MySQL 面试题——MySQL 基础
目录
- 1.什么是 MySQL?有什么优点?
- 2.MySQL 中的 DDL 与 DML 是分别指什么?
- 3.✨数据类型 varchar 与 char 有什么区别?
- 4.数据类型 BLOB 与 TEXT 有什么区别?
- 5.DATETIME 和 TIMESTAMP 的异同?
- 6.✨MySQL 中 IN 和 EXISTS 的区别是什么?
- 7.MySQL 中记录货币用什么字段类型比较好?
- 8.MySQL 怎么存储 emoji?
- ✨9.DROP、DELETE、TRUNCATE 之间有什么区别?
- 10.UNION 与 UNION ALL 有什么区别?
- 11.count(1)、count(*)、count(column_name) 之间有什么区别?
- 12.MySQL 中的 CUBE 与 ROLLUP 有什么区别?
- 13.✨一条 SQL 查询语句的执行顺序是什么样的?SQL 语句的执行过程是什么样的?
- 14.MySQL 的内连接、左连接、右连接有什么区别?
- 15.什么是 JDBC?
- 16.使用 JDBC 进行查询包括哪些步骤?
- 17.✨PreparedStatement 和 Statement 的区别是什么?
- 18.MySQL 怎么删除数据?
- 19.✨MySQL 中的视图是什么?有什么作用?如何创建?
- 20.✨使用 limit 进行分页查询时存在什么问题?如何优化分页查询?
1.什么是 MySQL?有什么优点?
(1)MySQL 是一种关系型数据库,主要用于持久化存储系统中的一些数据,例如用户信息。由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL (General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是 3306。
(2)MySQL 主要具有下面这些优点:
- 成熟稳定、功能完善、开源免费。
- 文档丰富,既有详细的官方文档,又有非常多优质文章可供参考学习。
- 开箱即用,操作简单,维护成本低。
- 兼容性好,支持常见的操作系统,支持多种开发语言。
- 社区活跃,生态完善。事务支持优秀, InnoDB 存储引擎默认使用 REPEATABLE-READ 并不会有任何性能损失,并且,InnoDB 实现的 REPEATABLE-READ 隔离级别其实是可以解决幻读问题发生的。
- 支持分库分表、读写分离、高可用。
2.MySQL 中的 DDL 与 DML 是分别指什么?
(1)在 MySQL 中,DDL 和 DML 都是 SQL 语言中的重要概念,它们分别代表数据定义语言 (Data Definition Language) 和数据操作语言 (Data Manipulation Language)。
- DDL:DDL 是 SQL 语言中用于定义和管理数据库结构的语言,包括 CREATE、ALTER 和 DROP 等命令。DDL 用于创建、修改和删除数据库对象,如表、索引、约束和视图等。使用 DDL,可以执行以下操作:
CREATE:创建数据库对象,如表、索引、约束和视图等。ALTER:修改数据库对象的结构,如修改表的列、约束和索引等。DROP:删除数据库对象,如表、索引、约束和视图等。
- DML:DML 是 SQL 语言中用于对数据进行操作的语言,包括 SELECT、INSERT、UPDATE 和 DELETE 等命令。DML 用于查询和修改表中的数据,但不会改变表的结构。使用 DML,可以执行以下操作:
SELECT:从表中获取数据。INSERT:向表中插入新数据。UPDATE:更新表中的数据。DELETE:删除表中的数据。
(2)总之,DML 和 DDL 都是 SQL 语言中非常重要的概念,DML 用于查询和修改表中的数据,DDL 用于定义和管理数据库结构,如创建、修改和删除表、索引、约束和视图等。
3.✨数据类型 varchar 与 char 有什么区别?
在 MySQL 中,varchar 和 char 都是用来存储文本类型数据的。其主要区别如下:
- 存储方式:char 类型的数据会被存储为固定长度的字符串,而 varchar 类型的数据则会根据数据长度来动态分配存储空间。
- 空间占用:由于 char 类型的数据存储为固定长度,所以它的存储空间通常比 varchar 类型的数据要大,特别是当存储的数据长度较短时。
- 检索速度:由于 char 类型的数据存储为固定长度,所以检索速度通常比 varchar 类型的数据要快。但是,由于 varchar 类型的数据可以动态分配存储空间,所以在存储长度不定的数据时,varchar 类型的数据通常更为高效。
- 默认长度:在 MySQL 中,如果不指定 char 或 varchar 类型的长度,则 char 类型的默认长度为 1,而 varchar 类型的默认长度为 255。
- 适用场景:char 类型的数据适用于存储长度固定的数据,如电话号码、邮政编码、身份证号码等;而 varchar 类型的数据适用于存储长度不定的数据,如文章、评论等。
4.数据类型 BLOB 与 TEXT 有什么区别?
