Git:Git的一些基本操作
文章目录
- 基本认识
- 使用方法
-
- 创建本地仓库
- 配置本地仓库
- 工作区、暂存区、版本库的概念
- 添加文件
- 版本回退
- 撤销修改
- 删除操作
基本认识
首先要对Git有一个基本的认知:
Git本质上是一个版本控制器,可以对一个信息的多个版本进行一些控制,而能对版本的控制的好处就是,不管需要哪个版本的内容,都可以借助Git这个工具找到所需要的信息
Git是一个软件,它又是客户端又是服务器
Git是一个只会记录变化的软件
Git是分布式软件,去中心化的
而我们熟知的所谓的Github和Gitee,实际上都是网站,这两个网站都是基于Git软件搭建的网站,简单来说,就是让版本的管理可视化而非命令行,有助于进行版本的管理
使用方法
下面进行Linux中关于Git的一些使用场景:
创建本地仓库
在使用Git前,首先要对创建一个Git的仓库:
git init
此时目录下看似没有信息,实际上已经有了一个信息:.git
而这个.git中是存在许多信息的:
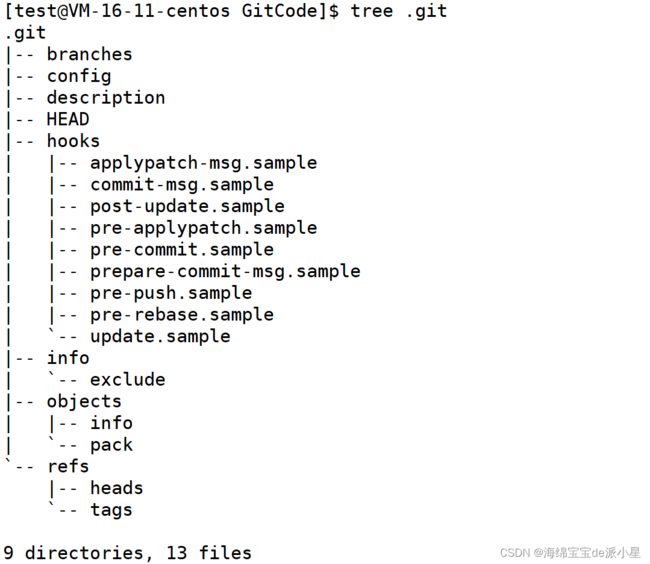
而这个文件就是代码在本地的一个仓库,仓库就创建好了
配置本地仓库
对于本地仓库的配置,首先要配置的是name和email的信息
配置name和email
# 配置用户名为xxx
git config user.name "xxx"
# 配置邮箱地址为xxxxxx
git config user.email "xxxxxxxxxx"
# 查看配置的信息
git config -l
删除name和email
信息有录入的途径,也会有删除的途径,Git本地仓库配置删除操作有:
# 删除name
git config --unset user.name
# 删除email
git config --unset user.email
此时再次查看配置信息就没有之前的信息了
–global的概念
在录入信息和删除中可以加入--global这个选项:
git config --global user.name "xxx"
git config --global user.email "xxxxxxxxxx"
git config --global --unset user.name
git config --global --unset user.email
这个选项的意思是,表示这台机器上的所有的Git仓库都采用了这个配置,因为在一台机器上是可以存在多个仓库的
为什么要配置仓库的用户名和邮箱?
这是由于Git本身的功能决定的,对于一个人提交的代码来说,在一个大型项目中重要的一步是这个项目的代码可以溯源,当找到一份异常的提交后,可以根据提交者的用户名和邮箱找到这份代码对应是由谁来完成的,这是Git所应具备的一项功能,因此在提交代码前需要将仓库信息进行初步的配置
工作区、暂存区、版本库的概念
在Git仓库中有上面的三个名词,那么三个词的概念如下:
工作区:就是电脑上要写的代码或文件的目录
暂存区:也叫做stage或index,一般来说是出于.git目录下的index文件下,也叫做索引
版本库:也叫做仓库,版本库中有一个隐藏的目录.git,前面也有提到这是一个隐藏文件,而这个.git实际上就是我们所谓的仓库,实际上它不算是工作区,是Git的一个版本库,这个版本库中的所有文件都能被Git进行管理,对于工作区中文件的各种操作,比如说新增删除等都能进行一定的追踪,在未来可以对于某个版本进行还原等操作
下面用一张图来阐述这三个区的一个基本概念:
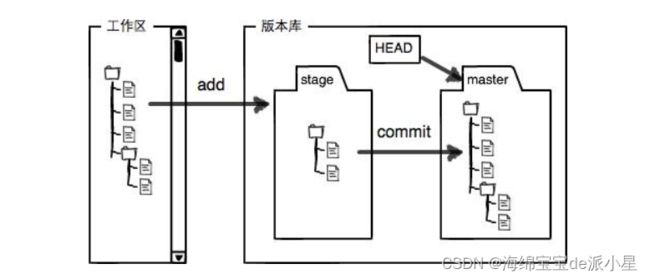
上图就表明了关于Git中的三个模块的一个基本概念,左侧就是工作区,右侧是版本库,版本库中又存在了一个临时暂存区和master的概念,而实际上版本库中还有对象库的概念,也就是objects,对象库中存储的是关于这些文件的一个索引
关于版本库中还有一个HEAD,这个HEAD其实是一个指针,文件是树形结构,因此必须有一个头指针用来对文件进行一些操作
下面对于工作区和版本库的一些操作进行阐述:
