【linux】linux grep命令使用详解
前言
在linux命令行中,经常需要对当前获取的一堆数据进行过滤、提取和分析,其中grep命令是其中非常重要的命令之一,比如,在生产环境服务器上,经常使用到下面这个命令
ps -ef | grep java
- 1
显然,grep的作用就是帮助筛选出那些运行中的java进程
grep 作用
文本搜索工具,根据用户指定的“模式”(过滤条件),对目标文本逐行进行匹配,并打印输出匹配到的行;
模式:由正则表达式的元字符串及文本字符串所编写的过滤条件
grep 完整语法结构
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
- 1
- 2
- 3
上述语法结构中,经常可配合下面的参数一起使用
-i : 忽略大小写;
-o : 仅显示匹配到目标字符串;
-v : 显示不能被匹配到的字符串(反转);
-E : 支持使用扩展的正则表达式字符串;
-q : 静默模式,不输出任何信息
- 1
- 2
- 3
- 4
- 5
grep命令是linux系统命令中最重要的命令之一,功能是从文本文件,或者管道数据流中筛选出匹配到的行或数据,如果再配合正则表达式,功能将十分强大;
grep 命令里的匹配模式,就是你想要找出来的数据,可以是普通的文字符号,也可以是正则表达式;
grep常用的参数总结
| 参数选项 | 解释说明 |
|---|---|
| -V | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配行数 |
| -E | 使用egrep命令 |
| -o | 只输出匹配内容 |
| -w | 只输出过滤的单词 |
| -F | 不适用正则表达式 |
| -l | 列出包含匹配项的文件名 |
| -L | 列出不包含匹配项的文件名 |
参数记住秘诀:vic win of line;
grep中常用正则表达式
一、基本常用正则表达式汇总
| 表达式 | 解释说明 |
|---|---|
| ^ | 用于模式最左侧,如 “^yu” 即匹配以yu开头的单词 |
| $ | 用于模式最右侧,如 “yu$” 即匹配以yu结尾的单词 |
| ^$ | 组合符,表示空行 |
| . | 匹配任意一个且只有一个字符,不能匹配空行 |
| | 转义字符 | |
| * | 重匹配前一个字符连续出现0次或1次以上 |
| .* | 匹配任意字符 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合符,匹配任意多个字符结尾的内容 |
| [abc] | 匹配 [] 内集合中的任意一个字符,a或b或c,也可以写成 [ac] |
| [^abc] | 匹配除了 ^后面的任意一个字符,a或b或c,[]内 ^ 表示取反操作 |
案例演示
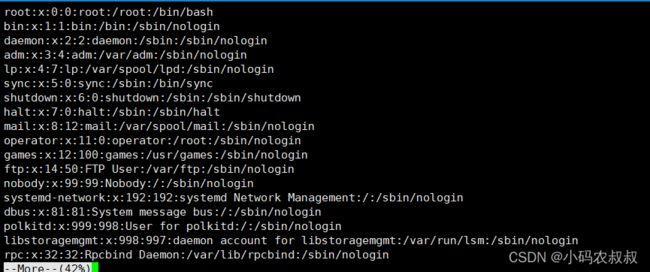
素材准备,将系统中账户密码输出到一个pwd.txt文件中
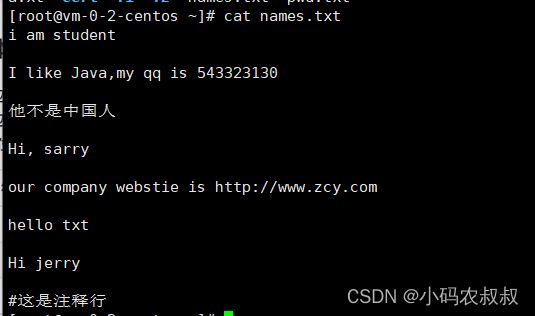
自定义一个names.txt 的文件,内容如下
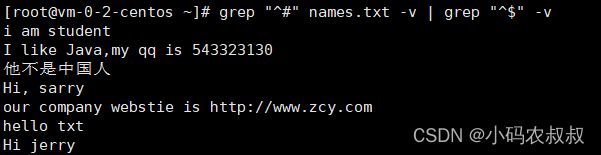
1、找出names.txt中的注释行,并过滤空行
grep "^#" names.txt -v | grep "^$" -v
- 1
2、输出以h开头的行,不区分大小写
这里重点考察对 “^” 的使用
grep -i "^h" names.txt
- 1