在 MySQL 中,BLOB 和 TEXT 都是用来存储大型二进制和文本数据的类型。它们的主要区别在于:
- 存储大小:BLOB 类型可以存储二进制数据,包括图像、音频、视频等大型二进制数据。而 TEXT 类型则可以存储文本数据,包括长文本、HTML代码、XML文档等。
- 存储方式:BLOB 类型的数据是二进制数据,存储方式为二进制格式,而TEXT类型的数据是文本数据,存储方式为字符格式。
- 最大长度:BLOB 类型最大长度为 65535 字节,TEXT 类型最大长度为 65535 字符或者 108 字节,取决于使用哪种编码方式。
- 索引和排序:BLOB 类型的数据不能被索引,也不能被排序,而 TEXT 类型的数据可以被索引和排序。
- 存储位置:BLOB 类型的数据可以存储在表内或者表外,而 TEXT 类型的数据只能存储在表内。
- 适用场景:BLOB 类型适用于存储大型二进制数据,如图像、音频、视频等;而 TEXT 类型适用于存储大量文本数据,如文章、评论等。
5.DATETIME 和 TIMESTAMP 的异同?
MySQL 中的 DATETIME 和 TIMESTAMP 都是用来存储日期和时间类型的数据,它们的相同点和不同点如下:
- 相同点:
- 都可以用来存储日期和时间类型的数据。
- 都可以进行日期和时间的计算和比较。
- 都可以使用标准的日期和时间函数进行操作,如 NOW()、DATE()、TIME() 等。
- 不同点:
- 存储范围:DATETIME 类型可以存储的日期和时间范围为
1000-01-01 00:00:00 ~ 9999-12-31 23:59:59;而 TIMESTAMP 类型可以存储的日期和时间范围为1970-01-01 00:00:01 ~ 2038-01-19 03:14:07。 - 存储空间:在 MySQL 5.6.4 之前,DateTime 和 Timestamp 的存储空间是固定的,分别为
8 字节和4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是5 ~ 8 字节,Timestamp 的范围是4 ~ 7 字节。 - 精确度:DATETIME 类型的精确度为秒级别,而 TIMESTAMP 类型的精确度为毫秒级别。
- 默认值:对于 DATETIME 类型,默认值为
NULL,对于 TIMESTAMP 类型,默认值为当前时间。 - 自动更新:TIMESTAMP 类型支持自动更新,可以通过设置 DEFAULT CURRENT_TIMESTAMP 或 ON UPDATE CURRENT_TIMESTAMP 来实现。
- 时区相关:DATETIME 类型存储的时间不会随时区改变,而 TIMESTAMP 类型存储的时间会随时区改变。
- 适用场景:DATETIME 适用于存储历史数据和事件,而 TIMESTAMP 适用于存储与时间相关的数据,如创建时间、修改时间等。
- 存储范围:DATETIME 类型可以存储的日期和时间范围为
相关文章:
美团面试:MySQL 保存日期用哪种数据类型?Datetime?Timestamp?数值时间戳?
6.✨MySQL 中 IN 和 EXISTS 的区别是什么?
(1)在 MySQL 中,IN 和 EXISTS 都是用来查询数据的关键字,它们的主要区别如下:
- 功能不同:IN 用于比较一个值是否在一个固定的集合中,而 EXISTS 用于判断一个子查询是否有返回结果。
- 执行顺序不同:IN 是先将右侧的集合查询出来,再将左侧的值与集合中的每一个值进行比较,因此在数据量较大的情况下,执行效率会较低。而 EXISTS 是先执行子查询,只要子查询有返回结果,就立即返回结果,因此在数据量较大的情况下,执行效率会比 IN 高。
- 返回结果不同:IN 返回的结果是匹配到的行,而 EXISTS 返回的结果是 true 或 false。
- 数据类型不同:IN 可以用于比较数值、字符串等数据类型,而 EXISTS 只能用于比较子查询的返回结果是否为空。
(2)总之,IN 和 EXISTS 都是用于查询数据的关键字,它们的功能、执行顺序、返回结果和数据类型都存在一定的区别,使用时需要根据实际需要选择合适的查询方式。在处理大量数据时,应该优先考虑使用 EXISTS 关键字,因为它的执行效率更高。
7.MySQL 中记录货币用什么字段类型比较好?