当对于工作区进行修改的时候,如果执行了git add的命令,那么出于暂存区的目录树的内容就会被更新,文件的索引也会被更新,但是这些更新都是暂时的,因为这些信息都被存储在暂存区中,而commit的存在就是对于master分支的一个更新,也就是说,只有在进行了commit的操作后,master的分支进行了相应的更新,也就可以理解为是暂存区的目录树进入到了真正的版本库中
由此可以引出一些结论:
首先要明确的是,.git就是我们所谓的仓库,但不能直接向仓库中写入东西,应该要在仓库所在的工作区下进行写入或其他操作
如果只是用新建或粘贴等的一些操作,并不能是向仓库中添加文件,只是在工作区进行了一定的写入和修改,必须要用add的操作将你所修改的目录树上传到stage暂存区,再从暂存区中commit文件到仓库,才能真正进行管理
添加文件
上面总结了一些关于文件的操作,那么下面具体的使用:
现在在.git所在目录下新建了一个test文件,那么就可以使用add的命令把文件添加到暂存区
# test所指的是文件名
git add test
# 表示直接将当前目录下的所有内容都新增到暂存区
git add .
再使用commit的命令将暂存区的内容都添加到本地仓库中
# message表示的就是关于本次提交的一些描述性的语言,用来记录提交细节
git commit -m "message"
查看.git文件
先看刚创建的git下的目录树:
[test@VM-16-11-centos GitCode]$ tree .git
.git
|-- branches
|-- config
|-- description
|-- HEAD
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- prepare-commit-msg.sample
| |-- pre-push.sample
| |-- pre-rebase.sample
| `-- update.sample
|-- info
| `-- exclude
|-- objects
| |-- info
| `-- pack
`-- refs
|-- heads
`-- tags
现在我们创建了一个test文件,接着把这个文件进行add和commit操作:
[test@VM-16-11-centos GitCode]$ tree .git
.git
|-- branches
|-- COMMIT_EDITMSG
|-- config
|-- description
|-- HEAD
|-- hooks
| |-- applypatch-msg.sample
| |-- commit-msg.sample
| |-- post-update.sample
| |-- pre-applypatch.sample
| |-- pre-commit.sample
| |-- prepare-commit-msg.sample
| |-- pre-push.sample
| |-- pre-rebase.sample
| `-- update.sample
|-- index
|-- info
| `-- exclude
|-- logs
| |-- HEAD
| `-- refs
| `-- heads
| `-- master
|-- objects
| |-- 22
| | `-- 7d6160665cbf086283c40409fe293725aba9c0
| |-- de
| | `-- 52fd134820bcfe69a77b154d8f429ba43d954a
| |-- f2
| | `-- 2a908e15bc9989e5a8de489dd757e37ca2e728
| |-- info
| `-- pack
`-- refs
|-- heads
| `-- master
`-- tags
使用git log命令可以查看历史的提交记录:
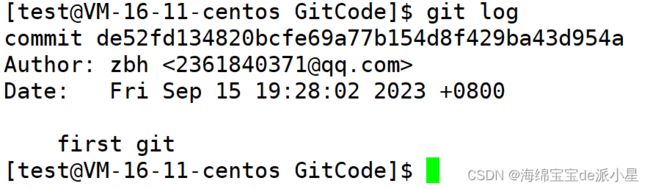
则此时显示的就是关于git提交的一些历史记录,这当中commit中有一组数据,我们要记录下来:
# commit后生成的一段十六进制编号
de52fd134820bcfe69a77b154d8f429ba43d954a
下面对比进行提交前后的目录树:

从中可以看出的第一个变化,就是提交后的目录树新增了一个index目录,而这也印证了前面所说的关于Git的暂存区的概念
前面又提到了,HEAD就是默认指向master分支的一个指针,因此可以在Linux下查看HEAD指向的内容:

从内容中可以看出,master路径下存放的是一段编号:
de52fd134820bcfe69a77b154d8f429ba43d954a
而这段编号和我们前面所看到的内容是一样的,这段内容保存的就是当前最新的commit id
下面继续来看树更新的部分:

objects中也进行了一些更新,而前面说到过,objects实际上就是Git的对象库,里面包含了创建的各种版本库对象和内容,当执行git add的命令的时候,暂存区的目录树被进行了更新,同时工作区的内容就被写入了对象库中的一个新的对象中,而这个对象就位于objects目录下,那么如何查看这个路径下的内容?
在查找的时候要把commit id分成两个部分,前两位是文件夹的名称,后面是文件的名称,因此就定位到了de文件夹下的相关内容
而如何查看这个文件的具体内容?实际上这个内容是不可以被直接查看的,因为这个内容被安全哈希算法进行了一定程度的加密形成的文件,但也有解决方法,可以用git cat-file命令来查看版本库对象的内容
# xxxx表示的是commit id
git cat-file -p xxxx

由此可以看出,这个commit id下存储的信息就是当初在commit -m后所写的更新信息
由此我们可以看出:
HEAD是一个默认指向master分支的一个指针refs/heads/master文件中存储的是当前master分支的最新的一个commit idobjects中包含了创建的各种版本库对象的内容,可以说是存放了Git维护中的所有的修改
关于add和commit的一些额外命令
git status
该命令用于查看在你上次提交后是否对于文件有进行新的修改
# xxx表示要对比的文件名
git diff xxx
下面进行一些实验:
现在重新写一个内容进行更新:

此时这里使用vim又输入了一些内容,此时输入命令后就提示要先提交到暂存区,再进行提交,下面执行add和commit命令

此时就提示已经工作区没有需要提交的内容
版本回退
既然是版本控制工具,那么想要得到之前的版本也是应该具备的一项功能,那么在Linux中如何实现版本回退?
需要用到reset指令!
# soft表示只改变版本库
git reset --soft [commit id]
# mixed表示改变暂存区内容
git reset --mixed [commit id]
# hard表示将暂存区和工作区都退回到以前版本
git reset --hard [commit id]
因此从中看出,hard指令在使用的时候是需要慎重的,如果你所写的代码没有进行提交,直接使用这个命令会导致代码被覆盖
简单来说,git reset命令的核心就是前面所说的commit id,如果能找到commit id就可以实现一系列的功能,因此下面Git还提供了一个找commit id的方法:
git reflog
Git回退的机理是什么?
对于当前的Git版本来说,Git版本的回退是相当快的,因为在Git内部有一个指向当前分支的HEAD指针,而在master文件中存储着最新的commit id,因此当在回退版本的时候,Git仅仅是把master中存储一个特定的版本,而当回退的时候,只需要让HEAD指针指向的master指向前面的一个版本就可以了
撤销修改
本小节主要介绍的是关于Git使用中版本回退的问题:
下面展示多个场景的不同使用方法:
1. 对于工作区内还没有add的代码
- 直接手动删除
这样的操作是有风险的,可能会多删或其他问题情况出现
- 使用命令
# xxx表示文件名
git checkout -- xxx
这个命令的作用就是将当前工作区的代码回退到上一次add时所提交的代码
2. 对于已经add没有commit的代码
对于这种情况,可以考虑使用前面的reset命令,选项可以采用mixed或hard都可以
这里要补充一点,reset并非必须使用commit id,也可以直接使用HEAD和^的组合:
# 这里的xxx可以是commit id,也可以直接写HEAD表示当前版本,也可以写HEAD^表示上一个或HEAD^^...
git reset [选项] xxxx
3. 对于已经commit没有push的代码
对于这种情况,直接使用HEAD^进行版本回退即可
git reset HEAD^
4. 如果进行push后的代码如何处理
此时涉及到远程仓库的概念,后面进行一些总结
删除操作
删除操作有两种:
- 直接使用
Linux下的删除命令
rm -f [file]
git add [file]
git commit -m "xxx"
- 直接使用Git本身提供的删除命令
git rm [file]
git commit -m "xxx"