3、输出以/bin/bash结尾的行
grep -n "bin/bash$" pwd.txt
- 1

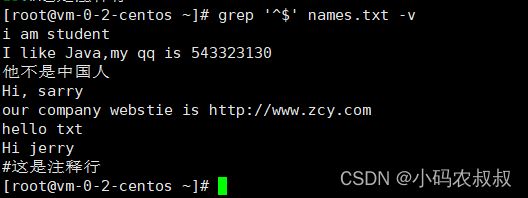
4、过滤非空的行
grep '^$' names.txt -v
- 1
5、匹配文本中至少包含一个 is 的行
grep -i ".is" names.txt
- 1

6、匹配文本中包含数字的行
考察对 [abc] 类似的用法
- [a-z] 匹配所有小写单个字母
- [A-Z] 匹配所有大写单个字母
- [a-zA-Z] 匹配所有单个大小写字母
- [0-9] 匹配所有单个数字
- [0-9a-zA-Z] 匹配所有数字和字母
grep "[0-9]" names.txt
- 1

二、扩展正则表达式使用
| 表达式 | 解释说明 |
|---|---|
| + | 表示匹配前一个字符一次或多次 |
| ? | 表示匹配前一个字符0次或1次 |
| () | 将一个或多个字符捆绑在一起,当作整体进行处理 |
| {n,m} | 匹配目标字符,最少n次,最多m次 |
| {n,m} | 匹配目标字符,最少n次,上不封顶 |
| > | 匹配位于 目标字符开头的字符串,即截止到 < 前面的字符为止,精确匹配 |
| < | 匹配位于 目标字符结尾的字符串,即截止到 > 前面的字符为止,精确匹配 |
案例演示
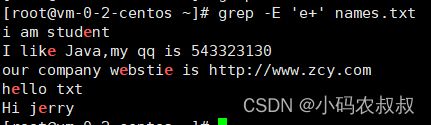
1、筛选前一个字符包含e的的文本行
grep -E 'e+' names.txt
- 1
2、筛选前一个字符包含he的出现0次或者1次的文本行
grep -E 'he?' names.txt
- 1

3、找出文本中包含 “hi” 或 “java” 的文本行
grep -E -i 'hi|java' names.txt
- 1

4、找出文本中包含 good和glad的文本
这里考察使用小括号() 分组的用法,下面有一个测试文本文件,内容如下
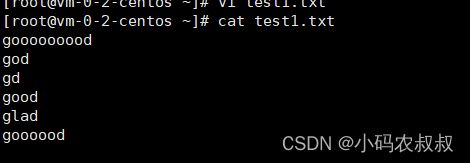
grep -E 'g(oo|la)d' test1.txt
- 1

5、找出文本中的 o 字符出现的次数最少2次,最多7次的文本行
考察dui {n,m}的用法,表示匹配的字符最少n次,最多m次
grep -E 'o{2,7}' test1.txt
- 1

6、找出文本中的 o 字符出现的次数最少3次
grep -E 'o{3,}' test1.txt
- 1

7、找出文本中root用户和zcy用户
如果像下面这样直接使用grep命令查找,可以看到zcy这个字符串开头的账户有多个,显然不符合预期
grep -E '^(root|zcy)' pwd.txt
- 1
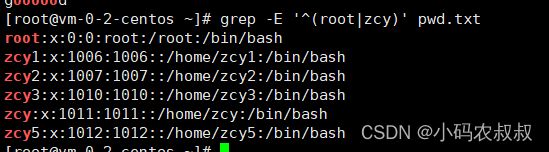
这就需要使用到 > 这个表达式了,改进之后,再次执行就符合预期的目标了
grep -E '^(root|zcy)\>' pwd.txt
- 1