(1)在 MySQL 中记录货币建议使用 DECIMAL 字段类型。DECIMAL 是一种精确的定点数值类型,它可以精确地表示小数点前后的数字,并且支持大范围的数字精度和范围。在存储货币等金额数据时,精度和精确度非常重要,因为不能出现计算误差,否则会造成严重的财务问题。
(2)DECIMAL 类型有两个参数,第一个参数表示总共的数字个数(整数部分 + 小数部分),第二个参数表示小数部分的数字个数。例如,DECIMAL(10, 2) 可以存储 10 位数字中的小数点后两位,因此可以存储金额数值,保留两位小数。
(3)需要注意的是,虽然 FLOAT 或 DOUBLE 也可以用来存储金额,但这两个类型是近似数值类型,是以二进制存储的,计算机在表示一个数字时,其宽度是有限的,因此无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度丢失的情况。例如,十进制下的 0.2 就无法精确转换成二进制小数。因此,在处理货币金额时,建议使用DECIMAL类型来保证精确度。
/*
0.2 转换为二进制数的过程如下:
(1) 不断乘以 2,直到不存在小数为止;
(2) 在计算过程中,得到的整数部分从上到下排列就是二进制的结果;
*/
0.2 * 2 = 0.4 -> 0
0.4 * 2 = 0.8 -> 0
0.8 * 2 = 1.6 -> 1
0.6 * 2 = 1.2 -> 1
0.2 * 2 = 0.4 -> 0(发生循环)
...
8.MySQL 怎么存储 emoji?
(1)在 MySQL 中存储 Emoji 表情可以使用 utf8mb4 字符集,因为 Emoji 表情并不是标准的 Unicode 字符,需要使用 4 个字节来表示。
(2)以下是存储 Emoji 表情的步骤:
- 创建一个 utf8mb4 字符集的数据库或者表。可以在创建数据库或表时指定字符集:
CREATE DATABASE mydatabase CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE TABLE mytable (
id INT PRIMARY KEY,
name VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
- 将连接的字符集设置为 utf8mb4。可以在连接数据库时指定字符集,或者在连接后使用 SET NAMES 命令设置字符集:
SET NAMES utf8mb4;
- 在插入 Emoji 表情时,可以直接使用 UTF-8 编码的表情字符,或者使用 Unicode 编码。例如:
INSERT INTO mytable (id, name) VALUES (1, '');
INSERT INTO mytable (id, name) VALUES (2, '\U0001F603');
# 第一个例子直接使用了 UTF-8 编码的表情字符,第二个例子使用了 Unicode 编码。
- 在查询 Emoji 表情时,需要确保连接的字符集是 utf8mb4,否则查询结果可能无法正常显示 Emoji 表情。可以使用 SET NAMES 命令设置字符集,或者在连接数据库时指定字符集。
(3)总之,要在 MySQL 中存储 Emoji 表情,需要使用 utf8mb4 字符集,并将连接的字符集设置为 utf8mb4,然后可以直接使用 UTF-8 编码的表情字符或 Unicode 编码来插入 Emoji 表情。
✨9.DROP、DELETE、TRUNCATE 之间有什么区别?
(1)在 MySQL 中,DROP、DELETE 和 TRUNCATE 都可以删除表或清空表中的数据,但它们之间的区别如下:
| delete | truncate | drop | |
|---|---|---|---|
| 类型 | 属于 DML | 属于 DDL | 属于 DDL |
| 回滚 | 可回滚 | 不可回滚 | 不可回滚 |
| 删除内容 | 表结构还在,删除表的全部或者一部分数据行 | 表结构还在,删除表中的所有数据 | 从数据库中删除表,所有数据行,索引和权限也会被删除 |
| 删除速度 | 删除速度慢,需要逐行删除 | 删除速度快 | 删除速度最快 |
(2)因此,在不再需要一张表的时候,用 drop;在想删除部分数据行时候,用 delete;在保留表而删除所有数据的时候,用 truncate。
10.UNION 与 UNION ALL 有什么区别?
