基础算法学习笔记---第一部分:排序算法
前言:
最近在复习基础算法,这里记录一下复习过程,以后有新体会随时更新。
第一部分:排序算法
我们通常所说的排序算法往往指的是内部排序算法,即数据记录在内存中进行排序。
排序算法大体可分为两种:
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
另一种是非比较排序,时间复杂度可以达到O(n),主要有:计数排序,基数排序,桶排序等。
这里我们来探讨一下常用的比较排序算法,下表给出了常见比较排序算法的性能:
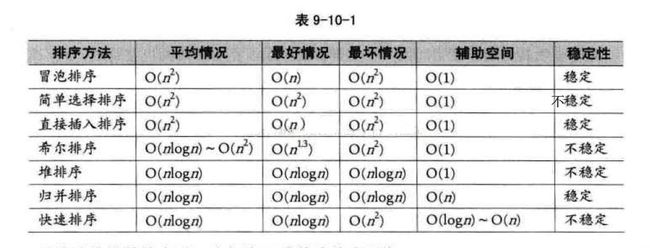
有一点我们很容易忽略的是排序算法的稳定性(腾讯校招2016笔试题曾考过)。
排序算法稳定性的简单形式化定义为:如果Ai = Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的。通俗地讲就是保证排序前后两个相等的数的相对顺序不变。需要注意的是,排序算法是否为稳定的是由具体算法决定的,不稳定的算法在某种条件下可以变为稳定的算法,而稳定的算法在某种条件下也可以变为不稳定的算法。
其次,说一下排序算法稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,前一个键排序的结果可以为后一个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位排序后元素的顺序在高位也相同时是不会改变的。
1.冒泡排序(Bubble Sort)
冒泡排序算法的运作如下:
- 比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
public class BubbleSort {
/*
* 最差时间复杂度 ---- O(n^2)
* 最优时间复杂度O(n)
* 平均时间复杂度 ---- O(n^2)
* 稳定性 ------------ 稳定
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int[] array){
for(int i=0;iarray[j+1]){ //如果条件改成A[i] >= A[i + 1],则变为不稳定的排序算法
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
flag = true; // 表示有数据交换
}
}
if(!flag){
break; // 没有数据交换,提前退出
}
}
}
} 2.选择排序(Selection Sort)
选择排序也是一种简单直观的排序算法。它的工作原理很容易理解:初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
注意选择排序与冒泡排序的区别:冒泡排序通过依次交换相邻两个顺序不合法的元素位置,从而将当前最小(大)元素放到合适的位置;而选择排序每遍历一次都记住了当前最小(大)元素的位置,最后仅需一次交换操作即可将其放到合适的位置。
选择排序的代码如下:
public class SelectionSort {
/*
* 最差时间复杂度 ---- O(n^2)
* 最优时间复杂度 ---- O(n^2)
* 平均时间复杂度 ---- O(n^2)
* 稳定性 ------------不稳定
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int array[]){
for(int i=0;iarray[j]){ // 找出未排序序列中的最小值
min = j;
}
}
if(min!=i){ // 放到已排序序列的末尾,该操作很有可能把稳定性打乱,所以选择排序是不稳定的排序算法
int temp = array[i];
array[i] = array[min];
array[min] = temp;
}
}
}
} 上述代码对序列{ 8, 5, 2, 6, 9, 3, 1, 4, 0, 7 }进行选择排序的实现过程如右图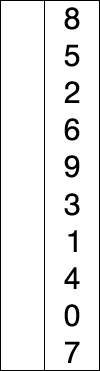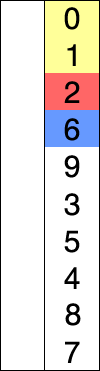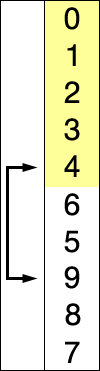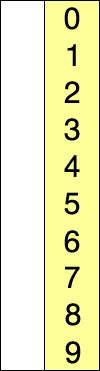
选择排序是不稳定的排序算法,不稳定发生在最小元素与A[i]交换的时刻。
比如序列:{ 5, 8, 5, 2, 9 },一次选择的最小元素是2,然后把2和第一个5进行交换,从而改变了两个元素5的相对次序。
3.插入排序(Insertion Sort)
插入排序是一种简单直观的排序算法。它的工作原理非常类似于我们抓扑克牌

具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
插入排序的代码如下:
public class InsertionSort {
/*
* 最差时间复杂度 ---- 最坏情况为输入序列是降序排列的,此时时间复杂度O(n^2)
* 最优时间复杂度 ---- 最好情况为输入序列是升序排列的,此时时间复杂度O(n)
* 平均时间复杂度 ---- O(n^2)
* 稳定性 ------------ 稳定
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int[] array){
if (array.length <= 1) {
return;
}
for (int i = 1; i < array.length; i++){
int get = array[i]; //右手抓到一张扑克牌
