慢SQL的致胜法宝 | 京东物流技术团队
大促备战,最大的隐患项之一就是慢SQL,对于服务平稳运行带来的破坏性最大,也是日常工作中经常带来整个应用抖动的最大隐患,在日常开发中如何避免出现慢SQL,出现了慢SQL应该按照什么思路去解决是我们必须要知道的。本文主要介绍对于慢SQL的排查、解决思路,通过一个个实际的例子深入分析总结,以便更快更准确的定位并解决问题。
解决步骤
step1、观察SQL
出于一些历史原因有的SQL查询可能非常复杂,需要同时关联非常多的表,使用一些复杂的函数、子查询,这样的SQL在项目初期由于数据量比较少,不会对数据库造成较大的压力,但是随着时间的积累以及业务的发展,这些SQL慢慢就会转变为慢SQL,对数据库的性能产生一定的影响。
对于这样的SQL,建议先了解业务场景,梳理关联关系,尝试将SQL拆解为几个简单的小SQL,在内存中关联组合。
step2、分析问题
大家在分析慢SQL时最常用的工具肯定是explain语句,如下是explain语句的执行输出。
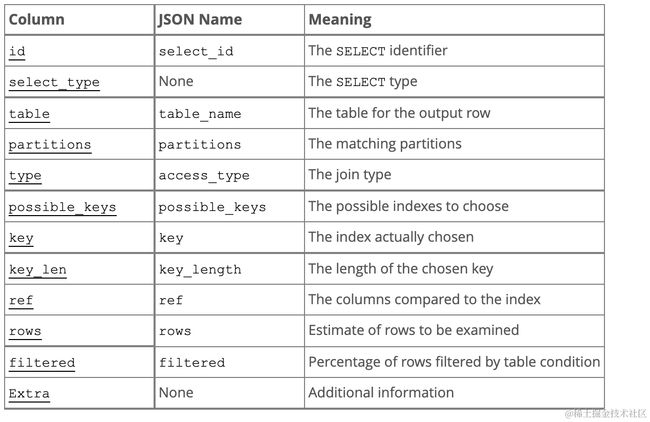
一般情况下我们最需要关注的指标有type、possible_keys、key、rows、extra几项。
type为连接类型,有如下几种取值,性能从好到坏排序如下:
- system:该表只有一行(相当于系统表),system是const类型的特例
- const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
- eq_ref:当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,性能仅次于system及const。
- ref:当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。如果使用的索引只会匹配到少量的行,性能也是不错的。
TIPS
最左前缀原则,指的是索引按照最左优先的方式匹配索引。比如创建了一个组合索引(column1, column2, column3),那么,如果查询条件是:
- WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 都可以使用该索引;
- WHERE column1 = 2、WHERE column1 = 1 AND column3 = 3就无法匹配该索引。
- fulltext:全文索引
- ref_or_null:该类型类似于ref,但是MySQL会额外搜索哪些行包含了NULL。这种类型常见于解析子查询
- index_merge:此类型表示使用了索引合并优化,表示一个查询里面用到了多个索引
- unique_subquery:该类型和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引。例如:
index_subquery:和unique_subquery类似,只是子查询使用的是非唯一索引
range:范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有BETWEEN子句或WHERE子句里有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
- index:全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
- 如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
- 按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
- ALL:全表扫描,性能最差。
possible_keys
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
key
表示MySQL实际选择的索引,重点需要注意Using filesort和Using temporary,前者代表无法利用索引完成排序操作,数据较少时从内存排序,否则从磁盘排序,后者MySQL需要创建一个临时表来保存结果。
通过EXPLAIN可以初步定位出SQL是否使用索引,使用的索引是否正确,排序是否合理、索引列区分度等情况,通过这些基本就可以定位出绝大部分问题。
step3、指定方案
若无法从SQL本身解决可以根据业务场景和数据分布情况等因素合理制定修改方案。
案例展示
1、本SQL主要存在两个问题,一个是查询结果数据量较大,大约2W条数据,其次就是根据非索引字段oil_gun_price排序,造成filesort。有两种修改选择,一种是改造为分页查询,根据id升序排序,根据id偏移避免深分页的问题,另外就是直接获取符合条件的全量数据,不指定排序方式,然后在内存中排序即可。像这样的场景尽量不要使用数据库进行排序,除非可以直接利用索引进行排序,不然尽量选择一次性或者分页的方式将所有数据加载到内存后在进行排序。
SELECT gs.id,
gs.gas_code,
gs.tpl_gas_code,
gs.gas_name,
gs.province_id,
gs.province_name,
gs.city_id,
gs.city_name,
gs.county_id,
gs.county_name,
gs.town_id,
gs.town_name,
gs.detail_address,
gs.banner_image,
gs.logo_image,
gs.longitude,
gs.latitude,
gs.oil_gun_serials,
gs.gas_labels,
gs.status,
gs.source,
gp.oil_number,
gp.oil_gun_price
FROM fi_club_oil_gas gs
LEFT JOIN fi_club_oil_gas_price gp ON gs.gas_code = gp.gas_code
WHERE oil_number = 95
AND status = 1
AND gs.yn = 1
AND gp.yn=1
ORDER BY gp.oil_gun_price ASC;
2、本SQL主要的问题在于在关联查询中使用了子查询进行拼接,子查询中条件较少,相当于先执行了一次全表扫描,将第一次查询的结果加载到内存中再去执行关联,查询时长2.63秒,是比较常见的导致慢SQL的原因,应该尽量避免使用,这里选择子查询改为关联查询,最后执行时长0.71秒
