HashMap源码前的知识储备:数据结构+算法
数据结构+算法
- 数据结构
- 摘要算法
- 二进制
1.数据结构
数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成 。
常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表等,如图所示:

每一种数据结构都有着独特的数据存储方式,下面为大家介绍它们的结构和优缺点
-
数组
数组是可以再内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。
优点:
1、按照索引查询元素速度快
2、按照索引遍历数组方便
缺点:
1、数组的大小固定后就无法扩容了
2、数组只能存储一种类型的数据
3、添加,删除的操作慢,因为要移动其他的元素。
适用场景:
频繁查询,对存储空间要求不大,很少增加和删除的情况。
-
链表
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
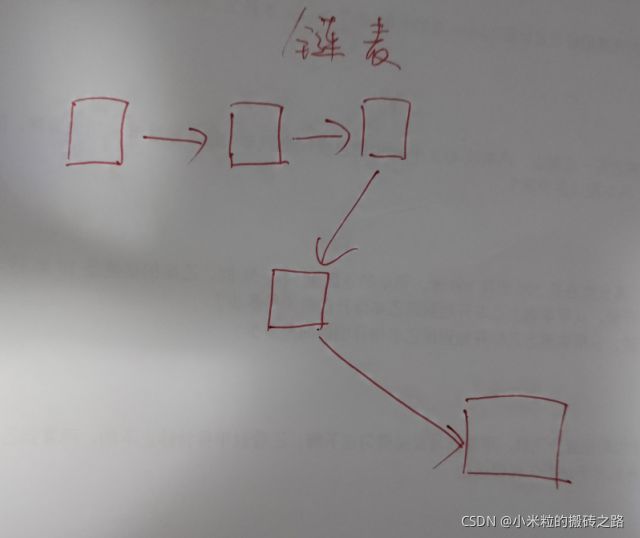
简单来说,就是不连续的存储空间,中间用箭头指向连接起来,所以它正好和数组相反,优缺点也显而易见
链表的优点:
链表是很常用的一种数据结构,不需要初始化容量,可以任意加减元素;
添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加,删除很快;
缺点:
因为含有大量的指针域,占用空间较大;
查找元素需要遍历链表来查找,非常耗时。
适用场景:
数据量较小,需要频繁增加,删除操作的场景
-
栈
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出,或者说是后进先出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。
集合里有专门存储栈的类叫Stack
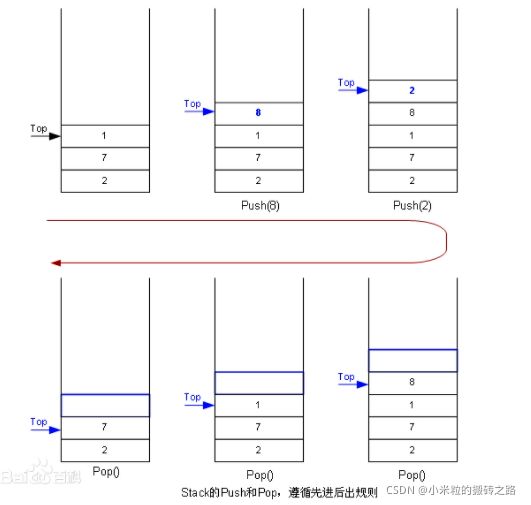
大家可以把他想象成电梯,先进后出,所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列,底层是递归,一层一层往上找,直到找到一个出口
-
队列
队列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。从一端放入元素的操作称为入队,取出元素为出队,示例图如下:
大家给他想象成我们小时候放学站队一样,先进先出,就很好理解了,在多线程阻塞队列管理中非常适用。
-
堆
堆是一种比较特殊的数据结构,可以被看做一棵树的数组对象,具有以下的性质:
(1)堆中某个节点的值总是不大于或不小于其父节点的值;
(2)堆总是一棵完全二叉树。
-
树
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
-
每个节点有零个或多个子节点;
-
没有父节点的节点称为根节点;
-
每一个非根节点有且只有一个父节点;
-
除了根节点外,每个子节点可以分为多个不相交的子树;
在日常的应用中,我们讨论和用的更多的是树的其中一种结构,就是二叉树。
二叉树是树的特殊一种,具有如下特点:
1、每个结点最多有两颗子树,结点的度最大为2。
2、左子树和右子树是有顺序的,次序不能颠倒。
3、即使某结点只有一个子树,也要区分左右子树。
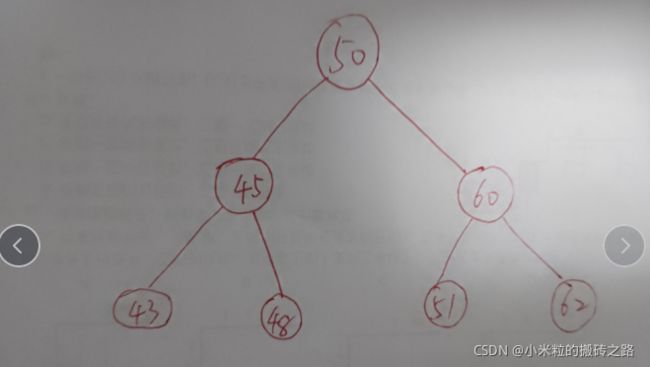
这样看二叉树像不像一道光洒在地上,每个节点都是一道影子,所以数是自带排序功能的,自左向右从小到大的排列
注意注意:
二叉树有很多扩展的数据结构,包括平衡二叉树、红黑树、B+树等,这些数据结构二叉树的基础上衍生了很多的功能,在实际应用中广泛用到,例如mysql的数据库索引结构用的就是B+树,还有HashMap的底层源码中用到了红黑树。
红黑树是自平衡的二叉树
什么叫平衡,简单理解就是任意节点的左右两个子树高度差都小于等于1,这样便利起来会更均匀
红黑树的自平衡,就是他会通过变色和旋转,使自己可以动态的平衡,也就是说不用你来平衡我,
我可以自己变化。类比的话,平衡二叉树就像学校里的女朋友,比较孩子气,一不开心就需要你哄,
需要你去让她平衡。红黑树相当于比较成熟的贤妻良母,当她不开心的时候,可以自己调节。
推荐个视频,专讲红黑树
https://www.bilibili.com/video/BV11E411Y77y?
下一篇讲解hashmap源码的时候就用到了这个知识点
-
图
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
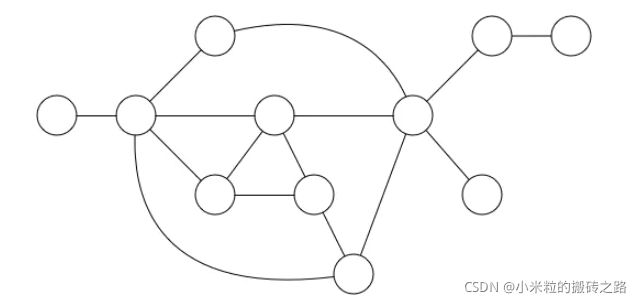
看起来像人物关系图一样,我们能从中间找到两个人共同的好友,就像微信的群聊一样
另一个应用就是jvm虚拟机垃圾回收的时候,会定时检查这个节点和别的节点有没有关系,然后再判断是否回收(jvm具体会讲到)
-
散列表
散列表,也叫哈希表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。(HashMap那一篇中页提到了哈希表https://blog.csdn.net/weixin_48682891/article/details/121583836?spm=1001.2014.3001.5501)
记录的存储位置=f(key)
这里的对应关系 f 成为散列函数,又称为哈希 (hash函数),而散列表就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。
哈希表在应用中也是比较常见的,就如Java中有些集合类就是借鉴了哈希原理构造的,例如HashMap,HashTable等,利用hash表的优势,对于集合的查找元素时非常方便的,然而,因为哈希表是基于数组衍生的数据结构,在添加删除元素方面是比较慢的,所以很多时候需要用到一种数组链表来做,也就是拉链法。拉链法是数组结合链表的一种结构,较早前的hashMap底层的存储就是采用这种结构,直到jdk1.8之后才换成了数组加红黑树的结构,其示例图如下:

从图中可以看出,左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
了解了哈希表之后,我们再看源码就不会费劲了哦~~~
2.摘要算法
- 什么是摘要算法
(1)绕口的概念
摘要算法是把任意长度的输入揉和而产生长度固定的伪随机输出的算法。
(2)消息摘要的主要特点有:
(1)无论输入的消息有多长,计算出来的消息摘要的长度总是固定的。例如应用MD5算法摘要的消息有128个比特位,用SHA-1算法摘要的消息最终有160比特位的输出,SHA-1的变体可以产生192比特位和256比特位的消息摘要。一般认为,摘要的最终输出越长,该摘要算法就越安全。
(2)加密过程不需要密钥,并且经过加密的数据无法被解密,可以被解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。
(3)摘要算法的用途
比如用户注册某个网站的时候要输入密码,但是身为网站的管理员你不能看到别人的密码(废话,不然就乱套了)所以用户在网页输入密码之后会用摘要算法解析为密钥存到数据库中,当用户再次校验的时候,再把数据库的秘钥再进行解析,看两次的内容是否一致,如果一致就证明你的密码没人动过,两次是一样的,否则就证明不一样…
再者可以想我们在迅雷下载电影的时候就是这个道理,下载到本地的时候会提示你改程序不受信任~~~
- hash(哈希)是什么
在区块链技术当中经常会听到哈希,那么什么是哈希呢,其实很简单。
Hash,哈希的英文是Hash,中文可翻译成散列或者哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。
简单点说,hash就是把任意的内容通过计算转换成一个特殊的值。文章也好,数字也好,视频也好……不管你的原内容有多大,转换后的结果都是同一个格式的值,这个值可以是字符串,可以是数字,具体取决于调用的算法。就像不管你是电影明星,还是社会大佬,还是企业高管,不管你有多少头衔,进了监狱,你就只有代号