在 MySQL 中,UNION 和 UNION ALL 都用于将多个 SELECT 语句的结果组合到一个结果集中。但是它们之间有一些重要的区别:
- UNION 操作符会去除重复行,但效率低于UNION ALL 操作符;
- UNION ALL 操作符不会去除重复行,所以效率更高;
11.count(1)、count(*)、count(column_name) 之间有什么区别?
(1)在 MySQL 中,聚合函数 COUNT() 函数用于返回查询结果中的行数。但是,COUNT() 函数的三种不同写法 COUNT(1)、COUNT(*)、COUNT(column_name) 之间有一些区别:
- COUNT(1) 和 COUNT(*):返回的结果相同,它们都会计算结果集中的行数,而不考虑行中是否包含 NULL 值。一般来说,COUNT(*) 是更常见的用法,因为它更简洁。
- COUNT(column_name):也会返回结果集中的行数,但它只计算指定列中非 NULL 值的数量。如果该列中包含 NULL 值,则它们不会被计算在内。
因此,当需要计算结果集中的行数时,可以使用 COUNT(1) 或 COUNT(*)。当需要计算特定列中的非 NULL 值数量时,可以使用 COUNT(column_name)。在大多数情况下,COUNT(*) 是最常用的写法,因为它比 COUNT(1) 更容易理解,而且性能相差不大。
(2)执行速度:
- 列名为主键,COUNT(column_name) 会比 COUNT(1) 快;
- 列名不为主键,COUNT(1) 会比 COUNT(column_name) 快;
- 如果表多个列并且没有主键,则 COUNT(1) 的执行效率优于 COUNT(*);
- 如果有主键,则 select COUNT(主键)的执行效率是最优的;
- 如果表只有一个字段,则 select COUNT(*) 最优;
12.MySQL 中的 CUBE 与 ROLLUP 有什么区别?
(1)在 MySQL 中,CUBE 和 ROLLUP 都是用于生成聚合数据的查询扩展,它们可以在一次查询中生成多个聚合结果,并在结果集中添加一个或多个小计行。它们的区别在于生成小计行的方式和范围不同。CUBE 子句会在所有可能的维度上生成总计,而 ROLLUP 子句则是在指定的列上按层次结构生成总计。
- 具体来说,CUBE 子句生成的聚合结果包括每个维度的子总计、每个维度组合的总计以及所有维度的总计。例如,如果一个表有三列,使用 CUBE 可以生成 7 个子总计,分别是按列 1 聚合、按列 2 聚合、按列 3 聚合、按列 1 和列 2 聚合、按列 1 和列 3 聚合、按列 2 和列 3 聚合,以及按列 1、列 2 和列 3 聚合。
SELECT column_1, column_2, column_3, SUM(value)
FROM table_name
GROUP BY CUBE(column_1, column_2, column_3);
- 而 ROLLUP 子句则是在指定的列上按层次结构生成小计行。例如,如果一个表有三列,使用 ROLLUP 可以生成 4 个小计行,分别是没有小计行、按列 1 小计、按列 1 和列 2 小计,以及按列 1、列 2 和列 3 小计。
SELECT column_1, column_2, column_3, SUM(value)
FROM table_name
GROUP BY column_1, column_2, column_3 WITH ROLLUP;
(2)因此,CUBE 子句适用于需要生成所有可能维度的聚合数据的情况,而 ROLLUP 子句则适用于按层次结构生成聚合数据的情况。同时,需要注意,使用 CUBE 或 ROLLUP 都会增加查询的计算量和数据量,可能会影响查询的性能。
13.✨一条 SQL 查询语句的执行顺序是什么样的?SQL 语句的执行过程是什么样的?
