG Run 中所有此 Task Instance 下游的 Task Instance。
Recursive: 当此 Task Instance 为 sub DAG 时,循环清除所有该 sub DAG 中的 Task Instance。注意:若当此 Task Instance 不是 sub DAG 则忽略此选项。
Mark Success 指令为讲当前 Task Instance 状态标记为 success。注意:如果该 Task Instance 的状态为 running,则会尝试 kill 该 Task Instance 所执行指令,并进入 shutdown 状态,并在 kill 完成后将此次执行标记为 failed(如果 retry 次数没有用完,将标记为 up_for_retry)。
2.4 Worker
一般来说我们用Celery Worker 来执行具体的作业。Worker 可以部署在多台机器上,并可以分别设置接收的队列。当接收的队列中有作业任务时,Worker 就会接收这个作业任务,并开始执行。Airflow 会自动在每个部署 Worker 的机器上同时部署一个 Serve Logs 服务,这样我们就可以在 Web 界面上方便的浏览分散在不同机器上的作业日志了。
2.5 Scheduler
调度器实际上就是一个 airflow.jobs.SchedulerJob 实例 job 持续运行 run 方法,job.run() 在开始时将自身的信息加入到 job 表中,并维护状态和心跳,预期能够正常结束,将结束时间也更新到表中,如果异常中断,导致结束时间为空。不管是如何进行的退出,SchedulerJob退出时会关闭所有子进程。
整个 Airflow 的调度由 Scheduler负责发起,每隔一段时间Scheduler 就会检查所有定义完成的DAG 和定义在其中的作业,如果有符合运行条件的作业,Scheduler就会发起相应的作业任务以供Worker 接收。
Scheduler 的调度过程如下:
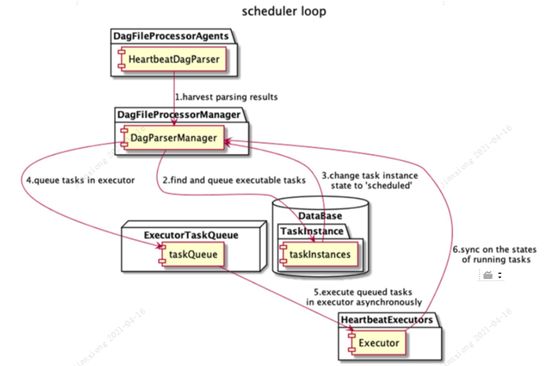
遍历 dags 路径下的所有 dag 文件, 启动一定数量的进程(进程池),并且给每个进程指派一个 dag 文件。 每个 DagFileProcessor 解析分配给它的dag文件,并根据解析结果在 DB中创建DagRuns 和 TaskInstance。
在scheduler_loop 中,检查与活动 DagRun 关联的 TaskInstance 的状态,解析 TaskInstance 之间的任何依赖,标识需要被执行的 TaskInstance,然后将它们添加至 executor 队列,将新排列的 TaskInstance 状态更新为QUEUED状态。
每个可用的executor 从队列中取一个 TaskInstance,然后开始执行它,将此 TaskInstance 的数据库记录更新为SCHEDULED。
当一个TaskInstance 完成运行,关联的 executor 就会报告到队列并更新数据库中的 TaskInstance 的状态(例如“完成”、“失败”等)。
一旦所有的dag处理完毕后,就会进行下一轮循环处理。这里还有一个细节就是上一轮的某个dag的处理时间可能很长,导致到下一轮处理的时候这个dag还没有处理完成。 Airflow 的处理逻辑是在这一轮不为这个dag创建进程,这样就不会阻塞进程去处理其余dag。
2.6 Flower
Flower 监控worker进程的存活性,启动或关闭worker进程,查看运行的task。
3 Airflow核心概念
3.1DAGs
DAG是一个有向无环图,它是task的集合,并且定义了这些task之间的执行顺序和依赖关系。比如,一个DAG包含A,B,C,D四个任务,A先执行,只有A运行成功后B才能执行,C只有在A,B都成功的基础上才能执行,D不受约束,随时都可以执行。DAG并不关心它的组成任务所做的事情,它的任务是确保他们所做的一切都在适当的时间,或以正确的顺序进行,或者正确处理任何意外的问题。
DAG 是在标准 Python 文件中定义的,这些文件放在 Airflow 的DAG_FOLDER中。Airflow 将执行每个文件中的代码以动态构建DAG对象。 您可以拥有任意数量的 DAG,每个 DAG 都可以描述任意数量的任务。通常,每个应该对应于单个逻辑工作流。
整个 DAG 的配置就是一份完整的 Python 代码,在代码中实例化 DAG,实例化适合的 Operator,并通过 set_downstream 等方法配置上下游依赖关系。下面我们简单看一下在 DAG 配置中的几个重要概念。
dag_id:给 DAG 取一个名字,方便日后维护。
dafault_args:默认参数,当属于这个 DAG 实例的作业没有配置相应参数时,将使用 DAG 实例的 default_args 中的相应参数。
schedule_interval:配置 DAG 的执行周期,语法和 crontab 的一致。
3.2 Task
task是Dag里最小的单元,是Dag的实例化,task之间存在依赖关系,每一个task执行都有对应的日志存在。task定义任务的类型、任务内容、任务所依赖的dag等。dag中每个task都要有不同的task_id。任务之间通过task.set_upstream/task.set_downstream来设置依赖,也可以用位运算:
t1 >> t2 << t3 表示t2依赖于t1和t3。
3.3 TaskInstance
记录Task的一次运行,TaskInstance有自己的状态,包括:running、success、failed、 skipped、up forretry等。
3.4 Sensors
Sensors是一个等待(轮询)某一时间、文件、数据库行、S3键、另一个DAG/Task等的Operator。
Airflow有3种不同的传感器运作模式:

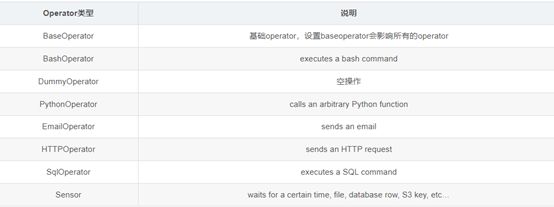
3.5 Operator
Operator即为操作器,定义任务该以哪种方式执行。airflow有多种operator,如BashOperator、DummyOperator、MySqlOperator、HiveOperator以及社区贡献的operator等,其中BaseOperator是所有operator的基础operator。
Operator 主要有三种类型:
执行一项操作或在远程机器上执行一项操作。
将数据从一个系统移动到另一个系统
类似传感器,是一种特定类型Operator,它将持续运行,直到满足某种条件。例如在 HDFS 或 S3 中等待特定文件到达,在 Hive 中出现特定的分区或一天中的特定时间,继承自 BaseSensorOperator。
3.6 BaseOperator
所有的 Operator 都是从BaseOperator 派生而来,并通过继承获得更多功能。因此BaseOperator的参数也是其他Operator的参数。
3.7 Pools
当有太多的进程同时冲击时,一些系统会不堪重负。Airflow Pools可以用来限制任意任务集的执行并行性。Pools的列表是在用户界面(Menu -> Admin -> Pools)中管理的,给Pools一个名字,并给它分配一定数量的工作槽。然后,任务可以通过在创建任务(即实例化操作者)时使用池参数与现有池之一相关联。
池参数可以和priority_weight一起使用,以定义队列中的优先级,当池中有空位时,哪些任务会被首先执行。默认的priority_weight是1,也可以提升到任何数字。当对队列进行排序以评估哪个任务应该被接下来执行时,我们使用priority_weight,并与该任务下游的所有priority_weight值相加。你可以用它来提升一个特定的重要任务,而通往该任务的整个路径都会得到相应的优先级。
3.8 Connections
连接到外部系统所需的信息存储在Airflow元存储数据库中,可以在用户界面中管理(Menu -> Admin-> Connections)。一个conn_id被定义在那里,主机名/登录/密码/模式信息被附加到它上面。Airflow管线通过指定相关的conn_id来检索集中管理的连接信息.
3.9 Xcoms
XComs让任务交换信息,允许更细微的控制形式和共享状态。这个名字是 "交叉通信 "的缩写。XComs主要由一个键、值和时间戳来定义,但也跟踪一些属性,如创建XCom的task/DAG,以及它何时应该变得可见。任何可以被提取的对象都可以作为XCom值,所以用户应该确保使用适当大小的对象。
XComs可以被 “推”(发送)或 “拉”(接收)。当一个任务推送一个XCom时,它使其他任务普遍可用。任务可以在任何时候通过调用xcom_push()方法推送XComs。此外,如果一个任务返回一个值(无论是从它的操作者的execute()方法,还是从PythonOperator的python_callable函数),那么包含该值的XCom会自动被推送。
任务调用xcom_pull()来检索XComs,可以选择应用基于key、源task_ids和源dag_id等标准的过滤器。默认情况下,xcom_pull()过滤的是XComs在被推送时由执行函数返回而自动给出的键(而不是手动推送的XComs)。
如果xcom_pull传递的是单个字符串的task_ids,那么将返回该任务的最新XCom值;如果传递的是task_ids的列表,那么将返回相应的XCom值的列表。
3.10 Variables
变量是一种通用的方式来存储和检索任意的内容或设置,作为Airflow中一个简单的键值存储。变量可以从用户界面(Admin ->Variables),、代码或CLI中列出、创建、更新和删除。此外,json设置文件也可以通过用户界面批量上传。虽然你的管道代码定义和你的大多数常量和变量应该在代码中定义,并存储在源控制中,但让一些变量或配置项目通过用户界面访问和修改是非常有用的。
3.11 Hooks
Hooks是连接外部平台和数据库的接口,如Hive、S3、MySQL、Postgres、HDFS和Pig。Hooks在可能的情况下实现一个通用接口,并作为操作者的构建块。它们也使用airflow.models.connection.Connection模型来检索主机名和认证信息。Hooks将认证代码和信息从管道中分离出来,集中在元数据数据库中。
Hooks本身在Python脚本、Airflowairflow.operators.PythonOperator以及iPython或Jupyter Notebook等交互式环境中使用也非常有用。
4 环境搭建——安装Python
4.1 安装软件环境
CentOS 7.X
Python 3.7或以上版本(推荐)
Postgres 11.9
Apache-Airflow 2.1.4
最好是虚拟机可以上网,方便在线安装
4.2 安装依赖环境
输入命令:
yum -y install zlib-devel bzip2-developenssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-develdb4-devel libpcap-devel xz-devel