SELECT count(0)
FROM trans_scheduler_base tsb
INNER JOIN
(SELECT scheduler_code,
vehicle_number,
vehicle_type_code
FROM trans_scheduler_calendar
WHERE yn = 1
GROUP BY scheduler_code) tsc ON tsb.scheduler_code = tsc.scheduler_code
WHERE tsb.type = 3
AND tsb.yn = 1;
----------修改后--------------
SELECT count(distinct(tsc.scheduler_code))
FROM trans_scheduler_base tsb
LEFT JOIN trans_scheduler_calendar tsc ON tsb.scheduler_code = tsc.scheduler_code
WHERE tsb.type = 3
AND tsb.yn = 1
AND tsc.yn=1
3、本SQL比较典型,是非常容易被忽视但又经常出现的慢SQL。SQL中carrier_code和trader_code都有索引,但是最后使用了update_time索引,这是由于MYSQL优化器优化后的结果,可能导致实际执行时使用的索引跟预想的不一样,这种SQL常见于在使用共用的查询SQL,实际上很多情况下并不能完全适用,例如排序方式,查询字段,返回条数等等,因此还是建议不同的业务逻辑使用自己单独定义的SQL。解决方式可以使用force_index根据情况指定索引或者修改排序方式
SELECT id,
carrier_name,
carrier_code,
trader_name,
trader_code,
route_type_name,
begin_province_name,
begin_city_name,
begin_county_name,
end_province_name,
end_city_name,
end_county_name
FROM carrier_route_config
WHERE yn = 1
AND carrier_code ='C211206007386'
AND trader_code ='010K1769496'
ORDER BY update_time DESC
LIMIT 10;
![]()
对于 limit N 带有 group by ,order by 的 SQL 语句 (order by 和 group by 的字段有索引可以使用),MySQL 优化器会尽可能选择利用现有索引的有序性,减少排序–这看起来是 SQL 的执行计划的最优解,但是实际上效果可能会南辕北辙,相信大家都遇到过很多案例中 SQL 执行计划选择 order by id 的索引进而导致全表扫描,而不是利用 where 条件中的索引查找过滤数据,这样就可能导致查询很低效(当然查询也可能很高效,这个跟表中数据的具体分布有关)
order by limit 优化能起到正面作用的前提是,首先假设有序索引和无序索引是不相关的,其次假设数据是均匀分布的。
这两个假设是估算通过排序索引来访问cost 的前提(但是现实生产环境中这两个假设在绝大多数场景中都是不成立的,所以就造成多数场景下索引选择错误),有可能会遇到通过条件索引过滤执行时间为几十毫秒,但是通过索引排序扫描耗时1小时的情况,可以认为是MySQL的一个bug。
4、SQL中的limit也是经常导致慢SQL的原因之一,当对SQL使用了limit进行限制时,如果SQL使用的limit限制大于剩余的总条数,并且使用的索引条件不能很好的利用上有序的特性,那么MYSQL很可能会进行全表扫描。例如下面这个SQL,SQL在执行过程中使用了create_time索引,但是条件中没有create_time作为条件,而SQL结果总条数为6,小于此时limit的结果10,因此MYSQL进行了全表扫描,耗时2.19秒,而当将limit改为6时,SQL执行时长为0.01秒,因为当MYSQL在查询到6条满足条件的结果时就直接返回了,不会再进行全表扫描。因此,当分页查询的数据已经不满一页的情况下,最好手动设置limit参数。
SELECT cva.id,
cva.carrier_vehicle_approval_code,
dsi.driver_erp,
d.driver_name,
cva.vehicle_number,
cva.vehicle_type,
cva.vehicle_kind,
cva.fuel_type,
cva.audit_user_code,
dsi.driver_id,
cva.operate_type,
dsi.org_code,
dsi.org_name,
dsi.prov_code,
dsi.prov_name,
dsi.area_code,
dsi.area_name,
dsi.node_code,
dsi.node_name,
dsi.position_name,
cva.create_user_code,
cva.audit_status,
cva.create_time,
cva.audit_time,
cva.audit_reason,
d.jd_pin,
d.call_source,
cv.valid_status
FROM driver_staff_info dsi
INNER JOIN carrier_vehicle_approval cva ON cva.driver_id = dsi.driver_id
INNER JOIN driver d ON dsi.driver_id = d.driver_id
INNER JOIN carrier_vehicle_info cv ON cv.vehicle_number = cva.vehicle_number
WHERE dsi.yn = 1
AND d.yn = 1
AND cva.yn = 1
AND cv.yn = 1
AND dsi.org_code = '3'
AND dsi.prov_code = '021S002'
AND cva.carrier_code = 'C230425013337'
AND cva.yn = 1
AND cva.audit_status = 0
AND d.call_source IN ('kuaidi',