(1)下图显示了不同子句的执行顺序:

- FROM:对 FROM 子句中的左表
和右表 执行笛卡儿积,产生虚拟表 VT1; - ON:对虚拟表 VT1 应用 ON 筛选,只有那些符合
的行才被插入虚拟表 VT2 中; - JOIN:如果指定了 OUTER JOIN(如LEFT OUTER JOIN、RIGHT OUTER JOIN),那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3。如果FROM子句包含两个以上表,则对上一个连接生成的结果表VT3和下一个表重复执行步骤1)~步骤3),直到处理完所有的表为止;
- WHERE:对虚拟表 VT3 应用 WHERE 过滤条件,只有符合
的记录才被插入虚拟表VT4中; - GROUP BY:根据 GROUP BY 子句中的列,对 VT4 中的记录进行分组操作,产生 VT5;
- CUBE | ROLLUP:对表 VT5 进行 CUBE 或 ROLLUP 操作,产生表 VT6;
- HAVING:对虚拟表 VT6 应用 HAVING 过滤器,只有符合
- SELECT:第二次执行 SELECT 操作,选择指定的列,插入到虚拟表 VT8 中;
- DISTINCT:去除重复数据,产生虚拟表 VT9;
- ORDER BY:将虚拟表 VT9 中的记录按照
进行排序操作,产生虚拟表 VT10; - LIMIT:取出指定行的记录,产生虚拟表 VT11,并返回给查询用户;
上述过程可简单表述为:
FROM:从指定的表或视图中选择要查询的数据源;ON与JOIN:将多个表连接起来,根据指定的连接条件进行关联;WHERE:对数据进行筛选,只选择满足条件的记录;GROUP BY:按指定的列进行分组;HAVING:对分组后的数据进行筛选,只选择满足条件的分组;SELECT:选择要查询的列或表达式,计算所需的结果。DISTINCT:去除重复的记录。ORDER BY:按指定的列对结果集进行排序。LIMIT:限制结果集的数量。UNION (ALL):合并多个查询的结果集。OFFSET:指定结果集开始的位置。
注意:一般来说,一条 SQL 不会覆盖上面所有的执行过程!
(2)在 MySQL中,SQL 语句的执行过程通常分为以下几个步骤:
- 语法分析和词法分析:将 SQL 语句分解为多个词 (tokens),验证语法的正确性。
- 查询缓存:MySQL 首先检查查询缓存,如果存在匹配的查询结果,将直接返回结果,而不执行实际的查询操作。
- 查询优化:MySQL 通过优化器对 SQL 语句进行优化,生成最优的查询执行计划。这包括选择合适的索引、连接顺序、访问路径等。
- 执行计划:MySQL 根据优化器生成的执行计划,确定具体的查询算法和操作顺序。
- 执行操作:MySQL 执行 SQL 语句,包括读取数据、筛选、排序等。根据执行计划,通过访问表、索引和其他数据库对象来获得结果集。
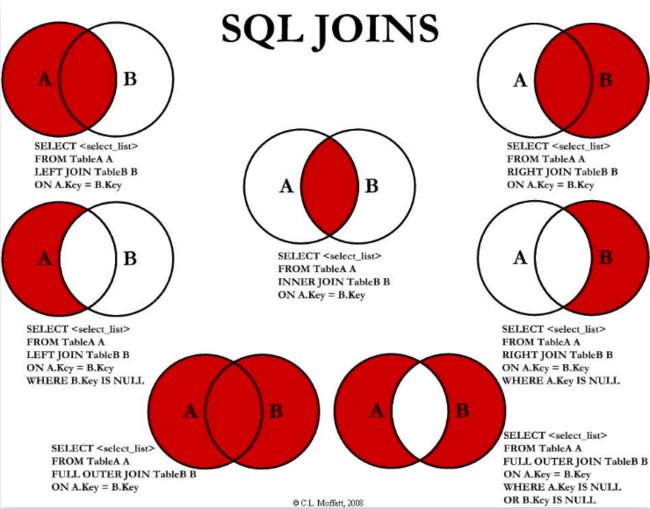
14.MySQL 的内连接、左连接、右连接有什么区别?
MySQL中的内连接、左连接和右连接是用来连接两个或多个表的操作,它们之间的区别如下:
- 内连接 (INNER JOIN):内连接返回两个表中满足连接条件的记录。即只返回两个表中共有的匹配数据行。如果一个表中的行没有匹配的行,则不会返回该行。
- 左连接 (LEFT JOIN):左连接返回左表中所有的记录,以及满足连接条件的右表中的匹配记录。如果右表中没有匹配的记录,那么返回的结果中右表的字段值将为
NULL。 - 右连接 (RIGHT JOIN):右连接返回右表中所有的记录,以及满足连接条件的左表中的匹配记录。如果左表中没有匹配的记录,那么返回的结果中左表的字段值将为
NULL。
15.什么是 JDBC?