4.3 下载安装包
cd /usr/local/
wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgz

检查下载的安装包
如果出现 找不到wget命令,输入yum-y install wget,依赖将会被安装
4.4 安装Python3
安装在/usr/local/python3(具体安装位置看个人喜好)
创建目录: mkdir -p /usr/local/python3
解压安装包:tar -zxvf Python-3.7.4.tgz
解压后出现python的文件夹
4.5 进入解压后的目录,编译安装
(编译安装前需要安装编译器yum install gcc)
安装gcc
输入命令 yum install gcc,确认下载安装输入“y”

(2)3.7版本之后需要一个新的包libffi-devel
yum install libffi-devel -y
(3)进入python文件夹,生成编译脚本(指定安装目录):
cd Python-3.7.4
./configure--prefix=/usr/local/python3
(4)编译:make


(5)编译成功后,编译安装:make install
安装成功

(6)检查python3.7的编译器:/usr/local/python3/bin/python3.7

4.6 建立Python3和pip3的软链
ln -sf /usr/local/python3/bin/python3.7/usr/bin/python3
ln -sf /usr/local/python3/bin/pip3/usr/bin/pip3
4.7 并将/usr/local/python3/bin加入PATH
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startupprograms
PATH=$PATH:$HOME/bin:/usr/local/python3/bin
export PATH
4.8 检查Python3及pip3是否正常可用
python3 -V
pip3 -V
5 环境搭建——安装Postgre
5.1 下载安装包
官网https://www.postgresql.org/
https://www.postgresql.org/ftp/source/v11.9/
下载后上传到Centos对应的路径,如下:

5.2 解压
mkdir /opt/postgresql
mv /home/efron/postgresql-11.9.tar.gz /opt/postgresql
cd /opt/postgresql
tar zxvf postgresql-11.9.tar.gz
5.3 编译
mkdir /usr/local/postgresql
cd /opt/postgresql/postgresql-11.9
./configure --prefix=/usr/local/postgresql
5.4 安装
make && make install
进入安装后的目录,查看目录结构
cd /usr/local/postgresql

创建目录data、log
mkdir /usr/local/postgresql/data
mkdir /usr/local/postgresql/log
5.5 加入系统环境变量
vim /etc/profile
在最后写入如下内容
PGHOME=/usr/local/postgresql
export PGHOME
PGDATA=/usr/local/postgresql/data
export PGDATA
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$PGHOME/bin
export PATH
使配置文件生效
source /etc/profile
5.6 增加用户 postgres 并赋权
adduser postgres
chown -R postgres:root /usr/local/postgresql/
5.7 初始化数据库
su postgres
/usr/local/postgresql/bin/initdb -D/usr/local/postgresql/data/
5.8 编辑配置文件
vim/usr/local/postgresql/data/postgresql.conf
listen_addresses = '*'
port = 5432
5.9 启动数据库服务
pg_ctl start -l/usr/local/postgresql/log/pg_server.log