哈哈哈哈哈哈想想我们刚才说的摘要算法,做摘要嘛,就像一本书或者一部电影的介绍一样,提取特点用简短的语言描述而已。
比如学校里有一千个学生,校长让我给他找几个学习好的同学,或者让我给他找几个会拉格朗日中值定理的同学,每个学生掌握的知识程度都不一样,我他妈上哪找去,一个一个问啊,这也太慢了,而且万一他明明不会缺骗我说他会怎么办?

考试!!!通过考试,把每个学生的学习成果由抽象概念转换成了一个真实的分数,现在校长让我找学习最好的同学,我就可以去找考试满分的同学,让我找会拉格朗日的同学,我就可以找相关题目答满分的同学。这样是不是就很方便了,第一减少了我的查询时间,第二学生不能不懂装懂。
以上例子就可以理解为一个摘要算法(哈希),你交白卷也好,你全写了也好,你填写的内容就是原文,考试的打分规则就是这里的算法,经过计算后给你得出你的分数,这就是你的哈希值。不管你原文有多长,不管你本人有多吊或者你爸是校长,你得到的分数都是0-满分之间。
再次总结一下hash的特点和用法:
- 任意长度的输入,得到固定长度的输出
- 不可逆,可以把原文计算成密文,但是不能倒推回去
解释:比如“你真厉害”计算后为“aaa",但是你无法通过”aaa"推导出他的原文 - 算法不固定,只要满足hash的思想就是hash算法。加密领域的常见摘要算法有md5,sha256等。
- 可以用来快速检索:比如比较一篇文章和其他一万篇文章是否相同,一行一行去看太慢了,做个哈希转换成某些数字去比较会更快。
- 防篡改:密码学里的主要用途,因为只能加密不能解密,所以发送数据时会把原文加密后把原文和密文一起发给对方,对方收到后,先对原文做个加密,如果密文和收到的一样说明内容没被改过。常见的比如用迅雷下载时,一般会带一个md5文件,如果下载完成后提示文件不安全,那可能就是源文件被修改过和提供的密文不一致。
- 密码保存。注册密码都是加密后保存在数据库的,好处就是数据库维护人员无法直接看到用户的密码,并且无法倒推。用户登录时,输入密码,计算hash,和数据库里存的去比较。
为什么要用哈希表?上一篇文章中讲到过,也可以参考这篇博客http://m.elecfans.com/article/1194442.html
3.二进制
- 二进制是一套计数方法,每个位置上的数有 2 种可能(0 - 1)
- 二进制是计算机的执行语言,但是早在计算机出现前就存在这套计数方法,最早可追溯到古埃及。
- 二进制转换
计算机运行的是二进制,但是我们在键盘上输入的并非二进制的内容,而是字母、数字(十进制)、汉字等,那计算机是怎么知道把这些内容转成二进制呢?计算机是人设计的,在了解计算机将我们输入的内容转成二进制前,先简单看下十进制和二进制的转换。

这里的套路是:
(1)算出 2 的 n 次幂不大于要表示的值;
(2)用要表示的值减去 2n,得到剩下的值后,重复步骤 1,直到最后剩下 0 为止。
举个例子,十进制的 107 如何转成二进制,先找出 2 的 n 次幂不大于 107 ,算得 n = 6,用 107 减去 26 得到 43;重复下来后 :
107 = 1 x 26 + 1 x 25 + 0 x 24 + 1 x 23 + 0 x 22 + 1 x 21 + 1 x 20 ,如果该位用到,用 1 表示,否则用 0 表示。所以 107 用二进制表示为:01101011
二进制转成十进制就是相反的过程,如 01011001 转成十进制:
01011001 = 0 x 27 + 1 x 26 + 0 x 25 + 1 x 24 + 1 x 23 + 0 x 22+ 0 x 21 + 1 x 20 = 89
其实简单一点来记住就是8421,比如1是01 ,2是10,3是11,以此类推,可以把你要转换的数字分成8 4 2 1的和就好计算很多,比如14=8+4+2,所以二进制是1110,16是10000…是不是简单了很多

有了二进制的基础,再看源码就不会费劲了呢
接下来就开始源码的讲解吧,移步下一篇吧~~~