(1)JDBC (Java Database Connectivity) 是 Java 语言中用于与关系型数据库进行交互的标准 API。它定义了一组 Java 接口和类,使得 Java 应用程序可以通过标准的方式连接、查询和操作各种关系型数据库,如 MySQL、Oracle、PostgreSQL、SQL Server 等。
(2)JDBC API 提供了一组标准的 Java 接口,用于连接数据库、执行 SQL 语句、处理结果集、事务处理等,使得 Java 程序员可以通过 Java 代码来操作数据库,而无需了解底层数据库的细节和特性。它将 Java 应用程序和各种关系型数据库解耦,使得 Java 应用程序能够以一种独立于数据库的方式进行开发和维护。
(3)JDBC API 包含两个层次:JDBC API 和 JDBC 驱动程序:
- JDBC API 定义了一组标准的接口和类,用于连接数据库、执行 SQL 语句、处理结果集、事务处理等。
- JDBC 驱动程序则提供了一组实现这些接口和类的具体实现,用于与不同的数据库进行交互。
(4)JDBC API 的使用非常广泛,几乎所有的 Java 应用程序都需要与数据库进行交互,包括 Web 应用程序、桌面应用程序、移动应用程序等。由于 JDBC API 是 Java 标准 API 的一部分,因此它与 Java 平台的兼容性非常好,而且各种数据库厂商都提供了相应的 JDBC 驱动程序,使得 Java 程序员可以方便地与各种数据库进行交互。
16.使用 JDBC 进行查询包括哪些步骤?
(1)使用 JDBC 进行查询通常包括以下步骤:
- 加载 JDBC 驱动程序:首先需要使用
Class.forName()方法加载数据库驱动程序,例如:
Class.forName("com.mysql.jdbc.Driver");
- 创建数据库连接:使用
DriverManager.getConnection()方法创建与数据库的连接,例如:
String url = "jdbc:mysql://localhost:3306/mydatabase";
String user = "myuser";
String password = "mypassword";
Connection conn = DriverManager.getConnection(url, user, password);
- 创建 SQL 查询语句:使用 Connection 对象的
createStatement()方法创建 Statement 对象,然后使用 Statement 对象创建 SQL 查询语句,例如:
Statement stmt = conn.createStatement();
String sql = "SELECT * FROM customers WHERE city = 'London'";
- 执行 SQL 查询语句:使用 Statement 对象的
executeQuery()方法执行 SQL 查询语句,例如:
//这里将 SQL 查询语句传递给 executeQuery() 方法,它会返回一个 ResultSet 对象,该对象包含查询结果的数据
ResultSet rs = stmt.executeQuery(sql);
- 处理查询结果:使用 ResultSet 对象的
getXXX()方法获取查询结果的数据,例如:
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String email = rs.getString("email");
System.out.println("id: " + id + ", name: " + name + ", email: " + email);
}
- 关闭连接和资源:使用 Connection、Statement 和 ResultSet 对象的
close()方法关闭连接和资源,例如:
rs.close();
stmt.close();
conn.close();
(2)综上所述,使用 JDBC 进行查询的步骤包括:加载 JDBC 驱动程序、创建数据库连接、创建 SQL 查询语句、执行 SQL 查询语句、处理查询结果和关闭连接和资源。
17.✨PreparedStatement 和 Statement 的区别是什么?