三、常用grep 正则表达式参数汇总
下面提供一些grep相关的可选参数,方便遇到问题时快速查阅
| 表达式 | 解释说明 |
|---|---|
| -a 或 --text | 不要忽略二进制的数据。 |
| -A<显示行数> 或 --after-context=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 |
| -b 或 --byte-offset | 在显示符合样式的那一行之前,标示出该行第一个字符的编号。 |
| -B<显示行数> 或 --before-context=<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前的内容。 |
| -c 或 --count | 计算符合样式的列数。 |
| -C<显示行数> 或 --context=<显示行数>或-<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前后的内容 |
| -d <动作> 或 --directories=<动作> | 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作 |
| -e<范本样式> 或 --regexp=<范本样式> | 指定字符串做为查找文件内容的样式。 |
| -E 或 --extended-regexp | 将样式为延伸的正则表达式来使用。 |
| -f<规则文件> 或 --file=<规则文件> | 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。 |
| -F 或 --fixed-regexp | 将样式视为固定字符串的列表。 |
| -G 或 --basic-regexp | 将样式视为普通的表示法来使用。 |
| -h 或 --no-filename | 在显示符合样式的那一行之前,不标示该行所属的文件名称。 |
| -H 或 --with-filename | 在显示符合样式的那一行之前,表示该行所属的文件名称。 |
| -i 或 --ignore-case | 忽略字符大小写的差别。 |
| -l 或 --file-with-matches | 列出文件内容符合指定的样式的文件名称。 |
| -L 或 --files-without-match | 列出文件内容不符合指定的样式的文件名称。 |
| -n 或 --line-number | 在显示符合样式的那一行之前,标示出该行的列数编号。 |
| -o 或 --only-matching | 只显示匹配PATTERN 部分。 |
| -q 或 --quiet或–silent | 不显示任何信息。 |
| -r 或 --recursive | 此参数的效果和指定"-d recurse"参数相同 |
| -s 或 --no-messages | 不显示错误信息 |
| -v 或 --invert-match | 显示不包含匹配文本的所有行 |
| -V 或 --version | 显示版本信息。 |
| -w 或 --word-regexp | 只显示全字符合的列 |
| -x --line-regexp | 只显示全列符合的列 |
| -y | 此参数的效果和指定"-i"参数相同 |
其他grep相关案例总结
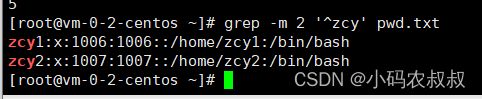
1、统计出zcy 账户出现的次数
grep -c '^zcy' pwd.txt
- 1

2、匹配zcy这个账户,匹配结果最多展示2条
grep -m 2 '^zcy' pwd.txt
- 1
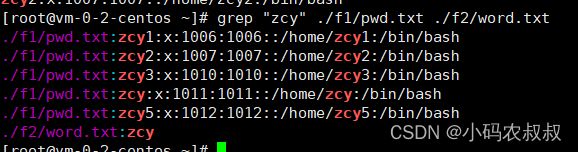
3、匹配多文件下,存在某个字符串的内容
grep "zcy" ./f1/pwd.txt ./f2/word.txt
- 1
4、找出系统密码中那些仅包含2位数或者3位数的内容
grep -n -E "\<[0,9]{2,3}\>" ./pwd.txt
- 1

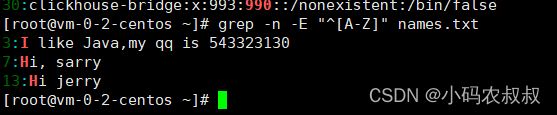
5、匹配那些以大写字母开头的行
grep -n -E "^[A-Z]" names.txt
- 1
6、从多个账户中匹配出任意一个符合要求的
grep -n -E "^(root|zcy|nobidy)\>" ./pwd.txt
- 1

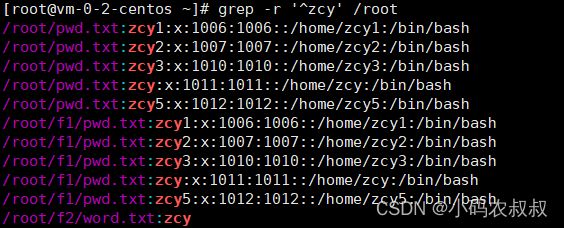
7、递归找出当前root目录下所有文件中包括zcy字符的文件
grep -r '^zcy' /root
- 1