查看版本
psql -V
5.10 登录数据库
psql -U postgres -d postgres

修改密码:
alter user postgres password"airflow"
5.11 创建airflow数据库
create database airflow;
GRANT ALL PRIVILEGES ON DATABASE airflow TO postgres;
/*Also note that since SqlAlchemy does not expose a way to targeta specific schema in the database URI, you may want to set a default schema foryour role with a SQL statement similar to */
ALTER ROLE postgres SET search_path = airflow, foobar
如果是Mysql数据库,执行以下操作
Create database airflowdb;
--创建用户airflow,设置所有IP均可以访问
Create user ‘airflow’@’%’ identified by ‘12345678’;
Create user ‘airflow’@’localhost’ identified by ‘12345678’;
--用户授权
Grant all on airflowdb.* to ‘airflow’@’%’;
--设置口令的级别
Set GLOBAL explicit_defaults_fow_timestamp = 1;
Flush privileges;
使用Dbeaver连接元数据库(这一步不是必须)
pg 元数据库连接,

6 环境搭建——安装Airflow
Airflow安装方式有多种,可以选择拉取镜像安装,如果是在云平台的K8S,还可以通过控制台实现一键安装
为了达到学习和练习的目的,我推荐如下安装方式,也是官网推荐的一种安装方式:本地安装(RunningAirflow locally),对应的官网地址:
https://airflow.apache.org/docs/apache-airflow/stable/start/local.html
6.1 创建虚拟环境
python3 -m venv tutorial-env
##激活虚拟环境
# On Windows, run:
# tutorial-env\Scripts\activate.bat
# On Unix or MacOS, run:
source/usr/local/airflow/tutorial-env/bin/activate
6.2 检查pip版本,升级到最新
pip3 -V
pip3 install --upgrade pip

6.3 开始安装
# Airflow needs a home. `~/airflow` is thedefault, but you can put it
# somewhere else if you prefer (optional)
export AIRFLOW_HOME=/usr/local/airflow/
echo "exportAIRFLOW_HOME=/usr/local/airflow" >> ~/.bashrc
# Install Airflow using the constraintsfile
AIRFLOW_VERSION=2.1.4
PYTHON_VERSION="$(python3 --version| cut -d " " -f 2 | cut -d "." -f 1-2)"
# For example: 3.6
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# For example:https://raw.githubusercontent.com/apache/airflow/constraints-2.2.5/constraints-3.6.txt
pip3 install"apache-airflow==${AIRFLOW_VERSION}" --constraint"${CONSTRAINT_URL}"

# The Standalone command will initialisethe database, make a user,
# and start all components for you.
airflow standalone
6.4 自定义元数据库类型
# 元数据库默认是Sqllit数据库,如果是其他数据库,需要修改对应的配置类型,我们选择的是Postgre,因此按照如下方式修改即可.
vim /usr/local/airflow/airflow.cfg
sql_alchemy_conn =postgresql+psycopg2://postgres:airflow@localhost:5432/airflow
6.5 安装psycopg2
# 因为安装时,python需要去连接Postgre数据库,因此还需要安装psycopg2
pip3 install psycopg2
6.6 元数据库初始化
airflow db init
报错问题解决:
# ImportError: libpq.so.5: cannot openshared object file: No such file or directory
cd /etc/ld.so.conf.d
echo "/usr/local/postgresql/lib">> pgsql.conf
ldconfig
find / -name libpq.so.5
找到
/usr/local/postgresql/lib/libpq.so.5
lib下明明有,但还是报这个错
原来是没有将gp的lib目录添加到环境变量中
vim ~/.bashrc
添加
exportLD_LIBRARY_PATH=/usr/local/postgresql/lib
source ~/.bashrc
find / -name pg_hba.conf
找到
/usr/local/postgresql/data/pg_hba.conf
添加
host postgres all 127.0.0.1/32 ident
如果出现schema没有指定的错误,需要修改一个参数文件
Vim /usr/local/postgresql/data/postgresql.conf
将 search_path参数打开
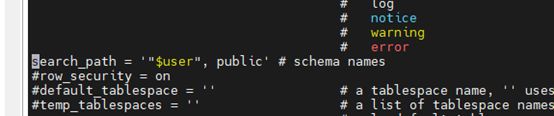
6.7 创建Web UI登陆用户
--管理员账号
airflow users create \
--username airflow \
--firstname efron \
--lastname shu \
--role Admin \
--email [email protected]
此时会提示设置密码,按提示输入账号密码即可.
6.8 启动webserver和scheduler
source /usr/local/airflow/tutorial-env/bin/activate
检查端口:
netstat -ntlp | grep 8080
airflow scheduler -D
airflow webserver --port 8080 -D
6.9 Web端口开放
点击”Tunneling”配置映射端口到本地


6.10 Web登陆Airflow
http://127.0.0.1:8080/
airflow/airflow
至此,Airflow的环境就部署完成了