(1)PreparedStatement 和 Statement 是 Java 中用于与数据库交互的两种不同类型的接口,并且前者是后者的子接口,都可以用于执行 SQL 语句,但是它们之间有几个主要的区别:
- 预编译:PreparedStatement 可以预编译 SQL 语句,这意味着在执行 SQL 语句之前,数据库已经将 SQL 语句编译为字节码,并做好了准备。这样可以提高 SQL 语句的执行速度,特别是在重复执行相同 SQL 语句的情况下。
- 参数绑定:PreparedStatement 可以预处理参数并绑定到 SQL 语句中,这样可以避免 SQL 注入攻击。而 Statement 需要手动拼接 SQL 语句和参数,容易受到 SQL 注入攻击。
- 可读性:PreparedStatement 比 Statement 更易于阅读和理解,因为它使用占位符 (?) 代替 SQL 语句中的参数,而 Statement 则需要手动拼接 SQL 语句和参数。
- 性能:在执行相同 SQL 语句的情况下,PreparedStatement 的性能通常比 Statement 更好,因为 PreparedStatement 可以重复使用已编译的 SQL 语句。而 Statement 每次执行都需要重新编译 SQL 语句。

(2)综上所述,PreparedStatement 比 Statement 更加安全、易于阅读和理解,并且在执行相同 SQL 语句的情况下,性能更好。因此,在实际开发中,PreparedStatement 更常用。
与 SQL 注入攻击有关的知识可以参考 SQL 注入攻击介绍这篇文章。
18.MySQL 怎么删除数据?
(1)在 MySQL 中,删除数据的原理可以简单地概括为以下几个步骤:
- 解析查询:当执行 DELETE 语句时,MySQL 服务器首先会对该语句进行解析,识别出要删除的表、删除的条件等信息。
- 锁定表:接下来,MySQL 会对要删除的表进行锁定,以防止其他会话对表进行修改。这样可以确保在删除数据的同时,其他会话不能读取或修改相同的数据,从而保证数据的一致性。
- 查询优化:MySQL 会进行查询优化,分析 DELETE 语句的条件和表结构,选择最优的执行计划。这包括确定使用哪个索引、如何访问表等。
- 执行删除:在执行过程中,MySQL 会根据指定的条件扫描表中的数据行,删除满足条件的行。删除的方式可以是物理删除,即直接从磁盘上删除数据;也可以是逻辑删除,即标记数据为已删除,但保留在磁盘上以便以后恢复。
- 更新索引:如果删除操作涉及到索引,MySQL 会相应地更新索引,确保索引的正确性和一致性。这可能包括删除或修改索引中与已删除数据相关的信息。
- 释放锁:在删除操作完成后,MySQL 会释放对表的锁定,允许其他会话对表进行操作。
(2)需要注意的是,MySQL 的删除操作是一个原子操作,要么全部删除,要么一个都不删除。此外,删除操作的性能受多种因素影响,如表的大小、索引的使用、删除条件的复杂性等。对于大表的删除操作,可能需要较长的执行时间。为了保证删除操作的效率,可以考虑合理设计表结构、创建适当的索引和优化查询语句。
19.✨MySQL 中的视图是什么?有什么作用?如何创建?
(1)在 MySQL 中,视图 (View) 是基于查询结果的虚拟表。视图以查询的形式定义,并且可以像表一样使用。它提供了一种简化复杂查询、重用查询逻辑和实现安全性控制的方法。
(2)MySQL 中的视图有以下几个主要作用:
- 简化复杂查询:视图可以将复杂的查询逻辑封装在一个视图中,使查询语句更简洁易读。它可以将多个表的关联查询、聚合操作和过滤条件等封装到一个视图中,方便开发人员使用。
- 查询重用:通过创建视图,可以将常用的查询逻辑定义为视图,以便多次重用。这避免了重复编写相同的查询语句,并提高了查询的效率和维护性。
- 安全性控制:视图可以限制用户对数据的访问权限。通过在视图中设置筛选条件和隐藏敏感数据,可以实现数据安全性的控制。这样,用户只能通过视图访问部分数据,而不能直接访问底层的数据表。
- 数据抽象:视图可以将数据表的复杂结构抽象为简单的逻辑视图,隐藏了底层的表结构和数据组织。这使得开发人员可以更专注于逻辑层面的操作,而不必关心底层数据的具体细节。
- 性能优化:视图可以作为查询优化的手段之一。通过在视图上创建索引,可以提高查询性能。此外,视图还可以对底层数据表进行聚合操作,减少数据的冗余和重复存储,从而提升查询效率。
需要注意的是,尽管视图提供了上述的便利和功能,但它们并不是实际的物理表,它们只是存储在数据库中的查询定义。因此,在对视图进行查询时,实际上是执行视图定义的查询语句,而不是直接访问底层数据表。
(3)创建 MySQL 视图可以通过以下步骤:
- 使用
CREATE VIEW语句创建视图,并指定视图的名称。其中,view_name 是视图的名称,column1、column2 等是要选择的列,table_name 是用于构建视图的表,condition 是一个可选的 WHERE 子句,用于过滤数据。
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;
- 执行
CREATE VIEW语句后,视图会被创建并存储在数据库中。你可以像使用表一样使用这个视图,对它进行查询等操作。 - 当数据表被更新时,视图也会被更新。这意味着你可以通过视图查询到最新的数据,而无需手动更新视图。
(4)下面是一个实际的创建视图的示例:
假设我们有一个名为 “employees” 的表,包含 “emp_id”、“emp_name” 和 “salary” 等列。我们可以创建一个为 “high_salary_employees” 的视图,只包含薪资高于 100000 的员工:
CREATE VIEW high_salary_employees AS
SELECT emp_id, emp_name
FROM employees
WHERE salary > 100000;
这样,当我们查询 high_salary_employees 视图时,将只返回薪资高于 100000 的员工的员工编号和姓名。注意,视图只是一个虚拟的表,它实际上并不存储数据。它只是一个查询定义的结果集。因此,当查询视图时,实际上是执行视图定义的查询语句。
20.✨使用 limit 进行分页查询时存在什么问题?如何优化分页查询?