'kuaiyun')
ORDER BY cva.create_time DESC
LIMIT 10
5、如下SQL表关联过多,导致数据库加载的数据量比较大,可以根据实际情况选择先查出来一张表的数据作为基础数据,再根据连表条件把剩下的字段填充上。数据量较大的表不建议关联过多表,可以通过适当冗余字段或者加工宽表代替。
SELECT blsw.bid_line_code,
blsw.bid_bill_code,
blsw.bid_line_name,
blsw.step_code,
blsw.step_type,
blsw.step_type_name,
blsw.step_weight,
blsw.step_weight_scale,
blsw.block_price,
blsw.max_weight_flag,
blsw.id,
blsw.need_quote_price,
bbs.step_item_code,
bbs.step_item_name,
bbs.step_seq,
bl.bid_line_seq
FROM bid_line_step_weight blsw
LEFT JOIN bid_bill_step bbs
ON blsw.bid_bill_code = bbs.bid_bill_code
AND blsw.step_code = bbs.step_code
AND blsw.step_type = bbs.step_type
LEFT JOIN bid_line bl
ON blsw.bid_line_code = bl.bid_line_code
AND blsw.bid_bill_code = bl.bid_bill_code
WHERE blsw.yn = 1
AND bbs.yn = 1
AND bl.yn=1
AND blsw.bid_bill_code = 'BL230423051192';
6、本SQL使用update_time作为时间范围索引,需要注意是否存在热数据过于集中的问题,导致查询数据量非常大,排序条件比较复杂,无法直接通过SQL优化解决。一方面需要先解决热数据过于集中的问题,一方面需要根据业务场景优化,比如增加一些默认条件以缩减数据量。
SELECT r.id,
r.carrier_code,
r.carrier_name,
r.personal_name,
r.status,
r.register_org_name,
r.register_org_code,
r.register_city_name,
r.verify_status,
r.cancel_time,
r.reenter_time,
r.verify_user_code,
r.data_source,
r.sign_contract_flag,
r.register_time,
r.update_time,
r.promotion_erp,
r.promotion_name,
r.promotion_pin,
r.board_time,
r.sync_basic_status,
r.personal_verify_result,
r.cert_verify_result,
r.qualify_verify_result,
r.photo_verify_result,
d.jd_pin,
d.driver_id,
v.vehicle_number,
v.vehicle_type,
v.vehicle_length,
r.cancellation_code ,
r.cancellation_remarks
FROM carrier_resource r
LEFT JOIN carrier_driver d
ON r.carrier_code = d.carrier_code
LEFT JOIN carrier_vehicle v
ON r.carrier_code = v.carrier_code
WHERE r.update_time >= '2023-03-26 00:00:00'
AND r.update_time <= '2023-04-02 00:00:00'
AND r.yn = 1
AND v.yn = 1
AND d.yn = 1
AND d.status != -1
AND IFNULL(r.carrier_individual_type,'') != '2'
ORDER BY (case r.verify_status
WHEN 30 THEN
1
WHEN 20 THEN
2
WHEN 25 THEN
3
WHEN 35 THEN
4
WHEN 1 THEN
5
ELSE 6 end), r.update_time desc, if((v.driving_license_time IS null
AND d.driver_license_time IS null), 0, 1) desc, if(((v.driving_license_time IS NOT null
AND v.driving_license_time < NOW())
OR (d.driver_license_time IS NOT null
AND d.driver_license_time < NOW())), 2, 0) DESC LIMIT 10;
实际开发过程中还有许多从SQL本身不好优化的场景,比如查询数据加载过多、表数据量过大、数据倾斜严重等等,尽量根据业务场景进行一些必要的保护措施限制,在不影响业务的情况下寻找替代方案,例如使用ES进行查询,不过还是需要根据实际的场景选择不同的方式解决。
7、对于一些较大数据量的表,在进行分页查询的时候其实很快就能返回结果,但是在进行分页count总条数时往往很慢,这是因为在分页查询时会有pageSize的限制,当MYSQL查询到满足条数的数据后就会直接返回,而在进行count时则会根据条件全表查询,当条件包含的数据量过大时就会限制SQL的性能。这种情况下建议一方面将分页逻辑重写,分离count和selectList,可以考虑应用ES作为count数据来源,或在某些条件下如果已存在总条数则不再count,减少分页count的次数;另一方面限制分页深度避免出现深分页。
总体优化原则
- 创建合适的索引
- 减少不必要访问的列
- 使用覆盖索引
- 语句改写
- 数据结转
- 选择合适的列进行排序
- 适当的列冗余
- SQL拆分
- 适当应用ES
作者:京东物流 李文浩
来源:京东云开发者社区 自猿其说Tech 转载请注明来源