int j = i-1; //左手上最后一张牌(左手是排好序的)
for (; j >= 0; j--){ //将右手抓到的牌和左手上有序的牌比较,如果比左手牌小就把左手牌往后移动
if (get < array[j]){
array[j+1] = array[j];
}else {
break;
}
}
array[j+1] = get; //最终会找到要插入的位置,插入右手的牌
}
}
}上述代码对序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行插入排序的实现过程如下

插入排序的改进:二分插入排序
对于插入排序,如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的次数,我们称为二分插入排序,代码如下:
public class InsertionSortDichotomy {
/*
* 最差时间复杂度 ---- O(n^2)
* 最优时间复杂度 ---- O(nlogn)
* 平均时间复杂度 ---- O(n^2)
* 稳定性 ------------ 稳定
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int[] array){
for(int i=1;iget){
right = mid-1;
}else{
left = mid+1;
}
}
for(int j=i-1;j>=left;j--){ // 将欲插入新牌位置右边的牌整体向右移动一个单位
array[j+1]=array[j];
}
array[left]=get; // 将抓到的牌插入手牌
}
}
} 当n较大时,二分插入排序的比较次数比直接插入排序的最差情况好得多,但比直接插入排序的最好情况要差,所当以元素初始序列已经接近升序时,直接插入排序比二分插入排序比较次数少。二分插入排序元素移动次数与直接插入排序相同,依赖于元素初始序列。
插入排序的更高效改进:希尔排序(Shell Sort)
4.归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。图解如下:

public class MergeSort {
/*
* 最差时间复杂度 ---- O(nlogn)
* 最优时间复杂度 ---- O(nlogn)
* 平均时间复杂度 ---- O(nlogn)
*
*
复杂度分析:
T(n) 拆分 n/2, 归并 n/2 ,一共是n/2 + n/2 = n
/ \ 以下依此类推:
T(n/2) T(n/2) 一共是 n/2*2 = n
/ \ / \
T(n/4) ........... 一共是 n/4*4 = n
一共有logn层,故复杂度是 O(nlogn)
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
int[] temp = new int[9];
sort(array,0,array.length-1,temp);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int a[], int first, int last, int temp[]) {
if (first == last){
return;
}
int mid = (first + last) / 2;
sort(a, first, mid, temp); //左边有序
sort(a, mid + 1, last, temp); //右边有序
mergearray(a, first, mid, last, temp); //再将二个有序数列合并
}
//将有二个有序数列a[first...mid]和a[mid+1...last]合并。
public static void mergearray(int a[], int first, int mid, int last, int temp[]) {
int i = first, j = mid + 1; //i:序列1的开始 j:序列2的开始
int k = 0;
while (i <= mid && j <= last) { //如果序列1和序列2都还有数,就依次两个序列,把小的放在模板数组前面
if (a[i] <= a[j])
temp[k++] = a[i++];
else
temp[k++] = a[j++];
}
//下面两个while循环有且只有一个会被执行
while (i <= mid) //如果序列1还有数,数列2没数了,就把序列1剩余的数放在模板数组后面
temp[k++] = a[i++];
while (j <= last) //如果序列1没数了,数列2还有数,就把序列2剩余的数放在模板数组后面
temp[k++] = a[j++];
for (i = 0; i < k; i++)
a[first + i] = temp[i]; //将模板里排好序的数复制到原数组
}
}
上述代码对序列{ 6, 5, 3, 1, 8, 7, 2, 4 }进行归并排序的实例如下:
5.堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为最大堆和最小堆,是完全二叉树。
最大堆要求节点的元素都要不小于其孩子,最小堆要求节点元素都不大于其左右孩子
补充知识点:
- 完全二叉树: 若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
- 满二叉树:除了叶子结点之外的每一个结点都有两个孩子,每一层(当然包含最后一层)都被完全填充。
- 完满二叉树:除了叶子结点之外的每一个结点都有两个孩子结点。
- 完全二叉树(Complete Binary Tree):
- 满二叉树(Perfect Binary Tree):