(1)使用 limit 进行分页查询存在的问题主要包括以下几点:
- 性能问题:使用
LIMIT进行分页查询时,数据库需要执行完整的查询,然后再将结果集中的部分数据截取出来。这意味着,在每次分页查询时,数据库需要获取和处理全部记录,即使只返回了部分数据。对于大数据量和复杂的查询,这可能导致性能问题,特别是在较高的页数或者需要获取很多数据时。 - 数据不稳定:由于数据库的数据的变动性,当在某一页进行翻页操作时,新的数据可能已经被插入或删除,导致页数的结果不稳定。这可能会导致分页数据的遗漏或重复,并且在下一页和上一页之间浏览时,数据可能发生变化。
- 缺少统计信息:使用
LIMIT进行分页查询,只能获取当前页的数据,而无法直观地看到总页数和总记录数。如果需要获取总页数和总记录数,通常需要额外执行一次查询来计算。
(2)基于游标和使用 ROW_NUMBER() 函数都是实现分页查询的常见方法,它们的原理如下:
- 基于游标的分页查询原理:基于游标的分页查询是通过在查询结果集中移动游标来实现分页的。当使用基于游标的分页查询时,数据库会将查询结果集存储到内存中,然后通过游标定位到指定的起始位置,并依次获取指定数量的数据,直到达到分页的结束位置。这种方式可以避免在数据库中反复查询和返回大量数据。
- 使用 ROW_NUMBER() 函数的分页查询原理:使用
ROW_NUMBER()函数可以给查询结果中的每一行分配一个序号。在分页查询时,可以利用ROW_NUMBER()函数给结果集中的每条记录编号,然后通过条件语句选择指定区间的序号范围来返回对应的分页数据。通常情况下,结合子查询进行使用,以便在外部查询中使用LIMIT或其他分页限制来获取指定的数据范围。
(3)这两种分页查询方式都可以在数据库中进行操作,但它们的实现方式略有不同:
- 基于游标的方式在内存中处理数据,适用于相对较小的数据量和需要快速响应的场景。
- 使用
ROW_NUMBER()函数可以在数据库层面进行排序和筛选,适用于大数据量和更精确的分页场景。
(4)以下是基于游标和使用 ROW_NUMBER() 函数的分页查询示例:
- 基于游标的分页查询示例:
DECLARE cur CURSOR FOR
SELECT column1, column2
FROM your_table
ORDER BY column1; -- 假设按列 column1 排序
SET @offset = 20; -- 起始位置
SET @limit = 10; -- 每页数据量
SELECT * FROM (
SELECT column1, column2, (@row_number:=@row_number + 1) AS row_num
FROM your_table, (SELECT @row_number := 0) AS t
ORDER BY column1
) AS subquery
WHERE row_num > @offset
LIMIT @limit;
- 使用 ROW_NUMBER() 函数的分页查询示例:
SELECT column1, column2
FROM (
SELECT column1, column2, ROW_NUMBER() OVER (ORDER BY column1) AS row_num
FROM your_table
) AS subquery
WHERE row_num BETWEEN 21 AND 30; -- 起始位置为 20,每页数据量为 10