- 完满二叉树(Full Binary Tree):
堆排序算法步骤大致如下:
- 由输入的无序数组构造一个初始最大堆(升序排序用最大堆,降序排序用最小堆)
- 把堆顶元素(最大值)和堆尾元素互换
- 把堆(无序区)的尺寸缩小1,并调用heapify(A, 0,length)从新的堆顶元素开始进行堆调整
- 重复步骤2,直到堆的尺寸为1
这里非常值得注意的一点是:交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整
图解过程可以参考:https://www.cnblogs.com/chengxiao/p/6129630.html
public class HeapSort {
/*
* 最差时间复杂度 ---- O(nlogn)
* 最优时间复杂度 ---- O(nlogn)
* 平均时间复杂度 ---- O(nlogn)
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int[] array){
//构建初始最大堆
for(int i=array.length/2-1;i>=0;i--){ //从最后一个非叶子节点开始,从下到上,从右到左构建最大堆
heapify(array,i,array.length);
}
//调整堆结构+交换堆顶元素与末尾元素
for(int j=array.length-1;j>0;j--){
swap(array,0,j); //将堆顶元素与末尾元素进行交换
heapify(array,0,j); //从新的堆顶元素开始向下进行堆调整,时间复杂度O(logn) 注意这里每次调整的堆的规模在减小
}
}
public static void heapify(int[] array,int currentRootNode,int length){
int left = currentRootNode*2+1; //当前根节点左子节点
int right = currentRootNode*2+2; //当前根节点右子节点
int max = currentRootNode;
if(left堆排序算法的演示:
堆排序是不稳定的排序算法,不稳定发生在堆顶元素与A[i]交换的时刻。
比如序列:{ 9, 5, 7, 5 },堆顶元素是9,堆排序下一步将9和第二个5进行交换,得到序列 { 5, 5, 7, 9 },再进行堆调整得到{ 7, 5, 5, 9 },重复之前的操作最后得到{ 5, 5, 7, 9 }从而改变了两个5的相对次序。
6.快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序n个元素要O(nlogn)次比较。在最坏状况下则需要O(n^2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他O(nlogn)算法更快,因为它的内部循环可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治策略(Divide and Conquer)来把一个序列分为两个子序列。步骤为:
- 从序列中挑出一个元素,作为"基准"(pivot).
- 把所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),这个称为分区(partition)操作。
- 对每个分区递归地进行步骤1~2,递归的结束条件是序列的大小是0或1,这时整体已经被排好序了。
快速排序的代码如下:
public class QuickSort {
/*
* 最差时间复杂度 ---- 每次选取的基准都是最大(或最小)的元素,导致每次只划分出了一个分区,需要进行n-1次划分才能结束递归,时间复杂度为O(n^2)
* 平均时间复杂度 ---- O(nlogn)
* 最优时间复杂度 ---- 每次选取的基准都是中位数,这样每次都均匀的划分出两个分区,只需要logn次划分就能结束递归,时间复杂度为O(nlogn)
*/
public static void main(String[] args) {
int[] array = {6, 5, 3, 1, 8, 7, 2, 9 ,4};
sort(array,0,array.length-1);
for (int i : array) {
System.out.print(i+" ");
}
}
public static void sort(int[] array,int left,int right){
if(left>right){ //递归结束条件
return;
}
int i=left,j=right;
int temp=array[left]; //temp中存的就是基准数,这里每次以最左边的数为基准
while(i!=j){
//顺序很重要,如果以左边的数为基准,就要先从右边开始找
while(array[j]>=temp&&i使用快速排序法对一列数字进行排序的过程:
快速排序是不稳定的排序算法,不稳定发生在基准元素与A[tail+1]交换的时刻。
比如序列:{ 1, 3, 4, 2, 8, 9, 8, 7, 5 },基准元素是5,一次划分操作后5要和第一个8进行交换,从而改变了两个元素8的相对次序。
Java系统提供的Arrays.sort函数。对于基础类型,底层使用快速排序。对于非基础类型,底层使用归并排序。请问是为什么?
答:这是考虑到排序算法的稳定性。对于基础类型,相同值是无差别的,排序前后相同值的相对位置并不重要,所以选择更为高效的快速排序,尽管它是不稳定的排序算法;而对于非基础类型,排序前后相等实例的相对位置不宜改变,所以选择稳定的归并排序。
参考博客:http://www.cnblogs.com/eniac12/p/5329396.html